10分钟手把手教学:用deepseek4j开发私有大模型知识库,零基础小白收藏这一篇就够了!!
deepseek4j 提供了一套强大的 API,涵盖了 Reasoner、Function Calling、JSON 解析等特性。本工具旨在简化 DeepSeek API 的集成,让开发者能够快速调用相关能力并集成到自己的应用中。然而,DeepSeek 官方并未提供向量模型,因此本工具在最初设计时未考虑向量搜索的集成。
DeepSeek R1 凭借其强大的思维链能力在开发者中广受欢迎,但 Spring AI 等主流框架对其支持不足,特别是在思维链内容保留和流式输出方面存在诸多限制。deepseek4j 1.4 版本重磅发布支持向量模型等重要更新。
背景
deepseek4j 提供了一套强大的 API,涵盖了 Reasoner、Function Calling、JSON 解析等特性。本工具旨在简化 DeepSeek API 的集成,让开发者能够快速调用相关能力并集成到自己的应用中。
然而,DeepSeek 官方并未提供向量模型,因此本工具在最初设计时未考虑向量搜索的集成。
现状
- deepseek4j 已全面支持 DeepSeek 的 Reasoner、Function Calling、JSON 解析等功能。
- R1 模型的私有知识库需求正在增长,许多开发者希望在 DeepSeek 之上实现私有知识库。
经过深入的技术方案评估,我们选择了一个优雅的解决方案:通过兼容 OpenAI 协议标准来集成向量模型能力。这种方案具有以下优势:
- 零额外依赖:无需引入新的依赖包,保持框架轻量
- 完美兼容性:与现有架构无缝衔接,确保向后兼容
- 标准化接入:采用业界通用的 OpenAI 协议,降低学习成本
详细的技术讨论和方案细节可参考 GitHub Issue:[RFC] 向量化模型支持 #15
快速上手
本文章将带领大家从零开始构建一个基础 RAG 系统。通过白盒编码的方式,不仅能深入理解 RAG 的核心原理,还可以根据实际需求灵活调整和优化各个环节。相比直接使用现有的开源 RAG 产品,这种方式能让我们更好地掌控系统行为,实现更精准的知识检索和问答效果。
1. 环境准备
在开始构建 RAG 系统之前,我们需要准备以下环境:
1.1 Ollama 模型准备
首先安装 Ollama,然后下载以下必要的模型:
# 下载推理模型 - 用于理解和生成回答
ollama run deepseek-r1:14b
# 下载向量模型 - 用于文本向量化
ollama run bge-m3:latest
1.2 向量数据库准备
本文使用 Milvus 作为向量数据库,你可以选择以下两种方式之一进行安装:
方式一:使用 milvus 测试环境
-
访问 Zilliz Cloud 中文版:https://cloud.zilliz.com.cn
-
获取连接信息(后续配置需要用到)
方式二:Docker 安装
# 1. 下载安装脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# 2. 启动 Docker 容器
bash standalone_embed.sh start
注意:如果选择 Docker 安装方式,请确保你的网络环境能够正常访问 Github。
- 初始化向量数据:创建本次知识库存储、获取链接信息和表信息:
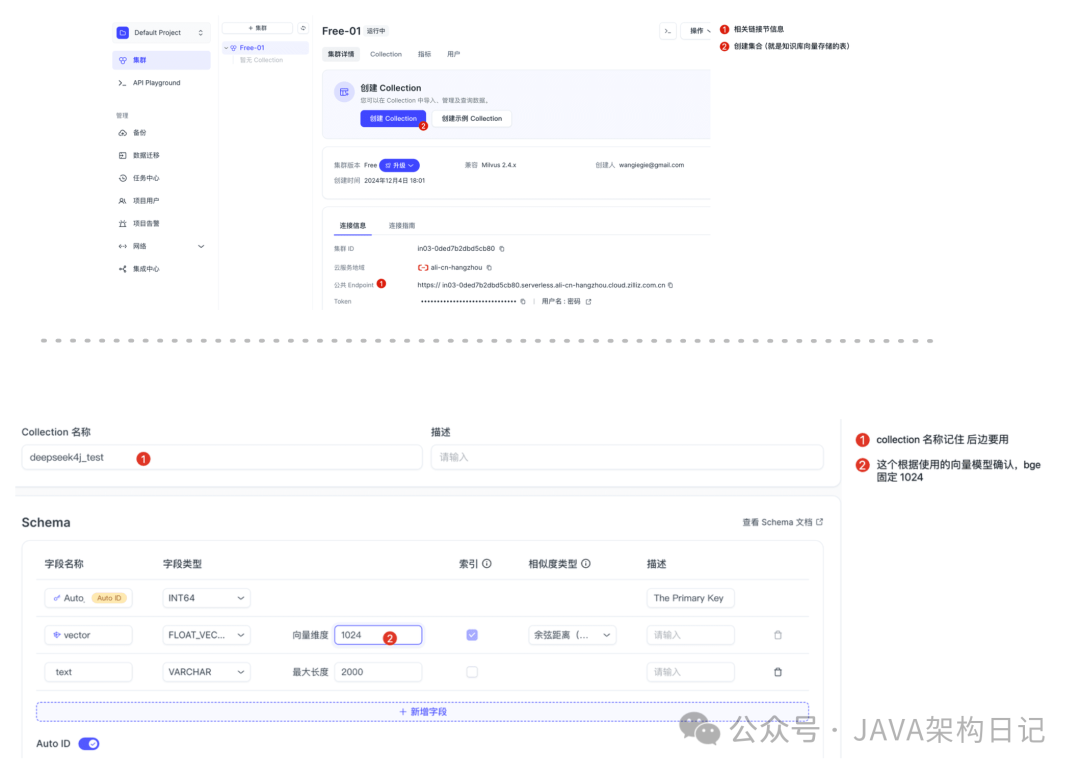
1.3 项目依赖
在你的 Maven 项目中添加以下依赖:
<dependency>
<groupId>io.github.pig-mesh.ai</groupId>
<artifactId>deepseek-spring-boot-starter</artifactId>
<version>1.4.0</version>
</dependency>
<!-- 链接 milvus SDK-->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.5.3</version>
</dependency>
application.yml 配置
# 推理模型链接信息
deepseek:
base-url: http://127.0.0.1:11434/v1
model: deepseek-r1:14b
api-key: ollama-local
# 向量模型链接信息
embedding:
api-key: ${deepseek.api-key}
base-url: ${deepseek.base-url}
model: bge-m3:latest
2. 初始化私有知识
在构建 RAG 系统时,第一步是将已有的知识内容转换为向量形式并存储到向量数据库中。
2.1 创建链接 链接客户端
// 1. Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri(CLUSTER_ENDPOINT) // 1.2 获取的 Milvus 链接端点
.token(TOKEN) // 1.2 获取的 Milvus 链接信息
.build();
MilvusClientV2 milvusClientV2 = new MilvusClientV2(connectConfig);
2.2 准备资料并向量化上传
以下示例为了节约篇幅,以处理纯文本资料。对于 Office 文档、图片、PDF、音视频等其他格式的文件处理,deepseek4j 提供了完整的解决方案

office2md 2.0 发布,支持并发视觉理解和图片自我矫正
@Autowired
EmbeddingClient embeddingClient;
{
// 这里以 2025最新的我司保密条例演示,可以换成你自己的
String law = FileUtil.readString("/Users/lengleng/Downloads/law.txt", Charset.defaultCharset());
String[] lawSplits = StrUtil.split(law, 400);
List<JsonObject> data = new ArrayList<>();
for (String lawSplit : lawSplits) {
List<Float> floatList = embeddingClient.embed(lawSplit);
JsonObject jsonObject = new JsonObject();
// 将 List<Float> 转换为 JsonArray
JsonArray jsonArray = new JsonArray();
for (Float value : floatList) {
jsonArray.add(value);
}
jsonObject.add("vector", jsonArray);
jsonObject.addProperty("text", lawSplit);
data.add(jsonObject);
}
InsertReq insertReq = InsertReq.builder()
.collectionName("deepseek4j_test")
.data(data)
.build();
milvusClientV2.insert(insertReq);
}
3. 创建 RAG 接口
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ChatCompletionResponse> chat(String prompt) {
MilvusClientV2 milvusClientV2 = new MilvusClientV2(connectConfig);
List<Float> floatList = embeddingClientOptional.get().embed(prompt);
SearchReq searchReq = SearchReq.builder()
.collectionName("deepseek4j_test")
.data(Collections.singletonList(new FloatVec(floatList)))
.outputFields(Collections.singletonList("text"))
.topK(3)
.build();
SearchResp searchResp = milvusClientV2.search(searchReq);
List<String> resultList = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
resultList.add(result.getEntity().get("text").toString());
}
}
ChatCompletionRequest request = ChatCompletionRequest.builder()
// 根据渠道模型名称动态修改这个参数
.model("deepseek-r1:14b")
.addUserMessage(String.format("你要根据用户输入的问题:%s \n \n 参考如下内容: %s \n\n 整理处理最终结果", prompt, resultList)).build();
return deepSeekClient.chatFluxCompletion(request);
}
前端测试
总结
本文通过以下核心步骤快速构建了基础 RAG 系统:
- 环境准备:部署推理模型和向量模型
- 知识库构建:向量化存储
- 检索增强:通过语义搜索获取关联知识
- 推理生成:结合上下文生成最终回答
要让 RAG 系统达到生产可用水平,每个环节都需要进一步优化和完善:
- 检索策略优化:结合关键词和语义的混合检索,提高召回准确度
- 重排序优化:对检索结果进行二次排序,确保最相关内容排在前面
- 提示词工程:优化 Prompt 模板,引导模型生成更准确的回答
- 知识库管理:定期更新和维护知识库,保证数据时效性
- 性能调优:优化向量检索和模型推理的性能
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 24
24 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)