Embedding在RAG中的核心作用及其几何类比-来自DeepSeek
Embedding在RAG中的核心作用及其几何类比
1. 核心概念映射
-
Embedding的本质:将文本、图像等非结构化数据转化为高维空间中的坐标点(向量),例如:
-
句子A → 向量 [0.2, -1.5, 3.0, ..., 0.7](假设维度为768)
-
句子B → 向量 [0.3, -1.4, 2.9, ..., 0.6]
-
关键点:语义相近的内容在高维空间中距离更近。
-
-
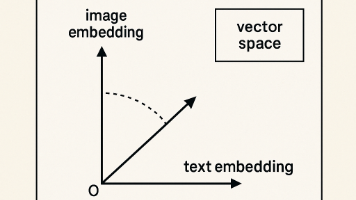
欧几里得几何类比:
-
二维平面:点 (2,3) 和 (2,4) 的直线距离为1,表示高度相似。
-
高维语义空间:句子A和句子B的向量距离越近,语义越相似(如余弦相似度0.92)。
-
差异:高维空间的距离计算更复杂(如余弦相似度替代欧氏距离),但逻辑一致。
-
2. Embedding在RAG中的具体应用流程
以检索增强生成(RAG)为例,说明Embedding如何驱动流程:
-
文档预处理:
-
将知识库中的文档切分为段落,生成每个段落的Embedding向量,存入向量数据库。
-
例:医学文献库 → 每段摘要转化为768维向量。
-
-
用户提问检索:
-
将用户问题“心脏病的早期症状有哪些?”转化为Embedding。
-
在向量数据库中搜索与该向量最接近的Top K个文档段落(如K=5)。
-
-
增强生成:
-
将检索到的相关段落与用户问题拼接,输入大模型(如GPT-4)生成答案:
输入 = "根据以下医学文献:{检索到的段落},请回答:心脏病的早期症状有哪些?" -
输出:结构化症状列表(胸痛、呼吸困难等),确保答案基于权威知识。
-
3. 语义空间的“距离”如何量化?
-
常用度量方法:
方法 公式 特点 余弦相似度 cos(θ) = (A·B)/(|A||B|) 忽略向量长度,专注方向一致性 欧氏距离 √Σ(A_i - B_i)^2 受向量维度缩放影响 点积 A·B = ΣA_iB_i 计算高效,需归一化后更合理 -
实际应用选择:
-
文本相似度通常用余弦相似度(更关注语义方向而非向量长度)。
-
图像检索可能用欧氏距离(如人脸识别需精确匹配特征强度)。
-
4. 高维语义空间的直观理解
-
挑战:人类难以想象超过3维的空间,但数学性质可类推。
-
降维可视化:
-
使用t-SNE或PCA将高维向量投影到2D/3D,近似观察聚类效果。
-
例:新闻标题Embedding经t-SNE可视化后,体育类、科技类标题形成明显簇群。
-
-
经典案例:
-
词向量类比:
向量("国王") - 向量("男") + 向量("女") ≈ 向量("女王") -
跨语言对齐:
不同语言的同一句话Embedding在共享空间中位置接近(如“Hello”与“Bonjour”)。
-
5. 实际应用场景与数据对比
| 场景 | Embedding作用 | 效果对比(相似度阈值) |
|---|---|---|
| 电商搜索 | 将用户Query与商品描述匹配 | 相似度>0.85 → 精准推荐 |
| 法律文书分类 | 判断案件类型(合同纠纷/刑事犯罪) | 类内平均相似度0.78 vs 类间0.32 |
| 客服意图识别 | 区分“退货申请”与“物流查询” | 意图簇间距>0.6 |
6. 技术优势与挑战
-
优势:
-
语义泛化:理解同义词(“手机”与“智能手机”相似度高)。
-
多模态统一:图文跨模态检索(用文本搜图)。
-
效率提升:相比关键词匹配,减少“词汇不匹配”问题(如“计算机” vs “电脑”)。
-
-
挑战:
-
维度灾难:过高维度可能引入噪声,需平衡信息密度(通常256-1024维较优)。
-
领域适配:通用Embedding(如BERT)在专业领域(如医疗)表现不佳,需微调。
-
计算成本:实时检索海量向量需优化(如Facebook的FAISS索引库)。
-
总结
Embedding通过将数据映射到高维语义空间,使机器能够像人类一样理解“意义相似性”。在RAG模式中,这种能力直接转化为:
-
精准检索:从海量数据中快速定位相关知识片段。
-
可信生成:基于权威信息生成答案,减少大模型幻觉(Hallucination)。
关键启示:
-
对开发者:优化Embedding模型和检索算法是提升RAG效果的核心。
-
对用户:理解“语义搜索”背后的高维逻辑,能更高效设计查询语句。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)