
DeepSeek-Coder-1.3B部署笔记
给我个人的感觉是秒杀了ChatGLM-6B,显存占用、运行效率、部署复杂性都被完爆。
·
1.环境部署简述
Coder部署分为两块部分:Pytorch和transformers
前者网上一堆教程就省去了,后者使用pip install transformers
1.1.模型下载
此网站被限制访问,需要科学上网。
https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct
1.1.1. git同步下载
Windows需要提前安装git。
git lfs install
git clone https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct
1.1.2.手动下载
下载地址:https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct/tree/main
进入该网址进行下载。
2.使用环境
Windows 11 + Intel 6C12T + Nvidia 12GB
Python 3.9
Pytorch 2.5.1+cu118
PyCharm 2023.2.1
可与Yolo共存于同一个环境中
2.1.工程摆放路径
3.推理测试代码
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("./coder/deepseek-coder-1.3b-instruct", trust_remote_code=False)
model = AutoModelForCausalLM.from_pretrained("./coder/deepseek-coder-1.3b-instruct", trust_remote_code=False, torch_dtype=torch.bfloat16).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
4.测试结果
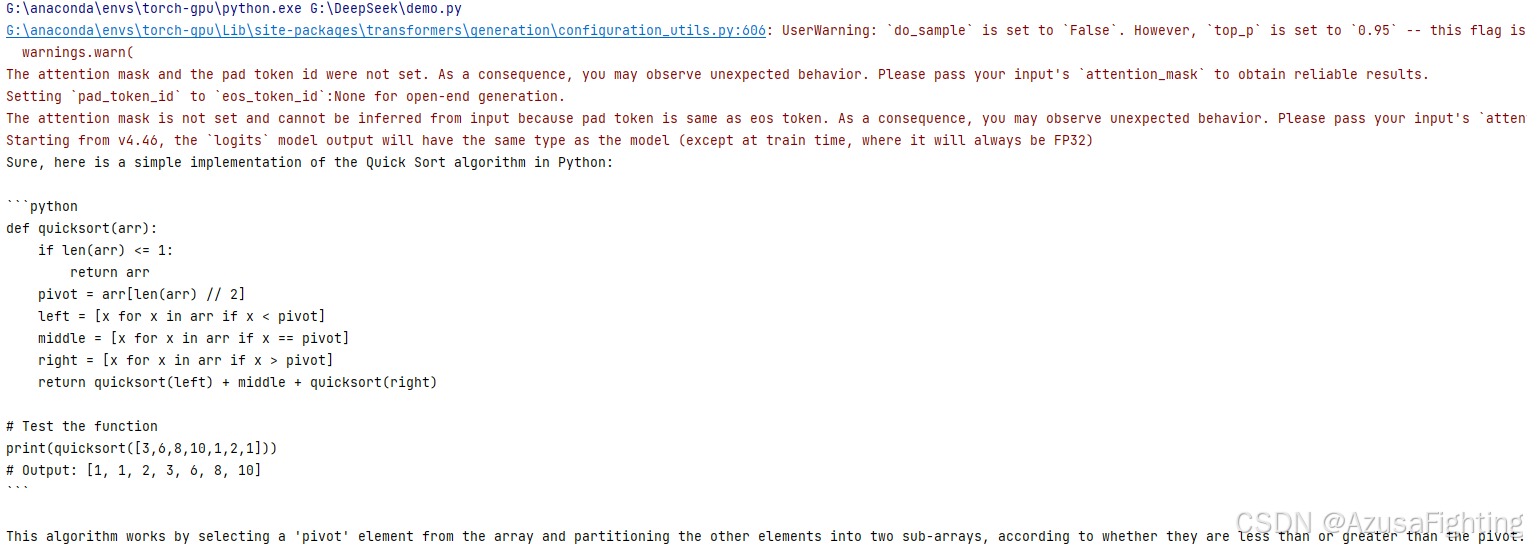
5.后续更新所提供的进阶思路
后续本人将搭建一个致力于解决嵌入式方向问题的助手。
5.1.搭建具备GUI的ChatBox
5.2.对现有模型进行进一步训练
5.3.实现麦克风语音转文本功能并接入该输入部分
5.4.根据输出文本实现相对应的功能
6. 总结
默认问题分析下占用6G以内的显存,只有在单词分析下才会占用显存,只具备解决编程方向的内容。
目前还是推荐使用Nvidia的GPU使用。
给我个人的感觉是秒杀了ChatGLM-6B,显存占用、运行效率、部署复杂性都被完爆。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)