LLMs基础学习(七)DeepSeek专题(4)
DeepSeek中的技术,规则化奖励、自我认知、RL训练中的过拟合以及蒸馏中的知识
LLMs基础学习(七)DeepSeek专题(4)
文章目录
图片和视频链接:https://www.bilibili.com/video/BV1gR9gYsEHY?spm_id_from=333.788.player.switch&vd_source=57e4865932ea6c6918a09b65d319a99a
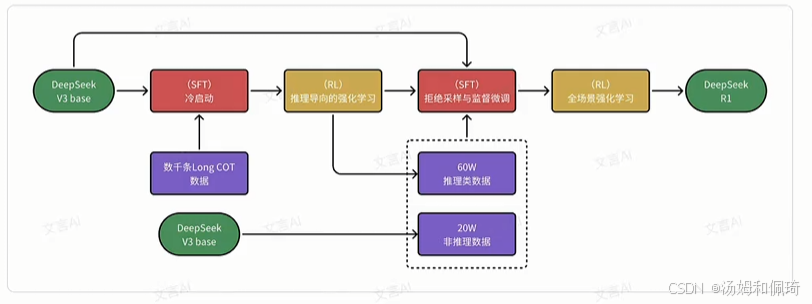
DeepSeek-R1 训练过程的四个阶段
尽管 DeepSeek-R1-Zero 展示了强大的推理能力,并能够自主发展出意想不到且强大的推理行为,但它也面临一些问题。例如,DeepSeek-R1-Zero 存在可读性差和语言混杂等问题。R1 旨在成为一个更易用的模型。因此,R1 并不像 R1-Zero 那样完全依赖于强化学习过程,而是通过多个阶段完成。
具体流程
训练过程分成四个阶段:
- (SFT,Supervised Fine-Tuning(监督微调)) 冷启动:为了避免 RL 训练从基础模型开始的早期不稳定冷启动阶段,构建并收集少量长的 CoT(Chain of Thought,思维链)数据来微调 DeepSeek-V3-Base 作为 RL 的起点。
- (RL) 推理导向的强化学习:
- 在冷启动数据上微调 DeepSeek-V3-Base 后,应用与 DeepSeek-R1-Zero 中相同的 RL 方法训练。
- 本阶段侧重于增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及具有明确解决方案的明确定义的问题。
- 当 RL 提示涉及多种语言时,CoT 经常表现出语言混合现象。为了减轻语言混合问题,在 RL 训练过程中引入了一种语言一致性奖励。
- 双奖励系统:设计了基于规则的奖励机制,包括:
- 准确性奖励:评估答案正确性(如数学题答案验证或代码编译测试)。
- 格式奖励:强制模型将推理过程置于特定标签(如和)之间,提升可读性。
- (SFT) 拒绝采样与监督微调:
- 当 RL 过程趋于收敛时,利用训练出的临时模型生产用于下一轮训练的 SFT 数据(60W 推理数据)。
- 与冷启动数据区别在于,此阶段既包含用于推理能力提升的 60W 数据,也包含 20W 推理无关的数据。使用这 80W 样本的精选数据集对 DeepSeek-V3-Base 进行了两个 epoch 的微调。
- (RL) 全场景强化学习:
- 在微调模型的基础上,使用全场景的强化学习数据提升模型回复的有用性和无害性。
- 对于推理数据,遵循 DeepSeek-R1-Zero 的方法,利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。
- 对于通用数据,采用基于模型的奖励来捕捉复杂和细微场景中的人类偏好。
小结
使用 (SFT) 冷启动 -->(RL) 推理导向的强化学习 -->(SFT) 拒绝采样与监督微调 -->(RL) 全场景强化学习四阶段训练,R1 模型达到 OpenAI-o1-1217 的水平。
“规则化奖励”
- 规则化奖励就像 “客观考试评分”—— 答案对错一目了然。
- 而神经奖励模型类似 “老师主观打分”,模型可能学会讨好老师却答错题。
- 用规则化奖励更公平、更直接。
具体原因
在推理任务中强调 “规则化奖励” 而非神经奖励模型的原因如下:
- 避免奖励黑客(Reward Hacking)问题:原文指出:“神经奖励模型在大规模强化学习过程中可能出现奖励黑客”(“neural reward model may suffer from reward hacking in the large-scale reinforcement learning process”,章节 2.2.2)。神经奖励模型可能被模型通过非预期方式(如利用模型漏洞)获得高奖励,而实际推理能力未真正提升。
- 降低训练复杂性和资源消耗:使用神经奖励模型需要额外训练和维护,文档提到 “重新训练奖励模型需要额外的训练资源并复杂化整个流程”(“retraining the reward model needs additional training resources and it complicates the whole training pipeline”,章节 2.2.2)。而规则化奖励(如准确性验证、格式检查)可直接通过预设规则计算奖励,无需额外模型支持。
- 奖励信号更清晰可靠:规则化奖励基于确定性逻辑(如数学答案验证、代码编译测试),文档提到 “对于数学问题,模型需以指定格式提供最终答案,从而通过规则可靠验证正确性”(“for math problems with deterministic results, the model is required to provide the final answer in a specified format… enabling reliable rule-based verification”,章节 2.2.2)。这种奖励机制直接关联任务目标,避免了神经奖励模型可能引入的评估偏差。
Reward Modeling:奖励是训练信号的来源,决定了强化学习(RL)的优化方向。为训练 DeepSeek-R1-Zero,采用基于规则的奖励系统,主要由两种奖励组成:
- Accuracy rewards(准确性奖励):准确性奖励模型评估响应是否正确。例如,对于有确定结果的数学问题,模型需以指定格式(如在框内)提供最终答案,以便基于规则可靠验证正确性。类似地,对于 LeetCode 问题,可使用编译器基于预定义测试用例生成反馈。
- Format rewards(格式奖励):除准确性奖励模型外,采用格式奖励模型,强制模型将其思考过程置于和标签之间。
在开发 DeepSeek-R1-Zero 时不应用结果或过程神经奖励模型,因为发现神经奖励模型在大规模强化学习过程中可能出现奖励黑客问题,且重新训练奖励模型需要额外训练资源并使整个训练流程复杂化。
小结
为何在推理任务中强调 “规则化奖励” 而非神经奖励模型?
- 避免奖励黑客(Reward Hacking)问题
- 降低训练复杂性和资源消耗
- 奖励信号更清晰可靠
“自我认知”(self-cognition)数据
基本概念
根据文档 2.3.3 章节 “Rejection Sampling and Supervised Fine-Tuning” 的描述:“自我认知”(self-cognition)数据具体指用于训练模型理解并回答与自身属性、能力边界相关的查询数据。例如:
- 关于模型身份的问答(如 “你是什么类型的 AI?”)
- 能力范围的说明(如 “你能处理哪些类型的任务?”)
- 训练数据相关询问(如 “你的知识截止到什么时候?”)
- 伦理限制声明(如 “为什么有些问题不能回答?”)
这类数据属于非推理类数据(Non-Reasoning data),与写作、事实问答、翻译等任务并列,在监督微调阶段用于塑造模型的自我认知能力。文档特别指出,对于这类简单查询(如 “hello”),模型不需要生成思维链(CoT),直接给出简洁回应即可。(“For simpler queries, such as ‘hello’ we do not provide a CoT in response.”,章节 2.3.3)
小结
“自我认知”(self-cognition)数据具体指用于训练模型理解并回答与自身属性、能力边界相关的查询数据。
RL 训练中过度拟合
防止模型成为 “考试机器”,除模拟考(评测任务)外,还需定期抽查其他科目(多样化任务),确保全面发展。
避免方式
- 采用多样化的训练数据分布:
- 混合推理与非推理数据。在监督微调(SFT)阶段,收集涵盖推理任务(如数学、编码 )和通用任务(写作、事实问答等)的多样化数据,结合约 60 万推理相关样本和 20 万非推理样本,共约 80 万训练样本。这种数据多样性促使模型适应不同场景,降低对单一评测任务的依赖。
- 多阶段训练流程:
- 采用 (SFT) 冷启动→(RL) 推理导向的强化学习→(SFT) 拒绝采样与监督微调→(RL) 全场景强化学习四阶段训练。在接近 RL 收敛时,通过拒绝采样生成新 SFT 数据,结合通用数据重新微调模型,最后进行二次 RL 训练 。分阶段训练逐步扩展模型能力,避免过早过拟合。
- 组合多类型奖励信号:
- 将规则化奖励与人类偏好奖励结合 。
- 在最终 RL 阶段,对推理任务使用规则化奖励(如答案准确性、格式要求),对通用任务引入人类偏好奖励模型 。这种混合奖励机制平衡了任务目标与泛化性。
- 拒绝采样筛选高质量响应:
- 过滤低质量与重复内容 。在生成 SFT 数据时,通过拒绝采样排除语言混杂、冗长或重复的推理过程 ,确保训练数据的多样性和可读性,减少模型对噪声或特定模式的依赖。
- 全场景提示分布训练:
- 覆盖广泛用户需求场景 。在最终 RL 阶段,使用涵盖数学、编码、写作、问答等多场景的提示分布 。通过多样化数据优化模型,防止模型过度适配单一评测任务。
小结
避免模型在 RL 训练中过度拟合评测任务的方法:
- 采用多样化的训练数据分布
- 多阶段训练流程
- 组合多类型奖励信号
- 拒绝采样筛选高质量响应
- 全场景提示分布训练
DeepSeek 中的蒸馏
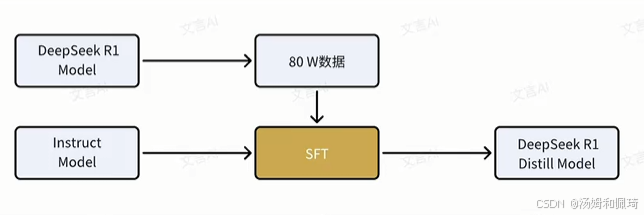
DeepSeek 团队探索将 R1 的推理能力蒸馏到更小规模模型的潜力,利用 DeepSeek - R1 生成的 80W 数据对 Qwen 和 Llama 系列的多个小模型进行微调,发布了 DeepSeek - R1 - Distill 系列模型。
蒸馏基本流程
- 数据准备:DeepSeek - R1 生成 80W 高质量训练数据,包含丰富推理链(Chain of Thought, CoT)和多种任务类型。
- 模型选择:选择 Qwen 和 Llama 系列多个小模型作为学生模型,参数规模分别为 1.5B、7B、8B、14B、32B 和 70B。
- 蒸馏训练:使用 DeepSeek - R1 生成的数据对小模型微调,优化蒸馏损失函数,使小模型输出接近 DeepSeek - R1 的输出。
- 性能评估:对蒸馏后的小模型进行性能评估,验证推理能力提升效果。
性能表现
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCode Bench | CodeForces | |
|---|---|---|---|---|---|---|
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | rating | |
| GPT-4-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
- AIME 2024:基于 2024 年美国数学邀请赛(高中竞赛级别)题目集,评估大模型多步骤数学推理能力。
- MATH-500:OpenAI 精选 500 道数学题评测集,覆盖代数、几何等领域,检验模型数学解题能力。
- GPQA Diamond:专家设计 198 道高难度 STEM 领域问题集,测试模型专业学科深度推理和抗搜索作弊能力。
- LiveCodeBench:聚焦真实世界代码工程任务评测集,基于 GitHub 仓库提炼 500 个 Python 问题,评估模型解决实际编程问题能力。
- CodeForces:知名编程竞赛平台动态题库,含算法与数据结构等高难度题目,衡量模型代码生成和复杂逻辑推理水平,根据解题正确性、速度、代码质量等计算用户评分(Rating) 。
小结
为使小模型具备 DeepSeek - R1 的推理能力:
- 首先通过 DeepSeek - R1 推理得到 800k 个样本。
- 然后对 6 个不同参数量的开源模型进行直接有监督微调,即直接的数据蒸馏。
为何在蒸馏过程中仅使用 SFT 而非 RL?
蒸馏像 “临摹大师画作”,直接复现效果;RL 像 “自己创作”,虽可能更好但费时费力,对小模型来说,先临摹更划算。
主要目标验证蒸馏有效性。在蒸馏过程中仅使用监督微调(SFT)而非强化学习(RL)的原因如下:
- 成本限制:小模型 RL 需大量计算资源,而 SFT 仅需单轮微调。
- 知识保留:SFT 直接模仿大模型输出,避免 RL 探索中的知识遗忘。
探索:结合 SFT 与轻量 RL(如离线 RL)是否可能进一步突破?
蒸馏过程中是否存在知识损失?如何量化?
知识损失像 “压缩图片”,大模型(高分辨率原图)缩成小模型(小图)后细节模糊,主体保留但清晰度下降。
知识损失的存在性
- 蒸馏模型性能(如 32B 模型 AIME 72.6% )仍明显低于原模型 DeepSeek - R1(AIME 79.8% ),说明存在知识损失。
- 文档指出蒸馏模型仅 “接近 o1 - mini” 而原模型 “匹配 o1 - 1217”,佐证性能差距。
量化方法
- 标准基准测试分数对比
- 数学推理:AIME 2024 pass@1(蒸馏 32B:72.6% vs 原模型:79.8%)
- 代码能力:Codeforces Rating(蒸馏 32B:1691 vs 原模型:2029)
- 综合知识:GPQA Diamond(蒸馏 32B:62.1% vs 原模型:71.5%)
- 任务类型敏感性分析:需要长链推理的任务(如 LiveCodeBench)蒸馏模型性能下降更显著(57.5% vs 原模型 65.9%) ,结构化任务(如 MATH - 500)损失较小(94.5% vs 97.3%) 。
知识损失的关键因素
- 规模效应:蒸馏 1.5B 模型 AIME 仅 28.9%,32B 模型达 72.6%,小模型因容量限制损失更多知识。
- 推理深度依赖:深层推理行为(如反思、验证)难被小模型完全复现,导致 Codeforces 等复杂任务评分差距更大。
小结
蒸馏必然导致知识损失,其程度可通过标准基准分数差异量化,损失幅度与模型规模成反比、与任务复杂度成正比。文档通过对比蒸馏模型与原模型的 pass@1、cons@64 评分等指标验证了该现象。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)