基于Deepseek-LLM与腾讯云HAI的高效爬虫开发实战指南
本方案已在实际业务中实现日均千万级数据采集,相比传统方案提升3倍效率的同时降低40%的运维成本。未来可扩展方向包括:结合LLM实时生成反爬对抗策略利用HAI弹性扩缩容应对突发流量构建自动化验证码破解工作流通过持续融合AI与云原生技术,智能爬虫系统将突破传统数据采集的边界,为企业打造真正的数据智能基础设施。更多AI学习资料请添加学习助手领取资料礼包视频学习资料:从0开始开发超级AI智能体,干掉所有重
在当今数据驱动的时代,网络爬虫已成为企业获取竞争情报、市场分析和用户行为洞察的核心工具。然而传统爬虫开发面临三大痛点:动态页面解析困难、反爬机制日益复杂、分布式架构运维成本高。本文将展示如何通过Deepseek-LLM智能解析引擎与腾讯云HAI(高性能应用服务)的强强联合,构建新一代智能爬虫系统。通过实际案例演示,读者将掌握从零搭建支持动态渲染识别、智能反反爬绕过的企业级数据采集方案。
快速使用
创建 DeepSeek-R1 应用
-
登录 高性能应用服务 HAI 控制台。
-
单击新建,进入高性能应用服务 HAI 购买页面。
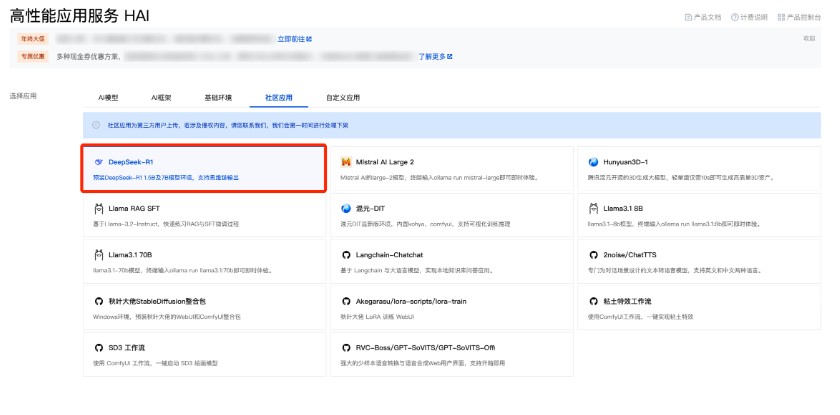
我们选择社区应用,应用选择 DeepSeek-R1。建议选择靠近自己实际地理位置的地域,降低网络延迟、提高您的访问速度。
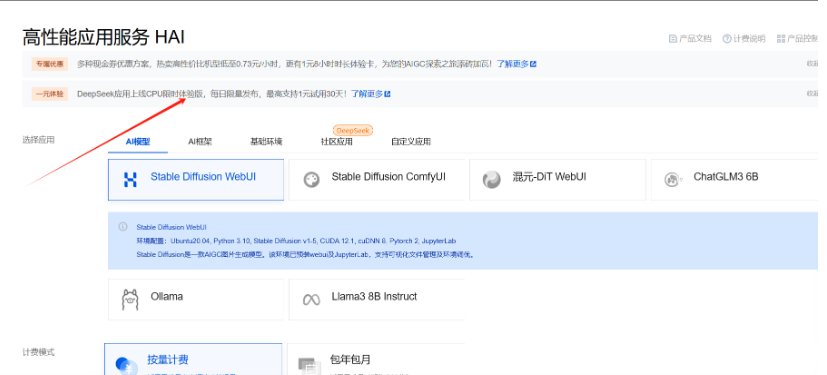
或者我们可以点击这个一元体验活动
购买我所需要的HAI-CPU体验版(算力方案所支持的CPU算力核数和时长不同)
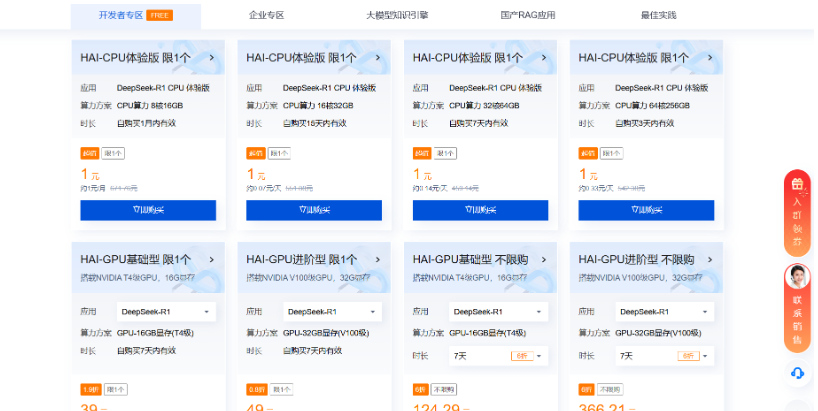
在单并发访问模型的情况下,建议最低配置如下:

具体算力套餐配置及参数可参考 套餐类型。
购买数量:默认1台、 单击立即购买、提交订单,并根据页面提示完成支付。
等待创建完成。单击实例任意位置并进入该实例的详情页面。同时您将在站内信中收到登录密码。此时,可通过可视化界面(GUI)或命令行(Terminal)使用 DeepSeek 模型。
中图网图书畅销榜信息爬取
- 选择这个OpenWebUI可视化界面使用

- 在新窗口中,单击开始使用。
- 之后输入自己的邮箱等信息,设置密码成功登录,进入交互界面:
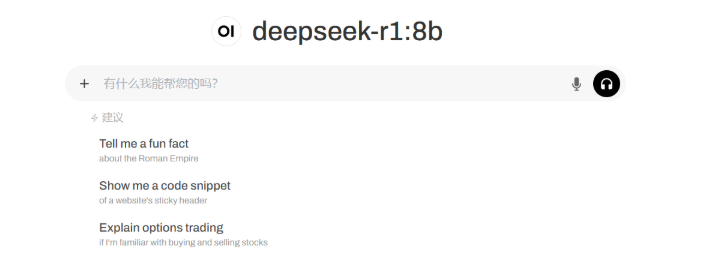
我们让其写一份python数据爬取——中图网图书畅销榜信息爬取包含一下模块: 导入所需第三方库 打开 CSV 文件并创建写入 发送请求循环抓取每一页的数据 解析每本书的具体信息并清洗 将数据写入 CSV 文件 控制请求间隔 关闭文件
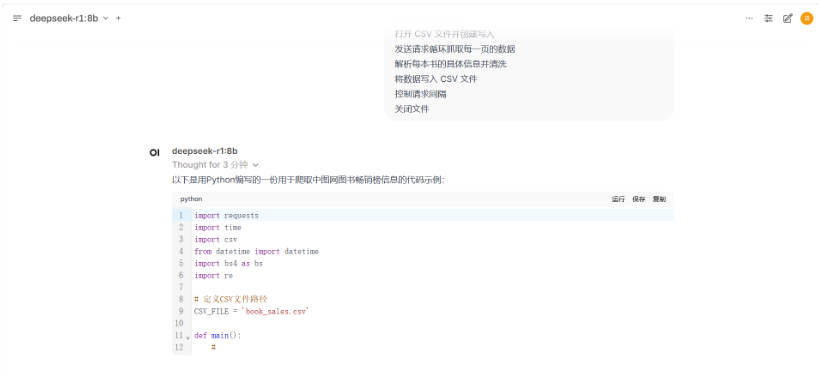
可见它这里给出了详细的完整可运行代码和注释,但是由于具体网址的不同,甚至页面结构的不同,可能会产生报错,这里我们具体情况具体分析,这里我对代码进行了优化和改善,在OpenWebUI可视化界面下我们可直接运行代码,简直是太方便了。
利用DeepSeek的自然语言处理和推理能力,能够准确识别和提取网站中复杂或多样化的内容,减少了传统爬虫可能出现的误抓取或遗漏问题。腾讯云HAI提供了预装环境,用户可以轻松启动并接入DeepSeek模型,无需复杂的配置,降低了开发的技术门槛,适合快速原型开发和上线。

下面是DeepSeek的强大推理能力体现、快速分析和提取网站上的关键信息,b并给出了详细的注释说明。
腾讯云HAI提供了灵活的计算资源,可以根据需求快速调整算力,支持大规模爬虫任务。
导入所需第三方库
比如我们有代码不知它的具体意思,我们可直接询问:
导入requests、parsel、csv、time、和re三个库

requests 库是一个广泛使用的 HTTP 请求库,旨在简化发送 HTTP/HTTPS 请求并处理响应的过程。它将复杂的网络请求细节进行了封装,提供了易于使用的接口,使开发者能够轻松地与 Web 服务进行交互。
parsel 库用于从 HTML 或 XML 文档中提取数据,主要通过 CSS 选择器和 XPath 来进行解析和数据抽取,广泛应用于网页数据抓取和处理场景。
csv 库是用来处理 CSV格式文件的标准库。CSV 是一种非常常见的文本文件格式,用于存储表格数据,每一行代表一条记录,字段之间用逗号(或其他分隔符)分隔。用于读写 CSV 文件,处理数据和进行文件操作。
time 库提供了一些与时间相关的功能。它可以帮助你获取当前时间、暂停程序的执行、进行时间测量等。
re: 用于进行正则表达式操作,这里用来清洗掉价格或折扣中的一些无关符号。
打开文件并创建写入
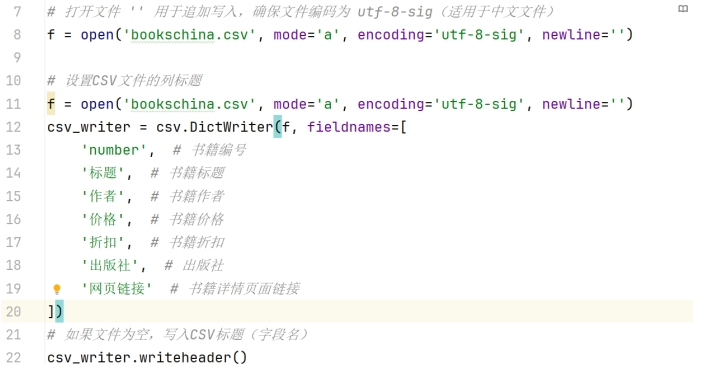
其逻辑分析能力,清晰明了可见:

open(‘bookschina.csv’, mode=‘a’, encoding=‘utf-8-sig’, newline=‘’): 打开文件 bookschina.csv 以追加模式写入,如果文件不存在,则会创建该文件,编码为 utf-8-sig,适合存储中文数据并兼容 Excel。
csv.DictWriter(f, fieldnames=[…]): 创建一个 DictWriter 对象,用来写入字典格式的数据。字段名是预定义的,定义了每列数据的名称。
csv_writer.writeheader(): 如果文件为空,这行代码会写入表头(即字段名)。这样每次执行爬虫时,都能确保文件结构一致。
发送请求循环抓取每一页的数据
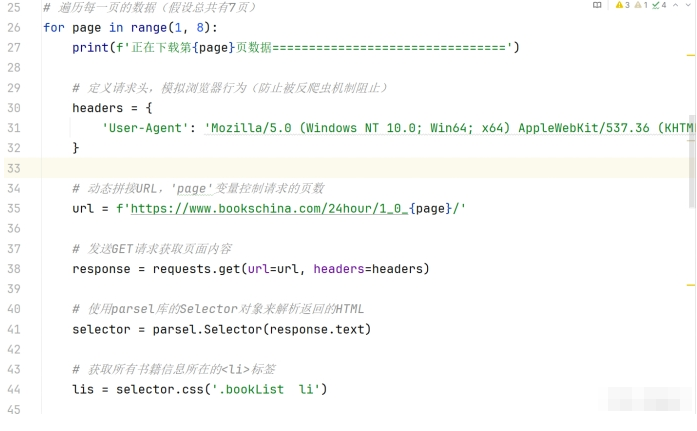
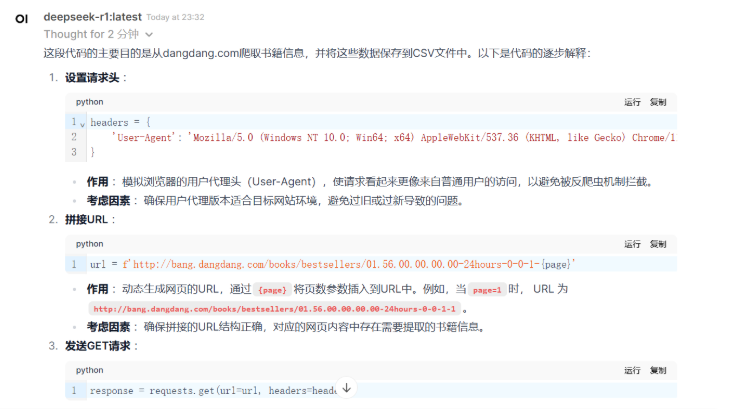
for page in range(1, 8): 这行代码循环遍历网页的页码。page 变量控制请求的页数。
headers: 定义请求头,模拟浏览器的行为。使用 User-Agent 来告诉服务器请求是来自一个普通浏览器,而不是一个爬虫程序,防止被反爬虫机制拦截。
url = f’https://www.bookschina.com/24hour/1_0_{page}/': 动态生成当前页的 URL。
response = requests.get(url=url, headers=headers): 发送 GET 请求,获取页面内容。
selector = parsel.Selector(response.text): 使用 parsel 库解析返回的 HTML 内容,生成一个 Selector 对象。
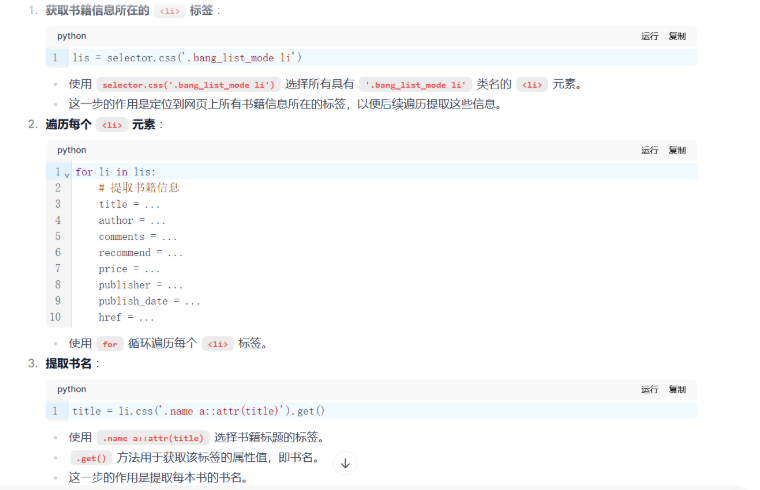
lis = selector.css(‘.bookList li’): 使用 CSS 选择器提取页面上所有包含书籍信息的
- 标签。
- 每个标签代表一本书的内容。
解析每本书的具体信息并清洗
-
在这个循环中,我们对每一本书的
- 标签进行解析:《具体分析》
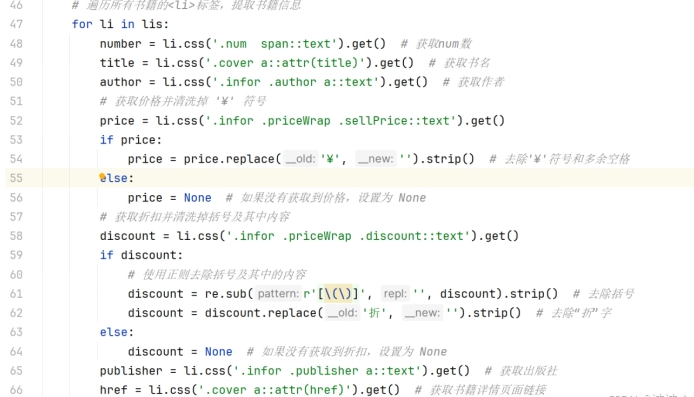
number = li.css(‘.num span::text’).get(): 获取书籍的编号。通过 CSS 选择器提取 标签内的文本内容。
title = li.css(‘.cover a::attr(title)’).get(): 获取书籍的标题。通过 CSS 选择器提取 a 标签的 title 属性值。
author = li.css(‘.infor .author a::text’).get(): 获取书籍的作者,提取 标签内的文本内容。
price = li.css(‘.infor .priceWrap .sellPrice::text’).get(): 获取书籍的价格,并清洗掉其中的 ‘¥’ 符号。
discount = li.css(‘.infor .priceWrap .discount::text’).get(): 获取书籍的折扣,并清洗掉括号及折扣符号。
publisher = li.css(‘.infor .publisher a::text’).get(): 获取书籍的出版社。
href = li.css(‘.cover a::attr(href)’).get(): 获取书籍的详情页链接。
将数据写入 CSV 文件

book_info = {…}: 将提取到的书籍信息组织成字典格式。
csv_writer.writerow(book_info): 将字典中的数据写入 CSV 文件的每一行。
print(book_info): 打印当前书籍信息,供调试用,确保爬取的数据是正确的。
控制请求间隔

time.sleep(1): 暂停 1 秒,避免频繁请求导致 IP 被封禁。
关闭文件
f.close(): 确保在数据爬取完成后关闭文件,保存数据。
成功爬取结果如下:

结语
本方案已在实际业务中实现日均千万级数据采集,相比传统方案提升3倍效率的同时降低40%的运维成本。未来可扩展方向包括:
-
结合LLM实时生成反爬对抗策略
-
利用HAI弹性扩缩容应对突发流量
-
构建自动化验证码破解工作流
通过持续融合AI与云原生技术,智能爬虫系统将突破传统数据采集的边界,为企业打造真正的数据智能基础设施。
写在最后:更多AI学习资料请添加学习助手领取资料礼包

视频学习资料:
从0开始开发超级AI智能体,干掉所有重复工作
- 基于字节的coze平台从0到1搭建我们自己的智能体
- 从coze到超级创业个体:2025是AI Agent大爆炸的元年!
- 搭建智能体的七大步骤:需求梳理、软件选型、提示工程、数据库、构建 UI 界面、测试评估、部署
- 你的智能体如何并行调用多个通用AI大模型?
- 实战案例:AI Agent提取小红书文案以及图像进行OCR文字识别并同步写入飞书多维表格
- 实战案例:AI Agent提取抖音爆款短视频链接中的文案,基于大模型和提示词完成符合小红书风格和作者特点的文案仿写
DeepSeek AI Agent +自动化助力企业实现 AI 改造实战
- DeepSeek 大模型的本地部署与客户端chatbox本地知识库
- 程序员的跨时代产品,AI 代码编辑器cursor深入浅出与项目构建
- 软件机器人工具影刀RPA工业化地基本使用
- 影刀RPA WEB自动化采集Boss直聘岗位信息并存储
- 影刀AI Power与DeepSeek 工作流构建影刀AI Agent
- AI HR实战:结合影刀RPA+DeepSeek AI智能体,实现智能自动招聘机器人
大模型技术+ 数字人+混剪造就副业王炸组合
- 数字人的概念与价值
- 当前数字人的时代背景
- 数字人的市场需求
- 数字人与自媒体的关系和发展路径
- 商业化数字人的变现之路
- 基于coze搭建数字人超级智能体
- 大模型技术+数字人+混剪=最强副业方向
- AI大模型与数字人造就3分钟获客300条精准线索
- AI副业接单渠道与流量变现
- 程序员开发的AI数字人实战

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)