【论文阅读笔记】Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
本文详述了deepseek关于Native Sparse Attention中关于transformer运算上的改造
一句话总结
<缝合>了之前几种长序列选择注意力机制的<半稀疏> 注意力运算模块,并把算法写到了Triton 上,总体上,模型的准确率表现有提升但不巨大,运算效率上提升显著。
方法概览(算法部分)
** 本篇blog主要是描述Native Sparse Attention在Attention模块运算上的改造。他们这篇文章还有一个重要改造就在GPU的运算逻辑上。这部分后面单开一篇整理
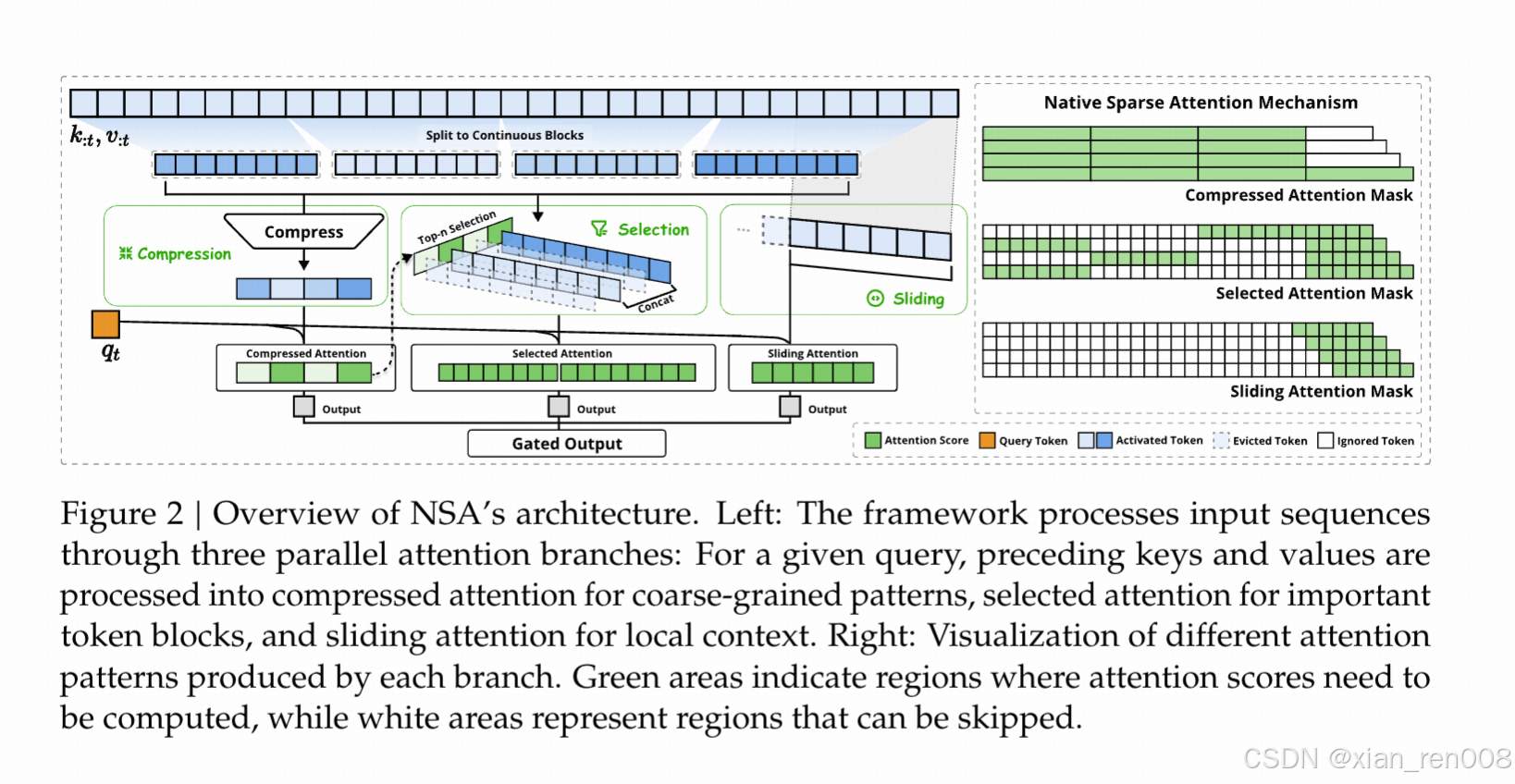
主要改动在于减少Attention中 KV的长度,为此做了三个动作
1. 整个序列先切块,按照块压缩,再做 attention 运算,形成 result1
2. 截选优质的块,做
3. 选最近一个块,做qk(不跟1.2 混着算)
另外这个图其实跟一些同类论文的画图顺序有点不一样,一般讲transformer结构改造的论文 数据流多数是从下往上画的(就是输入的xToken序列在图的最下面,然后通过若干运算到达图的最上面),他这个是从上往下画,所以乍一看容易让人蒙一下,但实际表述还是很清楚的。
展开说说
下面会统一用block来表示块(之前的长序列transformer的论文里,通常会使用chunk,我这里猜测主要是为了和后面应建预算那里的术语打通,所以统一用的block)
分Block压缩
操作上,简单的说
- 使用rolling window strategy(时序领域里常用这个说法,换成图像领域其实就相当于是1D convolution)把序列切成若干个Block。
- 把每个Block都拍扁了:用MLP在seq维度上做降维映射。
- 把拍扁了的block连成一个新的短序列和Q做QK的运算
比如一个seq_len=24的 token sequence,shape 是[batch_size, 24, hidden_dim]
第一步:按照窗口长度=8,stride=4,切成5个快
第二步:每个块用一个MLP压缩成这个shape [..., 1 , hidden_dim]
第三步:这样形成的K^cmp,其shape为[batch_size, 5, hidden_dim] ,做QK运算
选择优质Block
虽然文中的名字是TokenSelection,但是这个称呼其实比较容易混淆。因为整个操作都是在Block这个水平上操作的。
操作上,仍然是高度简化版本(后面再说我主要简化了什么)
- 还是先把全系列切成若干个Block
- 每个Block用MLP压缩
- 用压缩过的 K c m p K^{cmp} Kcmp 和 Q Q Q做QK的运算,形成一个<重要性分>
- 选出<重要性分>最大的top-k个Block 并生成一个Token level的 attention mask
- 用 Q Q Q 和 K K K 和4 中做出来的attention mask 做QK的运算(这样就相当于是Q和仅有的K个Block的 K tokens 做QK的运算,不单运算少,还好并行)
说说我简化了什么
- 从操作步骤上看,这个部分的1-3 是和上面分Block压缩是一致的,那在实践中也确实没必要算两遍,但是压缩块的大小和优质块的大小是可以不一样的,当不一样的时候,又不想重算应该怎么做映射呢?我把论文里的公式贴出来
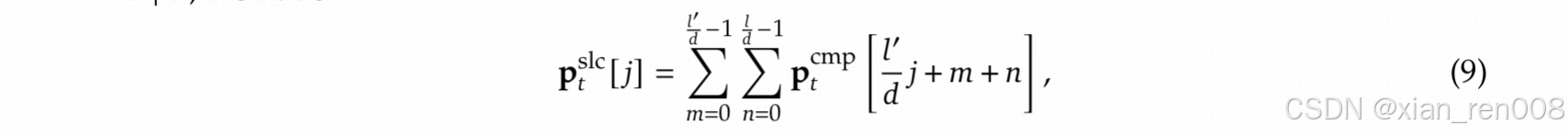
- 针对在GQA MQA这类常用的attention变种怎么执行,这部分跟上面那部分在论文里相近的位置。
- 实际生成过程中,序列seq_len 总是不能被 l l l 或 l ′ l' l′ 整除,怎么处理
拉最近一个Block
文章中之所以称为sliding window,主要是因为随着生成的进度,这个窗口总是当前生成token最近的一个Block。不过用sliding window反而容易产生混淆。
这里操作就一个,就是取最近的n个token作为K,V,和Q做QK的运算。
总结
这回再看作者的图
- 最左边的数据流 是把他token上蓝色的四个区域压缩成四块算attention
- 中间的部分 是借用了左边压缩块的结果,把压缩块中深绿色的Block里的所有token concat到一起形成一个短序列 ,然后和Q做attention
- 右侧 是最近的一个Block的token单独拿出来和Q做attention。
- 最右侧的三个网格–>而在真正执行的时候,是按照上面的逻辑算出三个mask来和做attention的运算函数对接的。
评价
从作者角度出发
- 作者的初衷是从优化角度上考虑的,主要目标还是在运算和存储都能打满的角度设计运算kernel
- 作者提到的trainable主要是压缩MLP这部分会随着训练而一起优化比固定规则强很多。
从同行的角度出发
- 之所以我称他为<半稀疏>,主要是这里取的Token基本上都是连续在某个窗口内的,不像Informer/LogFormer等等在Token级别抽取的方案,当然这在很多任务上都是非常合理的,而且也是并行效率很高的一种做法。
- 之所以我称他<缝合>了很多同类方法,主要是在时序和长文本领域 分块,分块压缩,选top-k,选最近一个window,其实都是21年前后大量时序transformer玩儿过的方案。
特别是分块和选择topk重要的块进行token concat这部分,21年我被IJCAI拒了的时序采样网络写的就是这个东西(当然我没那个实力连运算一起优化了,我就当审稿人拒我很有理吧)
- 分块机制的合理性:由于softmax的机制
导致在超长序列上做Attention甚至可以约等价于在超长序列上做RAG。
即便是把完整的KV算了,但在softmax影响下还是会丢很多信息,尤其是在相对位置编码加成下,更是如此。因此,从减少运算角度上说这个方法是非常合理的。
4. 分块优选的隐含风险:其实是有两个,一个运算处理不够简单,这也是在长文本领域里众多Transformer变种最终都没有打败直接并行运算的原因(Flash Attention),另外一个是分块选择这个设计仍然是有一个注入的设计bias,就是
与任务相关的信息会相对密集的存在于长序列的少量片段中。
这个假设在时序预测的层面上是容易站得住脚,但在文本处理领域是否完全站得住脚,我打个问号。(倒不是说这个一定不对,是我也没把常见任务逐个拿起来分析过)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)