聊聊DeepSeek训练——基于强化学习训练的底层逻辑
在接触DeepSeek时,就有疑问:是怎么基于RL算法训练的?就一句GRPO算法的介绍吗?GRPOTrainer[1]类是HuggingFace官方基于GRPO算法的实现,DeepSeek官方paper地址:GRPO[2]。Group Relative Policy Optimization(GRPO)是一种用于强化学习和自然语言处理的优化算法,旨在改进策略优化过程,尤其适用于处理文本生成等任务。
❝
聊聊从GRPO RL算法实现来看大模型的训练逻辑
概述
在接触DeepSeek时,就有疑问:是怎么基于RL算法训练的?就一句GRPO算法的介绍吗?
GRPOTrainer[1]类是HuggingFace官方基于GRPO算法的实现,DeepSeek官方paper地址:GRPO[2]。
Group Relative Policy Optimization(GRPO)是一种用于强化学习和自然语言处理的优化算法,旨在改进策略优化过程,尤其适用于处理文本生成等任务。
其算法原理如下
-
基于相对优势: GRPO 算法关注的是组内样本之间的相对优势,而非绝对的奖励值。在一个批次的样本中,它通过比较不同样本的奖励来确定每个样本的相对优劣,以此作为优化策略的依据。这种相对优势的计算可以减少奖励函数的偏差和方差,使训练更加稳定。
-
策略优化: 其核心目标是优化策略网络,使得智能体在面对不同的输入时,能够选择更有可能获得高相对奖励的动作。通过不断调整策略网络的参数,让智能体逐渐学习到最优的行为策略。
GRPO算法公式如下:



计算流程图如下:
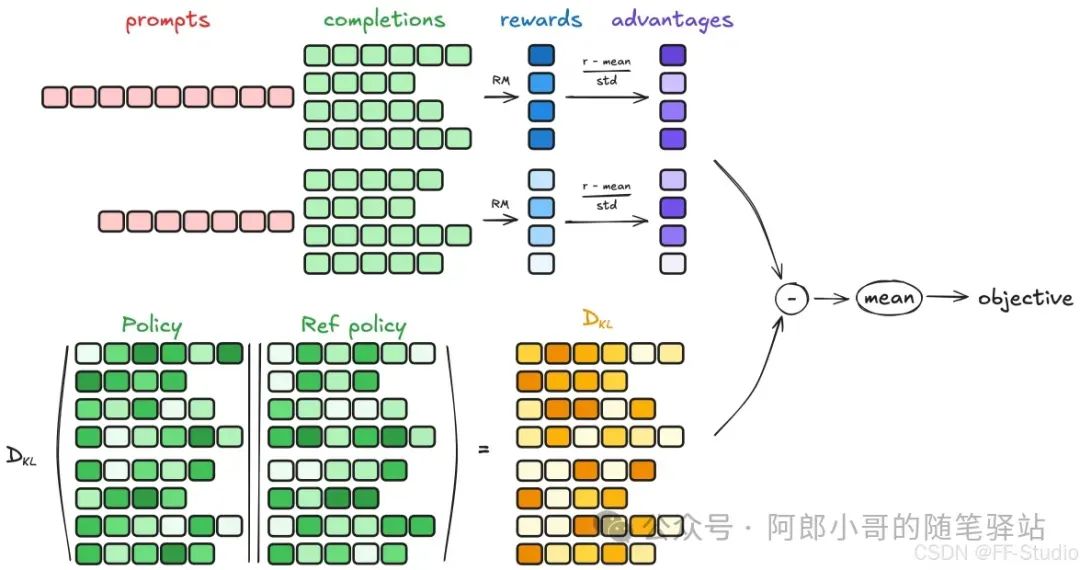
源码
GRPOTrainer继承自Trainer类,在Trainer类中封装了很多的训练逻辑,GRPOTrainer只需要实现该算法必要的步骤即可。
示例调用:
from datasets import load_dataset
from trl import GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs="weqweasdas/RM-Gemma-2B",
train_dataset=dataset,
)
trainer.train()
代码结构:
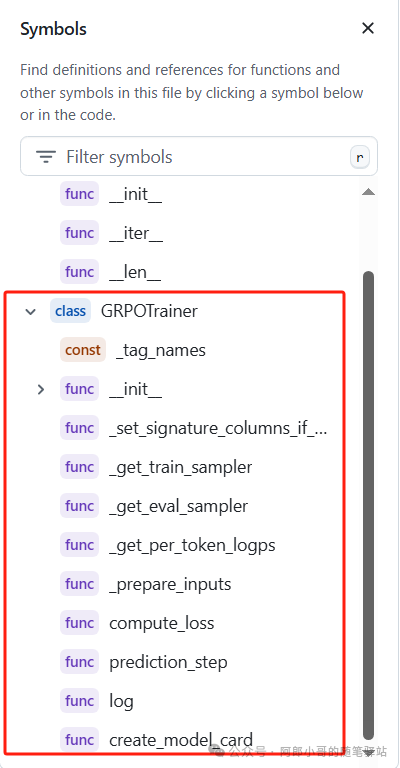
总的来说,prediction_step、compute_loss、_prepare_inputs、_get_per_token_logps四个函数是GRPO算法的关键实现,同时结合父类Trainer,即可实现神经网络模型的前向迭代、反向传播,损失计算、梯度更新等训练流程。
prediction_step
该方法在父类Trainer中调用,而GRPOTrainer重写了该方法,最终会返回计算后的loss。
def prediction_step(self, model, inputs, prediction_loss_only, ignore_keys: Optional[list[str]] = None):
# 预处理输入的input
inputs = self._prepare_inputs(inputs)
with torch.no_grad():
with self.compute_loss_context_manager():
# 计算loss
loss = self.compute_loss(model, inputs)
loss = loss.mean().detach()
# 返回loss值
return loss, None, None
_prepare_inputs
预处理输入的input,在这里会计算completion(即model的返回值)、reward值、GRPO算法的advantage值等,并最终都返回;其中GRPO算法的advantage计算公式为:
:平均值
:标准差
看看最后返回的结构与注释:
{
"prompt_ids": prompt_ids, # prompt对应的数字表示,也可以理解为词元token
"prompt_mask": prompt_mask, # mask掩码
"completion_ids": completion_ids, # model返回的预测值的数字表示,即对prompt的补全
"completion_mask": completion_mask, # mask掩码
"ref_per_token_logps": ref_per_token_logps, # 引用模型的token概率
"advantages": advantages, # GRPO算法的advantage,在Loss计算需要用到
}
关键代码片段及注释:
def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:
# 处理输入的query,即prompt
prompts = [x["prompt"] for x in inputs]
prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs]
# 返回prompt的数字表示
prompt_inputs = self.processing_class(
prompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False
)
prompt_inputs = super()._prepare_inputs(prompt_inputs)
prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"]
# .....其它code.....
# ......
# ......
# Generate completions using vLLM: gather all prompts and use them in a single call in the main process
# 使用vllm生成prompt的后续补全信息,即model的输出
all_prompts_text = gather_object(prompts_text)
if self.accelerator.is_main_process:
# 调用模型生成补全
outputs = self.llm.generate(all_prompts_text, sampling_params=self.sampling_params, use_tqdm=False)
completion_ids = [out.token_ids for completions in outputs for out in completions.outputs]
else:
completion_ids = [None] * len(all_prompts_text) * self.num_generations
# 解码输出的ids,将数字表示转换为文本表示
completions = self.processing_class.batch_decode(completion_ids, skip_special_tokens=True)
if is_conversational(inputs[0]):
completions = [[{"role": "assistant", "content": completion}] for completion in completions]
# 计算reward
# 将prompt与model的completion作为参数,传入奖励函数中;具体的奖励逻辑由外部传入的reward_func参数决定
output_reward_func = reward_func(prompts=prompts, completions=completions, **reward_kwargs)
rewards_per_func[:, i] = torch.tensor(output_reward_func, dtype=torch.float32, device=device)
rewards = rewards_per_func.sum(dim=1)
# 根据GRPO算法的advantages
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
# 这里...
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4)
# 最终返回...
return {
"prompt_ids": prompt_ids,
"prompt_mask": prompt_mask,
"completion_ids": completion_ids,
"completion_mask": completion_mask,
"ref_per_token_logps": ref_per_token_logps,
"advantages": advantages,
}
总的来说,GRPO算法的advantage就是在这里计算的,最后返回。
compute_loss
loss计算,在前面做的处理会往inputs中放入一些必要的参数,而在loss计算时,将其作为参数。在这里会计算KL散度,结合之前计算的advantage值,基于GRPO算法的目标函数公式,最终计算出loss。该loss值会在父类Tainer中反向传播应用,并计算梯度。
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"]
completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"]
input_ids = torch.cat([prompt_ids, completion_ids], dim=1)
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)
logits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokens
# 获取词元概率 (model的输出与ref model的输出)
per_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep)
# 计算KL散度
ref_per_token_logps = inputs["ref_per_token_logps"]
per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
# 计算loss:根据advantage,kl散度,基于GRPO算法的目标函数
advantages = inputs["advantages"]
per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1)
per_token_loss = -(per_token_loss - self.beta * per_token_kl)
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
return loss
小结
梳理了一遍GRPO算法的实现,也算是理解了如何基于RL算法来训练LLM。其实对于我个人最早接触RL算法时,是真不太能想想如何基于RL来训练LLM,毕竟的确是蛮复杂的。
通过GRPO算法代码的梳理,结合以前神经网络的基础,目前算是捋顺了神经网络的训练流程(代码实现),而不仅仅停留在理论上;同时也理解了是如何在LLM训练中应用RL算法。
总的来说,基于RL算法中的目标函数,以RL中的奖励机制,对LLM的输出进行打分评价,并计算各个output的优势数值,再基于KL散度来计算loss损失,以此来做反向传播,更新模型梯度,最终达到更好的训练效果。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 22
22 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)