谈谈Llama4 和DeepSeek GRM
四月一开始就这么多好玩的东西~, Llama 4凌晨突然发布, 不知道是不是要和其它模型错峰. 然后还有一篇DeepSeek的RL的论文. 另外有一个港科大的Dream-7B做text diffusion也很好玩. 还有Anthropic的一些SAE后续的工作Circuit Tracing[1], AI Biology[2]好像大模型可解释性的特征提取的工作对外公开的只有Antropic, OAI
TL;DR
四月一开始就这么多好玩的东西~, Llama 4凌晨突然发布, 不知道是不是要和其它模型错峰. 然后还有一篇DeepSeek的RL的论文. 另外有一个港科大的Dream-7B做text diffusion也很好玩. 还有Anthropic的一些SAE后续的工作Circuit Tracing[1], AI Biology[2]好像大模型可解释性的特征提取的工作对外公开的只有Antropic, OAI以前发了一两篇Blog就没有对外披露了... 而国内好像还没有太多的人重视这一块...
本文先把Llama4和DeepSeek GRM的作业交了吧, Llama 4在长文本上有很多值得借鉴的地方,但是我个人觉得还是DeepSeek的NSA处理更加巧妙一些. 另外Scale-Softmax构建自适应的温度也是很值得借鉴的. 然后DeepSeek GRM在强化学习的Reward Model处理上,通过模型产生Self-Principal然后构建评价体系最终生成评论(Critique)的处理非常干净优雅, 也很值得去学习.
1. Llama 4
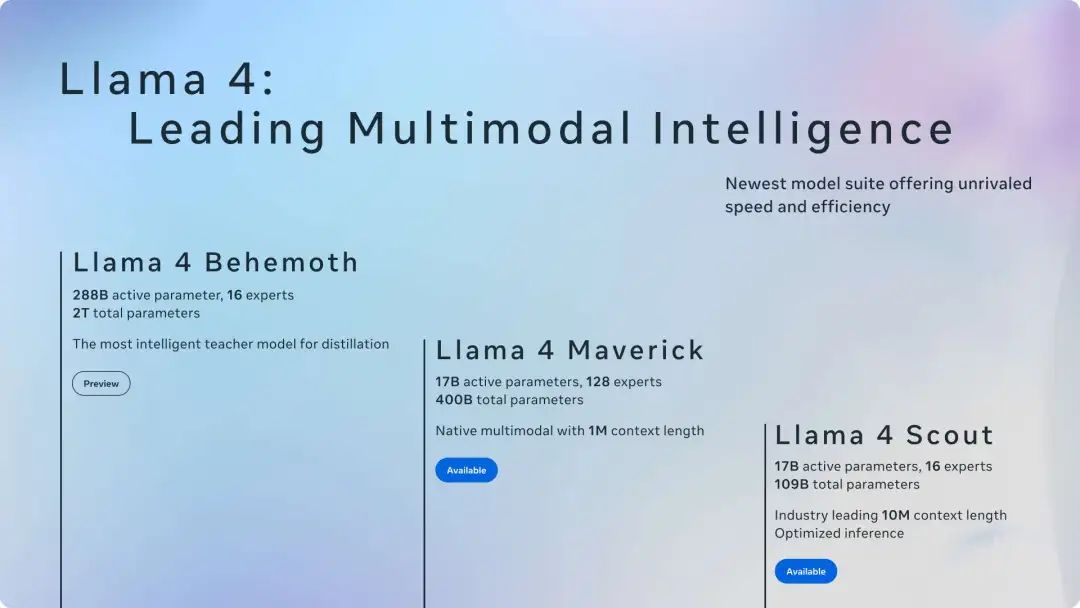
Llama 4是第一个开源的原生多模态的MoE模型. 首批发布的是Llama 4 Scout和Llama4 Maverick, 还有一个更大的2T参数的Llama4 Behemoth
1.1 模型参数和结构
Llama4 Scout是一个109B参数的模型, 激活参数17B, 每层总共有16个专家. ContextLength达到了10M. 而Maverick激活参数也为17B, 总参数规模达到了400B, ContextLength为1M. 对比了一下两个模型的参数:
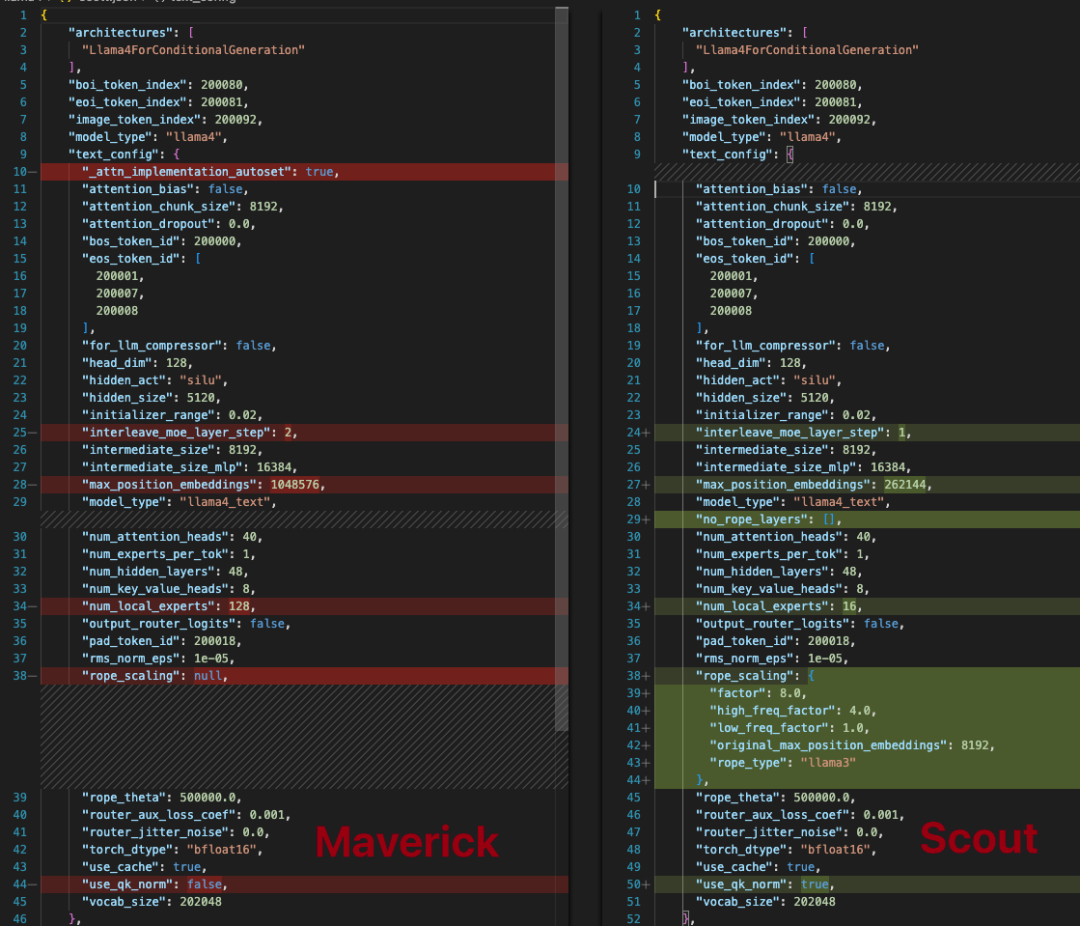
模型层数都为48层, 相对于DeepSeek-V3更浅, 有助于提高推理时的TPS, 而hidden-dim为5120, 也是采用MHA有40个Head(head_dim=128),最值得关注的是MoE的实现. 从参数上看它采用了Sparse MoE和Dense MLP interleave的方式构建. MLP的中间层维度为16384, MoE则是8192. Scout的interleave_moe_layer_step为1,即MoE和MLP交替出现. 而400B的Marverick则是每隔2层换成一个MoE层,然后继续2层MLP. DeepSeek-V3的做法则是采用前3层Dense MLP后续全部为MoE.
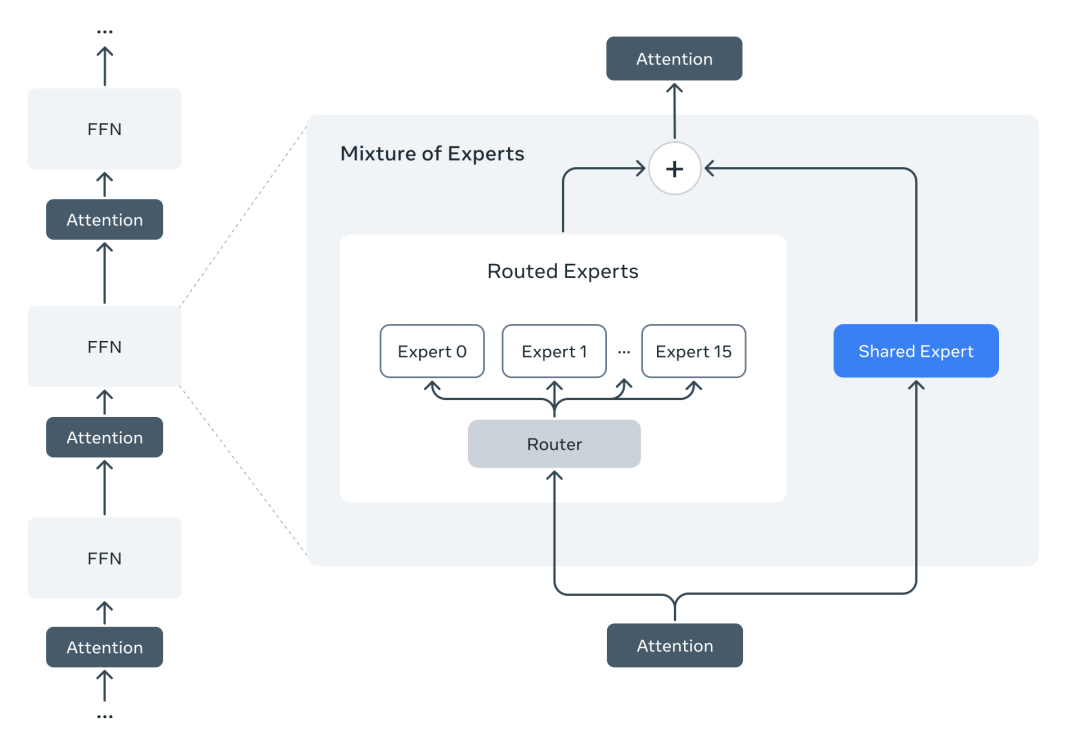
MoE实现上也借鉴了DeepSeek-V3的方式, 在Scout中有16个Routed Expert, Marverick有128个, 并有一个Shared Expert. 然后但是Activated Routed Expert 只有一个. 而MoE中间层的维度正好为Dense MLP的一半, 一个Shared和一个Routed Expert使得激活的参数和MLP是相同的. 因此Scout和Maverick都是17B的激活参数.
整个模型参数规模相对较小, 400B/109B也很容易放到单机里运行, 同时由于Activated Expert只有一个, 对于互联网络带宽和EP并行的需求也少了很多.具体的MoE Gating设计可能要等Llama4 Technical Report出来才能知晓了.
然后采用了Interleaved Attention Layer避免位置编码和Inference time tempreature Scaling的方式构成iRoPE, 这个也是一个非常值得关注的点. 但是从模型的参数来看, 在Scout上依旧还是实现了RoPE,并且还打开了QK的Norm.
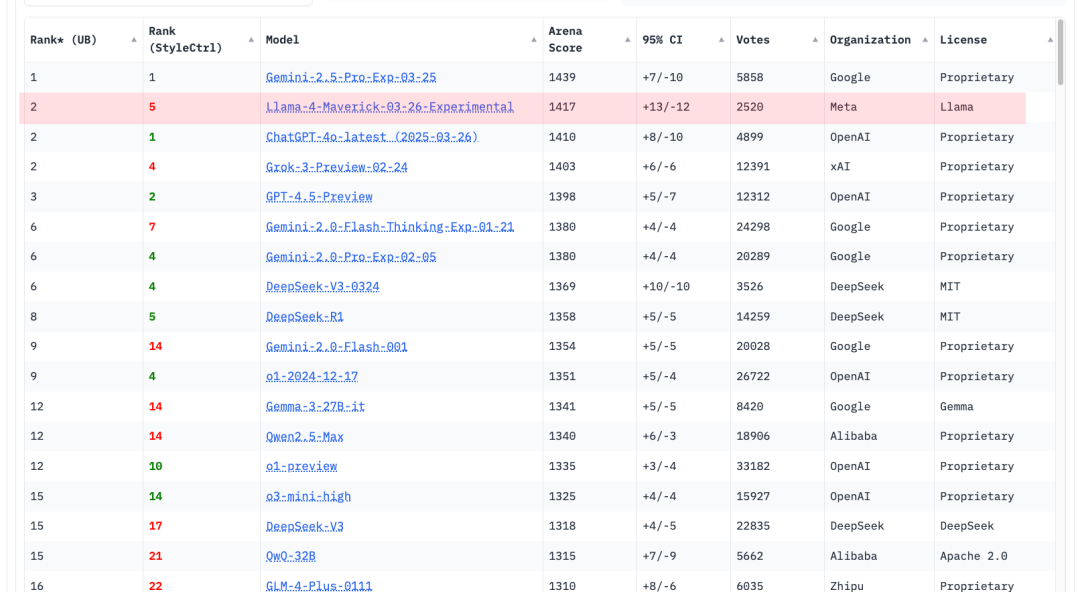
模型跑分的效果也是很不错的, Maverick在很多基准测试中击败了GPT-4o和Gemini 2.0 Flash, Coding等任务上也接近DeepSeek-V3的表现. LMArena上ELO分为1417 位列第二. 并且Meta还披露了正在训练的2T参数的Behemoth多个测试中超越了GPT4.5,Sonnet 3.7和Gemini 2.0 Pro.
总体来看, Llama4对推理是非常友好的, 模型层数浅, TPS会更容易做高, 然后激活参数比DSv3还少了一半, 然后单个Expert的参数规模也挺大的, 采用1-Shared+1-Routed的方式通信压力也不大, ContextLength也很长,对于后续应对一些Reasoning的任务也挺好的. 然后还有原生多模态的支持. 同时参数规模400B也可以更好的进行单机部署. Interleave的MoE+MLP应该也可以更好的做一些Microbatch的Overlap. 但是也有一些缺点, 只有一个Activated Expert在训练的过程中是否真的能够有效的训练并保持专家的专业性, 这一点我是有一点怀疑的. 当然这也是训练的基础设施上的一些问题导致的妥协.
1.2 预训练
Llama3的预训练Token为15T,而在Llama 4翻倍了增加到了30T, 大概率估计是一些多模态的内容. 多模态采用Early Fusion融合了文本和视觉标记到统一的模型主干中, 这样能够训练大量的未标记的文本/图像和视频数据. 视觉编码器(Vision Encoder)是基于MetaCLIP的一个改良版本, 通过冻结Llama模型参数来独立的训练使得Vision Encoder, 它是一个34层的模型, 参数如下:
"hidden_size": 1408,
"image_size": 336,
"intermediate_size": 5632,
"num_attention_heads": 16,
"num_channels": 3,
"num_hidden_layers": 34,
"patch_size": 14,
然后预训练精度也采用了FP8, 超大杯Behemoth训练时采用了32K个GPU, 应该都是H100的那个集群扩容到32K个GPU进行训练的. 每个GPU 390TFLOPS, 不过估计MFU还需要混合精度训练时的具体实现.
然后提了一句在“Mid-Training”阶段, 采用了一些新的方法包括使用椅子的专用的数据集进行长上下文扩展等.
1.3 后训练
Llama4的后训练也有很多看点, 由于本身是一个多模态的明星, 最大的挑战是多模态书如下, 在推理和对话能力上如何保持平衡. 整个后训练的流程为先做SFT, 然后在线的强化学习, 最后做了一些DPO. 然后有一个关键的教训是SFT和DPO会限制在线RL的探索, 在推理/编码/数学任务上带来影响. 然后主要采用了Model as a Judge的方式删除了50%标记为Easy的数据, 并对剩余较难的数据进行了轻量级的SFT. 随后在多模态RL时, 选择更难的Prompt. 然后还构建了一种持续Online RL的策略, 在训练模型和使用它来持续过滤和仅保留中等到困难难度的提示之间交替. 最后通过一些轻量级的DPO来处理与模型响应质量相关的极端情况. 三个模型的相关性能如下表所示
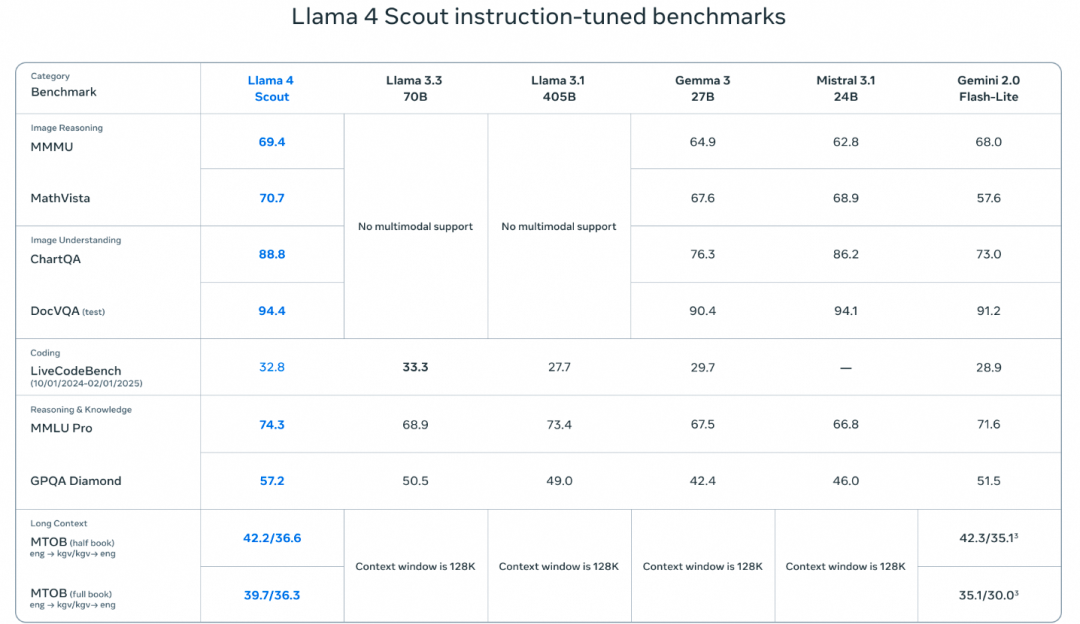
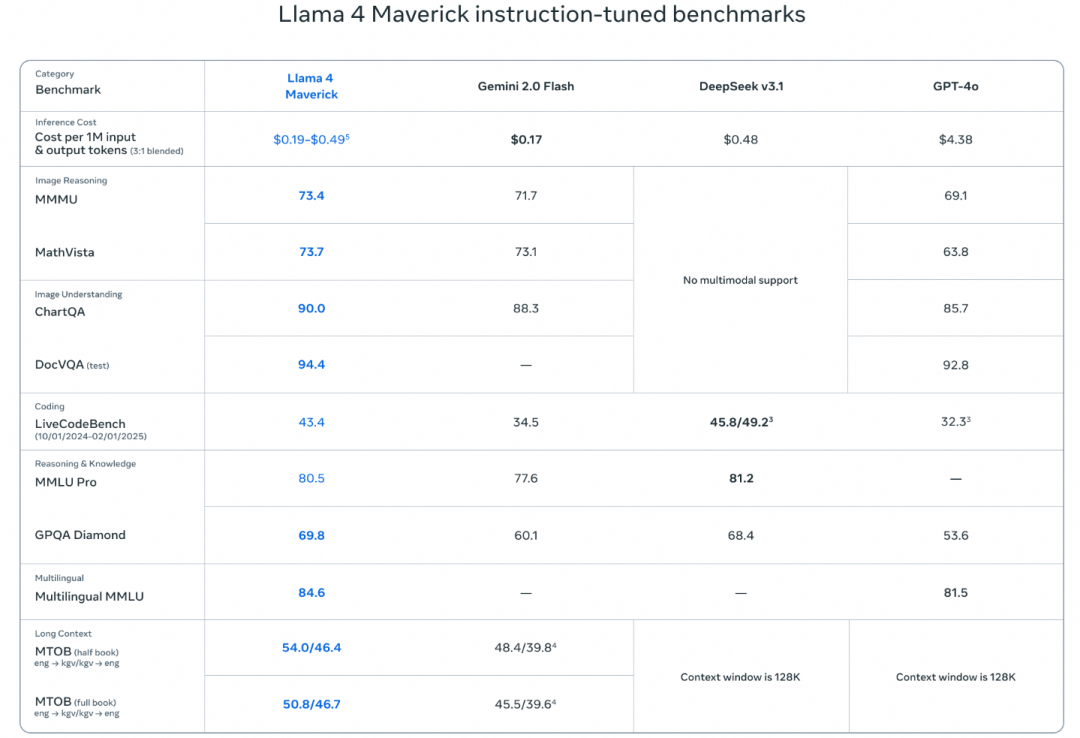
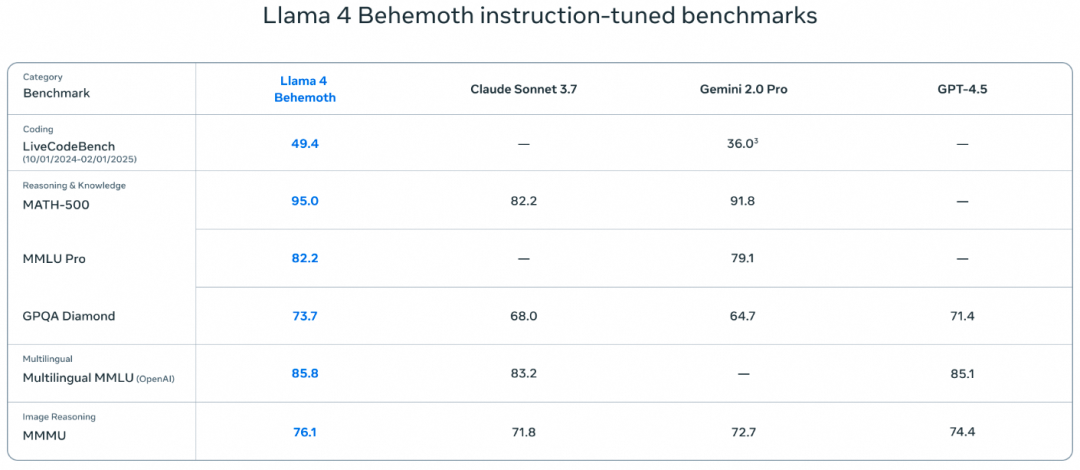
1.4 长文本iRoPE
在Scout中max_position_embeddings为256K, 而Marverick为1M. 但是Scout通过iRoPE将其扩展到了10M, 而且主要场景很清楚, 针对多文档摘要/推荐系统这些解析广泛的用户活动,以及大量的代码库进行推理等任务. 主要是采用了交错注意力层(Interleaved Attention Layer)并避免位置编码. 具体引用了论文《The Impact of Positional Encoding on Length Generalization in Transformers》[3] 这篇文章是讨论位置编码问题很全面的一文.
首先它介绍了在transformer中使用位置编码由来是相对于RNN这些顺序模型, transformer的并行计算需要利用位置编码来帮助词序编码.
Recently, asking models to emit
intermediate computation stepsinto ascratchpad, also referred to as chain-of-thought, has been adopted to improve the length extrapolation in Transformers (Nye et al., 2021; Wei et al., 2022b).
然后Interleaved Attention实际上是将一些内容放入到ScratchPad内计算Attention? 例如作者构建了由<input>, <computation>, <output>,<variable_update>, <remaining_input>构成的ScratchPad

另一方面, 还控制了推理阶段的Softmax的Tempreture, 文章引用的是《Scalable-Softmax Is Superior for Attention》[4], 其实更值得参考的一篇文章是来自于Google Deepmind的《softmax is not enough (for sharp out-of-distribution)》[5]这个结论挺有意思的,也就表明softmax从根本上无法在所有可能的输入上维持稳健的推理行为.

然后通过自适应的温度似乎可以? 下图是一个未调整温度的,

而通过自适应调整温度的图如下, 直观感觉是否是解析力更好了?
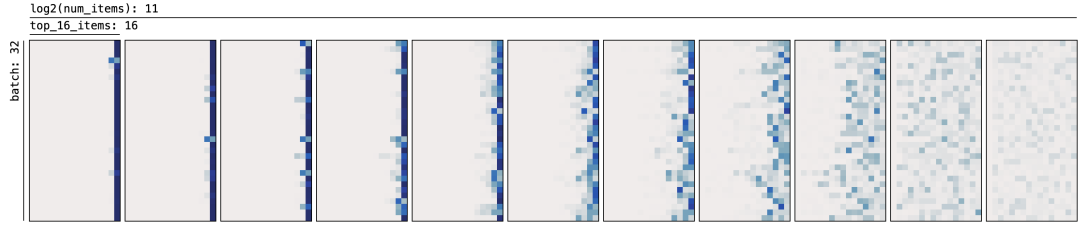
回到正题, Llama 4做了两个模型的NiH测试, 文本类模型在10M Context上Scout表现的很好, 视频也是. Maverick测试1M也挺好的.
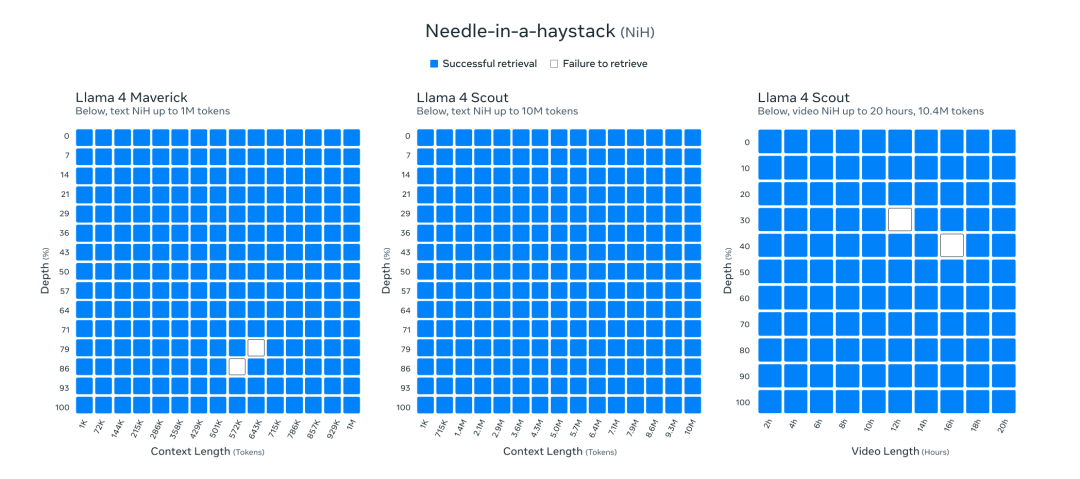
2. DeepSeek GRM
来自于4.3发布的论文《Inference-Time Scaling for Generalist Reward Modeling》[6]文章最精彩的部分在这个图
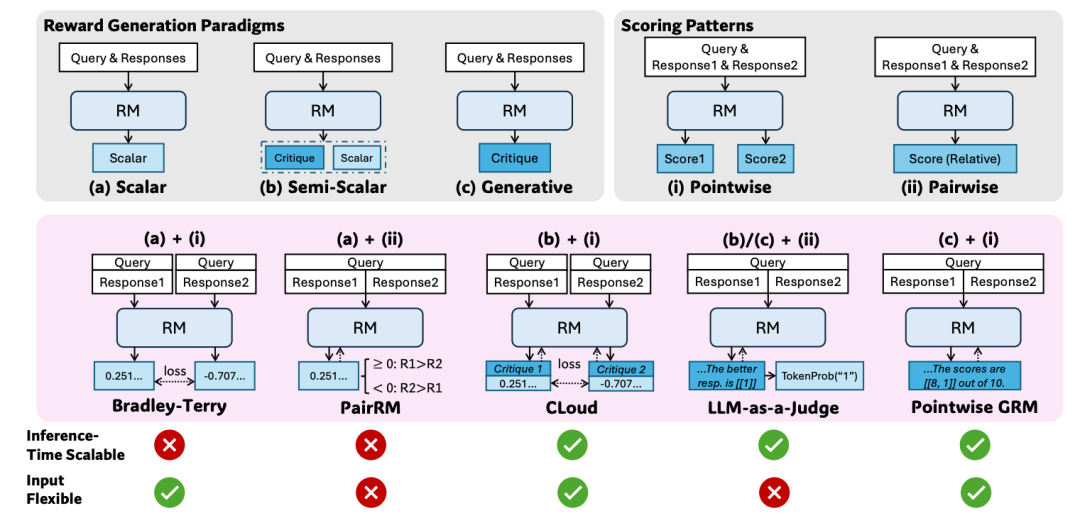
对于强化学习, 核心是评判多个答案的好坏, 因此Reward Model的设计就很关键了, 然后作者将Reward生成的范式(Reward Generation Paradigms)分为了3类, 也就是图中的模式(a),(b),(c).
-
(a)标量(Scalar): 这种范式对给定的Query & Response计算出一个标量分数作为奖励.
-
(b)半标量(Semi-Scalar):这种范式类似于购物软件的评论, 不光要采用标量值打分,还有一段评论, 可以用来提取给出该打分的原因.
-
(c)生成式(Generative): 这种方式会生成一段文本式的评论(Critique)作为奖励, 奖励值可以从文本内提取, 当然也可以通过一些格式要求,把奖励的分值写在评论中.
然后是评分模式(Scoring Pattens)
-
(i) PointWise: 独立的给每一个回复评分
-
(ii)Pairwise: 对两个回复之间进行相对比较评分.
然后是这几种方法的组合, 其实最关键的是最后两行. 基于标量的区分度有限, 无法做到Inference-Time Scale, 然后对于回复的多种情况(单个/多个评分)即Input Flexible, 而在搜索的过程中Pair-Wised无法实现对单个和多个回复(两两Pair-wised也很复杂)的比较. 基于这些原则最后选择了PointWise GRM(c)+(i)的方式.
2.1 RM范式
然后基于这几种模式, 有五种范式
2.1.1 Bradley-Terry
Bradley-Terry 模型是对象之间成对比较结果的概率模型 。给定从某个总体中提取的一对项目 i 和 j,它估计成对比较 i > j 结果为真的概率. 但是这种方式的最大问题是只有一个标量的值作为结果, 说实话就跟大厂打绩效一样的, 一个大团队很多人, 如何打3.5+和3.75, 甚至3.5-和3.25对管理者而言都是非常难处理的. 因此当模型在Inference-Time Scaling的时候, 产生了大量的Response后, 单个标量值其实很难比较.
2.1.2 PairRM
同样采用标量值打分, 但是更难的是还要PairWised去比较, 但对于一个大团队的管理者还要对团队成员的绩效两两比较, 确实太难了, 因此Input Flexible这一项也被打了X.
2.1.3 CLoud
Semi-Scalar是一种比较自然的评价方式, 既要有一个量化的分值, 又要有一段评论. 很多购物软件的消费评价都是这样的方式. 跟绩效中的管理者反馈一样, 不光要绩效打分还有一段管理者评价, 看上去Inference Time Scale因为评论的存在能够获得更多样性的结果(类似于管理者对绩效进行预期管理和解决绩效争议的), 同时由于PointWise的分值也不需要横向对比, 对Input Flexible是友好的.
但是, 测试结果显示CLoud的方法性能其实很拉垮, 随着Sample Reward的增加它并没有很大的提升. 其实这个标量的评分影响还是很大的..
2.1.4 LLM-as-a-Judge
RM生成的内容带有评论(Critique), 但是模型只是简单的利用Token概率(TokenProb),即评论中出现[1]更好的内容来选择, 虽然这样评论的方式支持Inference Scaling扩大的很多输入的评论, 但是比较评判还是PairWise的
2.1.5 PointWise GRM
这是DeepSeek这篇论文采用的方式, 模型在RM只产生评论, 然后对这些评论进行Point-Wise的评分.最终在测试中这种模式能够很好的Scaling
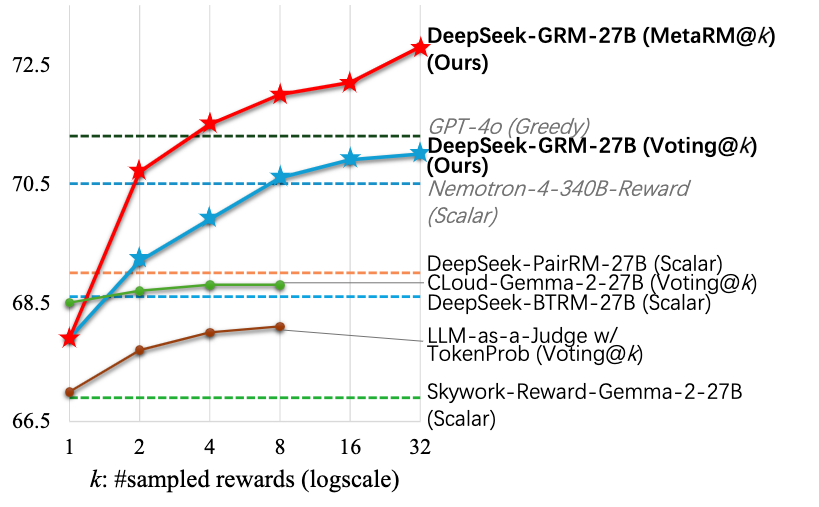
2.1.6 小结
其实本质的问题是在Inference-Scaling的时候, 我们期望模型尽量输出多个备选的Response然后进行比较, 而基于标量打分的机制并不好, 多次采样的答案例如一个是3.73 另一个是3.68, 其实也很难评判3.73和3.68到底哪个更好, 并且大量的备选Response标量分数值的区分度相对较小. 而基于Critique的方式就相对来说好很多, 有了更详细的评论可以做更多样性的处理了比对.
另一方面是Input Flexible, 针对多个Response进行Pair-wised比较其实也是很难的, 因此还是需要选择PointWise打分的方式.
针对Semi-Scalar的方法, 似乎在测试中CLoud的表现并不好, 个人估计主要还是这个标量值的影响导致的. 例如评价一篇生成的作文, 通常像高考作文那样仅打一个分数还是会比较容易产生争议的. 而Generative-GRM的方法,我觉得本质上是Semi-Scalar变成了一种基于文本的Vector/Matrix的比较, 评论中会从文章的艺术性/行文流畅度/新颖性等各个维度进行评判. 注意关键的问题是在GRM中的Generalist,通过这种评论的方式使得输出的对比有了更多样性的结果, 例如针对代码类任务, 可能会基于是否能编译/运行效率/输出结果美观度等几个维度评判, 而针对数学类任务会基于证明的正确性/证明过程是否简洁直观等几个维度评判, 通过这样的方式解锁了针对不同任务的泛化能力.
2.2 SPCT
正如前文所述, Generalist RM 需要在特定领域之外生成高质量的奖励,其中奖励的标准更加多样化和复杂,通常没有明确的参考或基本事实. 对于一般领域,采用原则(Principals)来指导奖励生成而不是人工规则(Rule-based), 从这一点来看算是DeepSeek从R1向R2进化的一步, 使得任务更加泛化.作者基于GPT-4o和Gemma-2-27B做了一些实验, 由模型自己产生一些原则并进行过滤后的生成效果还是有显著的性能提升.
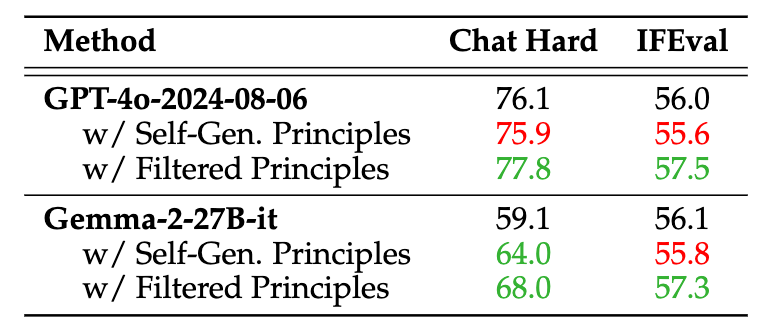
作者把这种方法称为 Self-Principled Critique Tuning(SPCT),由模型自己构建原则对Critique进行评判. SPCT有两个阶段, 如下图所示:
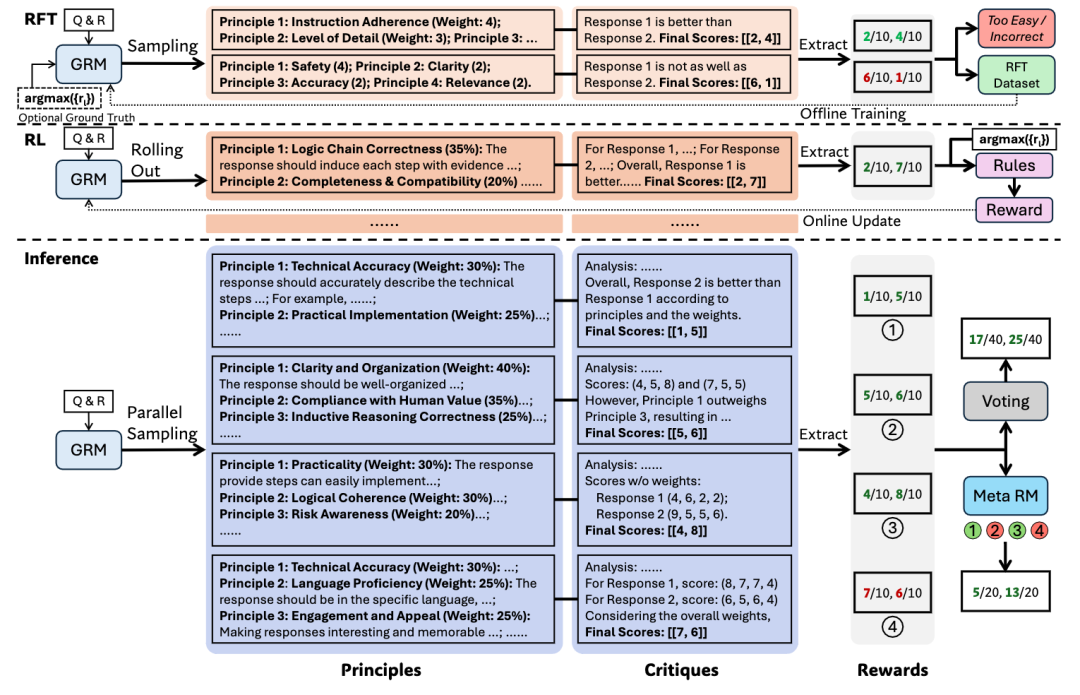
首先是一个Rejective Fine-tune作为cold-start, 基于生成的原则产生评论,并在内部包含一个基于原则的打分向量, 然后构建RFT的数据集. 然后是一个Rule-Based Online RL. 基于自己生成的Principal(Self-Principal)对输出的结果进行评论, 并且对各个原则打分和汇总构建FinalScore. 然后再采用Rule-Based RL生成Reward进行模型的在线更新迭代.
最后下半部解释了推理执行的行为. 可以看到它会并行Sample并产生多个Principal和基于这些Principal的评论, 最终得出多个Sample的point-wise Reward, 然后采用Voting或者MetaRM的方式选择. 一些消融实验和测试结果:
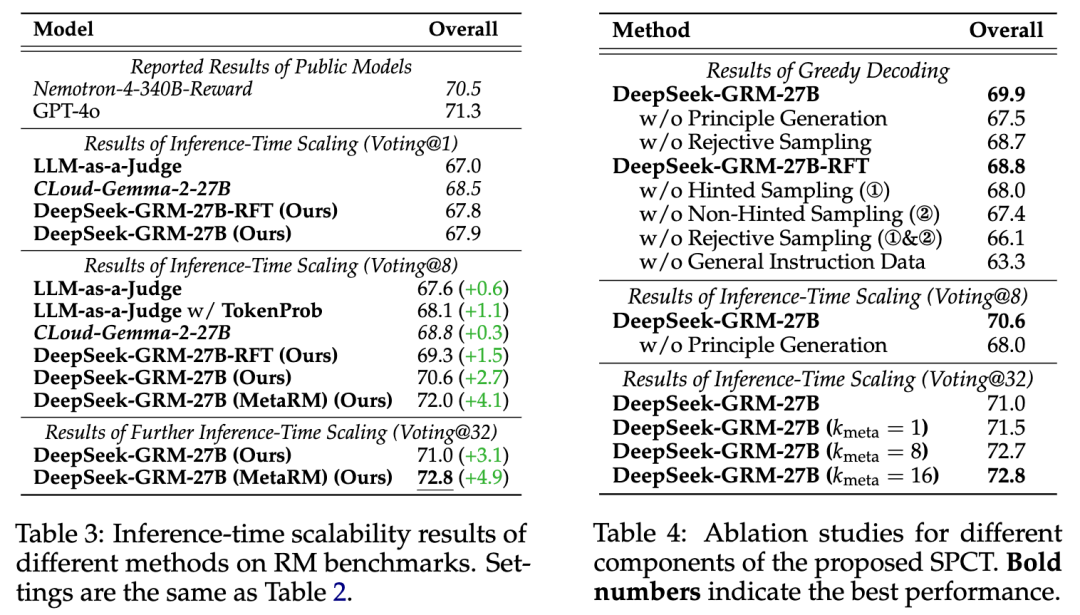
2.3 Scaling
最后作者还做了一些Scaling的测试, DeepSeek-GRM-27B 的Inference-time和Training-Time Scaling性能,通过使用不同大小的 LLM 进行训练后。模型在 Reward Bench 上进行了测试,结果如图所示。使用 32 个样本 DeepSeek-GRM-27B 的直接投票可以达到与 671B MoE 模型相当的性能,Meta RM 引导投票可以在 8 个样本下获得最佳结果,证明了 DeepSeek-GRM-27B 与缩放模型大小相比推理时间缩放的有效性。
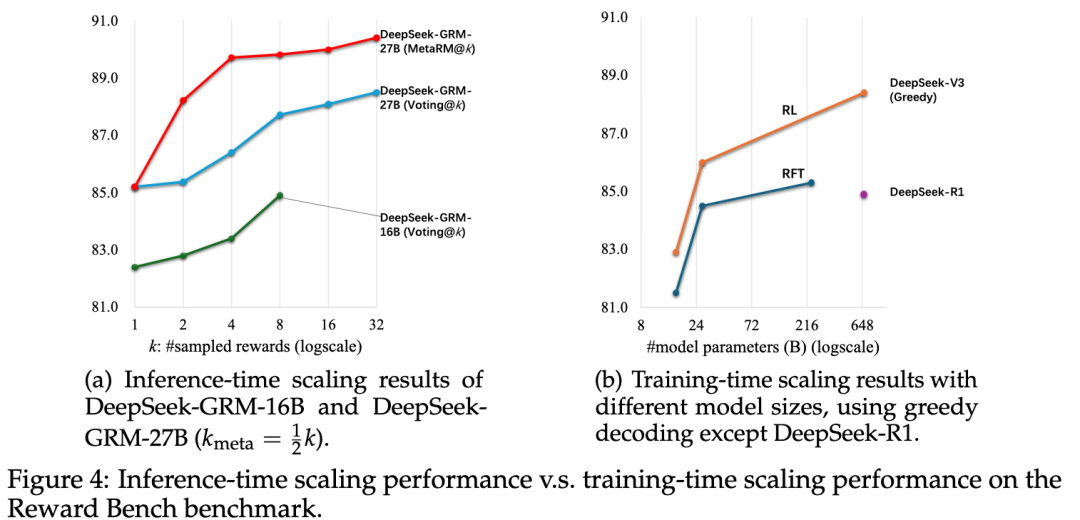
此外,还使用DeepSeek-R1下采样对300个样本做了一个有趣的实验,并发现其性能甚至比 236B MoE RFT 模型更差,这表明为推理任务扩展长思维链并不能显着提高Generalist RM 的性能。
2.4 小结
整体来看DeepSeek这篇GRM的论文工作还是非常干净直接的风格, 针对通用的Reward Model设计上采用了模型自己生成Principal的多维度打分评价体系,并根据这些生成的原则来产生评论, 并基于评论给出最终的Point-Wise打分. 通过这样的Reward Model设计非常巧妙的提高了模型本身的泛化能力. GRM这样的通才(Genralist)奖励模型在MetaRM的指导下, 显示出了很好的Scaling, 对未来的DeepSeek-R2充满了期待~

一、大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!

二、如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)