【探索 AI 新边界】手把手教你本地部署 DeepSeek:释放私有化 AI 的无限潜力
本地安装部署deepseek大模型,不再受服务器繁忙,请稍后再试的困扰,小白手把手教程,从0到1本地部署deepseek
当前deepseek大火,作为国内领先的大型语言模型解决方案,在技术能力、应用适配性和生态建设方面展现出显著优势。deepseek官网:DeepSeek。但是无论由于外部网络攻击还是说国内访问量就是很大的原因,总是会遇到:服务器繁忙,请稍后再试的响应。当然目前国内很多平台都提供了不同的deepseek模型使用方式,这里列举两个我自己使用的两个平台,点击跳转直接食用,目前都提供了大量的免费token,个人使用的话还是足够的
但终究是企业部署在云端服务器上的,终归是需要money支持的,所以自己就在家研究琢磨尝试了在自己本地机器上部署一个简化的deepseek模型来体验使用
这里是一份零基础保姆级教程,手把手教你本地部署自己的deepseek。不用再看到服务器繁忙的回复,同时可以实现本地运行,保护自己的数据隐私,也可以实现定制化的调优和本地知识库的搭建
前面做一下相关介绍,可以跳过直接跳到部署环节食用
为什么要本地部署deepseek
开始之前,先考虑一下为什么需要本地部署deepseek呢?
-
离线可用性,本地部署可以实现断网情况下依旧可以使用
-
完全自主的定制化,可以使用自己本地的训练数据,灵活适配自己专属的知识库
-
数据安全和隐私保护,所有的数据都在自己的本地处理,避免一些敏感信息的泄露风险
-
性能和效率,使用云端部署的大模型,可能会出现卡顿,延迟甚至无响应的问题,本地部署可以充分利用自己本地的硬件设备(CPU,GPU)提升处理速度和响应效率
deepseek满血版vs蒸馏版
deepseek官网部署的为满血版的模型,企业平台提供的包括满血版也有蒸馏版的模型,两者对比如下:
| 维度 | 满血版 (Full-Powered) | 蒸馏版 (Distilled) |
|---|---|---|
| 模型规模 | 百亿/千亿参数级完整架构 | 十亿级轻量化模型,参数压缩至原版10%-30% |
| 计算需求 | 需高端GPU集群(如A100/H100),显存≥80GB | 单卡消费级GPU(如RTX 3090)或CPU即可运行 |
| 推理速度 | 响应延迟较高(秒级),适合非实时场景 | 毫秒级响应,支持高并发实时交互 |
| 任务精度 | 复杂逻辑推理、长文本生成效果顶尖 | 常规问答/分类任务接近原版,复杂任务存在差距 |
| 部署成本 | 硬件与运维成本高,适合中心化服务 | 边缘设备可部署,综合成本降低60%以上 |
满血版需要极高的硬件要求,我们个人自己本地部署的话就部署一下蒸馏版体验一下即可
Ollama
当前成本最低,流程最简单,最适合新手的本地部署大模型的方法就是通过ollama部署。
Ollama 是一款开源的轻量化框架,专注于简化大型语言模型(LLM)在本地环境中的部署与运行。其设计核心理念是让开发者无需复杂配置即可快速体验和集成大模型能力,尤其适合个人开发、原型验证和边缘计算场景。
核心功能与特性
-
极简部署流程
-
通过一行命令(如
ollama run llama2)即可拉取并运行模型,自动处理依赖项和运行时环境。 -
支持 Windows/macOS/Linux 全平台,特别优化 Apple Silicon(M1/M2)芯片的本地推理性能。
-
-
模型格式兼容性
-
基于 GGUF(GPT-Generated Unified Format) 格式,支持量化模型(4-bit/5-bit/8-bit)以降低硬件需求。
-
兼容 LLaMA、Mistral、DeepSeek 等主流开源模型的转换部署。
-
-
资源高效利用
-
对 CPU 推理深度优化,无需高端 GPU 即可运行百亿参数模型(如 7B/13B 规模)。
-
动态内存管理技术可在 8GB RAM 设备上运行中小模型,适合边缘设备部署。
-
-
开发友好生态
-
提供 RESTful API 接口,轻松与 Python、JavaScript 等语言集成。
-
支持与 LangChain、LlamaIndex 等 AI 工具链无缝协作。
-
Ollama部署与官方部署方案的对比优势
| 维度 | Ollama | 官方原生部署(如 PyTorch) |
|---|---|---|
| 启动速度 | 分钟级(预编译二进制 + 模型库) | 小时级(环境配置 + 依赖安装) |
| 硬件门槛 | 支持低配 CPU / 笔记本 | 通常需要中高端 GPU |
| 学习曲线 | 命令行交互,适合新手 | 需掌握 Python/MLOps 知识 |
| 灵活性 | 受限(依赖社区模型库) | 完全开放(支持自定义训练 / 微调) |
本地设备硬件配置介绍
先介绍一下自己本地设备的具体配置
| CPU | AMD Ryzen 9 9950x 16-Core Processor十六核 |
|---|---|
| GPU | NVIDIA GeForce RTX 4070 TiSUPER |
| 主板 | 微星 MAG X670E TOMAHAWK WIFI(MS-7E12) |
| 内存 | 金士顿64GB DDR5 |
| 硬盘 | Samsung SSD 990 PRO 1TB Seagate ZP2048CM30003(2048GB) |
| 操作系统 | windows10 专业版 |
分割线~~下面正式开始部署
工具无法下载,下载慢,可以访问百度网盘,下载食用
百度网盘分享链接:提取码71x2
第一步、下载安装Ollama
1、打开浏览器Ollama官网
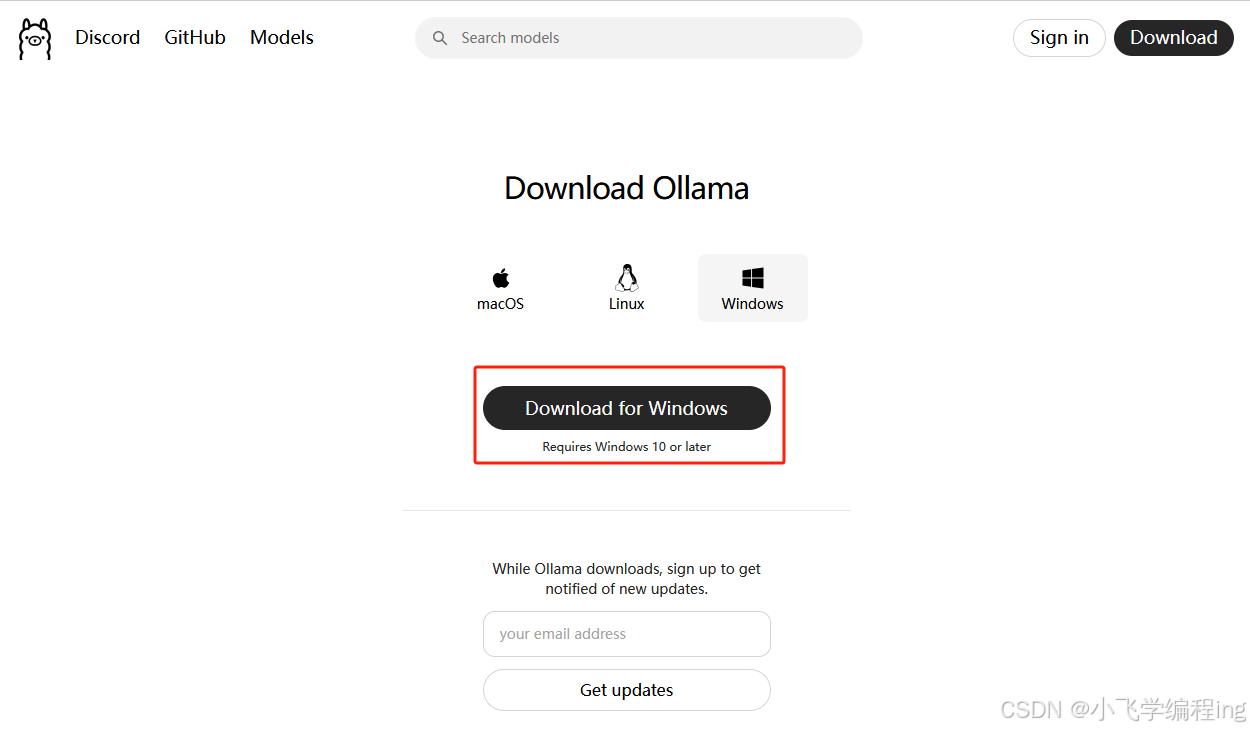
下载完成后,点击安装。
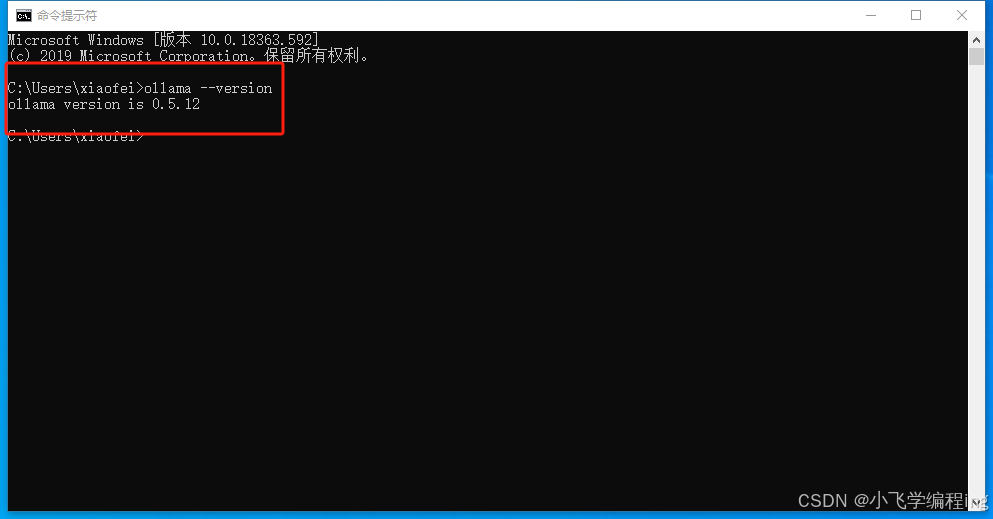
2、确认安装结果
安装完成后,打开命令行确认是否安装成功
如何打开命令行
-
win键+R,打开“运行”对话框,输入cmd,点击确定,即可打开
-
开始菜单旁边的搜索框,直接输入cmd/命令提示符,在搜索结果中找到“命令提示符”或“cmd”图标,单击打开。
判断是否安装成功,在命令行中输入
ollama --version
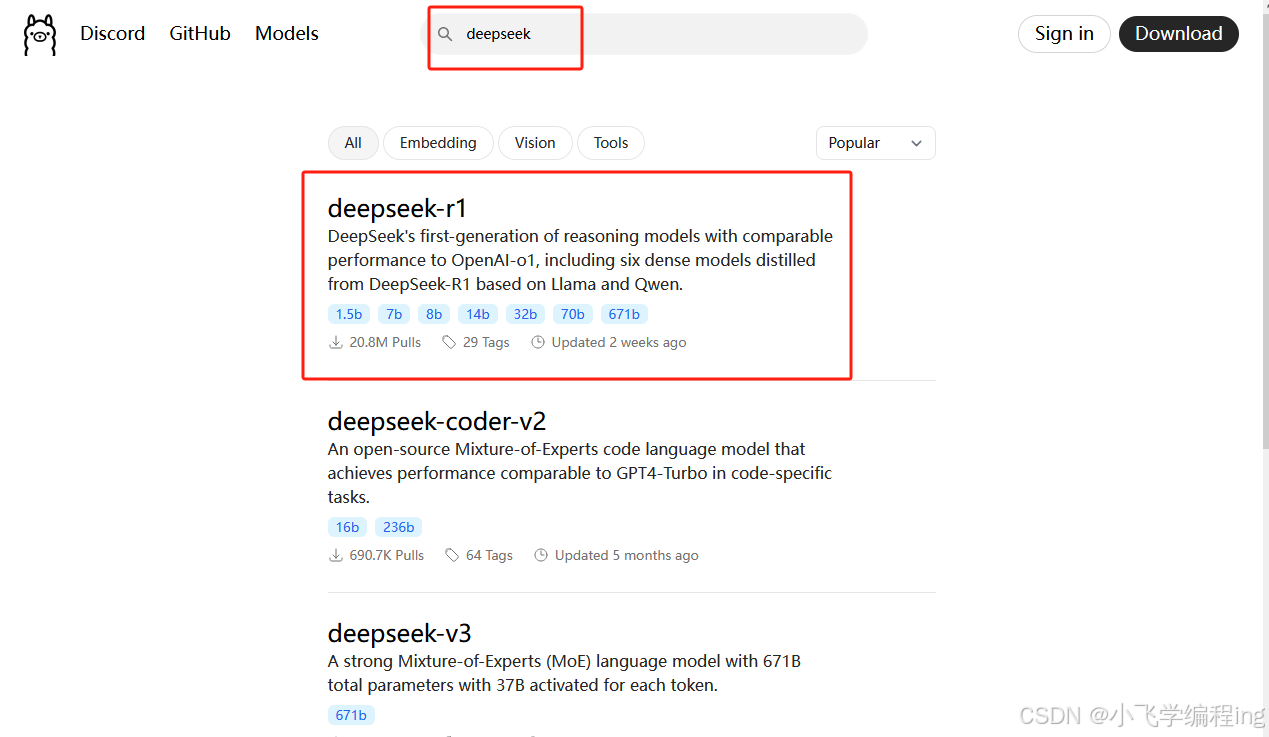
第二步、使用Ollama安装部署deepseek模型
浏览器打开Ollama支持的模型列表:Ollama Search,页面列表第一个就是deepseek,没有的话,可以在搜索框中输入deepseek进行搜索
1、选择模型版本
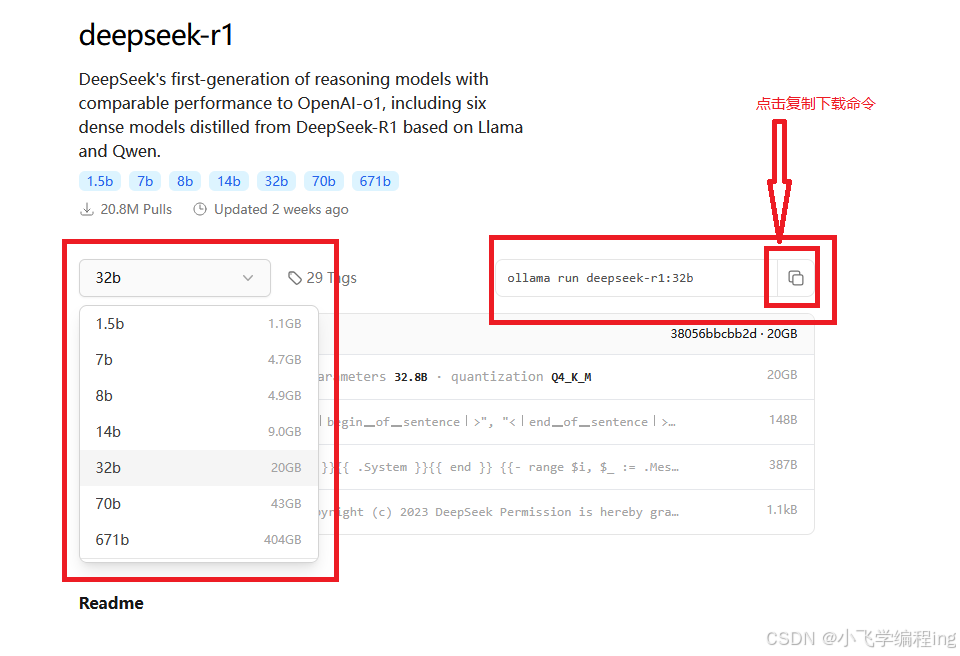
我在自己本地设备部署了14b,32b版本,可以带起来,本教程以1.5b为例进行演示,大家可以选择自己设备适配的模型版本
2、开始部署
复制下载部署命令,在命令行中执行
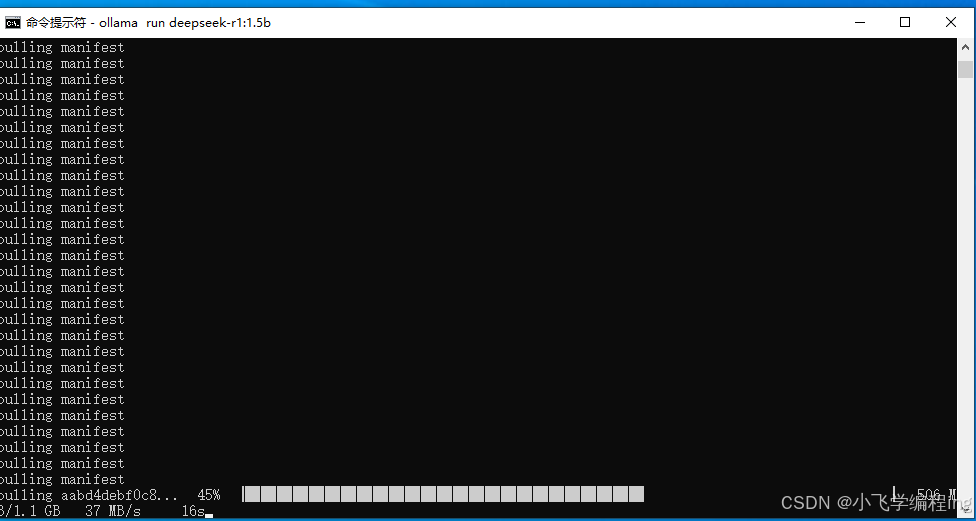
3、安装完成
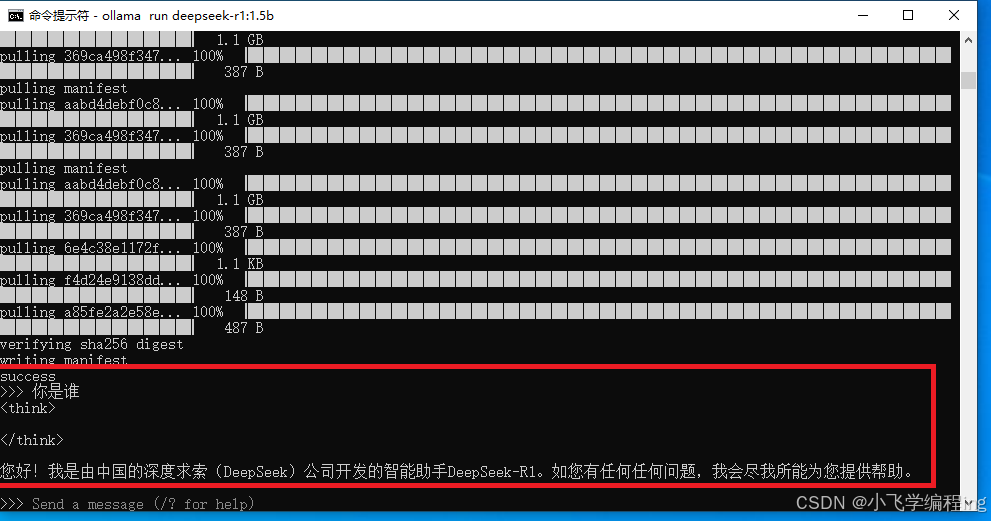
出现“success”字样表示安装完成
输入“你是谁”,可以秒回
第三步、chatbox+Ollama实现友好交互,丝滑使用
1、下载chatbox
访问chatbox官网,点击免费下载
2、安装chatbox
无脑下一步点击安装
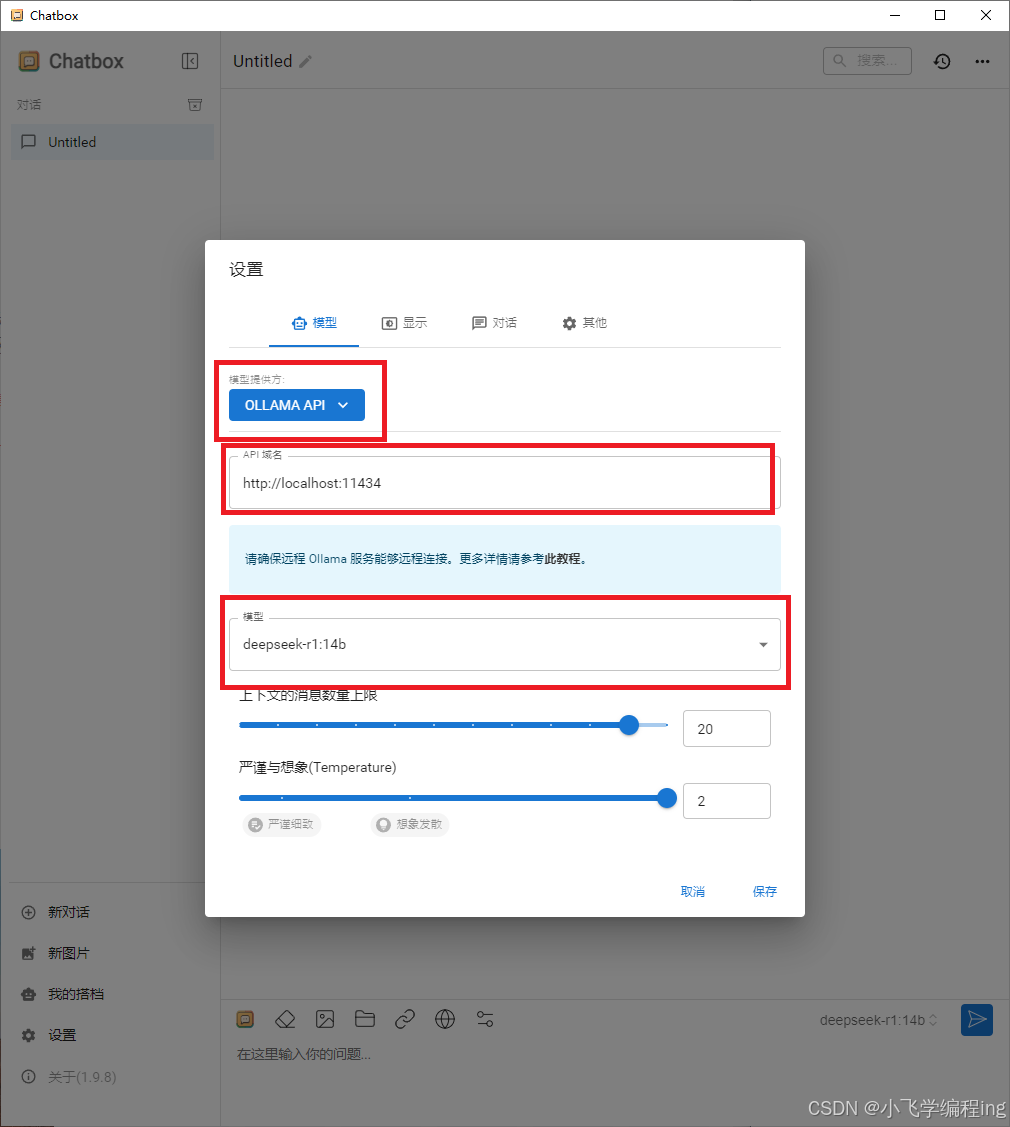
3、设置模型
-
模型提供方选择OLLAMA API
-
API域名默认即可
-
模型选择安装的模型
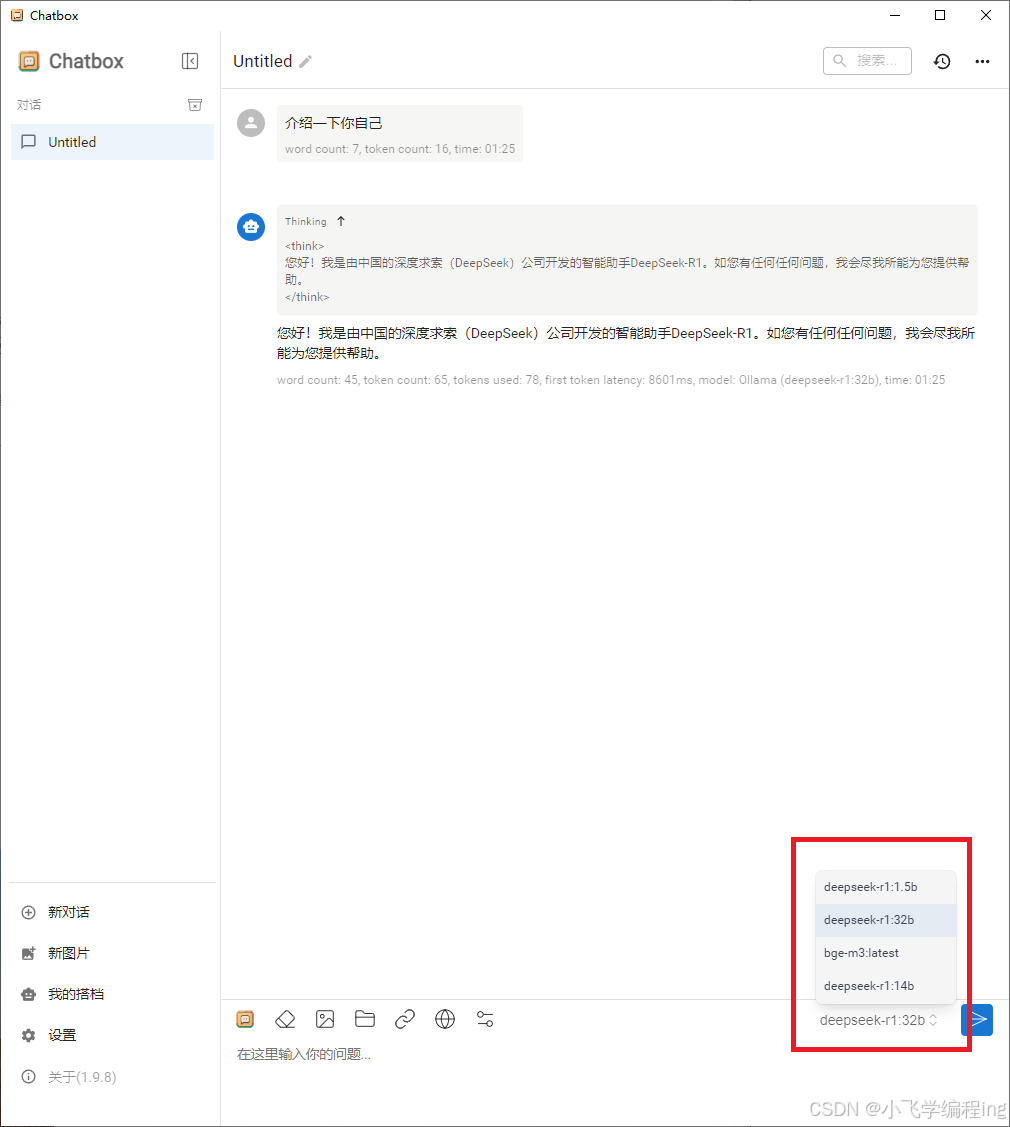
这样就可以在聊天窗中选择你的本地模型进行使用了
OK。到此教程结束,本地部署deepseek完成,可以美美的食用了~~
PS:电脑重启或者ollama启动失败时,可能会出现沟通出现网络错误的报错,重启一下ollama即可
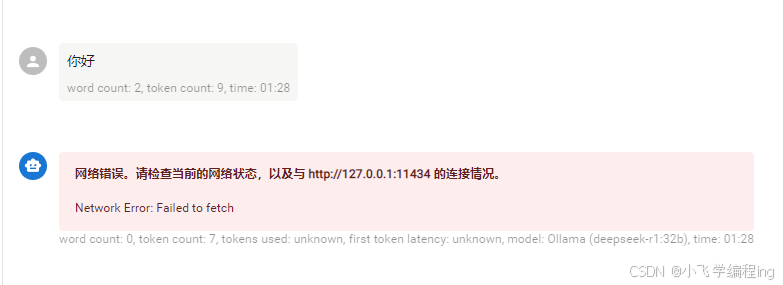
重启ollama方法:开始菜单旁边的搜索框搜索ollama,点击打开即可

目前还在学习探索使用ollama借助国内部署好的模型,接入使用满血deepseek,以及借助anythingLLM搭建自己的专属知识库等问题,后续再继续更新~~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)