论文解析:DeepSeek-R1的创新及其在LLM领域的重要意义
DeepSeek打破了“SFT+RL”的传统范式,证明了纯强化学习激发推理能力的可行性,在降低数据依赖、提升模型自主性、推动训练方法革新等方面具有里程碑意义。它既为学术界开辟了新研究方向(如无SFT的RL理论),也为工业界提供了高效训练框架,可能成为下一代大模型训练的基石技术。
1. 研究背景与核心贡献
近年来,大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得了显著进展,但其推理能力的提升仍面临诸多挑战。传统方法主要依赖监督微调(Supervised Fine-Tuning, SFT)和标注数据,但这种方式成本高昂且难以覆盖复杂推理场景。DeepSeek-AI 团队提出的 DeepSeek-R1 系列模型,通过纯强化学习(Reinforcement Learning, RL)和多阶段训练策略,在无需大量标注数据的情况下显著提升了模型的推理能力,并开源了多个规模的蒸馏模型,为研究社区提供了重要参考。
核心创新点

纯强化学习驱动的推理能力
- DeepSeek-R1-Zero 是首个完全通过大规模 RL 训练(无 SFT 阶段)实现高性能推理的模型。其展示了 RL 在激励模型自主发展复杂推理行为(如自我验证、反思、长链思维)中的潜力。
- 通过 GRPO(Group Relative Policy Optimization)算法优化策略,显著降低了 RL 训练成本,同时保持性能。
冷启动与多阶段训练优化
- DeepSeek-R1 在 R1-Zero 基础上引入冷启动数据(少量高质量长链思维示例),结合多阶段 RL 和 SFT,解决了可读性差、语言混合等问题,最终达到与 OpenAI-o1-1217 相当的推理性能。
推理能力的蒸馏技术
- 将 DeepSeek-R1 的推理能力迁移至小规模模型(1.5B~70B),验证了知识蒸馏的有效性。例如,蒸馏后的 14B 模型在部分基准测试中超越 QwQ-32B-Preview。
系统性实验与开源贡献
- 在数学、编程、科学推理等 20+ 基准测试中全面验证性能,并开源模型与训练流程,推动社区研究。
2. 方法详解:从 DeepSeek-R1-Zero 到 DeepSeek-R1
2.1 DeepSeek-R1-Zero:纯强化学习的突破
核心思想:直接从基础模型(DeepSeek-V3-Base)启动 RL 训练,探索无监督条件下模型的自我进化能力。这项研究打破了“SFT+RL”的传统范式,证明了纯强化学习激发推理能力的可行性,在降低数据依赖、提升模型自主性、推动训练方法革新等方面具有里程碑意义。它既为学术界开辟了新研究方向(如无SFT的RL理论),也为工业界提供了高效训练框架,可能成为下一代大模型训练的基石技术。
技术实现
强化学习框架
- 采用 GRPO 算法,通过分组采样(每组 G 个输出)估计基线值,避免传统 PPO 中需额外训练评判模型的复杂性。优势函数计算为:
- 目标函数结合策略优化与 KL 散度约束,防止策略偏离参考模型过多。
奖励设计
-
准确性奖励:基于规则验证答案正确性(如数学问题答案格式匹配、代码编译测试)。
-
格式奖励:强制模型将推理过程封装在
<think>和<answer>标签中,确保输出结构化。
自我进化现象

-
模型在训练中自发涌现出反思、多步验证等行为(“顿悟时刻”)。例如,面对复杂方程时,模型会重新审视初始步骤并修正错误。
性能表现
-
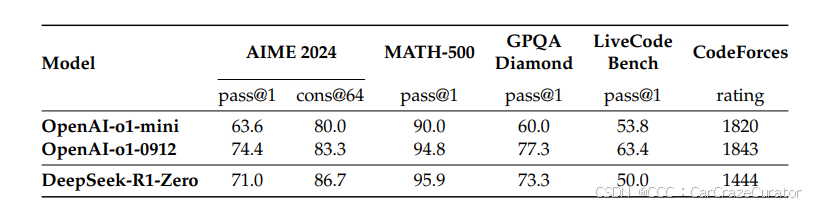
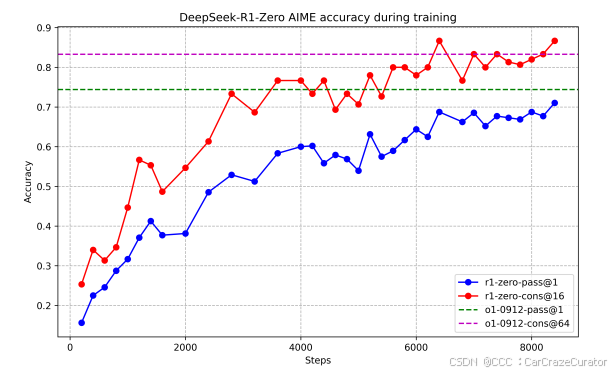
在 AIME 2024 数学竞赛中,Pass@1 从初始 15.6% 提升至 71.0%,多数投票(64 样本)后达 86.7%,与 OpenAI-o1-0912 相当。
-
语言混合与可读性问题成为主要瓶颈,促使后续改进。
2.2 DeepSeek-R1:冷启动与多阶段训练
核心改进:引入冷启动数据(数千条高质量长链思维示例)和多阶段训练流程,平衡推理能力与用户友好性。
训练流程
冷启动阶段
-
通过少量人工设计的 CoT 数据微调基础模型,确保初始输出的可读性与格式规范。
-
输出模板设计为
<reasoning_process>后接<summary>,强化结构化表达。
推理导向的强化学习
-
在冷启动模型上应用与 R1-Zero 相同的 RL 训练,但新增 语言一致性奖励,抑制中英文混合问题。
拒绝采样与监督微调
-
RL 收敛后,通过拒绝采样生成 60 万条高质量推理数据,并结合 20 万条非推理任务数据(写作、事实问答等)进行 SFT。
-
最终模型通过第二轮 RL 对齐人类偏好(有用性、无害性)。
性能对比
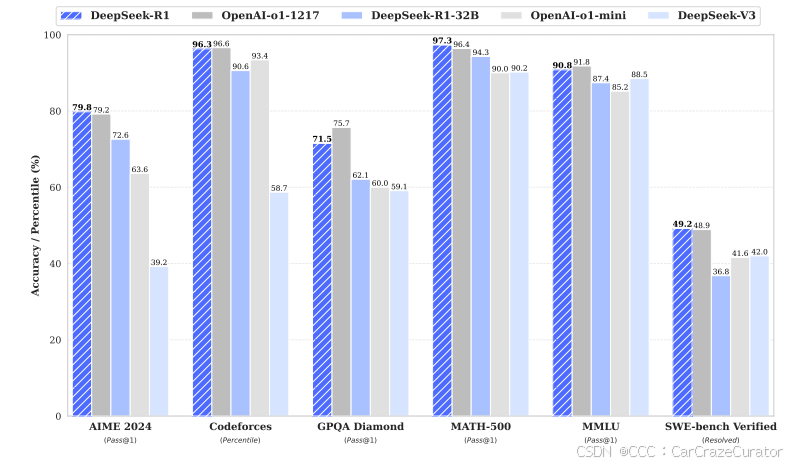
-
在 MATH-500 上 Pass@1 达 97.3%,与 OpenAI-o1-1217 持平;Codeforces 竞赛评分 2029,超越 96.3% 人类参赛者。
-
知识类任务(MMLU、GPQA)表现优异,但中文 SimpleQA 因安全对齐略有下降。
2.3 蒸馏技术:小模型的大潜力
核心策略:将 DeepSeek-R1 生成的 80 万条数据用于微调开源小模型(Qwen、Llama 系列),仅用 SFT 即实现显著提升。
实验结果
-
DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上 Pass@1 达 55.5%,超越 QwQ-32B-Preview。
-
DeepSeek-R1-Distill-Llama-70B 在 LiveCodeBench 上 Pass@1 达 57.5%,接近 o1-mini 水平。
技术意义:验证了蒸馏在资源受限场景下的可行性,同时表明小模型依赖纯 RL 训练难以匹敌蒸馏效果。
3. 实验分析与技术讨论
3.1 基准测试全面领先
表 4 显示,DeepSeek-R1 在多项任务中超越主流模型:
-
数学推理:AIME 2024 Pass@1 79.8%,CNMO 2024 Pass@1 78.8%。
-
编程能力:Codeforces 竞赛评分 2029(超越 96.3% 人类),LiveCodeBench Pass@1 65.9%。
-
知识问答:MMLU 90.8%,GPQA Diamond 71.5%。
3.2 失败尝试与启示

-
过程奖励模型(PRM):因难以定义细粒度步骤且易引发奖励黑客问题,最终未采用。
-
蒙特卡洛树搜索(MCTS):在 token 生成空间中的局部最优问题限制了其扩展性。
3.3 蒸馏 vs. 强化学习

实验表明,直接对小模型进行大规模 RL 训练(如 Qwen-32B)效果有限,而蒸馏能更高效迁移推理能力。这说明:
-
知识蒸馏是经济高效的方案,但突破智能边界仍需更大基模型与 RL 结合。
4. 创新总结与未来方向
4.1 核心创新
-
纯 RL 激励推理:首次验证无需 SFT 即可通过 RL 激发模型自主推理能力,为无监督学习开辟新路径。
-
冷启动数据设计:通过少量高质量数据引导模型输出规范化,解决 RL 初期不稳定性。
-
多阶段训练框架:RL 与 SFT 交替优化,兼顾性能与对齐需求。
-
开源生态贡献:发布 1.5B~70B 蒸馏模型,降低社区研究门槛。
4.2 局限与未来工作
-
语言混合:当前模型优化以中英文为主,其他语言场景存在混合问题。
-
工程任务瓶颈:因评估耗时,软件工程任务的 RL 训练尚未充分开展。
-
提示敏感性:模型对零样本提示依赖较强,少样本提示可能降低性能。
未来方向:
-
探索长链思维在多功能调用、多轮对话中的应用。
-
开发异步评估框架,加速工程类任务的 RL 训练。
-
扩展多语言支持与降低提示敏感性。
5. 结论
DeepSeek-R1 系列通过纯强化学习与多阶段优化,显著提升了语言模型的推理能力,并在开源社区中树立了新的标杆。其技术路径不仅验证了 RL 在复杂任务中的潜力,也为小模型的高效部署提供了可行方案。尽管存在部分局限性,但其在数学、编程、知识推理等领域的卓越表现,标志着 LLM 向通用人工智能(AGI)迈出了坚实一步。
参考文献:DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1 · GitHub

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)