
vLLM 等大模型推理性能监控:全方位策略与实践
随着大语言模型(LLM)的广泛应用,AI 推理应用的需求正以指数级的速度不断攀升。开源大模型 DeepSeek 以其出色的推理性能和高准确性,在开发者社区中迅速崭露头角,备受青睐。无论是企业级应用还是个人项目,DeepSeek 均已成为构建智能对话系统、内容生成工具以及复杂决策支持系统的核心驱动力。然而,随着模型规模的持续扩大以及推理请求量的急剧增加,无论是 DeepSeek 官方服务,还是各大云
概述:
随着大语言模型(LLM)的广泛应用,AI 推理应用的需求正以指数级的速度不断攀升。开源大模型 DeepSeek 以其出色的推理性能和高准确性,在开发者社区中迅速崭露头角,备受青睐。无论是企业级应用还是个人项目,DeepSeek 均已成为构建智能对话系统、内容生成工具以及复杂决策支持系统的核心驱动力。然而,随着模型规模的持续扩大以及推理请求量的急剧增加,无论是 DeepSeek 官方服务,还是各大云厂商所推出的推理应用,都逐渐开始显露出一系列性能瓶颈问题。

一、AI 推理应用的观测需求与痛点洞察
以自建 DeepSeek 应用为例:剖析可观测需求的关键维度:
1:性能指标监控
推理应用的性能至关重要,其关键指标包括请求延迟、吞吐量以及并发处理能力等。例如,用户期望推理应用能在极短时间内(毫秒级)返回结果,但当请求量突然剧增时,服务可能会因资源争抢导致延迟急剧上升。在这种情况下,若缺乏细粒度的性能监控,问题定位将变得十分困难。
2:使用监控
AI 推理应用通常依赖 GPU、TPU 或 PPU 等高性能计算设备。对这些设备的资源利用率进行监控,不仅要关注硬件层面,还需结合模型推理的具体行为。例如,某些模型可能因内存分配不合理,导致频繁的显存交换,进而影响整体性能。
3:模型加载与卸载的开销
DeepSeek 模型以及推理运行的基础环境镜像体积庞大,加载和卸载过程耗时较长。如果不对这一过程进行可观测,可能会导致服务启动时间过长或资源竞争。
4:模型行为监控
在模型推理过程中,可能出现异常输出或错误预测,这些问题通常与输入数据的质量或模型本身的稳定性有关。若未对模型行为进行有效观测,可能会引发业务风险。
5: 分布式架构监控
在大规模推理场景下,分布式架构成为必然选择。然而,分布式系统中的节点通信延迟、负载均衡和服务发现等问题,都会对推理应用的稳定性产生影响。
面对这些挑战,传统的监控手段显得捉襟见肘。例如,仅依赖日志分析无法实时捕捉性能瓶颈,而简单的 CPU/GPU 使用率监控也无法全面反映推理应用的健康状态。AI 推理应用的可观测需求不仅涉及硬件资源和性能指标,还包括模型行为和分布式架构的复杂性。因此,如何通过高效的可观测手段实现对 AI 推理应用的全链路可观测性,已成为技术团队亟待解决的问题。本文将深入探讨 AI 推理应用的可观测方案,并基于 Prometheus 规范提供一套完整的指标观测方案,助力开发者构建稳定、高效的推理应用。
二、基于 Prometheus 的全链路可观测方案
Prometheus 具备诸多显著优势:
1:多维数据模型
Prometheus 能够借助标签(Labels)实现对指标的分类与过滤操作,进而便捷地完成不同维度数据的聚合及分析流程。比如,可依据 GPU ID、模型名称或请求类型等维度对性能指标实施分组处理。
2:高效的拉取机制
Prometheus 采取主动拉取(Pull)模式来收集指标数据,有效规避了传统推送模式下可能出现的数据丢失或重复等不良状况。
3:丰富的生态系统
Prometheus 拥有广泛的 Exporter 以及客户端库,可实现与各类框架和工具的无缝对接。像 Ray Serve、vLLM 等推理框架,均能借助 Exporter 来暴露自身指标。
4:强大的告警功能
Prometheus 内置的 Alertmanager 支持基于规则的告警配置,能够及时察觉潜在问题,并进行通知。
5:可视化支持
Prometheus 可与 Grafana 等可视化工具搭配使用,构建直观的观测大盘,助力团队迅速掌握服务状态。

-
IaaS 层智算物理设备,覆盖 GPI/PPU 设备,RDMA 网络,CPFS 存储,CPU和内存等关键性和利用率监控;
-
针对 Kubernetes 编排层的全套指标监控支持,完善的生态能力全量复用;
-
智能 PaaS 平台 PAI 和百炼的上下层结合的指标监控体系;
-
社区常见的训练/推理框架全部支持 Prometheus 指标规范,实现默认指标埋点。
这些使得我们针对 AI 推理的指标观测方案的建设站在了高起点
三、推理应用全链路可观测性实践指南
(一)推理框架 Ray Serve
Ray Serve 是为了解决传统推理框架灵活性、性能和可扩展性不足而设计的,具有以下特点:
- 动态伸缩能力:
可根据实时流量动态调整模型副本数量,高效利用资源,适合流量波动大的在线推理场景。
- 多模型支持:能同时部署多个模型,通过路由规则将请求分发到不同模型实例,例如将 NLP 模型和图像分类模型部署在同一服务中。
- 批处理优化:
提供内置批处理机制,将多个请求合并为一个批次处理,提升 GPU 利用率。
- 灵活的服务编排与部署:可将模型推理与其他业务逻辑无缝集成,形成端到端服务流水线,支持单机、多节点及 Kubernetes 集群化部署。
Ray Serve 是开源 AI 推理工具集中的佼佼者,推理性能直接依赖于推理框架。因此,需要从模型加载、副本调度、流量路由、请求处理性能、Token 输入输出等方面建立完善的观测指标。在 Ray Serve 内置指标集基础上,根据推理服务特点选择性自定义性能指标即可。
Ray Serve 内置完善的指标集,通过 Ray 的监控基础设施暴露重要系统指标,还可利用内置的 Ray Serve 指标深入了解应用服务性能,如成功和失败请求的数量。这些指标默认以 Prometheus 格式在每个节点上暴露。


采集 RayServe 内置指标
假设我们在 Kubernetes 中通过 KubeRay 部署 RayServe,可以通过配置 PodMonitor 来采集 Head 和 Worker 节点暴露的指标。
apiVersion: monitoring.coreos.com/v1kind: PodMonitormetadata:name: ray-workers-monitornamespace: prometheus-systemlabels:# `release: $HELM_RELEASE`: Prometheus can only detect PodMonitor with this label.release: prometheusspec:jobLabel: ray-workers# Only select Kubernetes Pods in the "default" namespace.namespaceSelector:matchNames:- default# Only select Kubernetes Pods with "matchLabels".selector:matchLabels:ray.io/node-type: worker# A list of endpoints allowed as part of this PodMonitor.podMetricsEndpoints:- port: metricsrelabelings:- sourceLabels: [__meta_kubernetes_pod_label_ray_io_cluster]targetLabel: ray_io_cluster---apiVersion: monitoring.coreos.com/v1kind: PodMonitormetadata:labels:# `release: $HELM_RELEASE`: Prometheus can only detect PodMonitor with this label.release: prometheusname: ray-head-monitornamespace: prometheus-systemspec:jobLabel: ray-head# Only select Kubernetes Pods in the "default" namespace.namespaceSelector:matchNames:- default# Only select Kubernetes Pods with "matchLabels".selector:matchLabels:ray.io/node-type: head# A list of endpoints allowed as part of this PodMonitor.podMetricsEndpoints:- port: metricsrelabelings:- action: replacesourceLabels:- __meta_kubernetes_pod_label_ray_io_clustertargetLabel: ray_io_cluster- port: as-metrics # autoscaler metricsrelabelings:- action: replacesourceLabels:- __meta_kubernetes_pod_label_ray_io_clustertargetLabel: ray_io_cluster- port: dash-metrics # dashboard metricsrelabelings:- action: replacesourceLabels:- __meta_kubernetes_pod_label_ray_io_clustertargetLabel: ray_io_cluster
在 RayServe 代码中自定义监控指标
框架内置的指标解决了基础的监控问题,但如果希望根据用户类型、请求内容或优先级来统计请求,按模型版本或输入 Token 数据来统计响应性能,模型全方位评估,模型推理结果准确度,输入数据质量监控等等。需要通过自定义指标埋点来解决。到这里,需要具备 Python 开发能力和掌握 Prometheus 指标模型。这有利于建立最贴近业务的直接监控指标。
下面是一个借助 ray.serve.metrics类库来实现自定义指标埋点的用例。
from ray import servefrom ray.serve import metricsimport timeimport requests@serve.deploymentclass MyDeployment:def __init__(self):self.num_requests = 0self.my_counter = metrics.Counter("my_counter",description=("The number of odd-numbered requests to this deployment."),tag_keys=("model",),)self.my_counter.set_default_tags({"model": "123"})def __call__(self):self.num_requests += 1if self.num_requests % 2 == 1:self.my_counter.inc()my_deployment = MyDeployment.bind()serve.run(my_deployment)while True:requests.get("http://localhost:8000/")time.sleep(1)
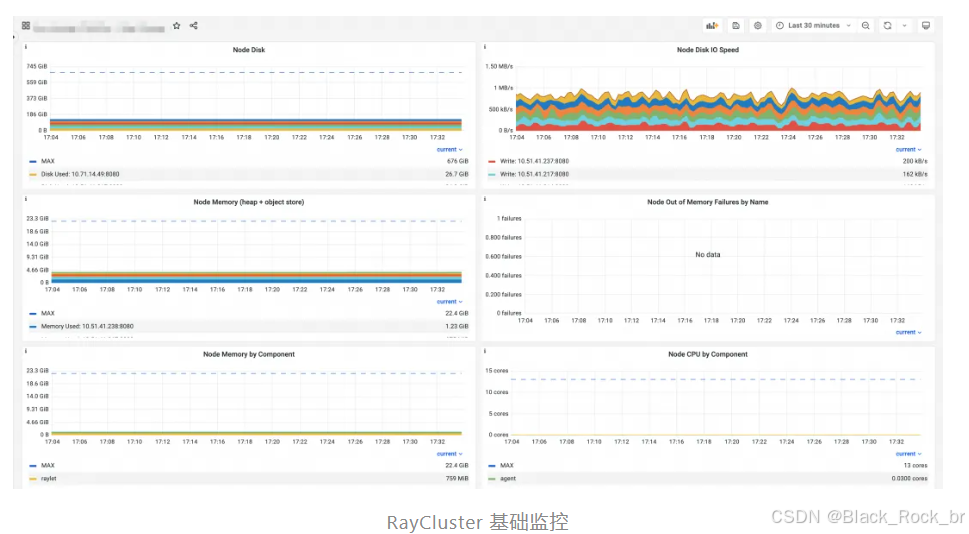
(二)大模型框架 vLLM
vLLM 是一个专注于大规模语言模型(LLM)推理的高性能框架,致力于解决大模型在推理过程中遇到的性能瓶颈问题。它提供了高效的批处理机制、显存优化以及分布式推理支持,特别适合处理高并发和长序列输入的场景。在基于 DeepSeek 的推理应用生产部署中,很多情况下会选择同时使用 Ray 和 vLLM 框架。
vLLM 更加贴近模型推理过程,通常会基于 vLLM 将大模型切分为多个 Block 进行分布式部署。因此,vLLM 能够为我们提供更细分的推理性能监控指标。
1.vLLM 内置指标说明
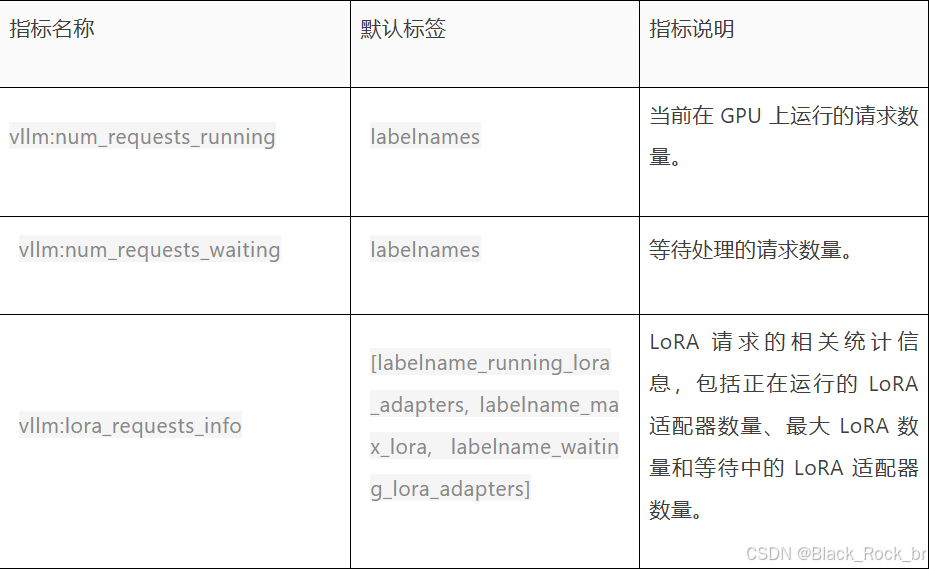
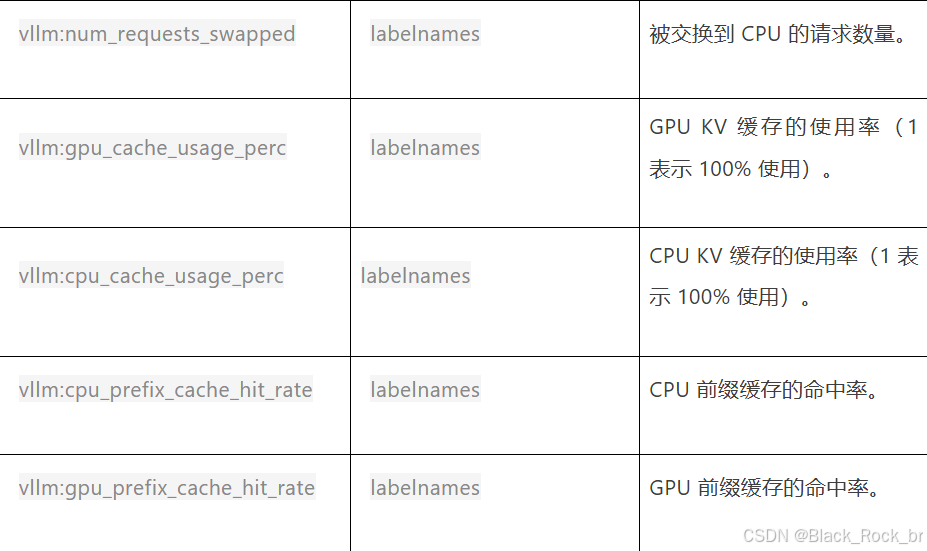
2. 迭代统计相关指标
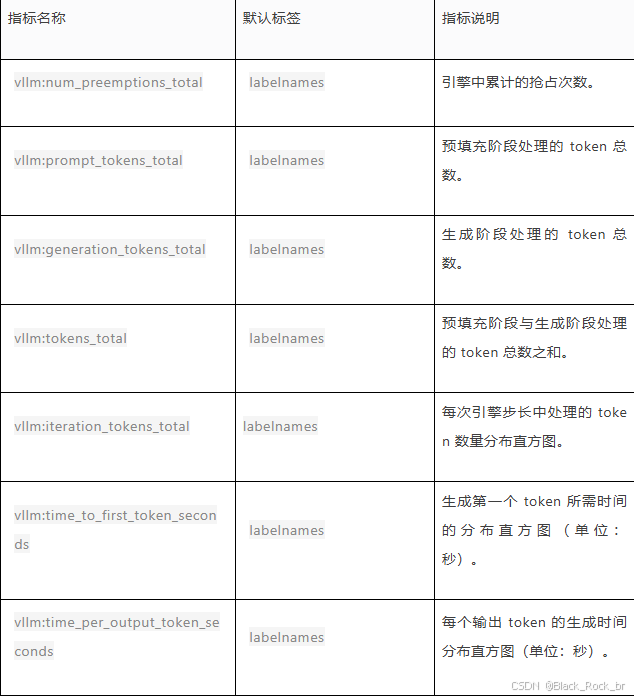
3. 请求统计相关指标
(1) 延迟相关
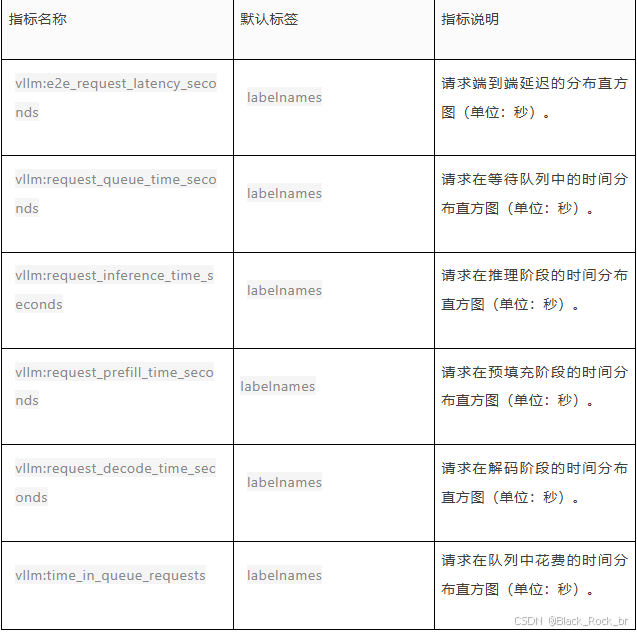
(2) 模型执行时间
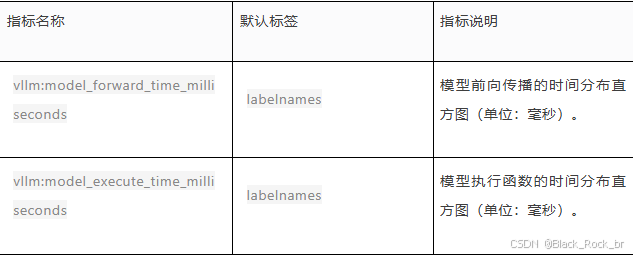
(3) Token 处理
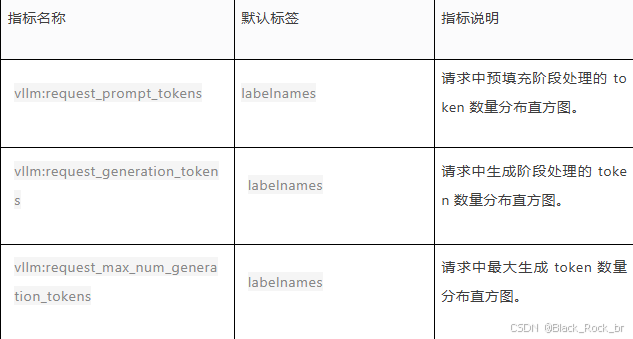
(4) 请求参数
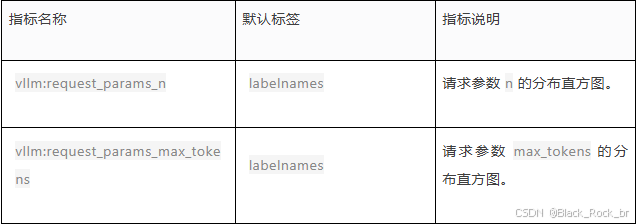
4. 推测解码(Speculative Decoding)相关指标
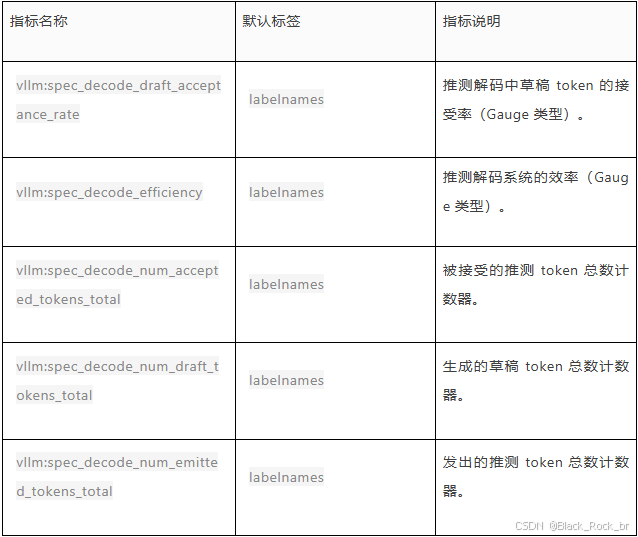
5. 默认标签说明
-
labelnames: 动态字段,表示指标的标签维度,例如模型名称、请求路径等。
-
Metrics.labelname_finish_reason: 表示请求完成的原因(如成功、失败等)。
-
Metrics.labelname_waiting_lora_adapters: 表示等待中的 LoRA 适配器数量。
-
Metrics.labelname_running_lora_adapters: 表示正在运行的 LoRA 适配器数量。
-
Metrics.labelname_max_lora: 表示最大 LoRA 数量。
6.采集 vLLM 服务指标
vLLM 通过 OpenAI 兼容 API 服务上的 /metrics 指标端点公开指标,下面是一个用例:
$ curl http://0.0.0.0:8000/metrics# HELP vllm:iteration_tokens_total Histogram of number of tokens per engine_step.# TYPE vllm:iteration_tokens_total histogramvllm:iteration_tokens_total_sum{model_name="unsloth/Llama-3.2-1B-Instruct"} 0.0vllm:iteration_tokens_total_bucket{le="1.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="8.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="16.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="32.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="64.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="128.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="256.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0vllm:iteration_tokens_total_bucket{le="512.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0...
如果 vLLM 服务部署到 Kubernetes 中,同样可以通过 PodMonitor 配置来采集它们,下面给出一个简单配置用例。要求 vLLM 的 Deployment 中需要给 Pod 配置标签app: vllm-server。

自定义指标的实现
自定义指标有两种方案:
-
如果将 vLLM 结合 Ray 使用,那么可以直接使用 Ray 的相关工具类。例如:
from ray.util import metrics as ray_metrics-
直接使用 Prometheus Python SDK。
# begin-metrics-definitionsclass Metrics:"""vLLM uses a multiprocessing-based frontend for the OpenAI server.This means that we need to run prometheus_client in multiprocessing modeSee https://prometheus.github.io/client_python/multiprocess/ for moredetails on limitations."""
直接参考 vLLM 内置指标的实现代码:
https://github.com/vllm-project/vllm/blob/main/vllm/engine/metrics.py

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)