零基础喂饭教程:本地低配置电脑部署deepseek-r1大模型,甚至可以部署最高的671b大模型,只需要做到这一点...
我们今天在低配置甚至无显卡的电脑里,部署国产之光:deepseek-r1大模型,可以根据自己的需求选各个参数的模型,甚至是671b(6710亿参数模型)。安装完成以后,安装程序会自己关闭,如果想判断是否安装成功,就打开命令行。等到出现 Send a message时,就可以输入文字进行沟通使用了。如果能显示出ollama版本,则安装成功。先下载安装OllamaSetup.exe。怎样判断自己可以安
我们今天在低配置甚至无显卡的电脑里,部署国产之光:deepseek-r1大模型,可以根据自己的需求选各个参数的模型,甚至是671b(6710亿参数模型)。
第一步 下载模型:
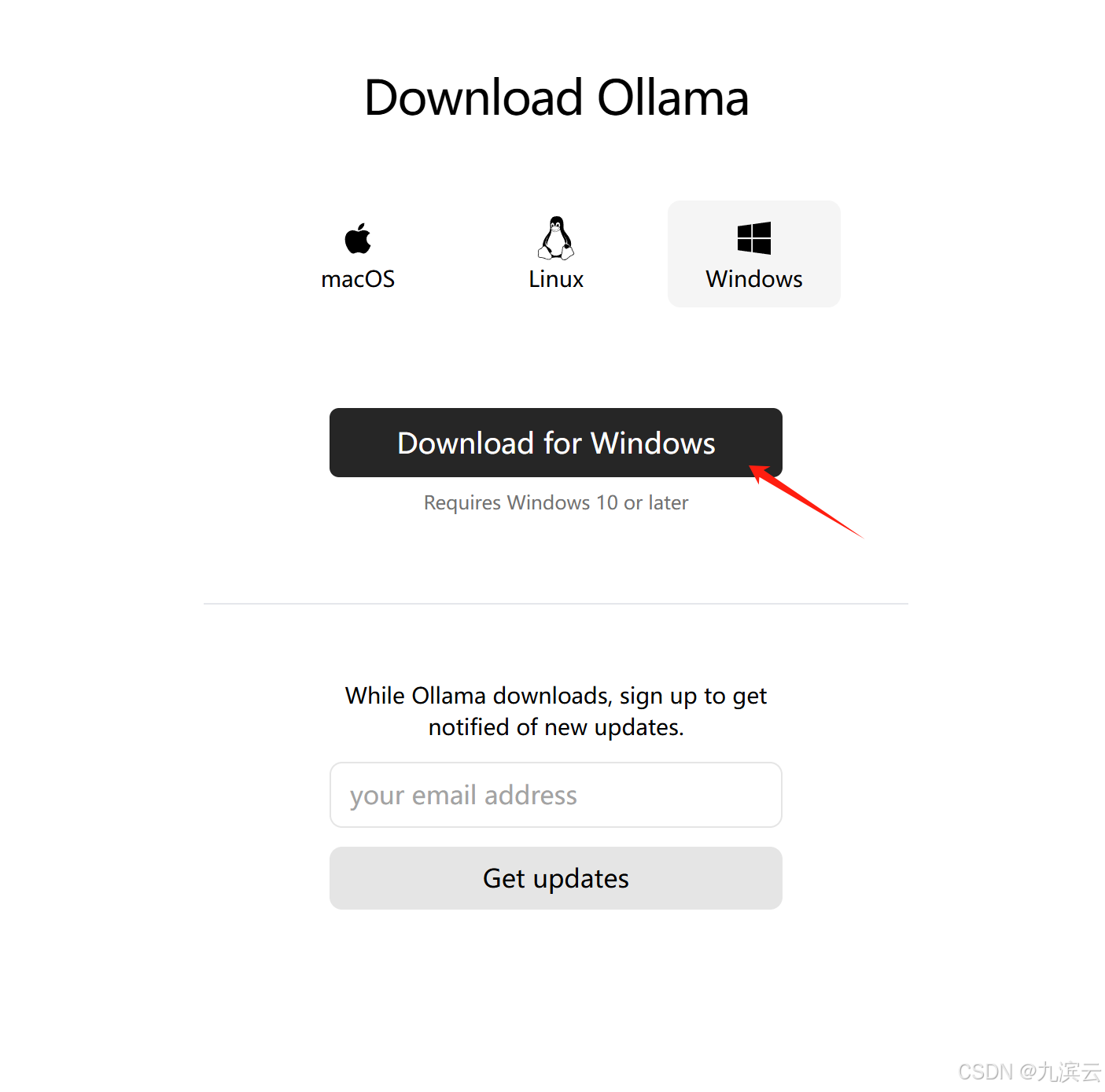
从网站 OllamaGet up and running with large language models.![]() https://ollama.com/下载适合自己的模型:
https://ollama.com/下载适合自己的模型: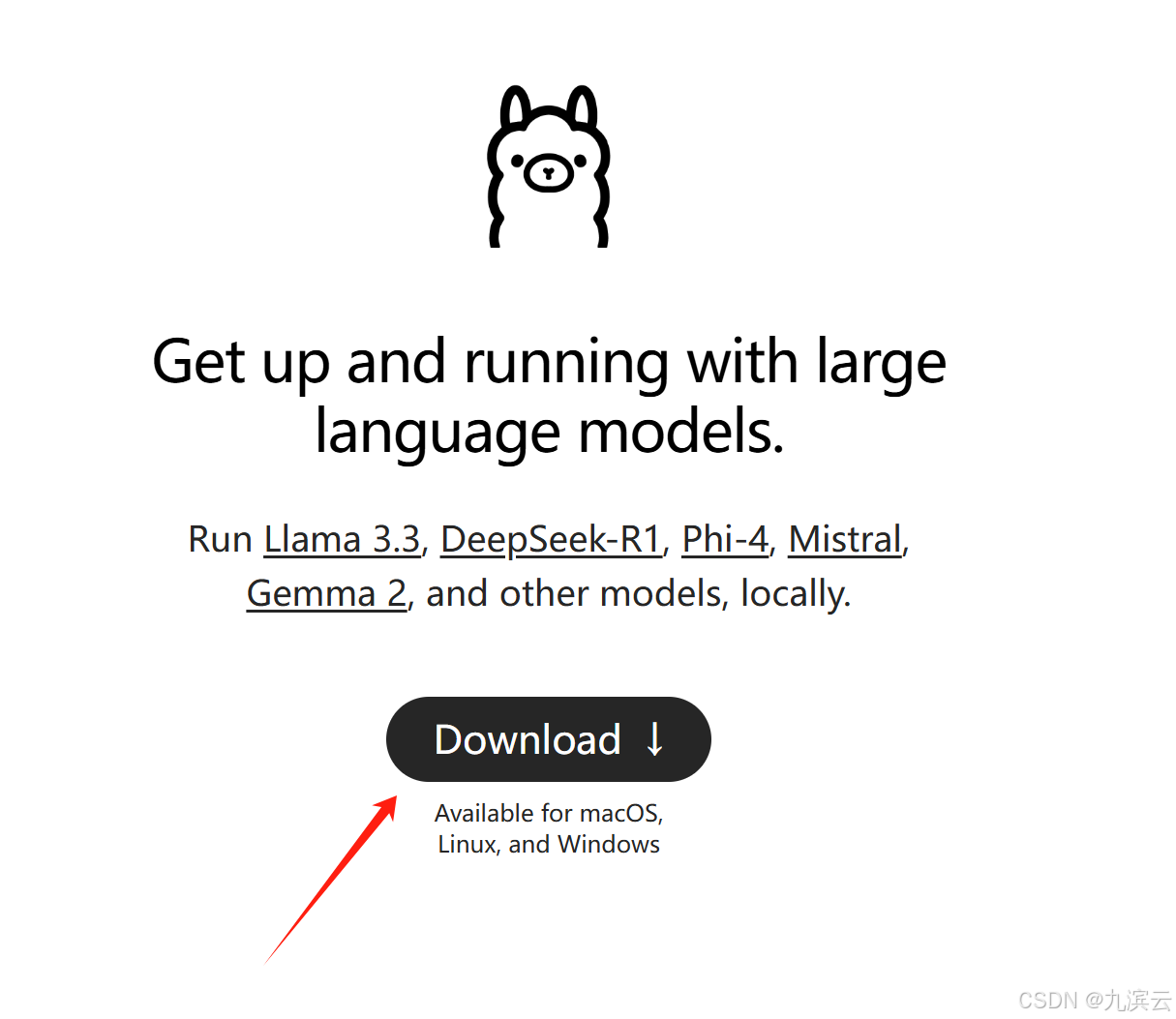
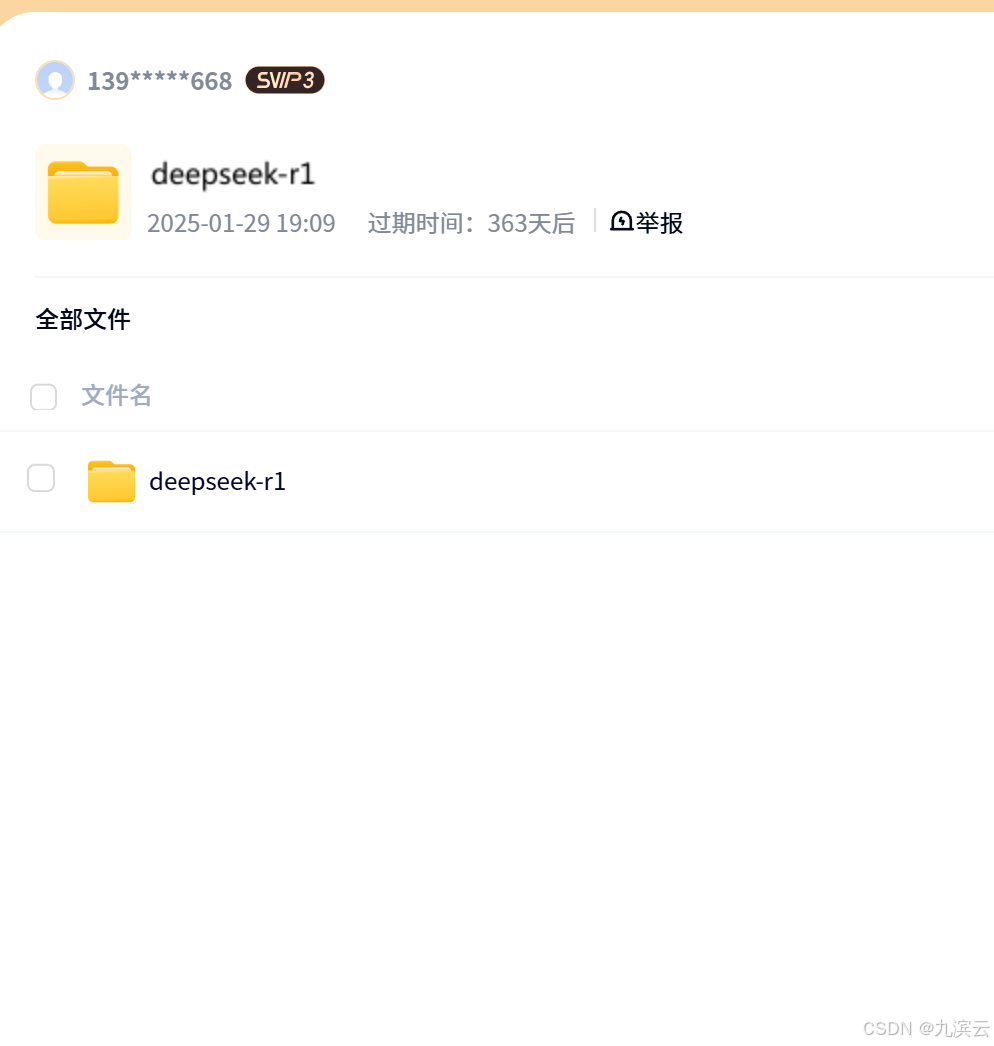
如果打不开上面的网站或者下载不了,可以关注并私信我要云盘的链接,里面不但有ollama,还有deepseek-r1的1.5b、7b、8b、14b、32b、70b、671b的模型文件,网盘内容如下:
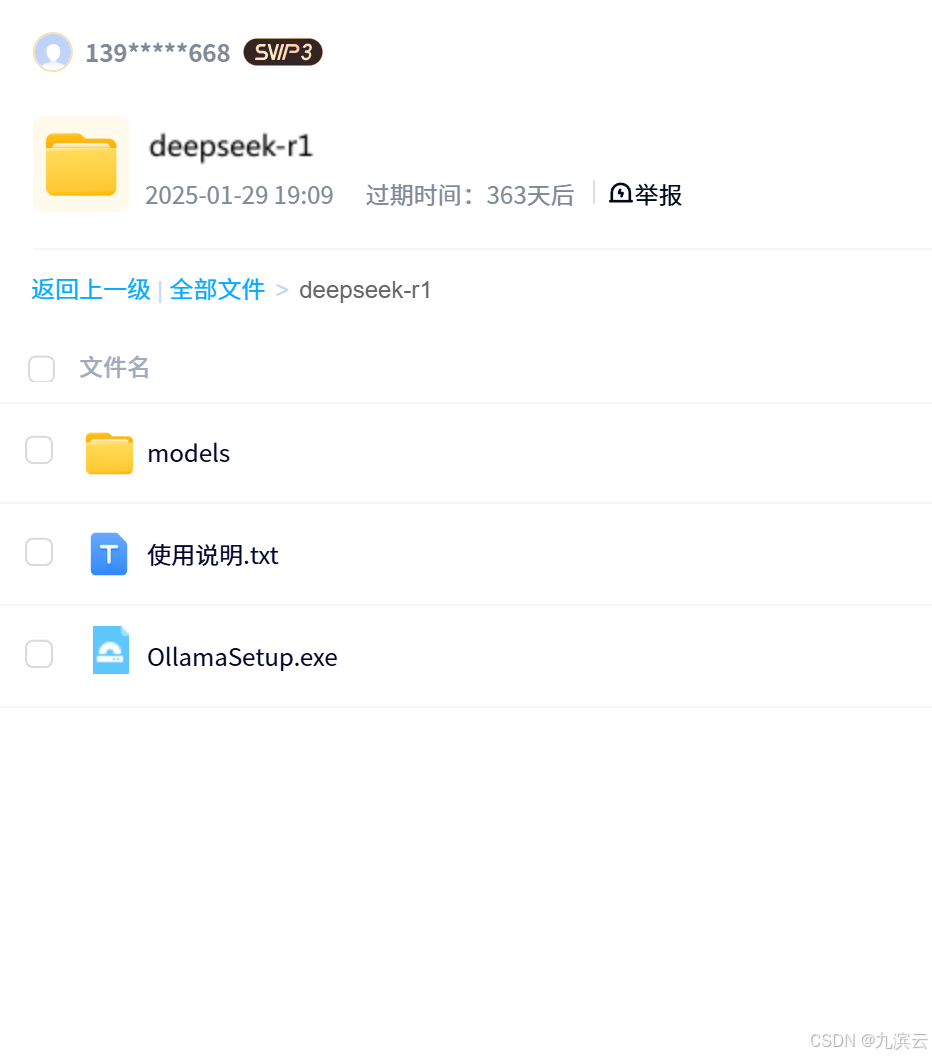
第二步 安装下载好的OllamaSetup.exe

直接点Install安装
第三步 判断是否安装成功
安装完成以后,安装程序会自己关闭,如果想判断是否安装成功,就打开命令行
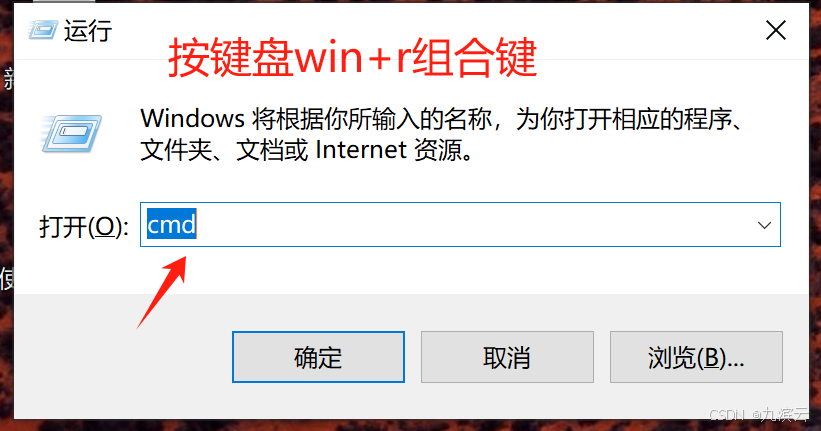
输入命令:ollama -v
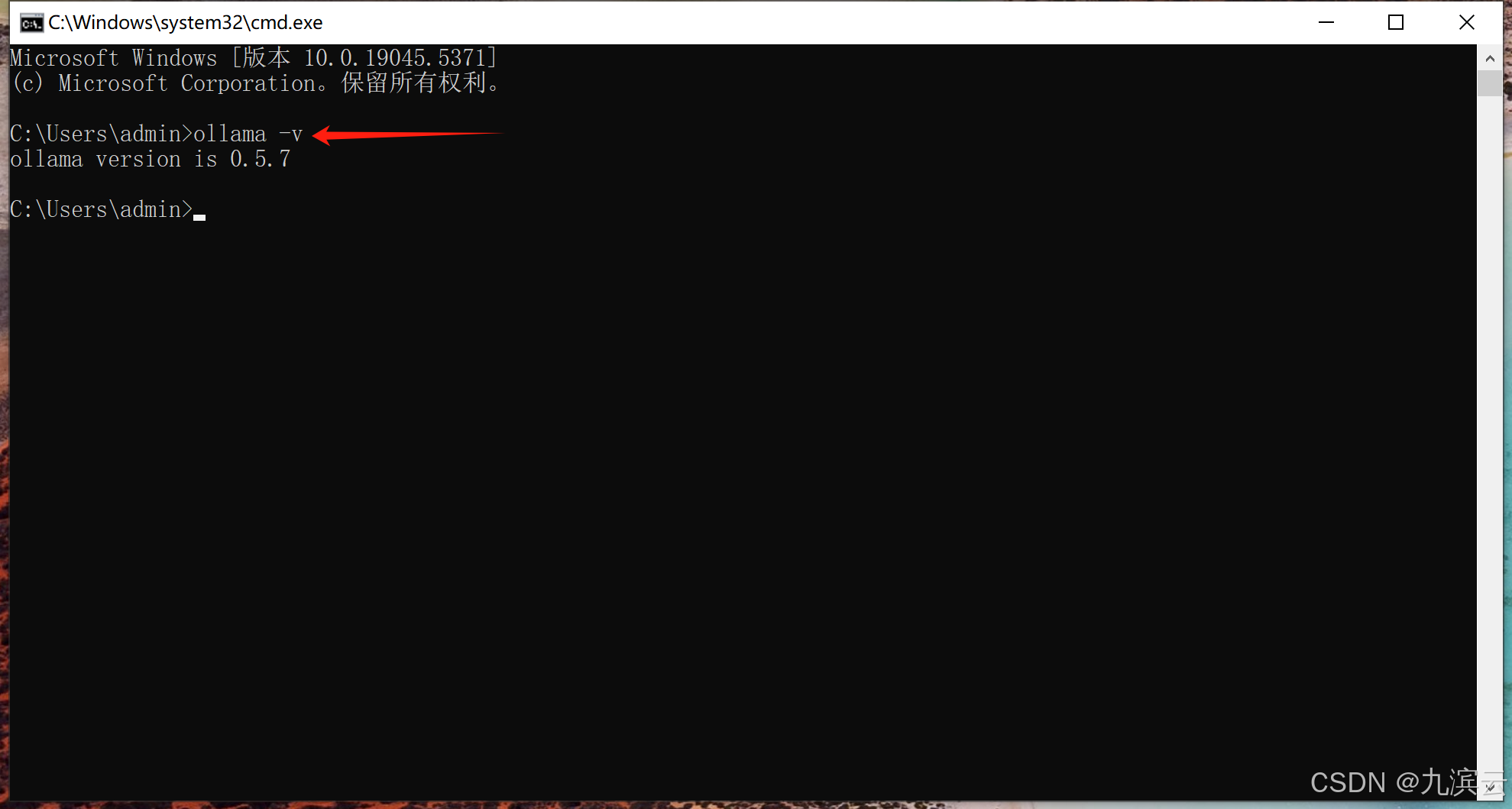
如果能显示出ollama版本,则安装成功。
第四步 下载并运行大模型
安装成功后,想运行哪个大模型,就运行哪个指令:
1.5b:ollama run deepseek-r1:1.5b
7b:ollama run deepseek-r1:7b
8b:ollama run deepseek-r1:8b
14b:ollama run deepseek-r1:14b
32b:ollama run deepseek-r1:32b
70b:ollama run deepseek-r1:70b
671b:ollama run deepseek-r1:671b系统会自动下载模型,并且最后运行,等待下载完成就行:
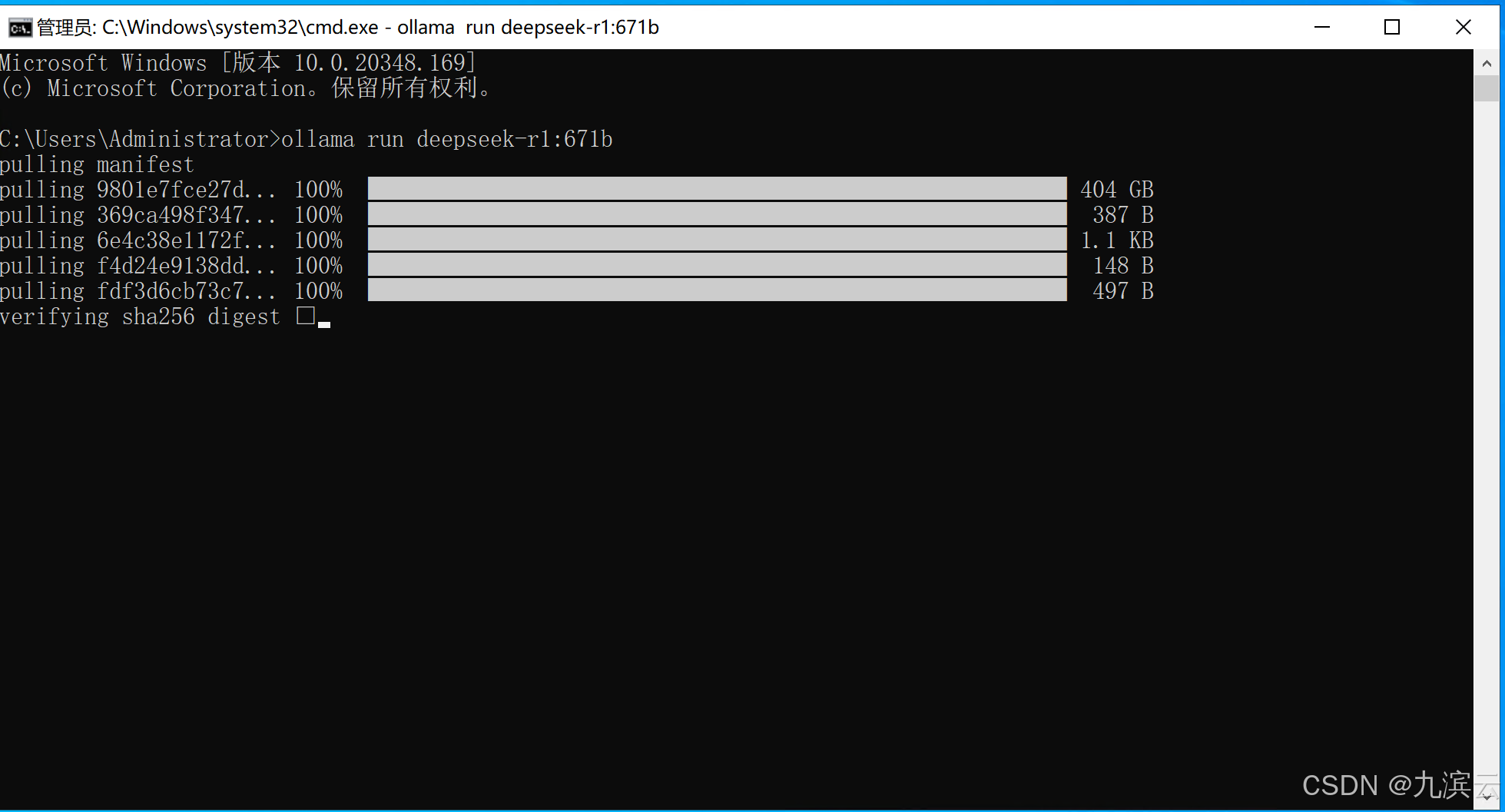
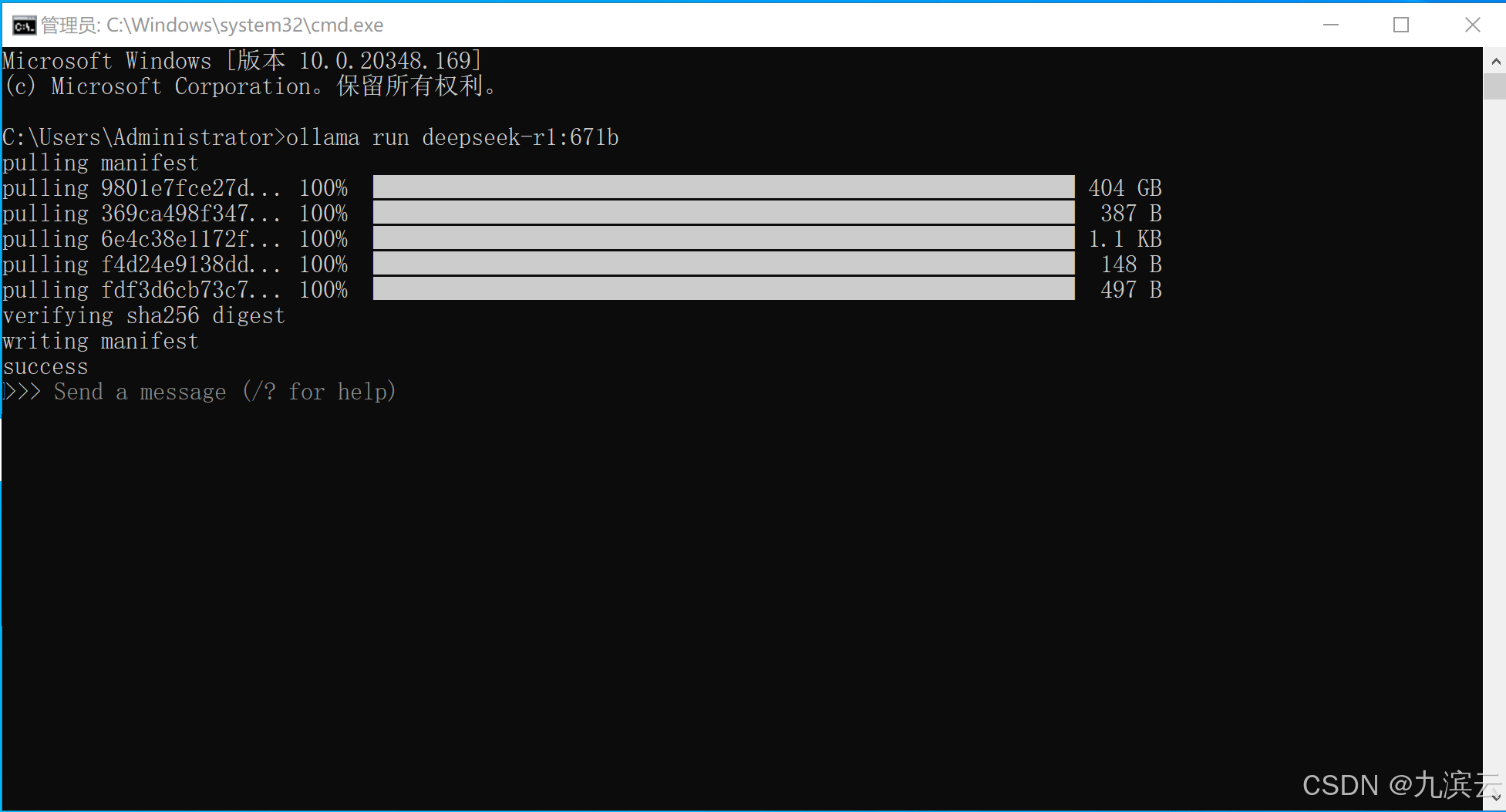
等到出现 Send a message时,就可以输入文字进行沟通使用了
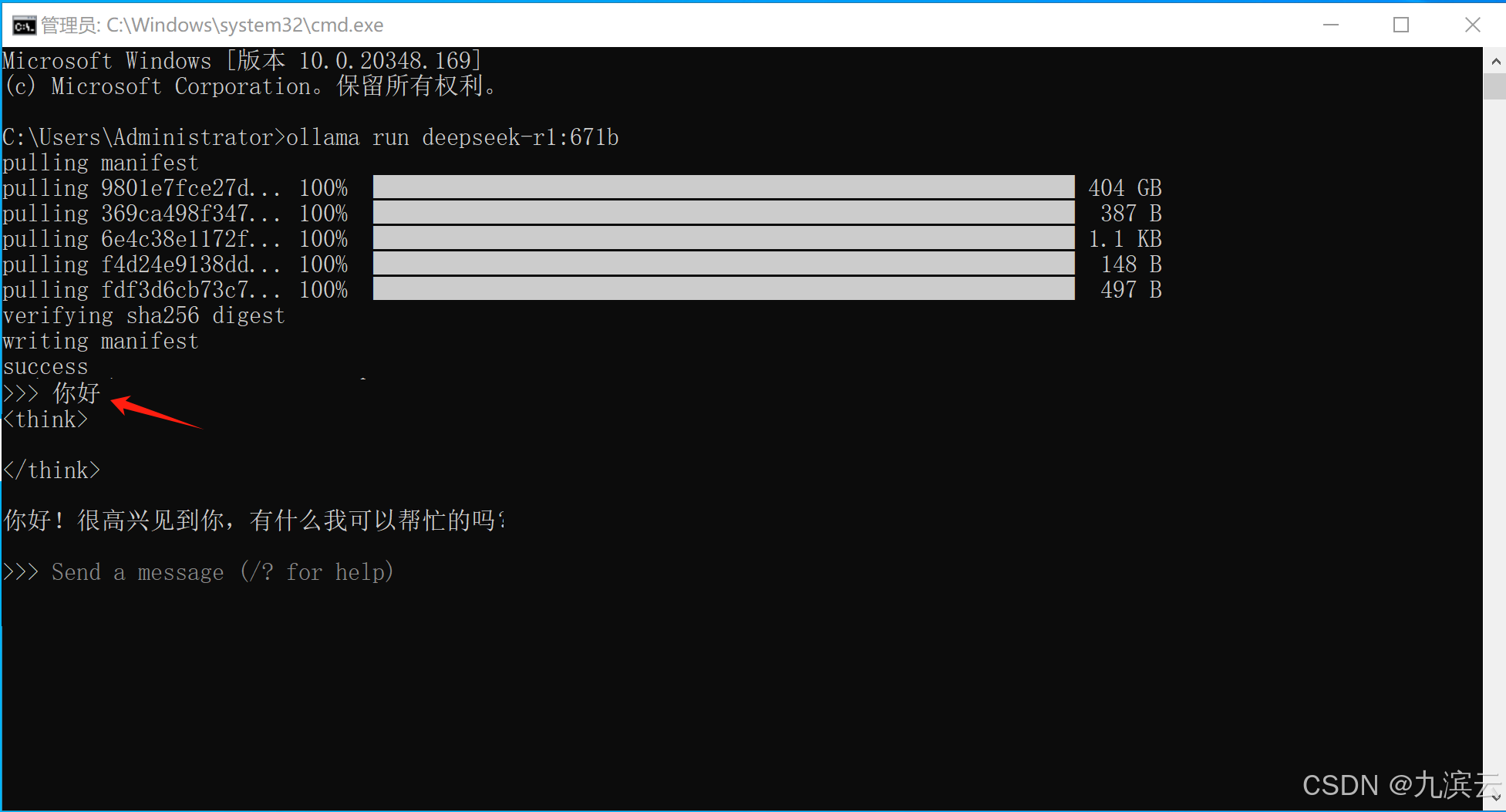
如果网络下载太慢,想从云盘下载模型的,则下载云盘中的models目录下的文件:
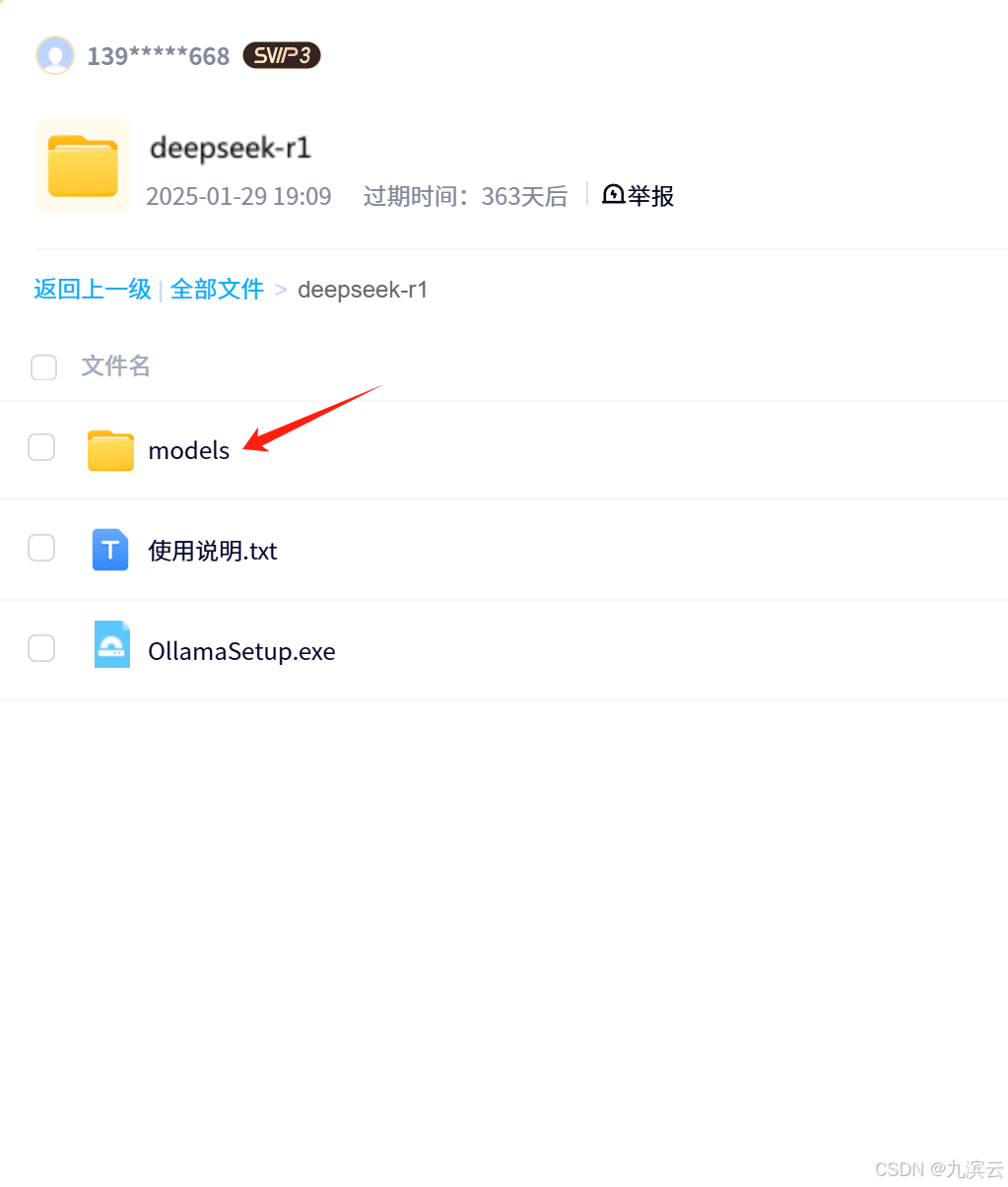
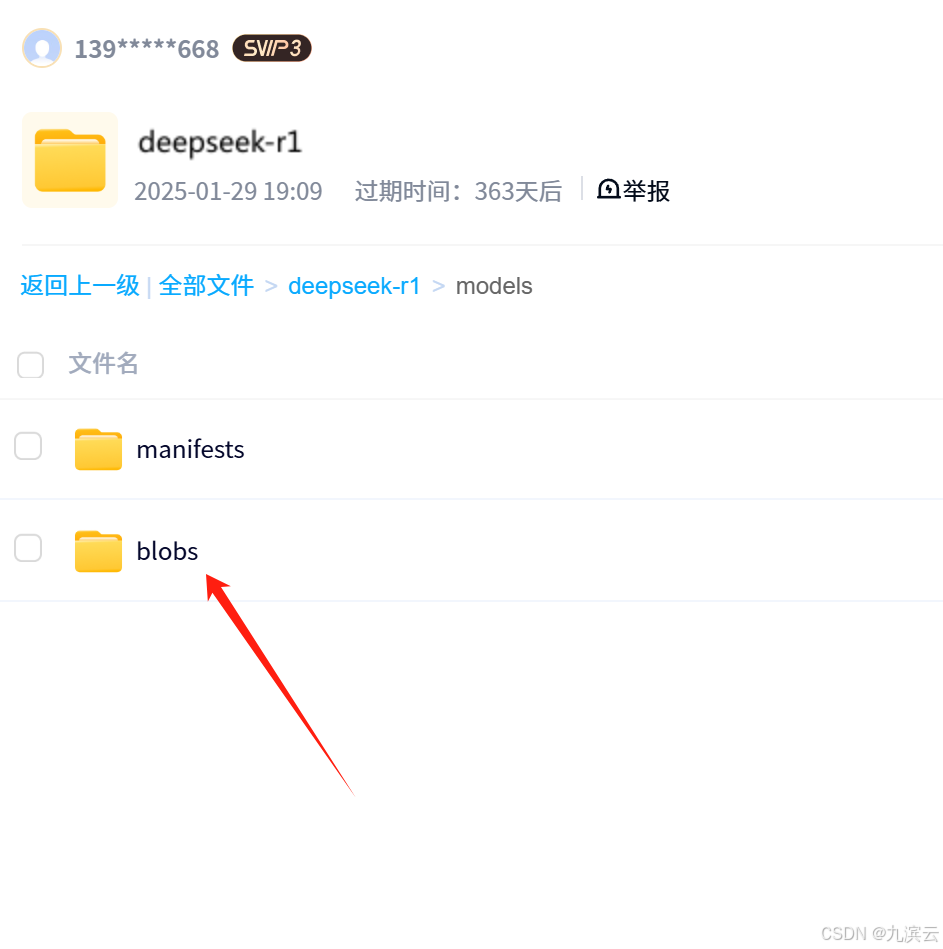
其中models/blobs中保存的是模型文件,如果只需要其中一种或几种,也不需要下载所有的模型: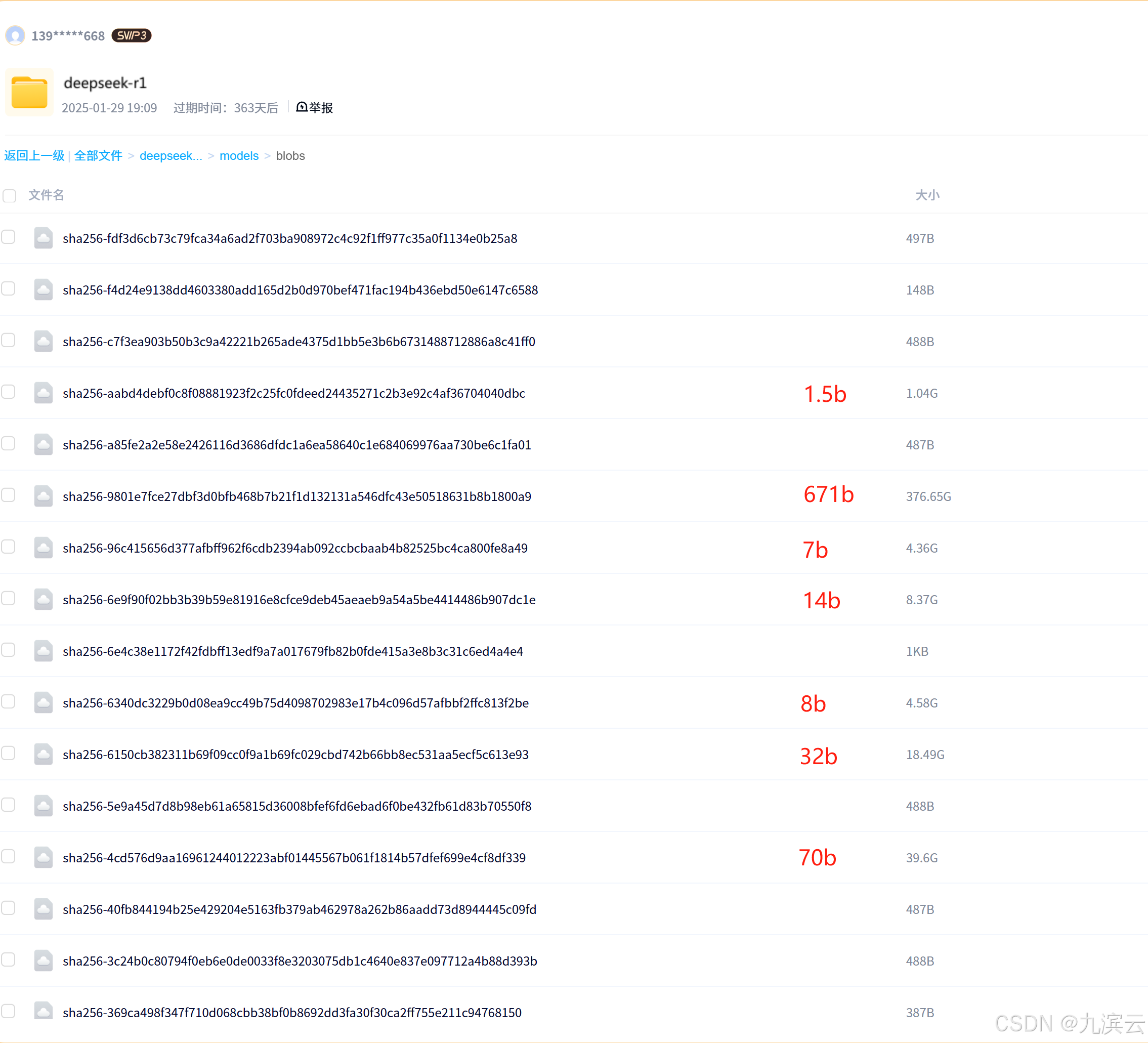
红字对应的那张就是模型对应的文件,想用哪个模型只需要下载哪个就可以了。
第五步 怎样判断自己可以安装哪个大模型?
参考下图:
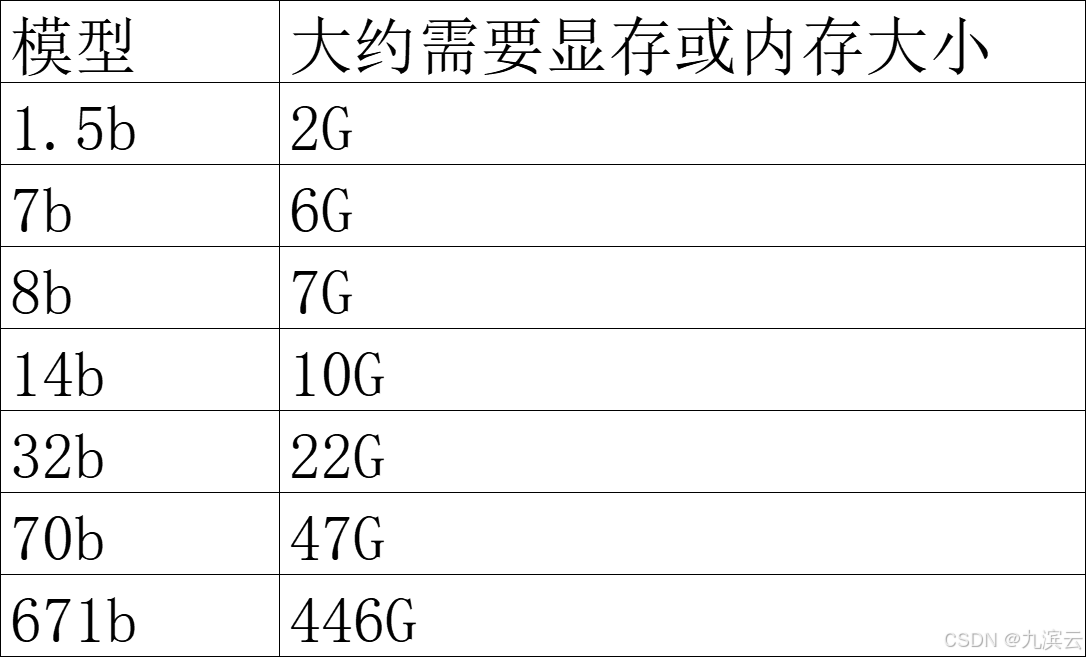
看自己的电脑剩余的显存+内存有多少,最大就可以选择哪个模型运行。
第六步 如果内存不足,想要运行更大的,甚至最大的怎么办?
当然有办法!但是前提是你的硬盘空间要充足,并且最好是ssd硬盘,硬盘速度越快越好。那就是用硬盘虚拟内存,具体做法如下:
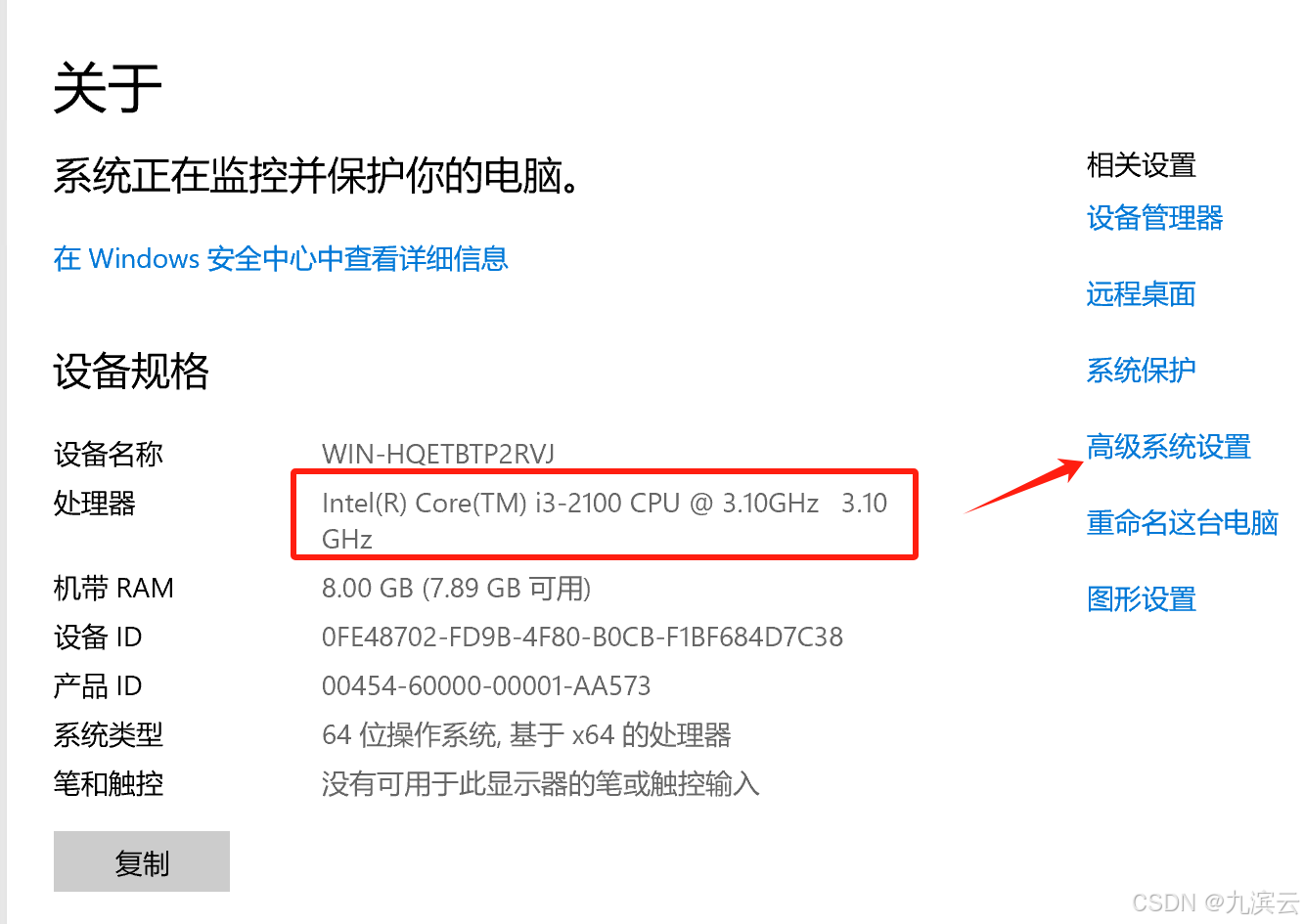
1、我的电脑点右键,点 属性

2、选择高级系统设置
3、选择高级里的设置
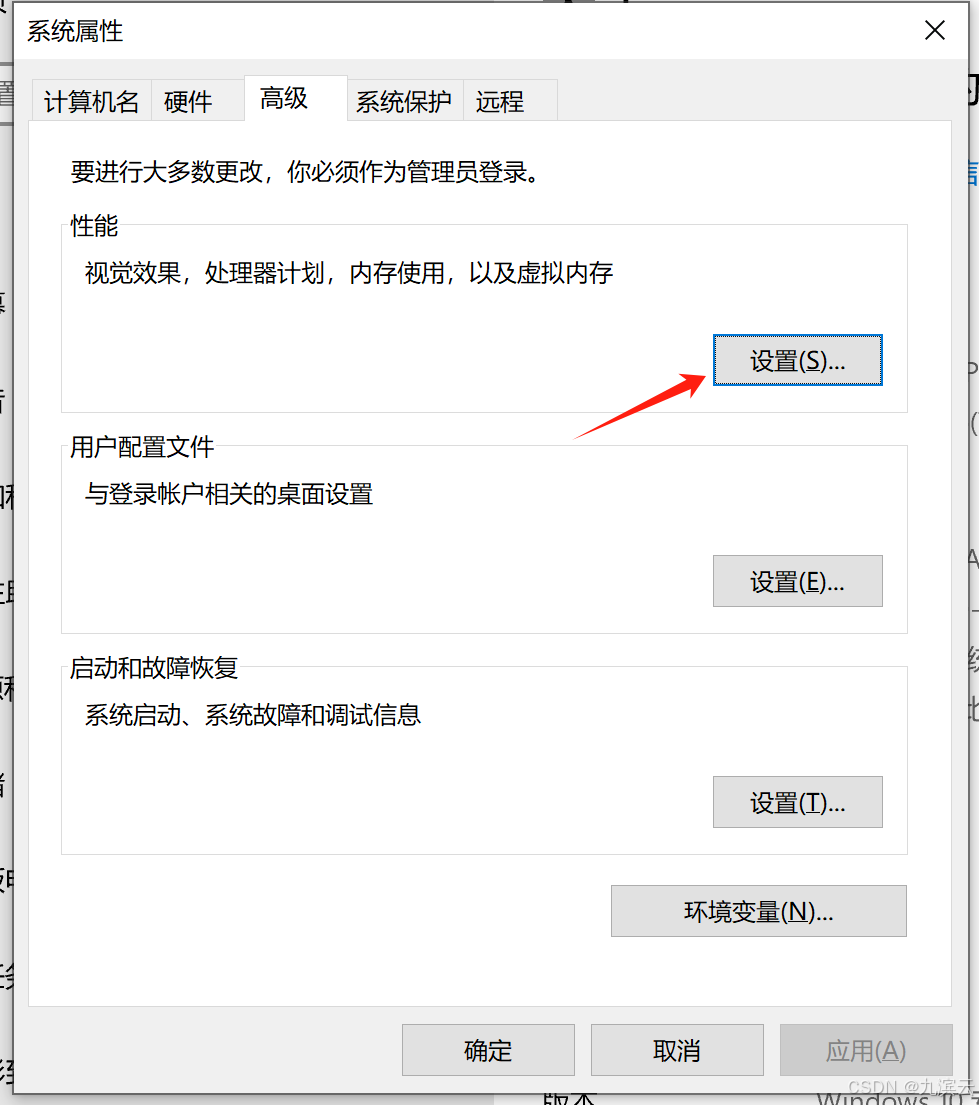
4、点击高级
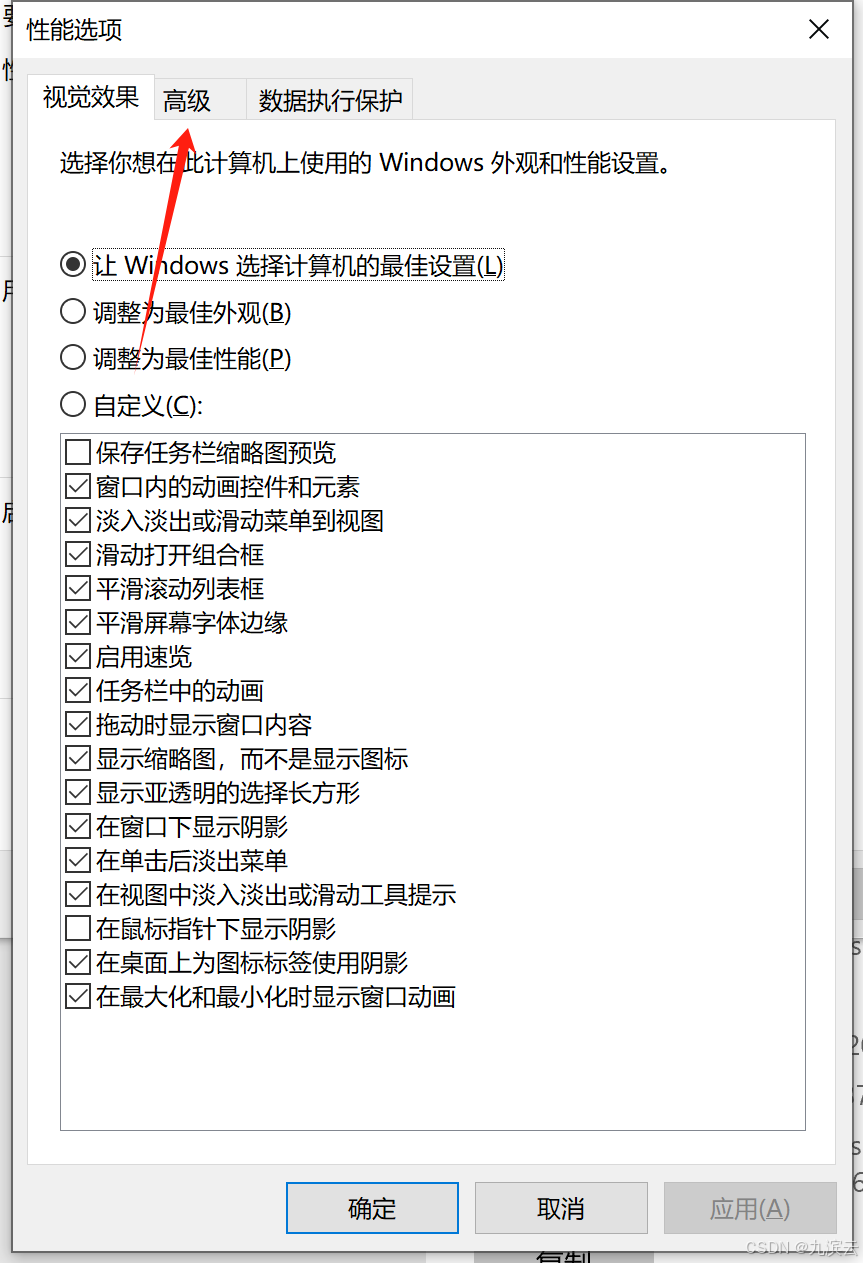
5、选择更改
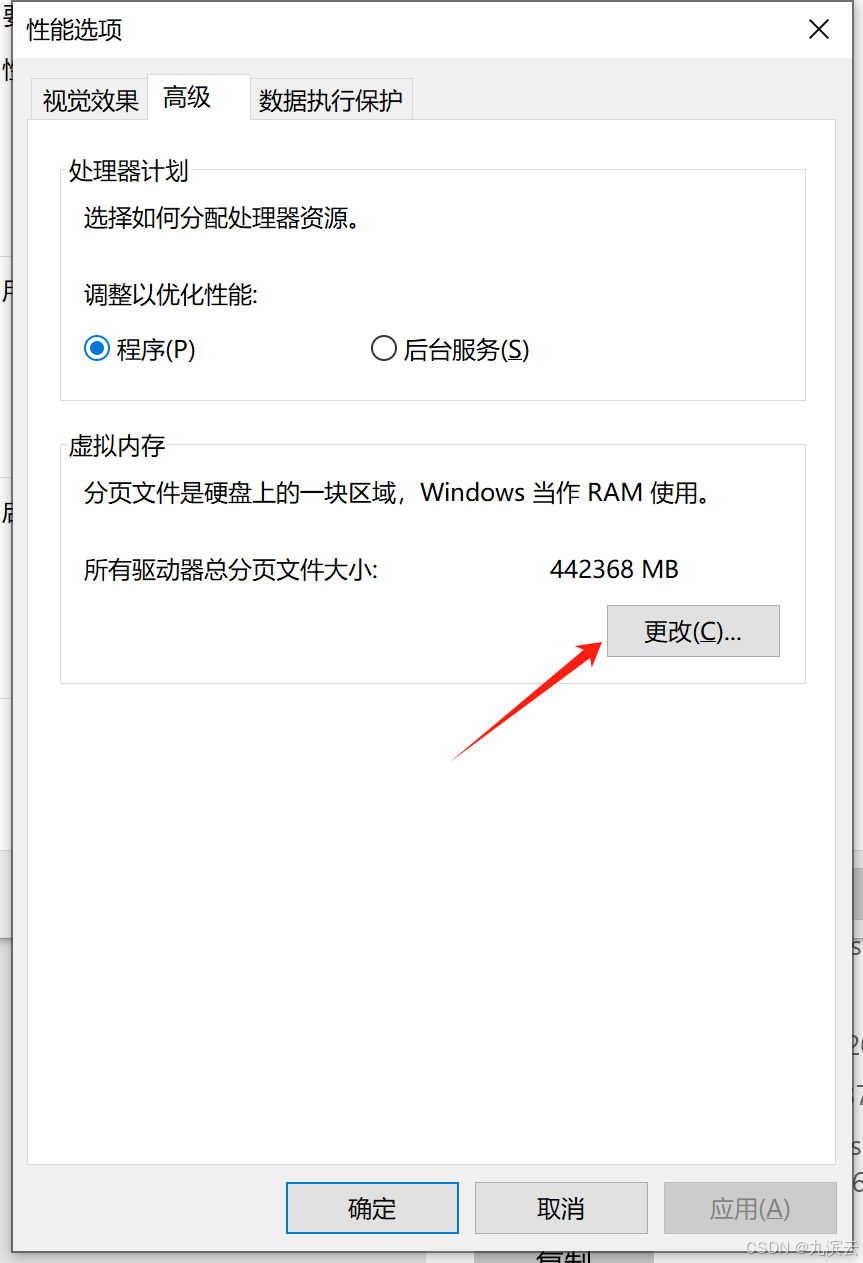
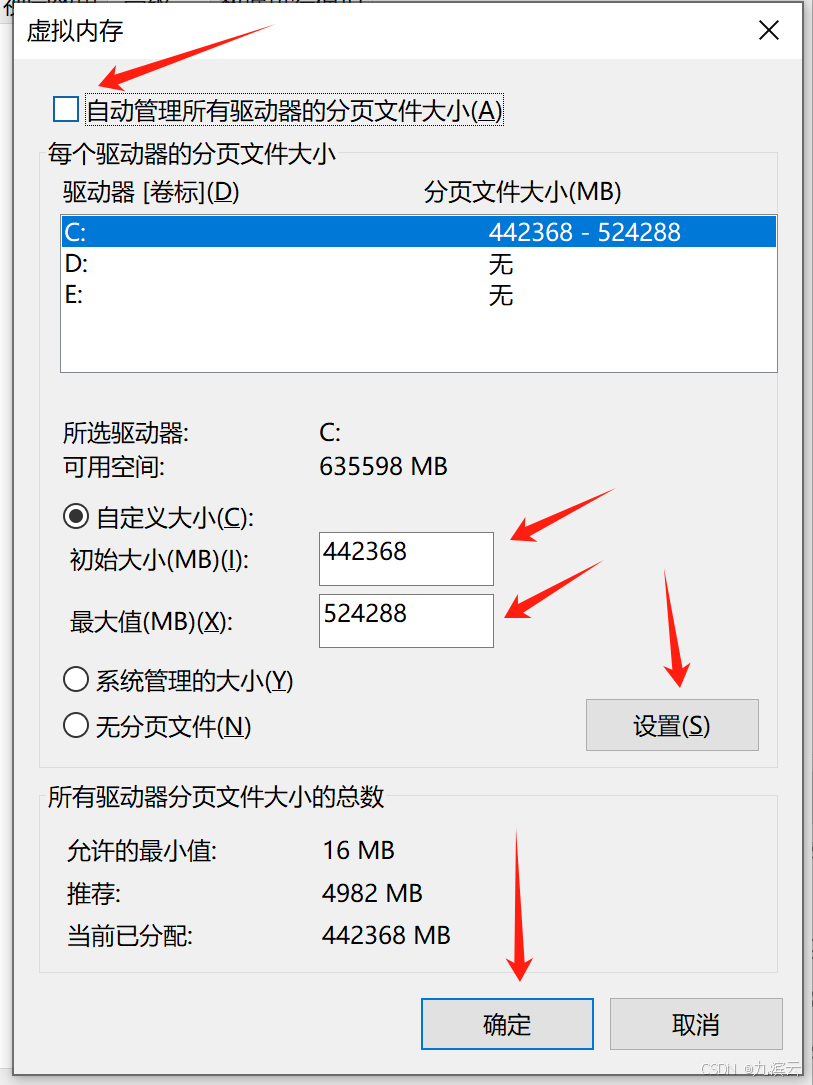
下图是运行671b模型的配置,可以按照下图的方式更改,如果电脑剩余空间太小,自定义的初始大小也可以设置为524288。
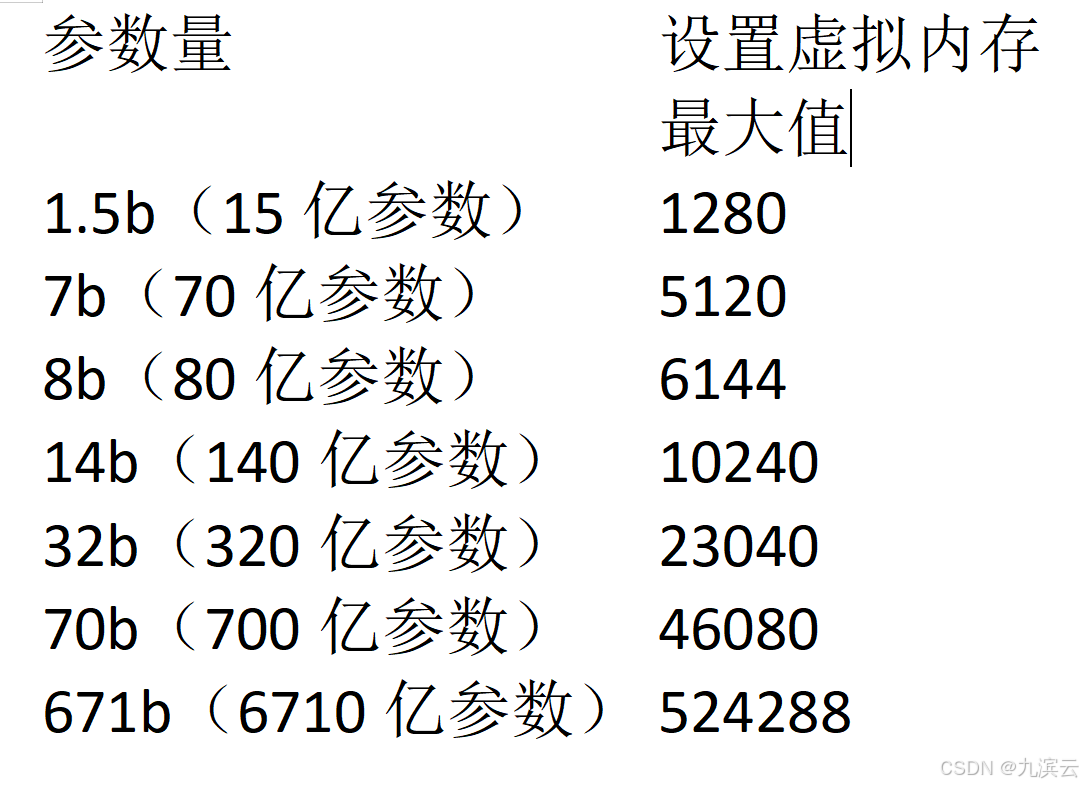
6、其他参数量需要设置的虚拟内存数值如下:
7、如果在设置过程中,需要重启,则先重启,然后需要重新做一遍!
8、设置好虚拟内存以后,就可以重新运行了:
1.5b:ollama run deepseek-r1:1.5b
7b:ollama run deepseek-r1:7b
8b:ollama run deepseek-r1:8b
14b:ollama run deepseek-r1:14b
32b:ollama run deepseek-r1:32b
70b:ollama run deepseek-r1:70b
671b:ollama run deepseek-r1:671b第七步 虚拟内存运行大模型的问题和意义
DeepSeek大模型能部署和能运行,并不能代表能作为生产力使用,其中还有个关键的问题就是推理速度,也就是每秒能生成多少tokens,生成的太慢,一个问题等半天,就没有实用意义了。
而用硬盘虚拟内存部署大模型,尤其是最大的模型,推理速度会极慢,那为什么我还要教大家这种部署方案呢?
首先普及一个知识,推理速度快慢排名是这样的:GPU+显存>CPU+内存>CPU+虚拟内存,而运行671b需要的空间是446G了,而目前来说,能有446G内存的人有多少?更不要说有446G的显存了,所以,能让671b在自己电脑上跑起来,并且不先花钱买设备的办法,只有虚拟内存这一种方案,这是从0到1的问题,也是从无到有的意思。大家用这种方式,可以去测试、去体验,如果模型能满足自己需求,再去购买设备来做生产力用,这样测试成本几乎是零,这就是本篇文章的意义。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)