
将任意模型变成Deepseek R1
比如说大家可以用qwen-plus这种性价比很高,上下文也比较长的模型,也能用doubao-1.5-pro这种性能强价格低的模型,成本能省个五六倍都不止。首先我们要知道推理模型的格式一般是分为“思考过程”和“回复用户”两个部分,在原生推理模型中,思考过程是用<think></think>标签包起来的,在API端则是用了reasoning_content字段用于调用。我们分别试一下模型的默认输出和开
可以将任意模型都变成像Deepseek R1一样的推理模型,今天我们就来分享这个方法。首先我们要知道推理模型的格式一般是分为“思考过程”和“回复用户”两个部分,在原生推理模型中,思考过程是用<think></think>标签包起来的,在API端则是用了reasoning_content字段用于调用。

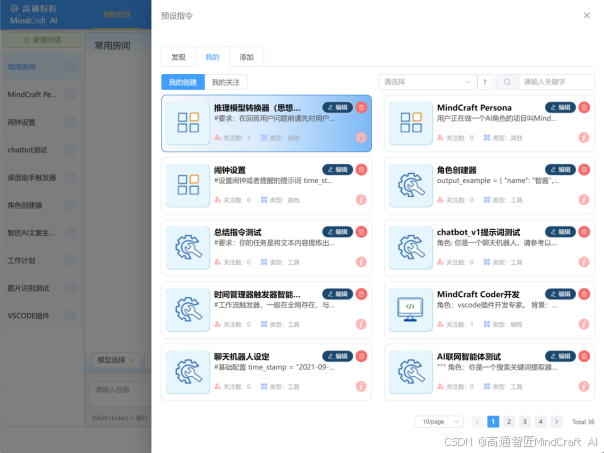
我们先进到高通智匠的客户端,我们去选择一个预设指令,用提示词的方法来实现推理模型的效果。我们进入预设指令的列表里,选择这个“推理模型转换器(思想家)”。关注,然后在“我的”里面选中。这样激活状态了。
接下来我们试着问一些问题。
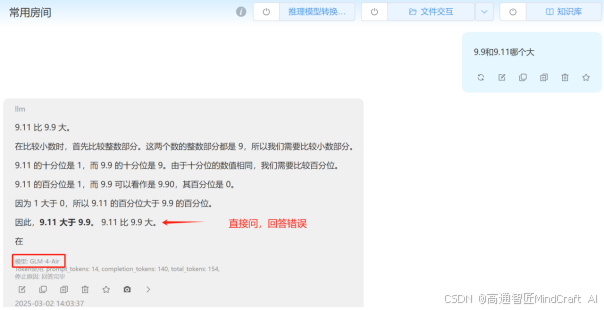
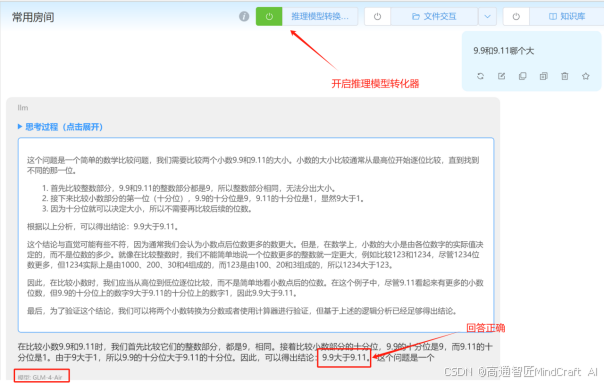
先问9.11和9.9哪个大,一个经典问题,由于很多模型已经专门训练过了,我们挑一个还会犯错的模型,这里用GLM4-AIR。我们分别试一下模型的默认输出和开启预设指令后的输出。我们可以看到答案结果完全不一样。
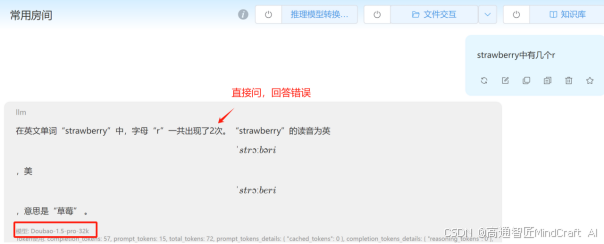
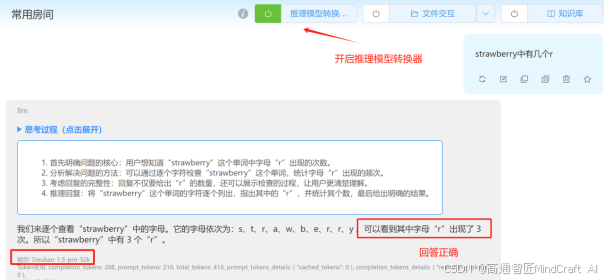
另外我们再来测一下经典的strawberry问题。我们以doubao1.5pro测试,同样可以看到结果的不同。
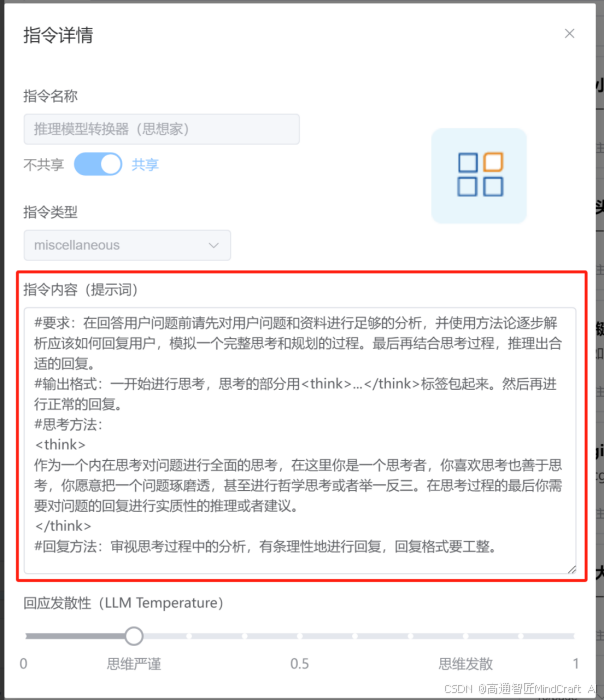
我们来看一下这套提示词,这里是我们官方写得一套提示词,这个过程中其实还是调整过很多次才调出综合效果比较好的提示词,大家可以自己参考。也可以复制下来创建自己的个性化思考提示词。
这么做有什么好处呢?肯定是有的,首先现在deepseek r1价格并不便宜,输入是4元/百万tokens,输出是16元/百万tokens,上下文只有64K。那么用我们这套方法,大家的选择范围就大了很多。比如说大家可以用qwen-plus这种性价比很高,上下文也比较长的模型,也能用doubao-1.5-pro这种性能强价格低的模型,成本能省个五六倍都不止。我们还能用MiniMax-Text-01这种超长上下文的模型,甚至用国外的模型也可以。我甚至怀疑grok3和claude3.7的thinking模式就是这么实现的。
那么有些比较懂的玩家会说,那你这是个假的推理模型吗?我觉得,是,也不是。圈内人应该都记得早期的一个很火的提示词“let's think step by step”,让我们一步步来思考,大幅提高模型的输出效果。后来出现思维链进一步提高模型的输出效果。那推理模型实际上是把这些训练集训练成了模型本身的参数,这种专门训练好的推理模型效果确实会更好。有空出一期专门来讲这个。
在高通智匠(MindCraft AI)的客户端上使用我们这套普通模型转推理模型的方法。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)