Deepseek项目如何落地?落地中有哪些需要考量?落地后维护怎么办?【大模型学习笔记】大模型小知识-汇总。
32B就是320亿参数,现在有1.5B,7B,8B,14B,32B,70B,671B的模型,除671B以外都是蒸馏出来的。对于使用者的体验,输出8-10的Token是最低人类可以接受的底线(类似于每秒24帧的视频),比较舒服的的体验是输出15Token往上(类似于每秒30帧的视频),也就是个正常水平。我身边的小伙伴自己写了个脚本,做并发测试,如果绕过管理工具的鉴权和数据(别问我这是啥,我也是初学者
最近跟风研究大模型及相关开源软件,一边学一边记笔记,以防日后想不起来了。
2025年2月22日笔记
知识点1:
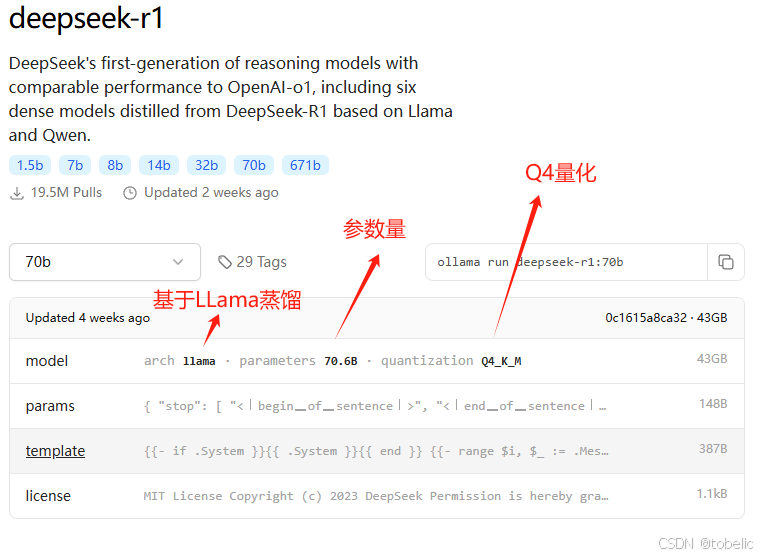
Deepseek大模型的命名规则,例如:DeepSeek-R1-Distill-Qwen-32B-Q4_K_M
deepseek-r1:模型名称
Distill:代表蒸馏过
Qwen:用千问蒸馏的,70B用LLama蒸馏的,只有671B是使用Deepseek2蒸馏的。只有671B具有MOE架构(MOE是Deepseek独有架构,所以说只有671B才能叫做Deepseek),要体验真正的Deepseek,只能使用671B参数量
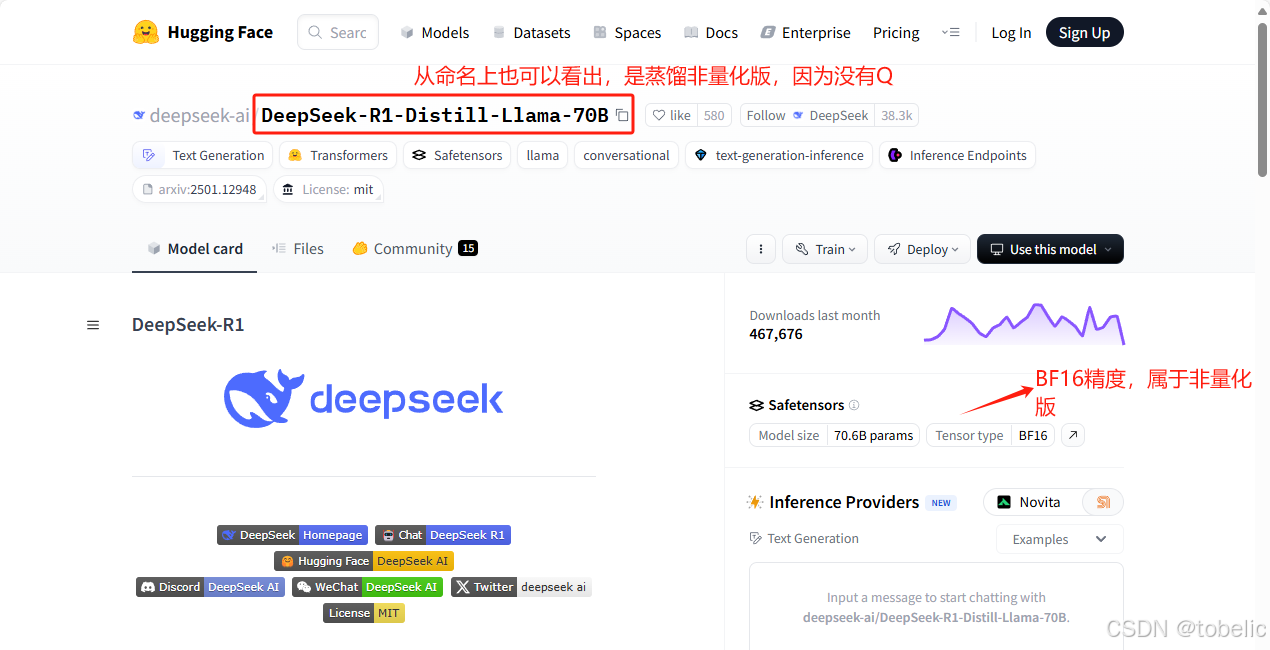
32B:Billion的缩写,模型的参数量。32B就是320亿参数,现在有1.5B,7B,8B,14B,32B,70B,671B的模型,除671B以外都是蒸馏出来的。671B有蒸馏版和未蒸馏版。如果看到FP16、BF16、BF32等字眼,这是模型的计算精度,代表着这个模型很牛,消耗的资源也很多。
Q4:代表Q4量化版,其他还有Q1-Q8等等,种类繁多。数值越大消耗资源越多,模型越聪明。补充:现在有IQ1、IQ2等,I代表什么不知道。
K、M:不是很清楚,太深奥了,应该跟格式有关。已知的有K、M、L、S、XS、XXS、XL等
知识点2:
模型参数量与显存的初步换算关系,以及量化做了什么。
| 精度规格 | 备注 | 参数大小 |
| FP32 | 标准训练精度,也是大模型训练的最常用精度 | 4字节/参数 |
| FP16 | 半精度浮点:可以减少内存占用和计算成本,但是会损失结果质量 | 2字节/参数 |
| BF16 | 全称bfloat16:和FP16类似,但更适合深度学习 | 2字节/参数 |
| FP8 | 8位浮点数,进一步压缩模型的精度浮点,适合加速推理 | 1字节/参数 |
| INT8 | 8位整数量化,将32位或16位浮点数转换为8位整数,减少存储和计算需求 | 1字节/参数 |
| INT4 | 4位整数量化,最常用的量化方案,进一步减少模型大小,但是会随时更多的模型精度 | 0.5字节/参数 |
注意,量化过程不是简单的按照比例压缩,与模型原始精度是无关的,而是将参数重新映射到更低的比特数。
例如:
FP32初始情况下,占用4字节,量化后是0.5字节
FP32初始情况下,占用2字节,量化后是0.5字节
从以上可以看出,无论原始模型占用多少字节,在同等量化后占用的空间都是一样的。
模型大小的计算:
模型大小=参数量*每参数占用字节
例如:
1B=10亿参数量,在FP32精度下每参数占用4字节
10亿*4字节/参数=40亿字节≈4GB显存空间
显卡在实际运行中,除了要一次性加载模型到显存,还需要一些空间来额外存储中间结果、梯度等数据。通常情况下,这些数据要占模型本身大小的20%到50%。由此可以推导出:
显存需求=模型大小*1.2~1.5
1B参数量对显存的需求:4GB*1.2=4.8≈5GB
70B的FP32模型对显存的需求:350GB显存
再来说量化,350GB的显存需求太大,如果使用Q4量化,模型参数占用从4字节降低到0.5字节,降低了8倍。也就是说350GB÷8倍=43.75GB,可以使用48GB显存run起来。
注:这里只是阐明模型的计算结果,并不考虑其他因素带来的影响。算是个最小配置吧,实际生产环境中还要考虑能耗、并发等问题。
知识点3:
如何看模型的浮点精度?
可以参考以下两个网站的数据:
1.ollama.com
2.huggingface.co
知识点4:
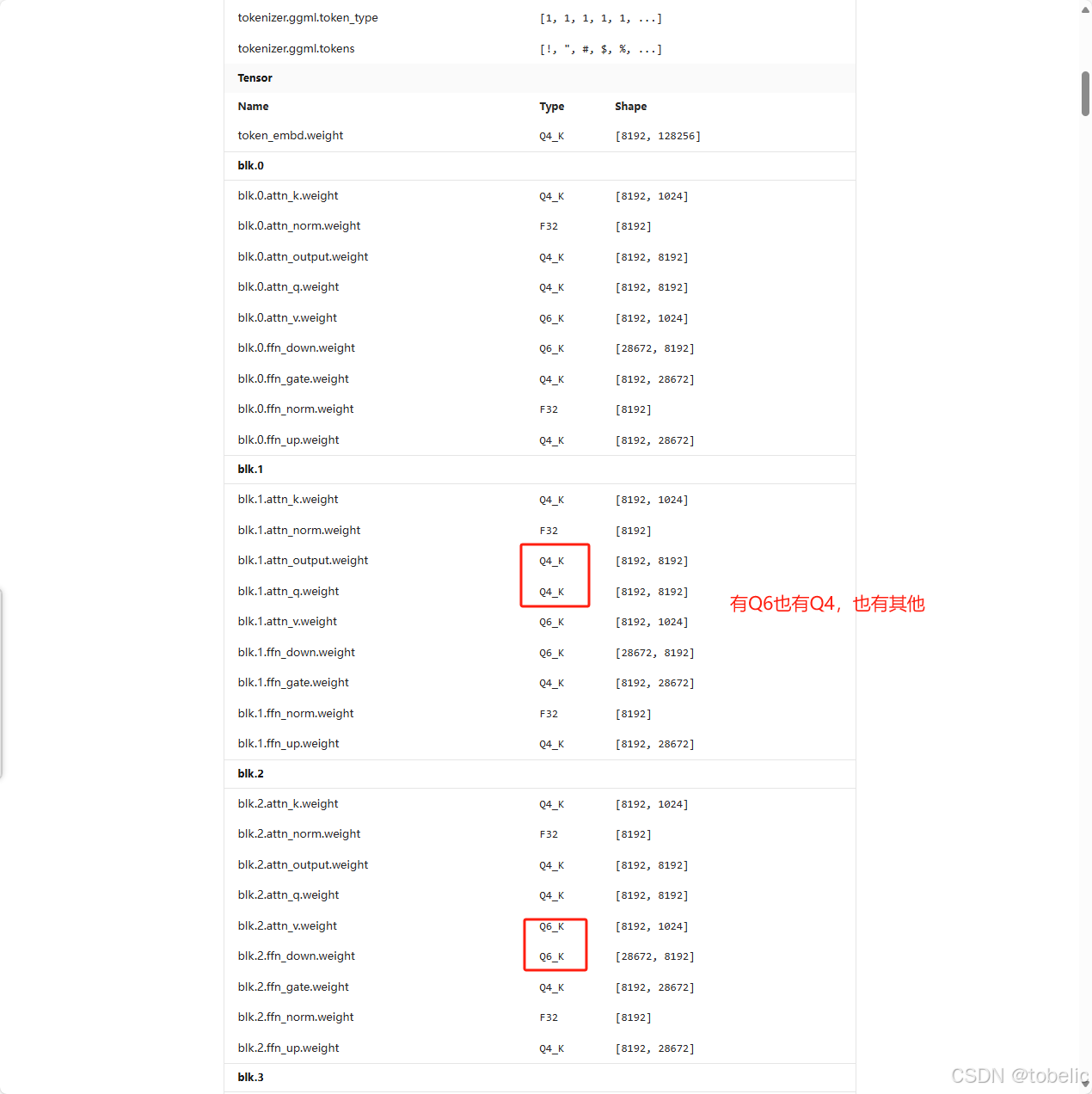
Q4量化是否就意味着都是Q4?
不尽然,从ollama的网站数据可以看出,每层的量化情况都不一样。可以参考:deepseek-r1:70b/model
知识点5:
框架是非常重要的,对于模型和硬件的性能发挥,起着至关重要的作用。不容忽视,例如:Vllm框架对于输出Token的速度有很大提高,由于Ollama框架和Ollama-Box等其他框架。
框架的管理工具,对并发有着很大影响。我身边的小伙伴自己写了个脚本,做并发测试,如果绕过管理工具的鉴权和数据(别问我这是啥,我也是初学者,没搞明白,你就听结果就行),并发性能有质的飞跃,同时失败请求降为0。
由此,大模型的优化比建设大模型更加重要。大模型不是预制菜,拿过来热一热就能吃。大模型非常考验厨师(信息化团队的技术功底)的厨艺。大模型是食材,同样的食材你做出来就是![]() ,别人做出来就是美味菜肴。
,别人做出来就是美味菜肴。
知识点6:
现在都想上本地大模型,不知道用什么配置。
1.在考虑硬件配置和架构之前,先看看自己的电力是否够用(租用IDC的除外)。紫光紫鸾1台8卡一体机的功耗大概是5.4KW,办公室内机房大都承载不了(还有很多其他原有设备和空调等)。
2.考虑使用人数与并发
3.考虑上哪个模型,模型不是参数量越大越好,还要可考虑是从哪个模型蒸馏出来,根据业务场景选择。现在网上很多算力租赁的平台,可以先采用租赁算力的方式测算好数据,再开干。
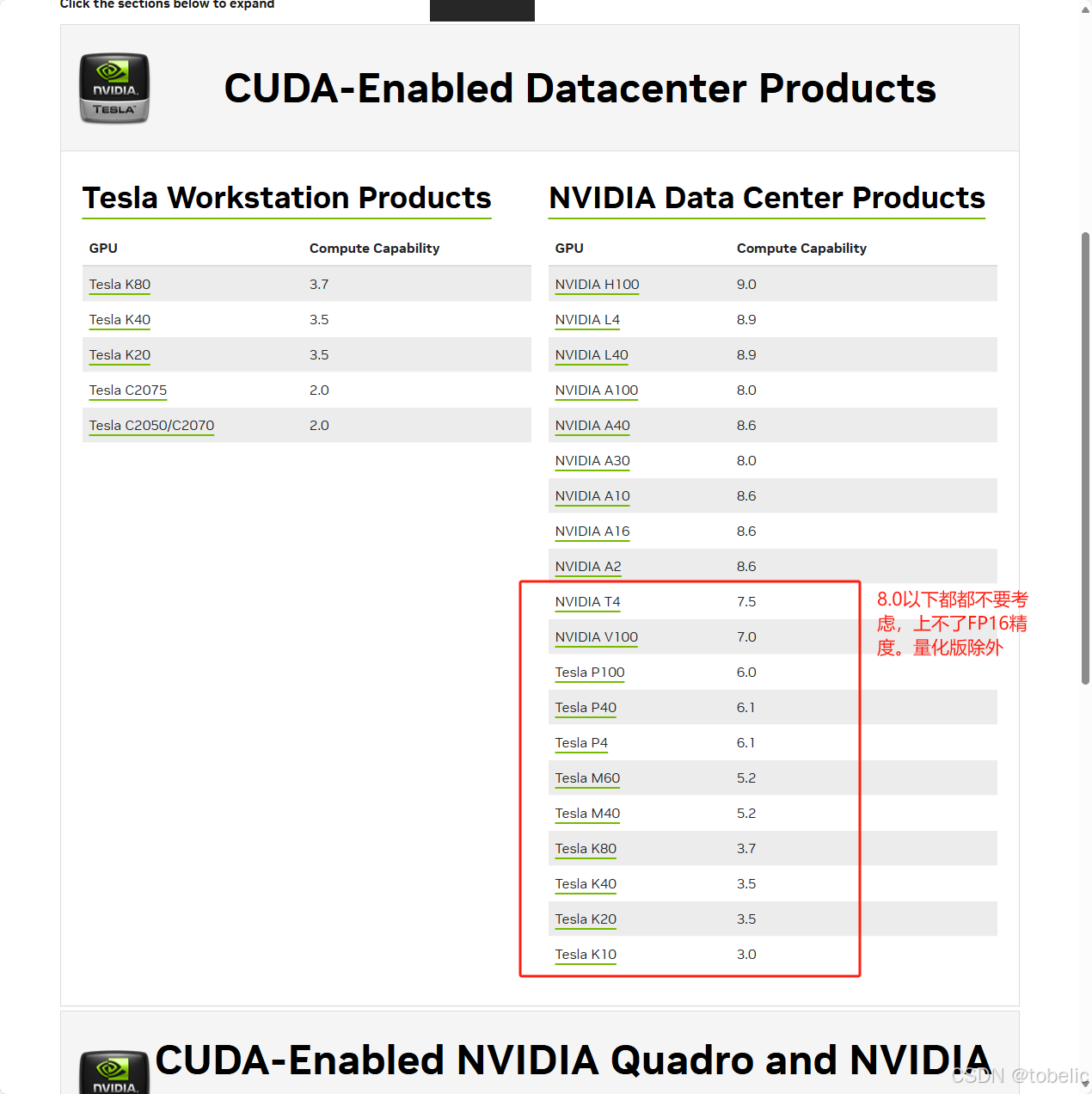
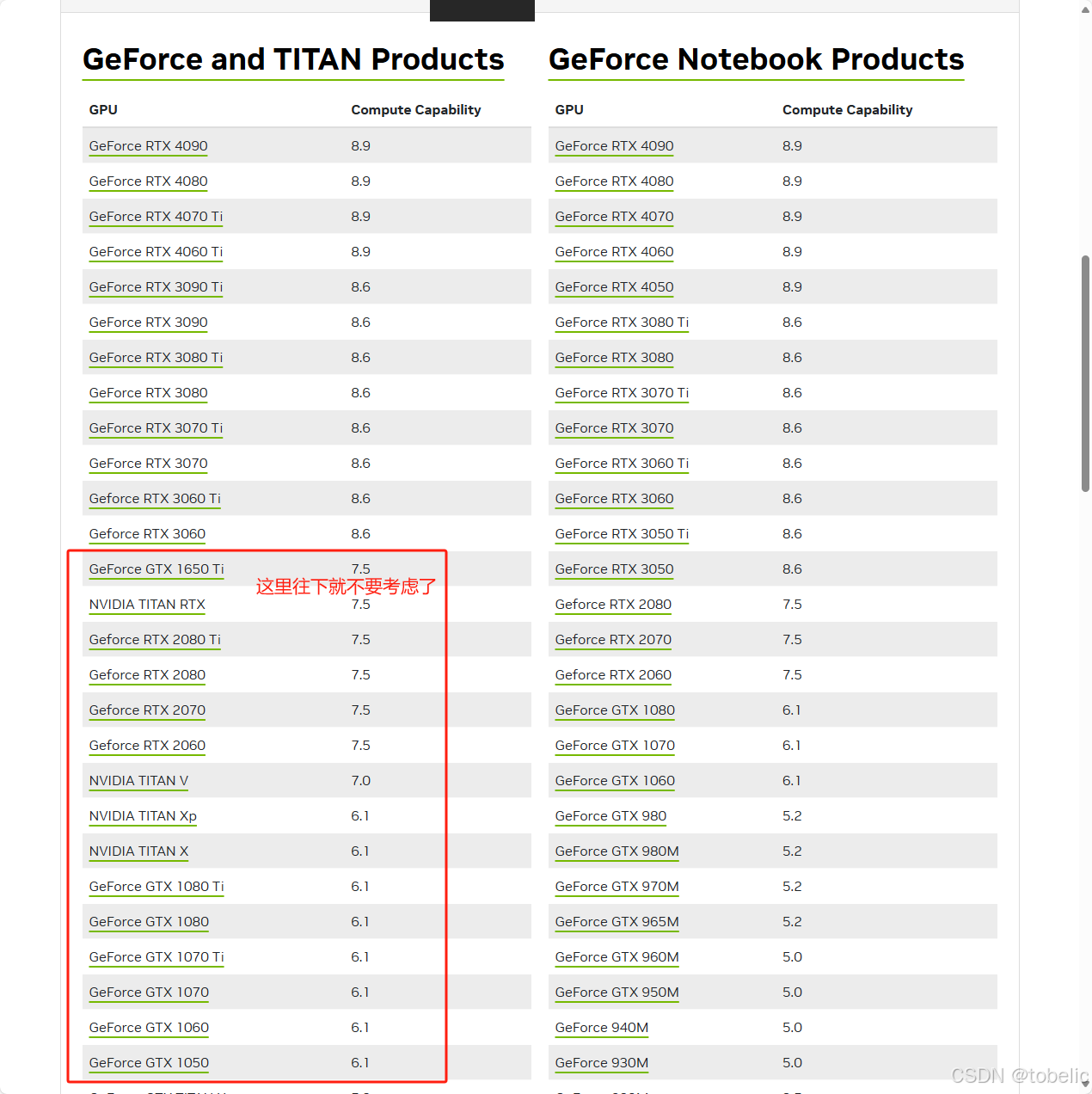
4.选择英伟达显卡时,要看显卡所能支撑Compute Capalibility(计算能力),英伟达网站上有关于计算能力的参数值,可以参考。CUDA GPUs - Compute Capability | NVIDIA Developer
起步3060,上不封顶
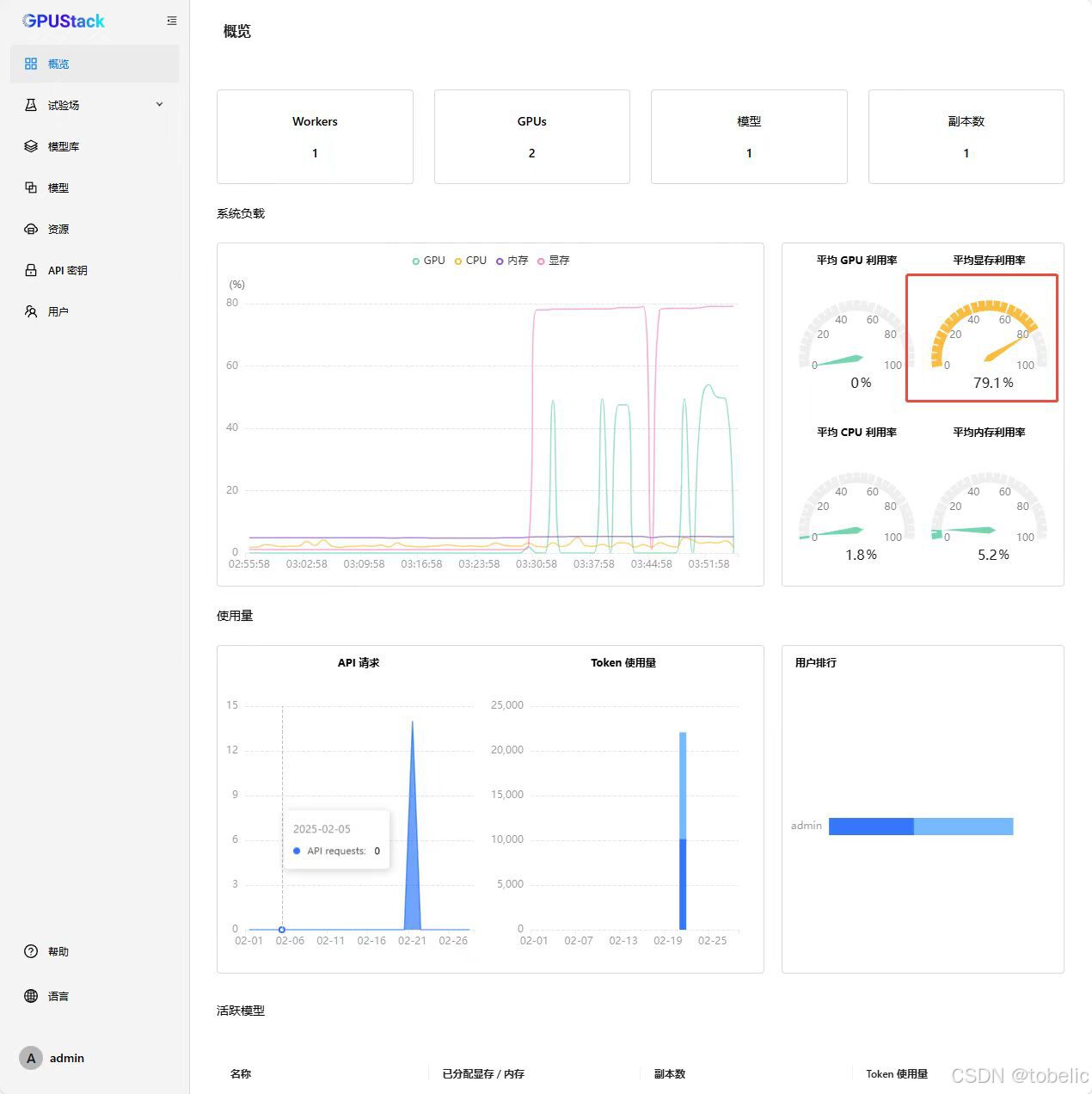
5.显存带宽是巨大瓶颈,我2块3090 24GB跑32BQ8模型时,监测GPU使用率时,基本维持在50%左右,估计显存带宽引起的瓶颈。
6.关于并发,这个是个玄学,从我实测数据看,2块3090 24GB只能同时回答4个问题。多出来的就要等着了,等其他问题回答完了,才能回答新的问题。同时我在测试,4卡2080TI 11GB是否会增加并发数。敬请期待
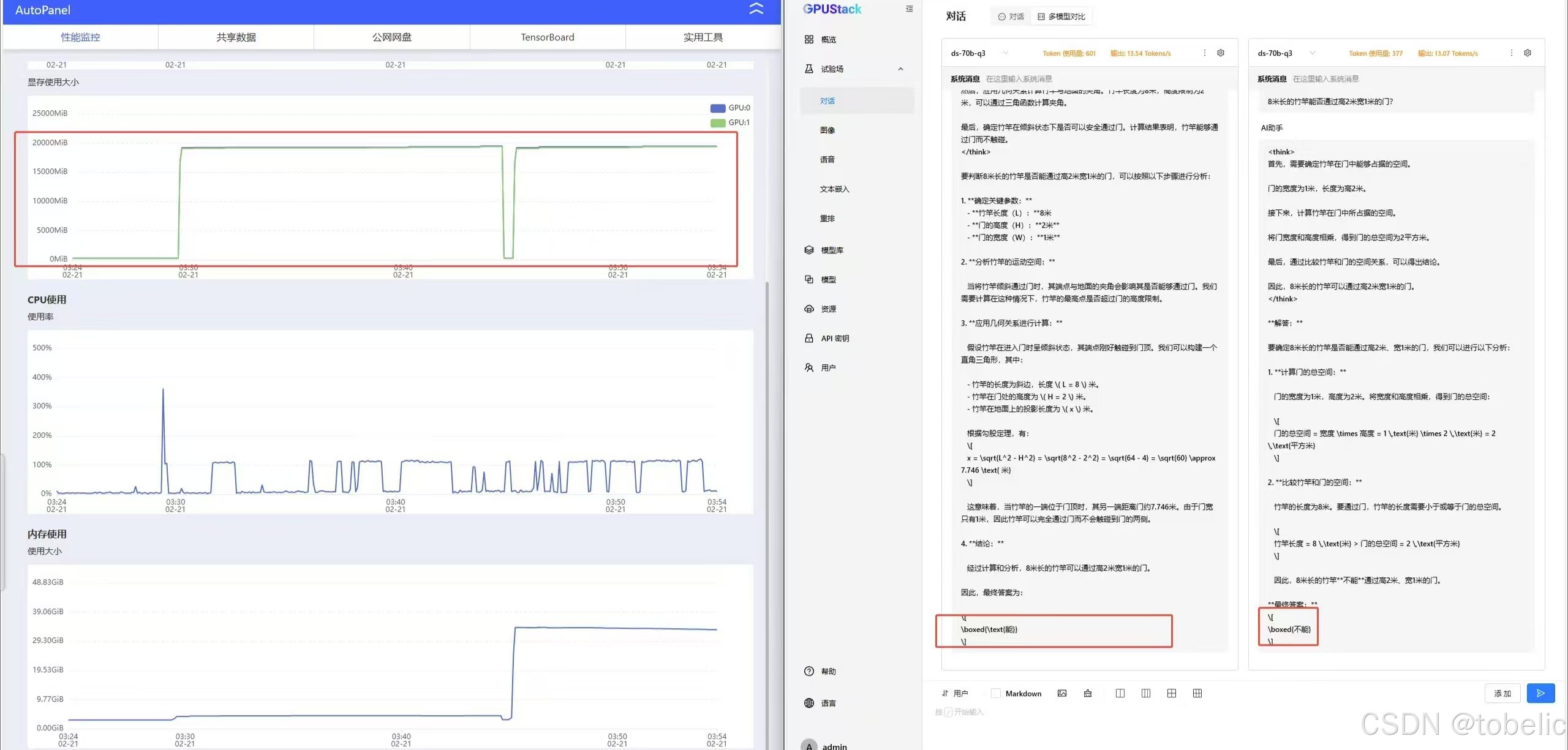
7.模型好不好有很多的维度,例如:对于中文语义的理解、输出Token的速度、上下文长度、思考深度、思考广度等等。然而,很多维度并不具有数字化评测标准,需要依靠人的主观判断。这就给模型、硬件的评测带来了很多不确定性。
8.关于评测:
并发多会降低每秒输出的Token数;
从逻辑推理、数学推理、常识推理、多步推理、批判性思维、创造性思维等方面准备问题,不能依靠单一问题、单一类型对模型惊醒评价;
评价维度:准确性、逻辑连贯性、解题完整性、复杂问题处理、常识合理性、创造性、响应时间等多个维度进行评分,最终得出结论。例如:
维度 | 评分标准(1-5分)
----------------|------------------------------------------------
准确性 | 结果正确性(数学答案精确到小数点后两位)
逻辑连贯性 | 推理链条完整度,是否存在逻辑跳跃
解题完整性 | 是否覆盖所有已知条件和隐含前提
复杂问题处理 | 对多变量问题的分解能力
常识合理性 | 是否符合现实世界的物理/社会规律
创造性 | 解决方案的新颖性和可行性
响应时间* | 生成完整回答所需时间(可选附加指标)
进阶标准:
1. 矛盾检测:能否识别题目中的潜在矛盾(如问题2的年龄悖论)
2. 假设检验:是否主动验证中间结论的正确性
3. 知识迁移:能否跨领域应用相关知识(如将物理原理应用于烹饪问题)
测试建议
1. 交叉验证:每个问题应测试3-5次,观察输出稳定性
2. 难度梯度:按简单→中等→困难分级(示例中问题1-3为初级,4-6为中级,7-12为高级)
3. 领域覆盖:建议补充专业领域推理题(如法律条文解读、医学诊断推理)
4. 异常处理:可加入包含陷阱或矛盾条件的题目,测试模型容错能力
着重观察输出稳定性,每个问题多次提问,会有不一样的结果。
9.关于输出Token的速度
对于使用者的体验,输出8-10的Token是最低人类可以接受的底线(类似于每秒24帧的视频),比较舒服的的体验是输出15Token往上(类似于每秒30帧的视频),也就是个正常水平。输出Token越快越好,这个非常影响体验。
10.模型性能与框架息息相关,这个我没有具体实测,但是从我身边的小伙伴处得知有很大关系。例如:Vllm框架对于输出Token的速度有很大提高,由于Ollama框架和Ollama-Box等其他框架。
10.给各位看官的忠告(尤其是决策者):
上本地大模型一定要谨慎,不要脑袋一热就上头,这时候需要下头,多听负面消息。这是一个长期的投资,不是一锤子买卖。上本地大模型容易,维护本地大模型看起来难,实则一点都不简单。维护成本是建设成本的10倍起步(这个是我胡诌的)。
从我测试的情况看,本地建设大模型不做任何优化时,经常会遇到各种各样的神奇BUG。这是由于大模型的整体架构过于复杂,并且大多基于开源框架、管理工具搭建而成。不是一班的学生,就要谨慎考虑。
最后再次提醒我自己: 大模型的优化比建设大模型更加困难重重。大模型不是预制菜,拿过来热一热就能吃。大模型非常考验厨师(信息化团队的技术功底)的厨艺。大模型是食材,同样的食材你做出来就是 ,别人做出来就是美味菜肴。
,别人做出来就是美味菜肴。
最后的彩蛋:
小伙伴说的人话:满八块肯定要一百个以上,玩这个671b部署两百万起步,还只是可以运行,双节点起负载均衡至少四百个,没这个投入就别瞎TM折腾所谓满血生产了,先找买单的棒槌吧,投四百多个,应用要多少钱投入开发出来然后还有效,就为几个逼人对话玩写小作文吗?都是忽悠傻子的。
有待学习的问题:
1.并发是个玄学,没有思路
2.多机多卡的架构中,到底用多少多机互联的带宽?25GB、100GB、还是IB网络。都是玄学

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)