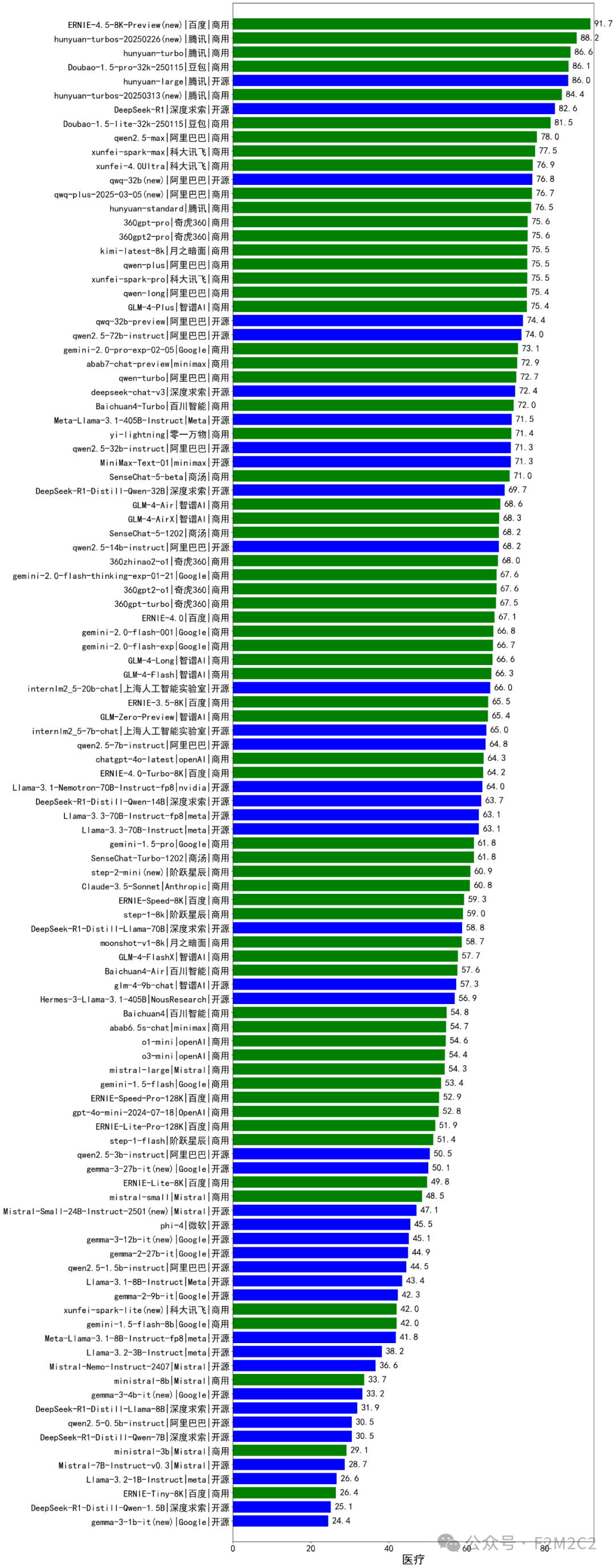
医疗行业|12个分类、18科目,110个大模型应用实测横评!
评测结论:百度系最新大模型得分第一!,腾讯系混元大模型排名第二,DeepSeek排名第七,和腾讯系模型是排名前10中唯二的开源模型。
本期安排上了应用于医疗行业的大模型能力评测,涉及12大分类、18个科目。同时,医疗领域不同类型、不同级别、不同科目的评测,都在爆肝输出中,敬请期待。
一、评测结论:
百度系最新大模型得分第一!,腾讯系混元大模型排名第二,DeepSeek排名第七,和腾讯系模型是排名前10中唯二的开源模型。
二、评测维度:
针对医疗行业的各类考试的选择题进行评测,囊括12大分类,18个科目:外科、皮肤科、妇产科、耳鼻咽喉科、神经内科、儿科、麻醉科、小儿外科、眼科、临床病理科、超声科、康复医学科、骨科、内科、口腔科、医学影像科、全科医学科、精神科。
各科目完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
三、评测方法:
结合以上医疗类目考试的选择题,分别让各个大模型进行回答,根据结果进行打分,并统计每个模型的答题准确率。
*评测综合得分排名(图)|绿色(闭源),蓝色(开源)
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
|
类别 |
大模型 |
医疗 |
排名 |
|
商用 |
ERNIE-4.5-8K-Preview(new) |
91.70 |
1 |
|
商用 |
hunyuan-turbos-20250226(new) |
88.20 |
2 |
|
商用 |
hunyuan-turbo |
86.60 |
3 |
|
商用 |
Doubao-1.5-pro-32k-250115 |
86.10 |
4 |
|
开源 |
hunyuan-large |
86.00 |
5 |
|
商用 |
hunyuan-turbos-20250313(new) |
84.40 |
6 |
|
开源 |
DeepSeek-R1 |
82.60 |
7 |
|
商用 |
Doubao-1.5-lite-32k-250115 |
81.50 |
8 |
|
商用 |
qwen2.5-max |
78.00 |
9 |
|
商用 |
xunfei-spark-max |
77.50 |
10 |
|
商用 |
xunfei-4.0Ultra |
76.90 |
11 |
|
开源 |
qwq-32b(new) |
76.80 |
12 |
|
商用 |
qwq-plus-2025-03-05(new) |
76.70 |
13 |
|
商用 |
hunyuan-standard |
76.50 |
14 |
|
商用 |
360gpt-pro |
75.60 |
15 |
|
商用 |
360gpt2-pro |
75.60 |
16 |
|
商用 |
kimi-latest-8k |
75.50 |
17 |
|
商用 |
qwen-plus |
75.50 |
18 |
|
商用 |
xunfei-spark-pro |
75.50 |
19 |
|
商用 |
qwen-long |
75.40 |
20 |
|
商用 |
GLM-4-Plus |
75.40 |
21 |
|
开源 |
qwq-32b-preview |
74.40 |
22 |
|
开源 |
qwen2.5-72b-instruct |
74.00 |
23 |
|
商用 |
gemini-2.0-pro-exp-02-05 |
73.10 |
24 |
|
商用 |
abab7-chat-preview |
72.90 |
25 |
|
商用 |
qwen-turbo |
72.70 |
26 |
|
开源 |
deepseek-chat-v3 |
72.40 |
27 |
|
商用 |
Baichuan4-Turbo |
72.00 |
28 |
|
开源 |
Meta-Llama-3.1-405B-Instruct |
71.50 |
29 |
|
商用 |
yi-lightning |
71.40 |
30 |
|
开源 |
qwen2.5-32b-instruct |
71.30 |
31 |
|
开源 |
MiniMax-Text-01 |
71.30 |
32 |
|
商用 |
SenseChat-5-beta |
71.00 |
33 |
|
开源 |
DeepSeek-R1-Distill-Qwen-32B |
69.70 |
34 |
|
商用 |
GLM-4-Air |
68.60 |
35 |
|
商用 |
GLM-4-AirX |
68.30 |
36 |
|
商用 |
SenseChat-5-1202 |
68.20 |
37 |
|
开源 |
qwen2.5-14b-instruct |
68.20 |
38 |
|
商用 |
360zhinao2-o1 |
68.00 |
39 |
|
商用 |
gemini-2.0-flash-thinking-exp-01-21 |
67.60 |
40 |
|
商用 |
360gpt2-o1 |
67.60 |
41 |
|
商用 |
360gpt-turbo |
67.50 |
42 |
|
商用 |
ERNIE-4.0 |
67.10 |
43 |
|
商用 |
gemini-2.0-flash-001 |
66.80 |
44 |
|
商用 |
gemini-2.0-flash-exp |
66.70 |
45 |
|
商用 |
GLM-4-Long |
66.60 |
46 |
|
商用 |
GLM-4-Flash |
66.30 |
47 |
|
开源 |
internlm2_5-20b-chat |
66.00 |
48 |
|
商用 |
ERNIE-3.5-8K |
65.50 |
49 |
|
商用 |
GLM-Zero-Preview |
65.40 |
50 |
|
开源 |
internlm2_5-7b-chat |
65.00 |
51 |
|
开源 |
qwen2.5-7b-instruct |
64.80 |
52 |
|
商用 |
chatgpt-4o-latest |
64.30 |
53 |
|
商用 |
ERNIE-4.0-Turbo-8K |
64.20 |
54 |
|
开源 |
Llama-3.1-Nemotron-70B-Instruct-fp8 |
64.00 |
55 |
|
开源 |
DeepSeek-R1-Distill-Qwen-14B |
63.70 |
56 |
|
开源 |
Llama-3.3-70B-Instruct |
63.10 |
57 |
|
开源 |
Llama-3.3-70B-Instruct-fp8 |
63.10 |
58 |
|
商用 |
gemini-1.5-pro |
61.80 |
59 |
|
商用 |
SenseChat-Turbo-1202 |
61.80 |
60 |
|
商用 |
step-2-mini(new) |
60.90 |
61 |
|
商用 |
Claude-3.5-Sonnet |
60.80 |
62 |
|
商用 |
ERNIE-Speed-8K |
59.30 |
63 |
|
商用 |
step-1-8k |
59.00 |
64 |
|
开源 |
DeepSeek-R1-Distill-Llama-70B |
58.80 |
65 |
|
商用 |
moonshot-v1-8k |
58.70 |
66 |
|
商用 |
GLM-4-FlashX |
57.70 |
67 |
|
商用 |
Baichuan4-Air |
57.60 |
68 |
|
开源 |
glm-4-9b-chat |
57.30 |
69 |
|
开源 |
Hermes-3-Llama-3.1-405B |
56.90 |
70 |
|
商用 |
Baichuan4 |
54.80 |
71 |
|
商用 |
abab6.5s-chat |
54.70 |
72 |
|
商用 |
o1-mini |
54.60 |
73 |
|
商用 |
o3-mini |
54.40 |
74 |
|
商用 |
mistral-large |
54.30 |
75 |
|
商用 |
gemini-1.5-flash |
53.40 |
76 |
|
商用 |
ERNIE-Speed-Pro-128K |
52.90 |
77 |
|
商用 |
gpt-4o-mini-2024-07-18 |
52.80 |
78 |
|
商用 |
ERNIE-Lite-Pro-128K |
51.90 |
79 |
|
商用 |
step-1-flash |
51.40 |
80 |
|
开源 |
qwen2.5-3b-instruct |
50.50 |
81 |
|
开源 |
gemma-3-27b-it(new) |
50.10 |
82 |
|
商用 |
ERNIE-Lite-8K |
49.80 |
83 |
|
商用 |
mistral-small |
48.50 |
84 |
|
开源 |
Mistral-Small-24B-Instruct-2501(new) |
47.10 |
85 |
|
开源 |
phi-4 |
45.50 |
86 |
|
开源 |
gemma-3-12b-it(new) |
45.10 |
87 |
|
开源 |
gemma-2-27b-it |
44.90 |
88 |
|
开源 |
qwen2.5-1.5b-instruct |
44.50 |
89 |
|
开源 |
Llama-3.1-8B-Instruct |
43.40 |
90 |
|
开源 |
gemma-2-9b-it |
42.30 |
91 |
|
商用 |
xunfei-spark-lite(new) |
42.00 |
92 |
|
商用 |
gemini-1.5-flash-8b |
42.00 |
93 |
|
开源 |
Meta-Llama-3.1-8B-Instruct-fp8 |
41.80 |
94 |
|
开源 |
Llama-3.2-3B-Instruct |
38.20 |
95 |
|
开源 |
Mistral-Nemo-Instruct-2407 |
36.60 |
96 |
|
商用 |
ministral-8b |
33.70 |
97 |
|
开源 |
gemma-3-4b-it(new) |
33.20 |
98 |
|
开源 |
DeepSeek-R1-Distill-Llama-8B |
31.90 |
99 |
|
开源 |
qwen2.5-0.5b-instruct |
30.50 |
100 |
|
开源 |
DeepSeek-R1-Distill-Qwen-7B |
30.50 |
101 |
|
商用 |
ministral-3b |
29.10 |
102 |
|
开源 |
Mistral-7B-Instruct-v0.3 |
28.70 |
103 |
|
开源 |
Llama-3.2-1B-Instruct |
26.60 |
104 |
|
商用 |
ERNIE-Tiny-8K |
26.40 |
105 |
|
开源 |
DeepSeek-R1-Distill-Qwen-1.5B |
25.10 |
106 |
|
开源 |
gemma-3-1b-it(new) |
24.40 |
107 |
|
开源 |
qwen2.5-math-72b-instruct |
/ |
108 |
|
开源 |
Yi-1.5-34B-Chat |
/ |
109 |
|
开源 |
Yi-1.5-9B-Chat |
/ |
110 |
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
大模型评测EasyLLM,目前已就DeepSeek和各个大模型的不同能力维度进行了综合评测(详情可回顾以下链接👇),接下来还会针对大模型当律师、医生、老师等各个岗位角色进行测评,看看谁是各个垂直领域的最强打工人!宝子们看好哪个大模型可以在哪些岗位胜任最强牛马?或者想评测大模型的哪方面能力?评论区留言,有求必测,一一公布结果!有评测样本、有图有真相!
往期文章
Llama/Qwen/DeepSeek开源之争——CLiB开源大模型排行榜03.04
那些免费的大模型API效果到底好不好?——CLiB大模型排行榜
关于大模型评测EasyLLM
-
最全——全球最全大模型产品评测平台,已囊括203个大模型
-
最新——月更各个大模型各项能力指标评测,输出排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯!
大模型评测EasyLLM目前已囊括187个大模型,覆盖chatgpt、gpt-4o、o3-mini、谷歌gemini、Claude3.5、智谱GLM-Zero、文心一言、qwen-max、百川、讯飞星火、商汤senseChat、minimax等商用模型, 以及DeepSeek-R1、deepseek-v3、qwen2.5、llama3.3、phi-4、glm4、书生internLM2.5等开源大模型。不仅提供能力评分排行榜,也提供所有模型的原始输出结果!
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)