DeepSeek开源周第四天|并行革命!三连开黑科技让大模型训练效率狂飙
双向流水线并行算法,实现计算和通信完全重叠。:专家并行负载均衡器。:分析 V3/R1 中计算与通信重叠的性能数据集。DualPipe是在DeepSeek-V3中首次出现双向流水线并行算法,(Forward Pass)(模型处理输入数据)和Backward Pass)(模型更新权重)的计算 - 通信阶段完全重叠,同时减少了 "" (Pipeline Bubbles)—— 即计算设备的空闲等待时间,通
开源周第四日,针对优化并行策略、重构并行计算,一口气霸气推出了三大开源利器:
-
DualPipe:双向流水线并行算法,实现计算和通信完全重叠。
-
EPLB:专家并行负载均衡器。
-
Profiling Data :分析 V3/R1 中计算与通信重叠的性能数据集。

DualPipe
DualPipe 是在DeepSeek-V3中首次出现双向流水线并行算法,前向计算过程(Forward Pass)(模型处理输入数据)和后向计算过程(Backward Pass)(模型更新权重)的计算 - 通信阶段完全重叠,同时减少了 "流水线气泡" (Pipeline Bubbles)—— 即计算设备的空闲等待时间,通过采用对称的微批次调度,优化了并行计算效率。
双向微批次调度策略,核心特点:
-
对称设计:反向方向的微批次与前向方向对称排列,形成一种几何平衡的调度结构
-
计算-通信重叠:两个共享黑色边框的单元格表示相互重叠的计算和通信过程
-
双向并行:同时在两个方向上推进微批次,最大化硬件利用率
调度策略与示例

8个流水线并行节点(PP ranks) 和 20个微批次(micro-batches) 的DualPipe调度示例。反向微批次(reverse micro-batches)与前向微批次(forward micro-batches)采用对称设计,为简化图示省略了反向微批次的批次ID(batch ID)。共享黑色边框的单元格表示计算与通信的相互重叠部分(mutually overlapped computation and communication)
流水线气泡与内存占用对比

符号说明:
-
𝐹:前向计算块(forward chunk)执行时间
-
𝐵:完整反向计算块(full backward chunk)执行时间
-
𝑊:“权重反向计算块”(backward for weights chunk)执行时间
-
𝐹&𝐵:前向与反向计算块重叠执行时间
此对比表明,DualPipe在气泡时间和激活内存占用上显著优于传统方法(如1F1B、ZB1P),尽管参数存储需求略高(2×),但通过重叠设计提升了整体效率
EPLB
EPLB:是为专家并行EP(Expert Parallelism)设计的动态负载均衡器。解决MoE模型在分布式训练和推理中不同GPU间负载不均衡的问题
EPLB解决策略
-
冗余专家策略
当某些专家(expert)因当前工作负载(如MoE层的门控权重分布)导致计算量过大时,EPLB会动态复制高负载专家(duplicate heavy-loaded experts),并将冗余副本分配到不同GPU,避免单一GPU成为性能瓶颈。
-
EPLB的负载均衡算法策略
分层负载均衡(Hierarchical Load Balancing):当服务器节点数量能整除专家组数量时,会采用分层负载均衡策略。首先将专家组均匀地打包到节点上,确保不同节点的负载平衡,然后在每个节点内复制专家,最后将复制的专家打包到各个GPU中,以确保不同GPU负载均衡。这种策略适用于预填充阶段且专家并行规模较小的情况。
全局负载均衡(Global Load Balancing):在其他情况下,则采用全局负载均衡策略,即不考虑专家组,对专家进行全局复制,并将复制的专家打包到各个GPU中。该策略适用于解码阶段且专家并行规模较大的情况。
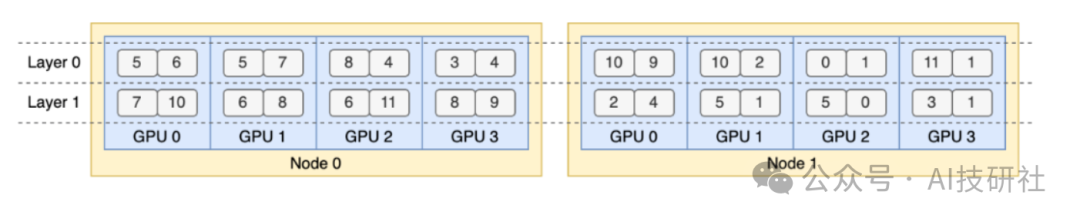
负载均衡器的主要函数为eplb.rebalance_experts。官方提供了一个两层混合专家(MoE)模型的示例代码,每层包含12个专家,每层引入4个冗余专家,总共16个副本放置在2个节点上,每个节点包含4个GPU。通过运行该示例代码,输出的结果可以展示由分层负载均衡策略生成的专家复制和放置计划。
Profiling Data
Profiling Data(性能剖析数据): DeepSeek公开了其训练和推理框架的性能分析数据,以帮助AI研究与开发社区更好地理解计算-通信重叠策略以及底层实现细节。
训练阶段
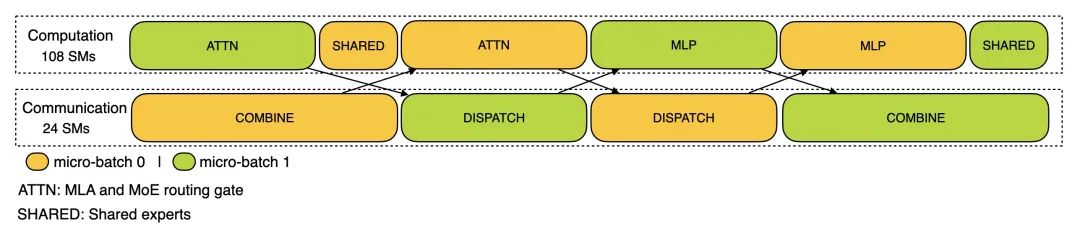
训练分析数据展示了 DualPipe 中单个前向和后向处理块对的重叠策略。每个处理块包含 4 个 MoE (Mixture of Experts)(混合专家模型)层,并行配置与 DeepSeek-V3 预训练设置一致:EP64(64 路专家并行),TP1(无张量并行 Tensor Parallelism),4K 序列长度。

推理阶段
-
预填充阶段 (Prefilling Stage):使用 EP32 和 TP1 配置,提示长度为 4K,每 GPU 批量大小为 16K 个 token。在预填充阶段,使用两个微批次交错进行计算和全对全通信 (All-to-All Communication),同时确保注意力计算负载在两个微批次间平衡。
-
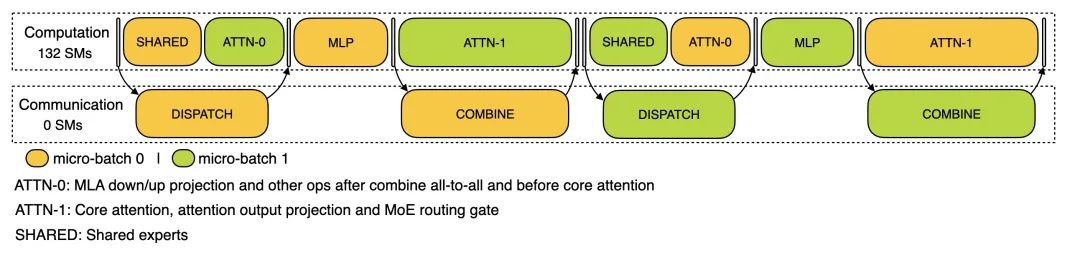
解码阶段 (Decoding Stage):使用 EP128 和 TP1 配置,提示长度 4K,每 GPU 批量大小为 128 个请求。与预填充类似,解码也利用两个微批次重叠计算和全对全通信。但与预填充不同的是,解码期间的全对全通信不占用 GPU 计算单元(Stream Multiprocessors, SMs)—— 网络通信消息发出后,所有 GPU 计算资源被释放用于其他计算,系统在计算完成后等待通信完成。
行业冲击波:低成本训练时代来临
-
中小团队的逆袭机会:用消费级GPU(如RTX 4090)即可训练千亿参数模型,硬件成本直降90%。
-
MoE模型平民化:EPLB让分布式MoE训练不再是大厂专利,开源社区已出现基于DualPipe+EPLB的“千元级MoE训练方案”。
-
开源生态闭环:与FlashMLA(推理加速)、DeepGEMM(矩阵计算)组成技术矩阵,开发者可像搭积木一样构建AI基础设施。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)