DeepSeek基础学习:深度讲解AI大模型基本原理
⭐️⭐️⭐️。
😊😊😊欢迎来到本博客😊😊😊
本次博客内容将继续讲解关于计算机视觉领域的相关知识
🎉作者简介:⭐️⭐️⭐️目前地学博士生在读。
📝目前更新:🌟🌟🌟目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、目前正在更新深度学习的相关内容。
💛💛💛本文摘要💛💛💛
本文我们将在本期博客深度讲解AI大模型原理

🌟AI大模型如何生成文本,模拟对话?
为什么生成式的AI大模型,可以和用户深度交流呢?本次博客通过以下三个步骤为大家深度讲解AI大模型的工作原理
1、文本生成的原理
2、基于llama模型,讲解大模型AI的推理过程
3、基于GPT模型,进行推理实验
这里主要思考一个问题,AI大模型为什么能够准确地回复你所提出的问题,并且可以根据用户和AI大模型历史对话生成符合历史对话逻辑的新对话呢?如果用户觉得回答得不好,还可以重新进行回答。其实对于AI大模型来说,这个过程本质上就是一个文本生成的过程。下方就是一个文本生成模型的基础模型。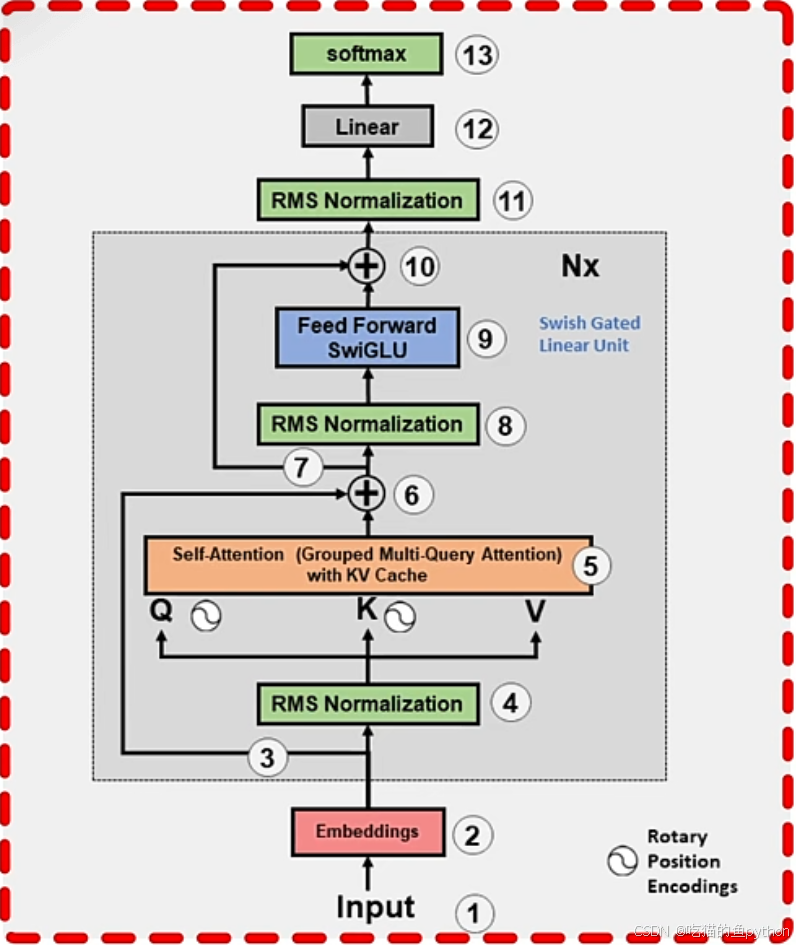
🌟文本生成的原理
这里介绍一个简单的文本生成的案例:
这里我输入今天天气真,那么训练好的AI大模型就会给我生成第六个字的,其中CLS是一个特殊标记,后续会做介绍。那么以此类推呢,AI大模型就会生成一整句话。
这里作为一种时间序列任务来说,每此生成新的字,都要使用前面的某几个字作为输入,最终要生成多少内容,取决于用户想要大模型生成多少内容。那么对话形式的文本生成是什么样的呢?
其中的SEP表示当前对话已经结束,开始下一个用户或者AI大模型进行输入。
所以说AI大模型本质上是一种文本生成,并没有理解对话本身的意义,是通过文本生成,模拟出对话的效果。
🌟基于llama模型,讲解大模型AI的推理过程
如何基于已经有的文本,生成下一个单词呢?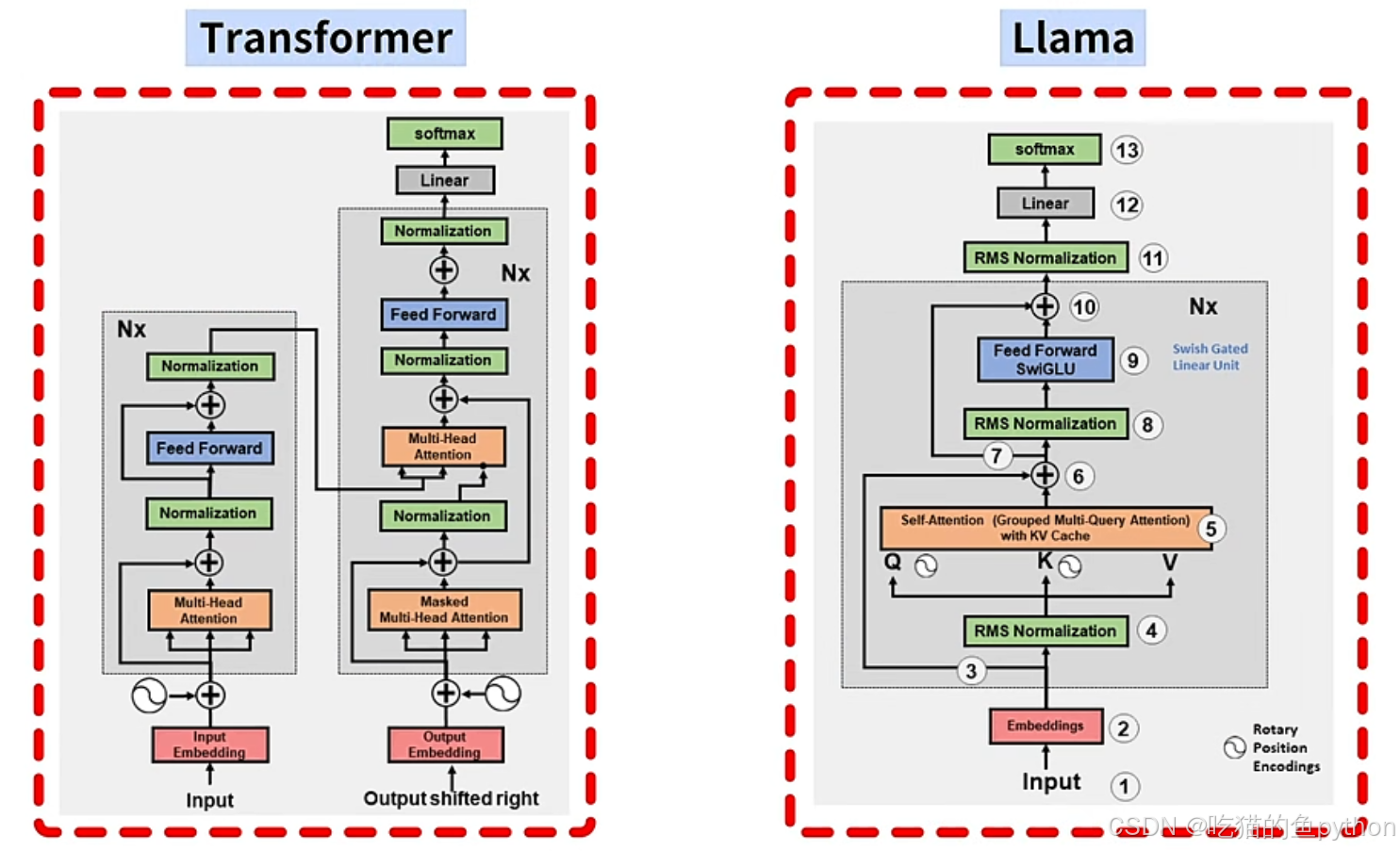
可以从上图看到Transformer和Llama文本生成模型的网络架构图,llama的大模型借鉴了Transformer模型的解码器,基本上都输入文本、Embeddings词嵌入层、Transformer块(其中脑阔了标准化、自注意力层以及前馈神经网络层)最后通过Linear全连接层,变换向量维度,最后通过softmax生成不同结果的概率,然后预测下一个单词。
最后的softmax比如是一个1000个字的分类任务,那么会根据softmax生成下一个字的概率。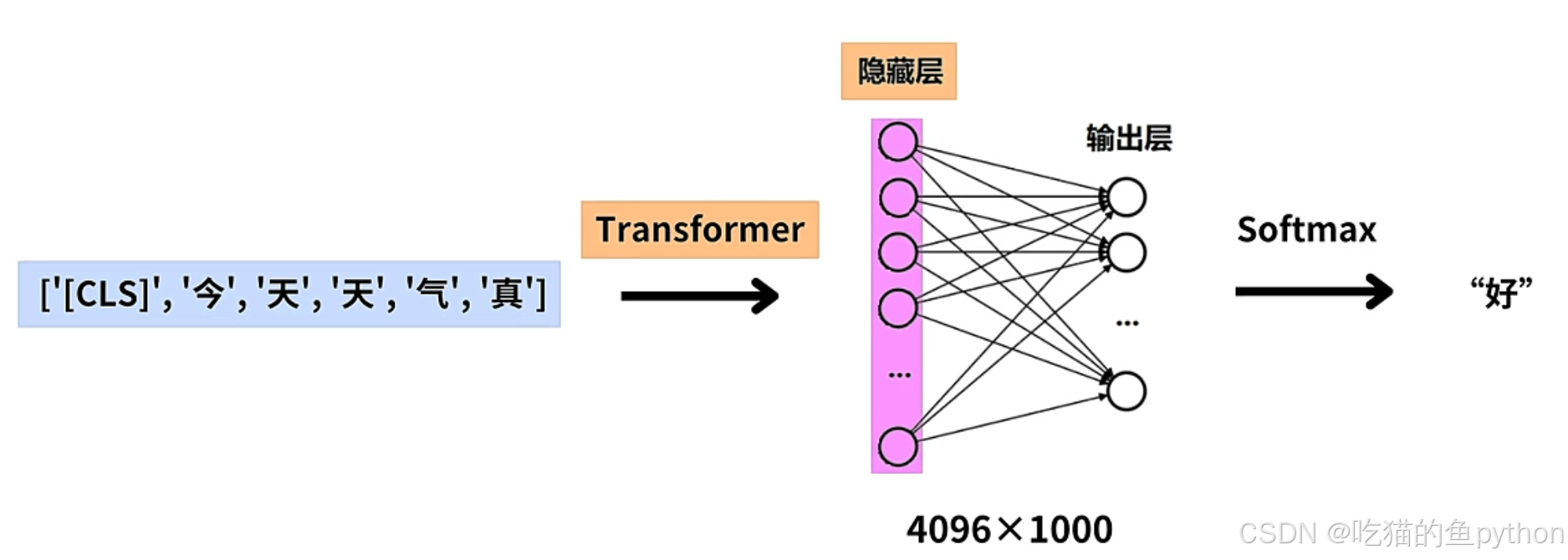
这里的好是对应概率的: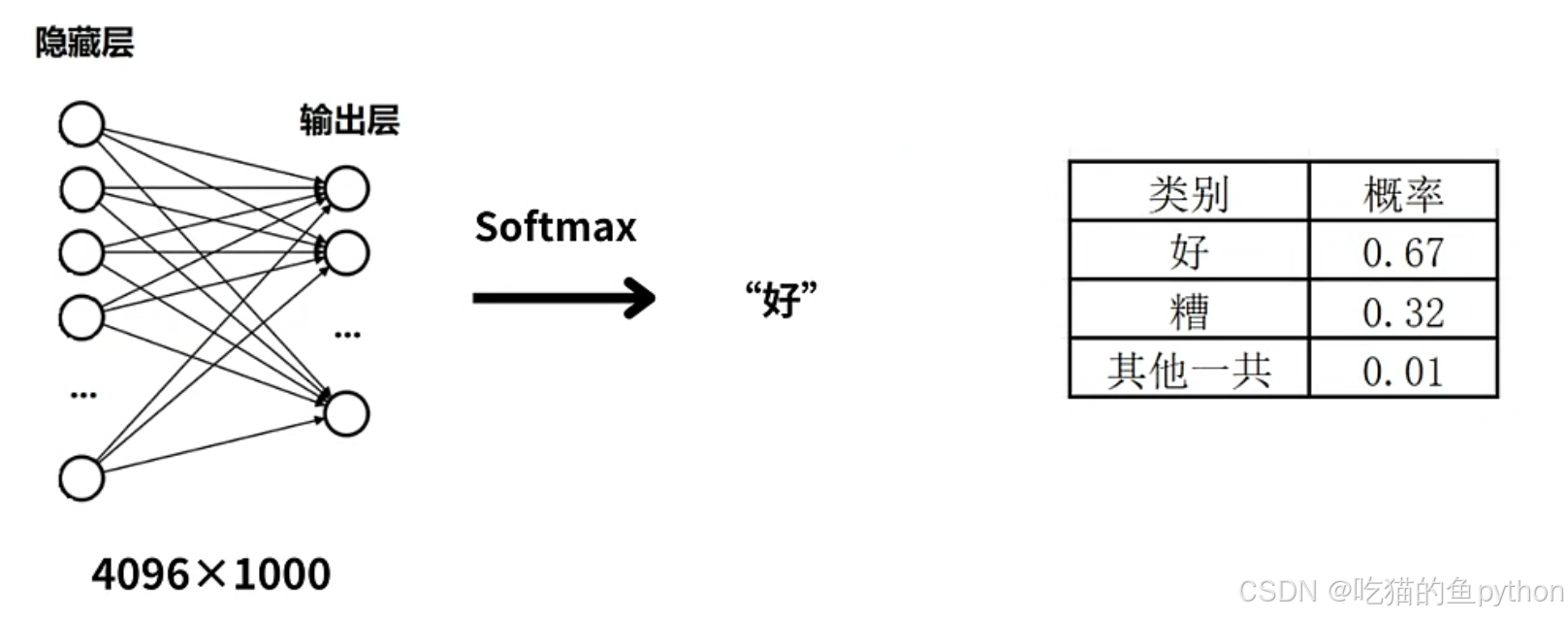 比如这里的好对应的0.67,那么就会优先选择好作为输出。那么这也是一种弊端,所以应该选择概率分布中的随即进行选择才符合情况,那么后期根据天气情况进行实质上的回答则是更进了一步。
比如这里的好对应的0.67,那么就会优先选择好作为输出。那么这也是一种弊端,所以应该选择概率分布中的随即进行选择才符合情况,那么后期根据天气情况进行实质上的回答则是更进了一步。
🌟基于GPT模型,进行推理实验

这里我们已GPT-2的大模型进行代码讲解,GPT-2是目前GPT-4模型的前身,也是目前最后一个开源的OPENAI的大模型项目。
我们现在通过代码文本进行观察: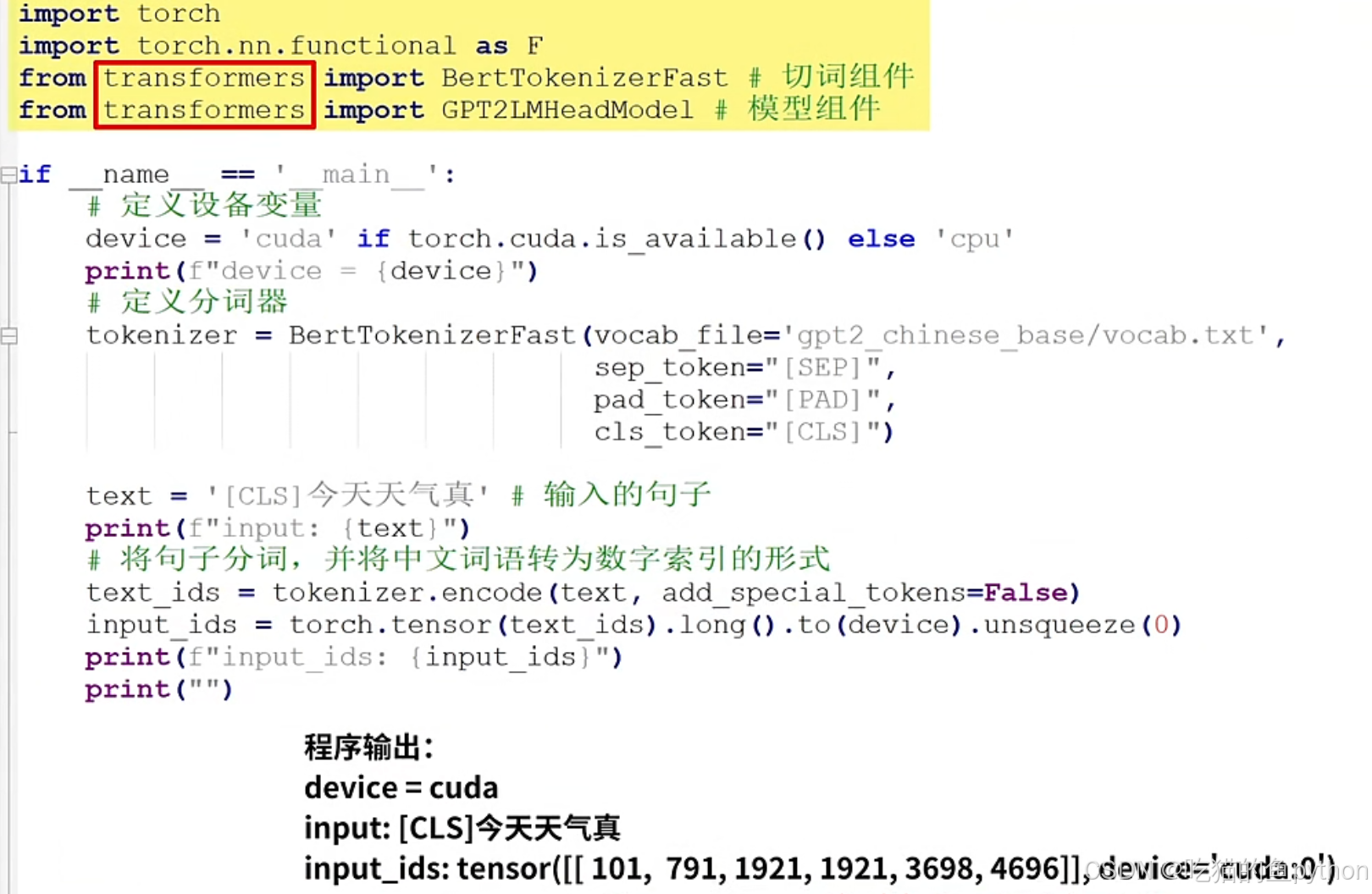
可以看到,代码这里使用了Transformer的相关组件,包括了BertTokenizerFast的切词组件和GPT2的模型组件,vocab.txt则是GPT2对应的文本库。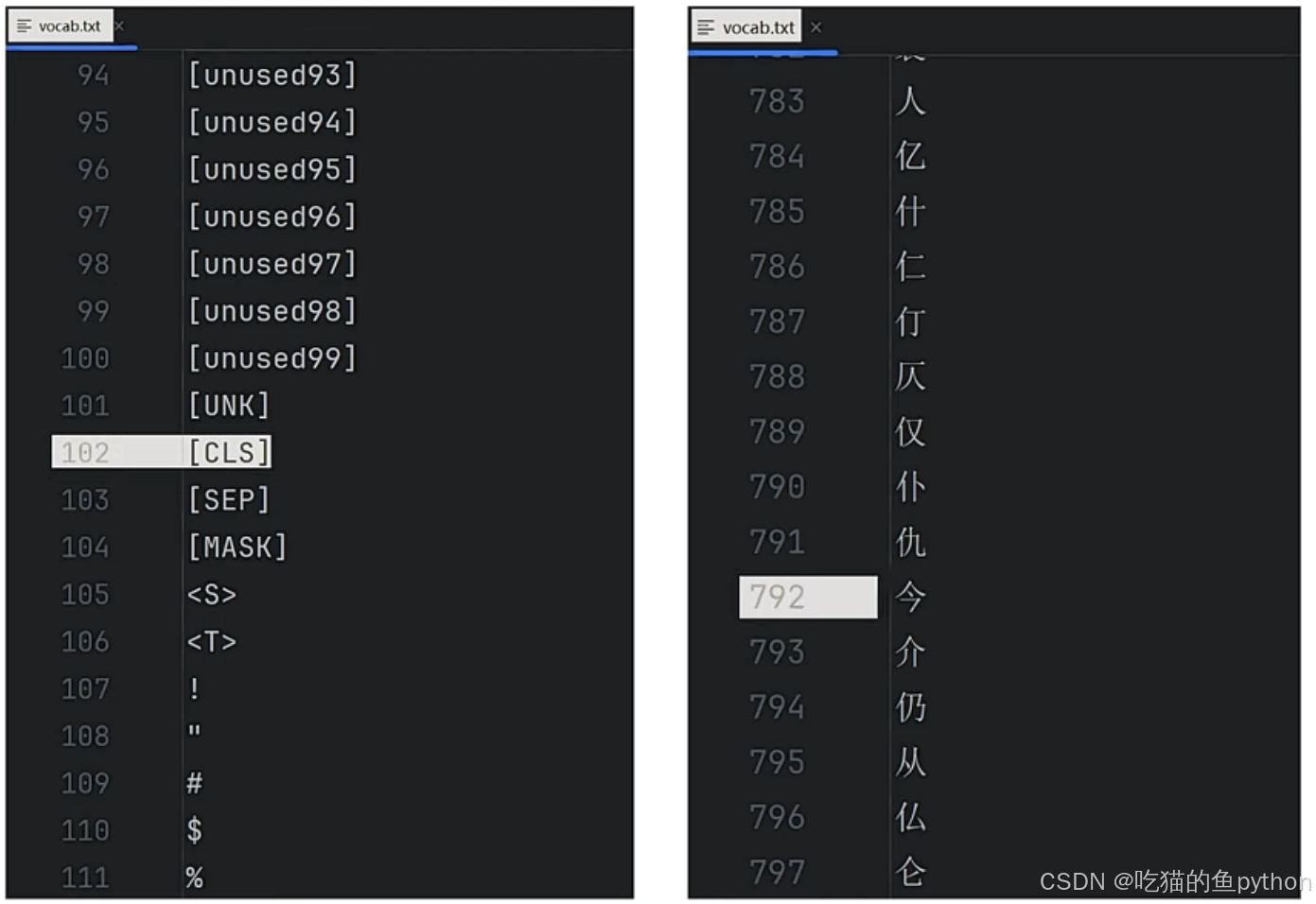
用户通过将词进行输入,然后通过文本库转换为向量的格式。输入到模型当中。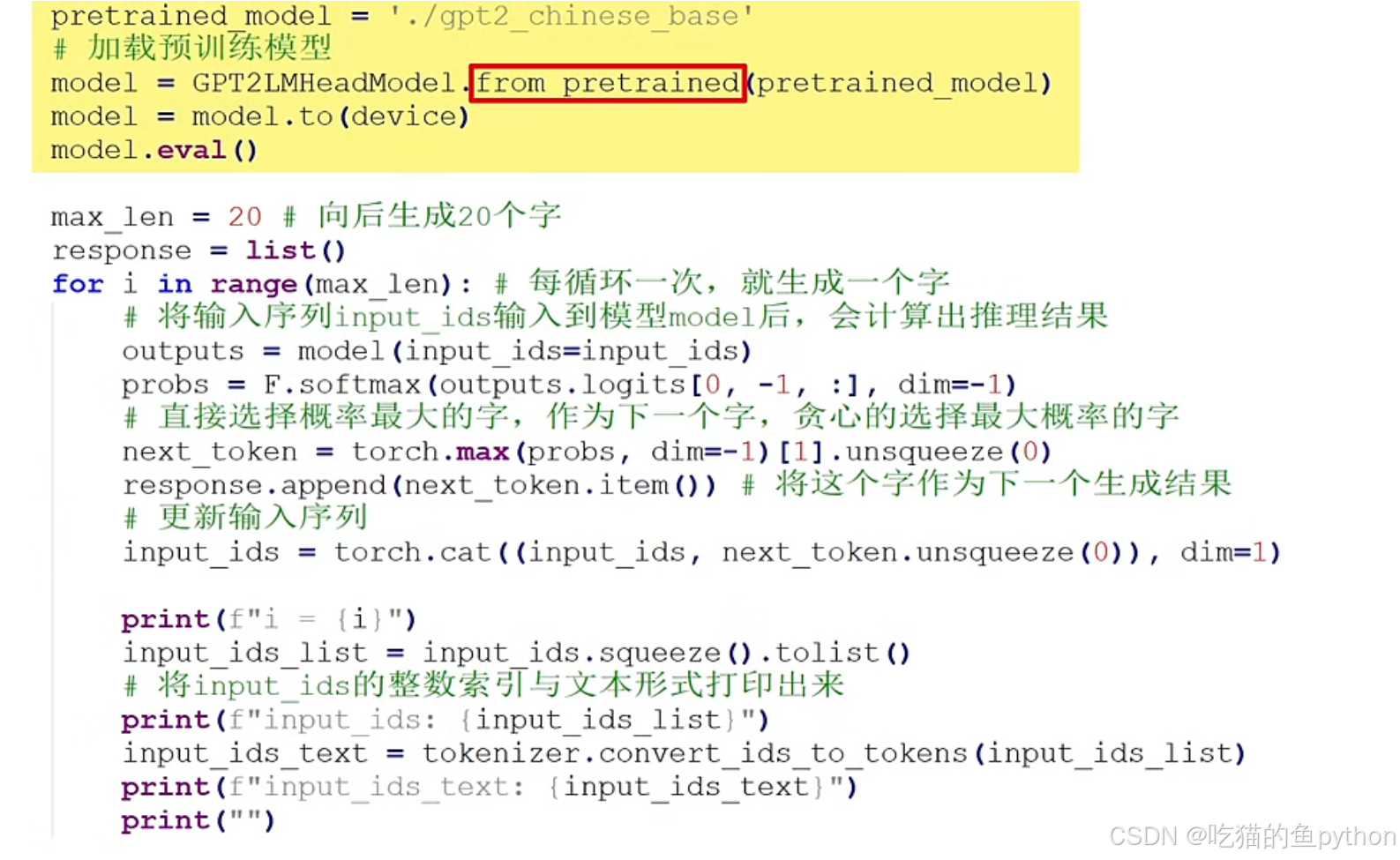
然后通过加载预训练模型,这里加载的是文本生成的模型,并非是文本对话模型。然后模型通过输入的向量内容推理下一个向量的结果,然后通过向量的索引值输出对应的文字。具体结果如下:
🔎支持:🎁🎁🎁谢谢各位支持!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)