
深度剖析一夜出圈的国产大模型 DeepSeek厉害在哪儿?
DeepSeek连续多日引发了全民关注,服务器还一度卡到宕机。采用压缩数据量、并行提效、蒸馏技术,得到更为精炼、有用的数据。一度让英伟达股价暴跌17%!
一、快速介绍

1.1 Deepseek 出圈由来
1月27日,美国芯片巨头英伟达股价暴跌17%,市值跌去5900亿美元(约合人民币4.24万亿元)。这与来自中国的人工智能初创公司DeepSeek“现象级崛起”密切相关,“好用、免费、训练成本低”,擅长创意写作、一般问答、编辑、总结等。DeepSeek连续多日引发了全民关注,服务器还一度卡到宕机。
登顶AI 大模型开源之最
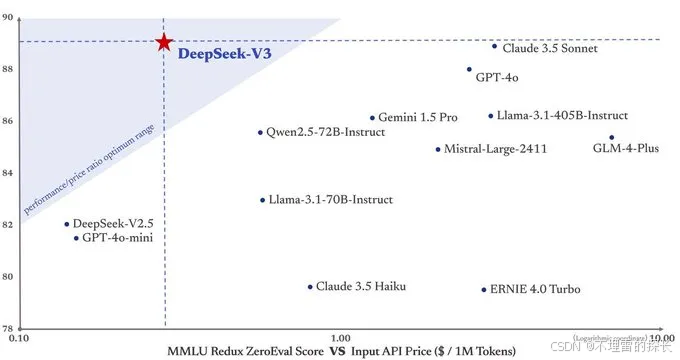
1.2 Deepseek 出自哪里?
来自杭州深度求索公司,系一家成立于2023年,使用数据蒸馏技术,得到更为精炼、有用的数据。由知名私募巨头幻方量化全资孕育而生,专注于开发先进的大语言模型(LLM)和相关技术。

1.3 Deppseek 为啥掀桌子?
首先系体验更好。对于资本市场来说,DeepSeek更大的惊喜来自于它的推理成本大幅降低。一句话总结就是“训练大模型也可以省钱,且训练出来的质量及效果还非常厉害”。
deepseek-v3 的训练成本,假设 H800 的租赁价格为每 GPU 小时 2 美元

有数据显示,最新版的推理大模型DeepSeek-R1,输入token定价为0.55美元/百万(OpenAI为15美元/百万),输出token为2.19美元/百万(OpenAI为60美元/百万),成本降低超90%。而此前DeepSeek-V3仅用550万元研发成本、2000张显卡打造,却达到与Llama 3 405B相媲美的性能,而OpenAI为了实现这一目标,花费了数亿美元。
二、为何出圈
2.1 出色推理性能体验
首先Deepseek是推理模型,先来看看Deepseek的发展构成:
| 分类 | 功能描述 | 补充 |
| DeepSeek-R1-Zero |
DeepSeek-R1-Zero 是一种通过大规模强化学习 (RL) 训练的模型,而不依赖监督微调 (SFT) 作为初步步骤。这种方法允许模型探索解决复杂问题的思路链 (CoT) |
可读性差和语言混合 |
| DeepSeek-R1 | 它在 RL 之前结合了多阶段训练和冷启动数据。DeepSeek R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能 | 深度思考 (R1) |
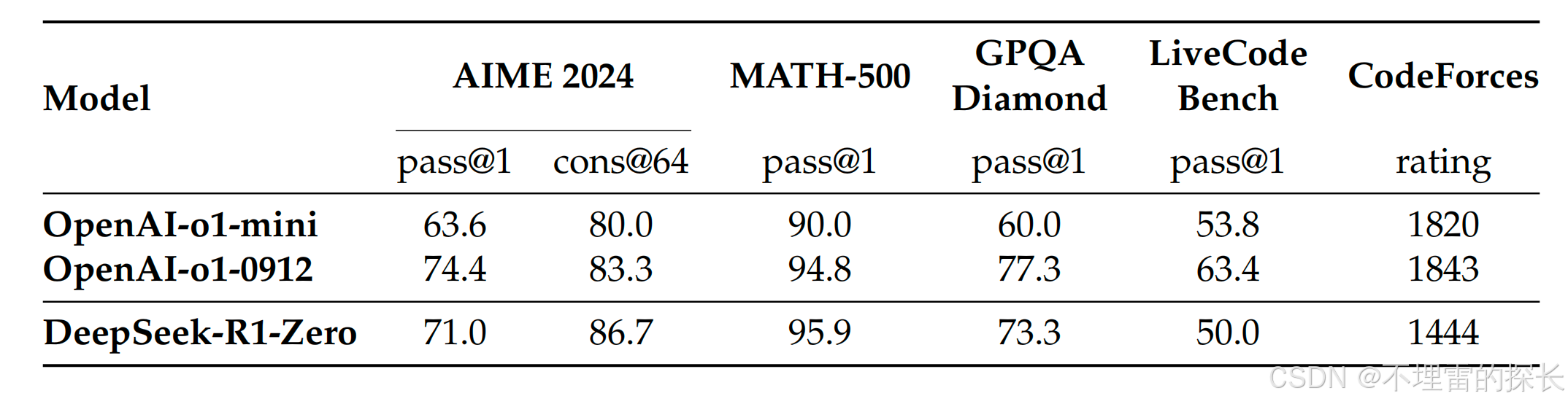
DeepSeek-R1-Zero 与 OpenAI o1 模型在推理相关基准上的比较
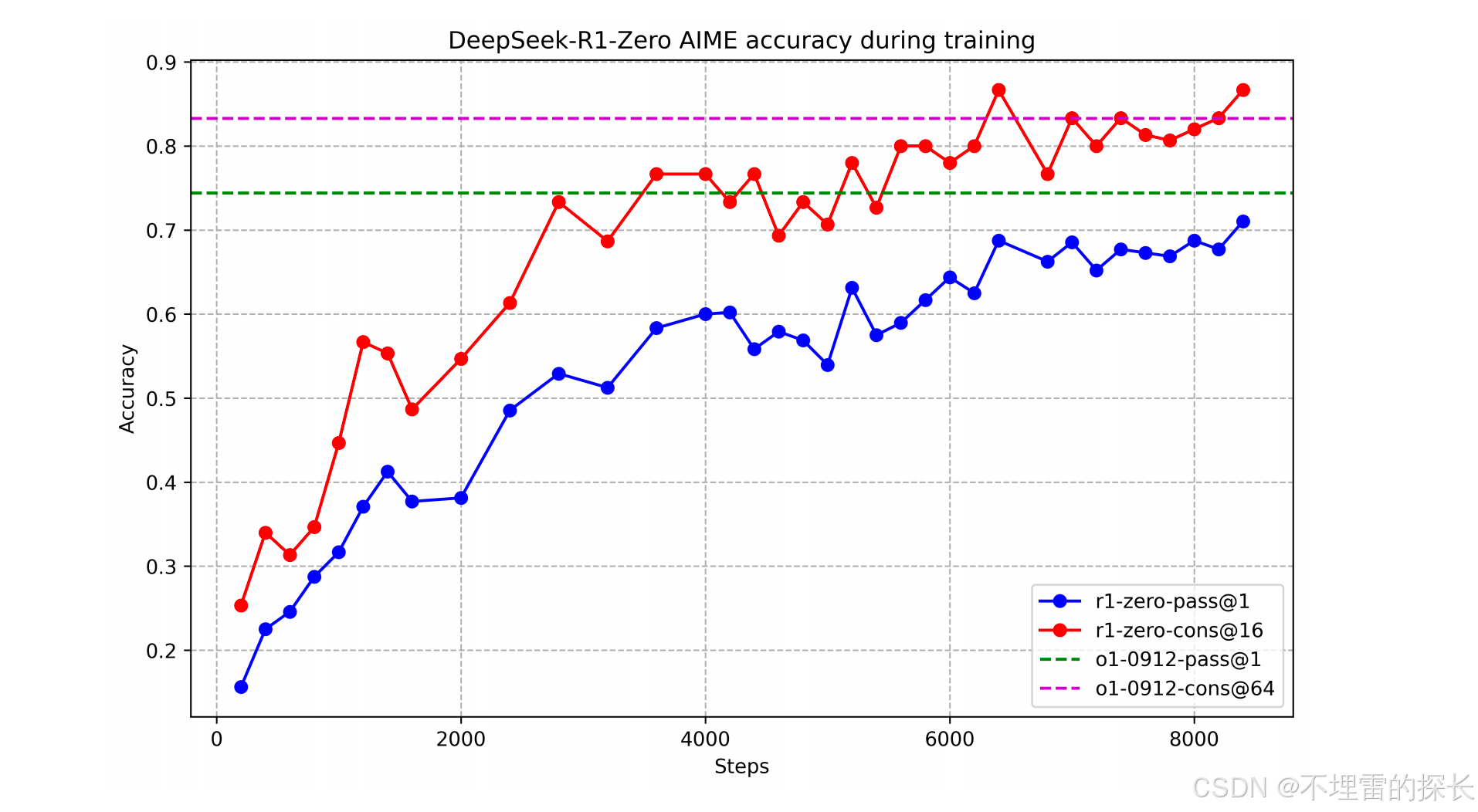
DeepSeek-R1-Zero 在训练期间的 AIME 准确率。对于每个问题,我们抽样 16 个答案并计算总体平均准确率,以确保稳定的评估。
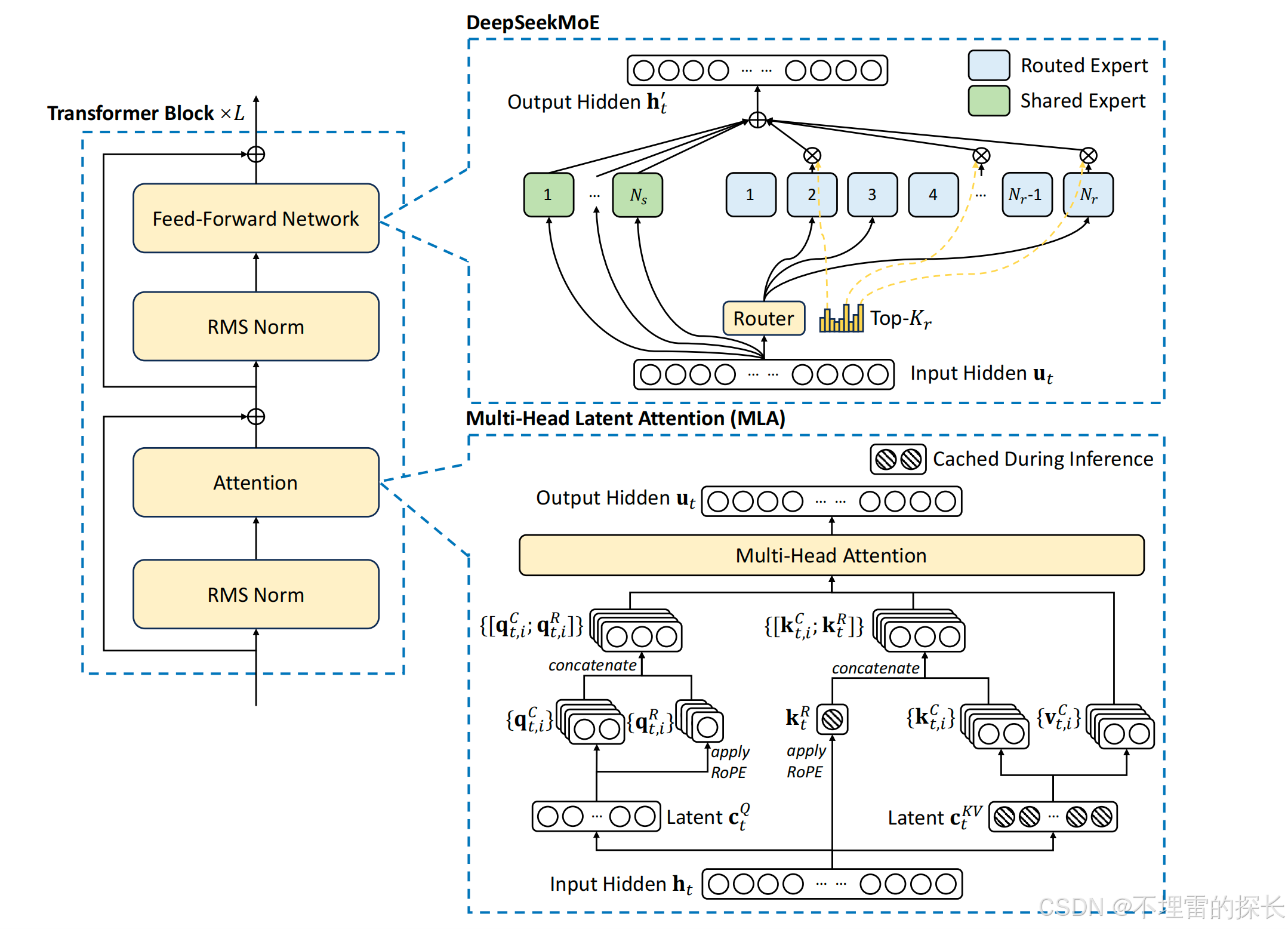
2.2 怎么做到又便宜又强大
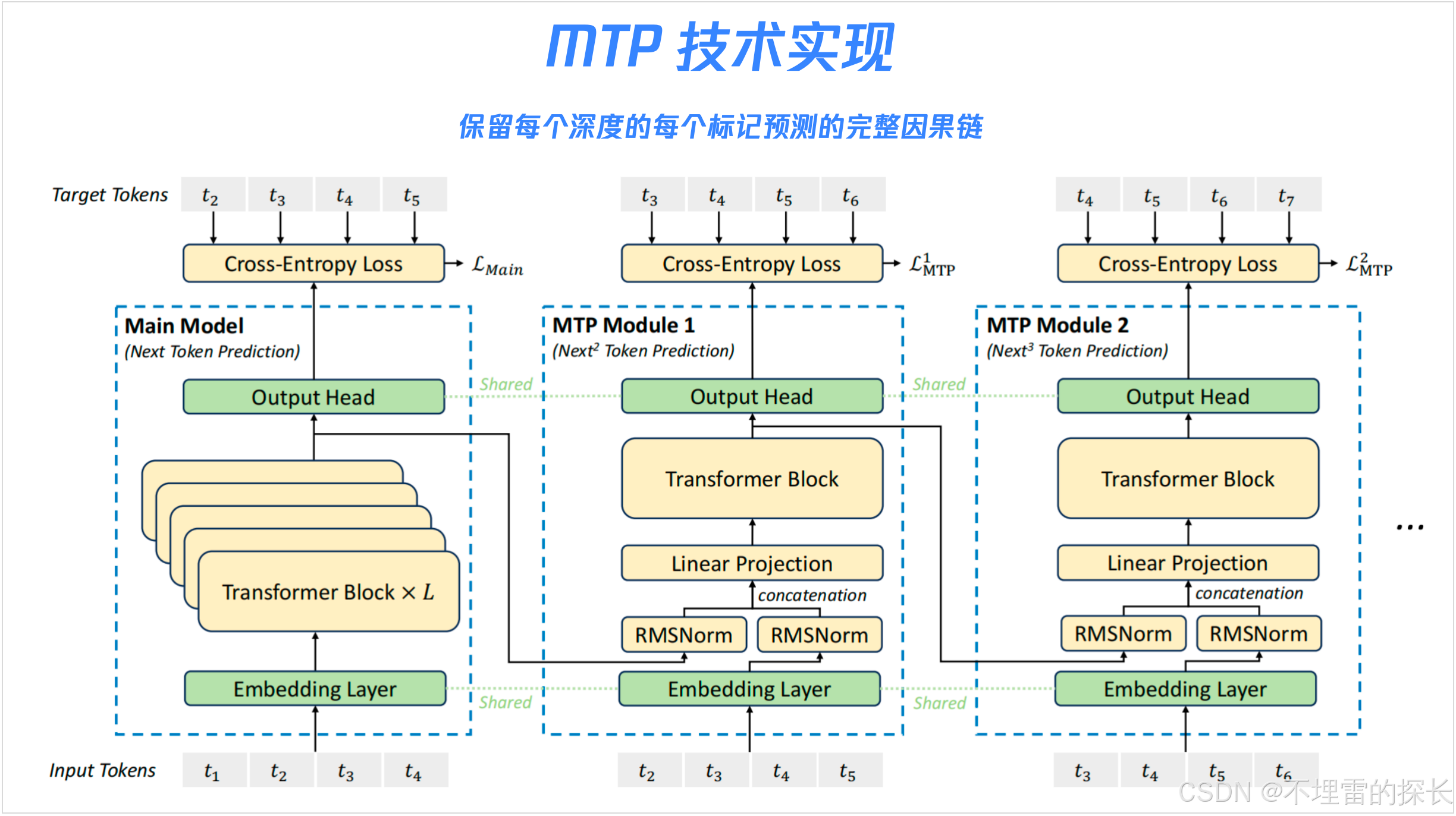
“AI 界拼多多”, 国产大模型DeppSeek-V3开源后刷屏,总训练成本557万美元,性能比肩GPT-4o。首先Deepseek 是MoE架构(Mixture of Experts 混合专家模型),它不是一个全才大模型,而是一个各领域专家大模型。DeepSeek 重点在工程实现了创新,通过高效的模型设计、数据优化、分布式训练、硬件利用、训练策略优化、开源工具使用和算法创新,显著降低了训练成本,同时保持了较高的模型性能。具体策略如下:

MLA 通过大幅减少生成的 KV 缓存来确保高效推理,而 DeepSeekMoE 则通过稀疏架构以经济的成本训练出强大的模型。
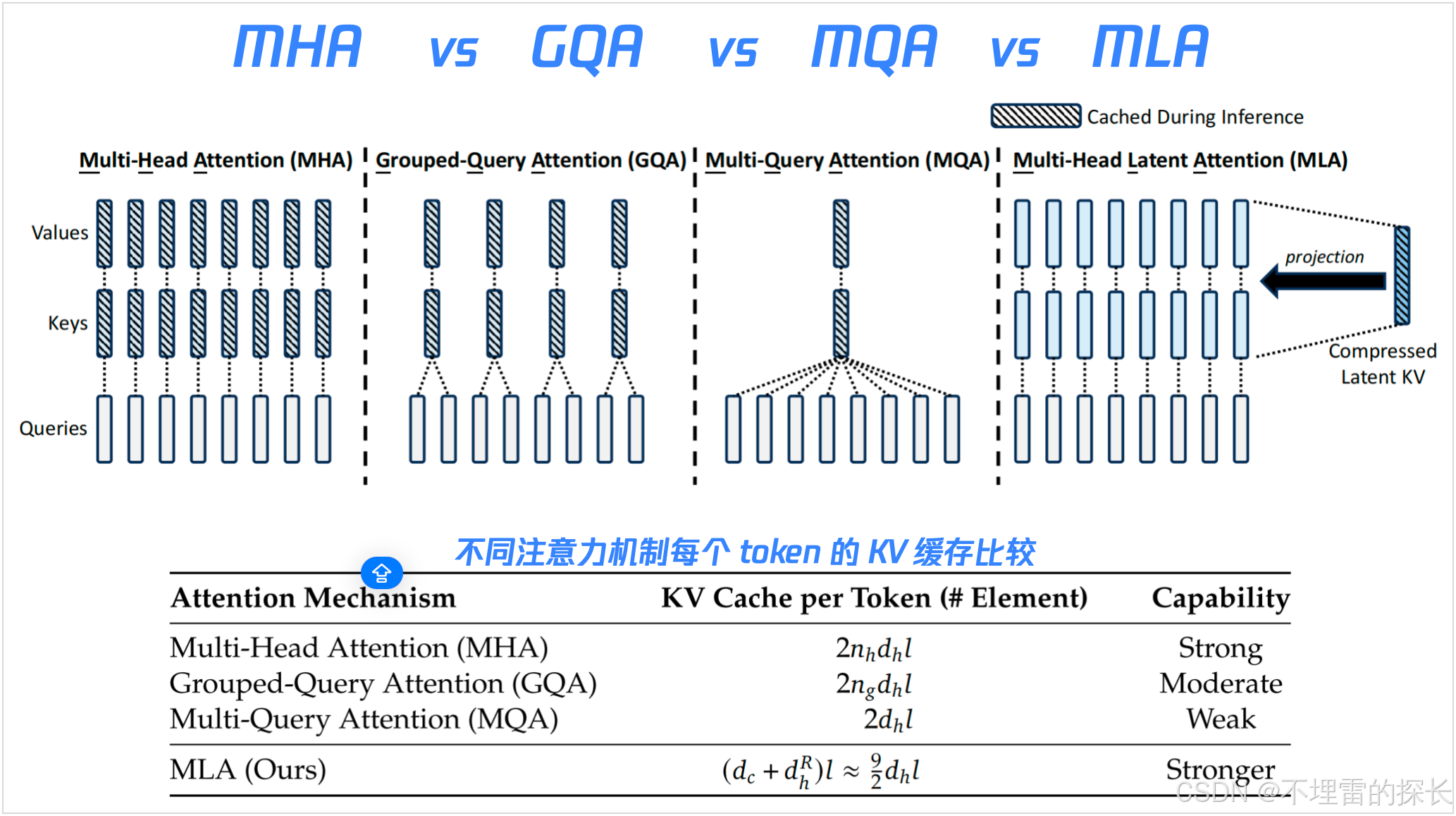
成本下降情况:
- Llama 3 405B 在多达16000 H100GPU上进行训练,成本大约是Llama3.1的 1/10 左右
- Deepseek 在2048块H800训练2个月,成本大约是GPT-4o 的 1/20 左右
2.3 对未来影响
- 重塑AI 大模型训练成本,让更多用户用得起高质量大模型;
- 倒逼各大厂商优化工程链路,不止追求理论创新,也要重视工程实现;
- 会让更多中小企业参与AI 大模型建设、使用上;
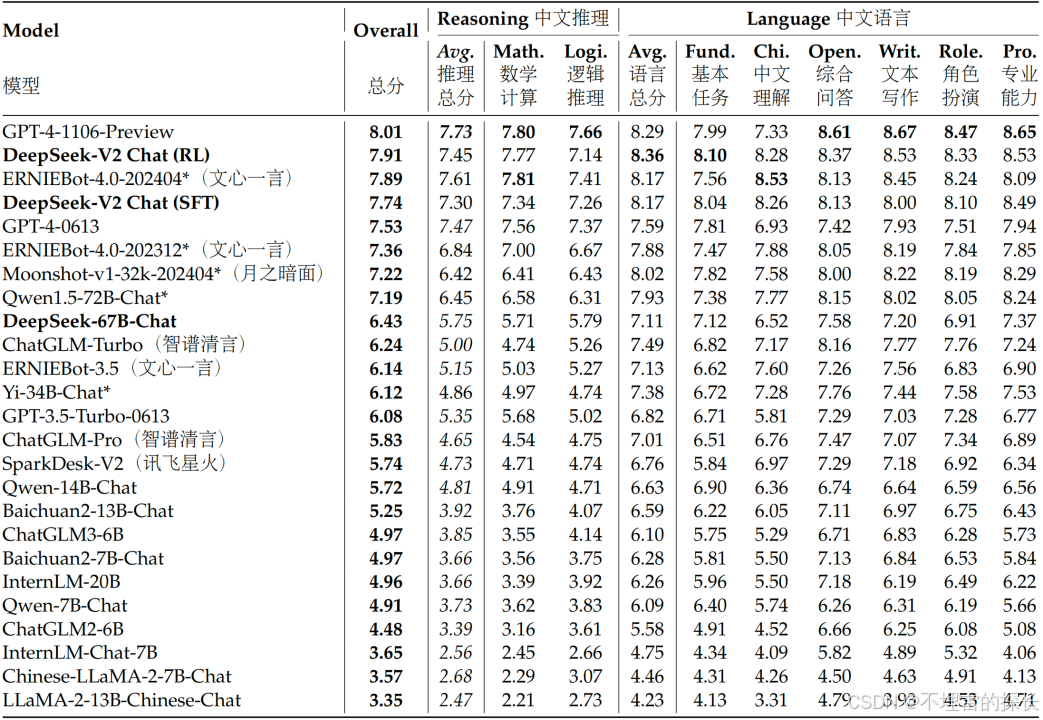
三、性能表现
3.1 综合能力表现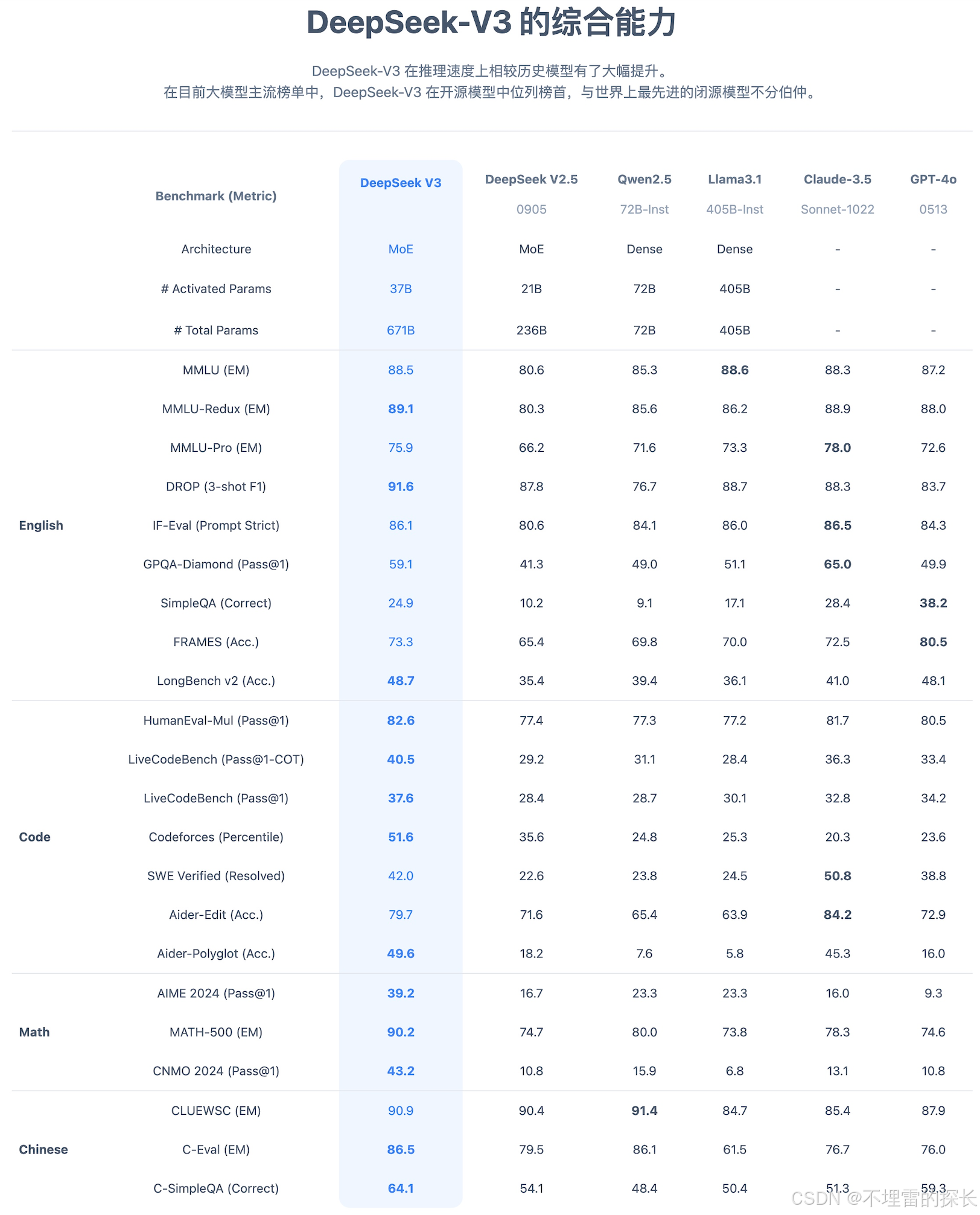
3.2 多任务 Benchmark 表现
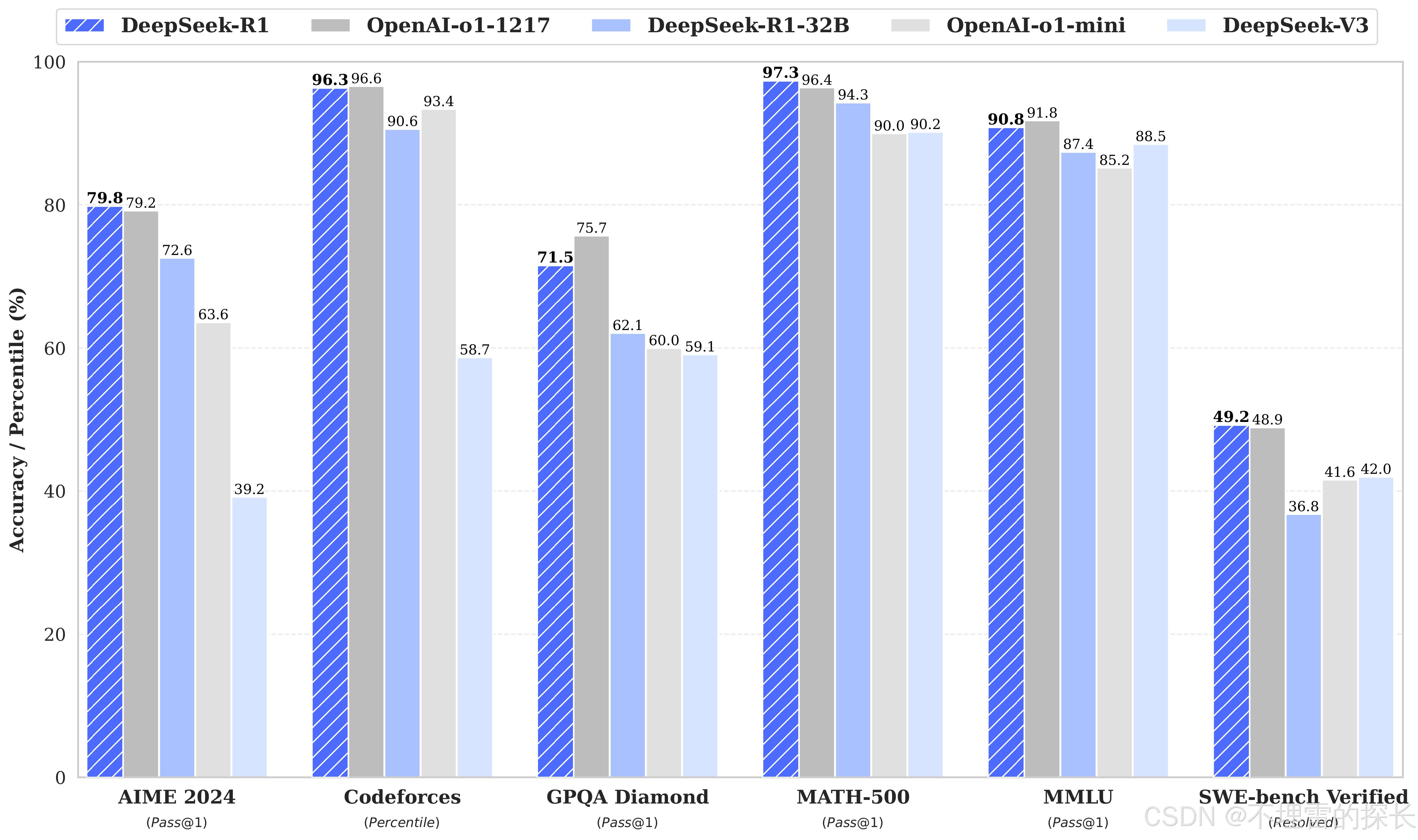
3.3 各大模型按总排名
四、如何使用
4.1 快速使用
4.1.1 电脑端
官网链接:DeepSeek。登录后,开箱即用~

4.1.2 移动端
可在应用商店快速安装、使用

4.1.3 代码开源
4.2 个人体验
擅长的地方:
-
自然语言处理:能够理解和生成自然语言文本,适用于对话、翻译、摘要生成等任务。
-
信息检索:快速从大量数据中检索相关信息,适用于问答系统和知识查询。
-
数据分析:能够处理和分析结构化数据,提供数据洞察和预测。
-
自动化任务:可以自动化处理一些重复性任务,如日程安排、邮件回复等。
-
多语言支持:支持多种语言,能够进行跨语言的交流和翻译。
不擅长的地方:
-
复杂推理:在处理需要深度逻辑推理或创造性思维的任务时,可能表现不如人类专家。
-
情感理解:虽然能够识别一些情感线索,但在深入理解和回应复杂情感方面仍有局限。
-
实时更新:知识截止日期为2024年7月,无法提供此后的实时信息或事件。
-
专业领域知识:在某些高度专业化的领域(如医学、法律等),可能需要结合专业人员的判断。
-
道德和伦理判断:在处理涉及道德和伦理的复杂问题时,可能缺乏足够的判断力。
总体而言,DeepSeek-V3在多个通用任务上表现出色,但在需要深度专业知识和复杂情感理解的任务上仍有提升空间。
|
项目 |
deepseek |
豆包 |
文心一言 |
kimi |
元宝 |
|
厂家 |
深度求索 | 字节 | 百度 | 月之暗面 | 腾讯 |
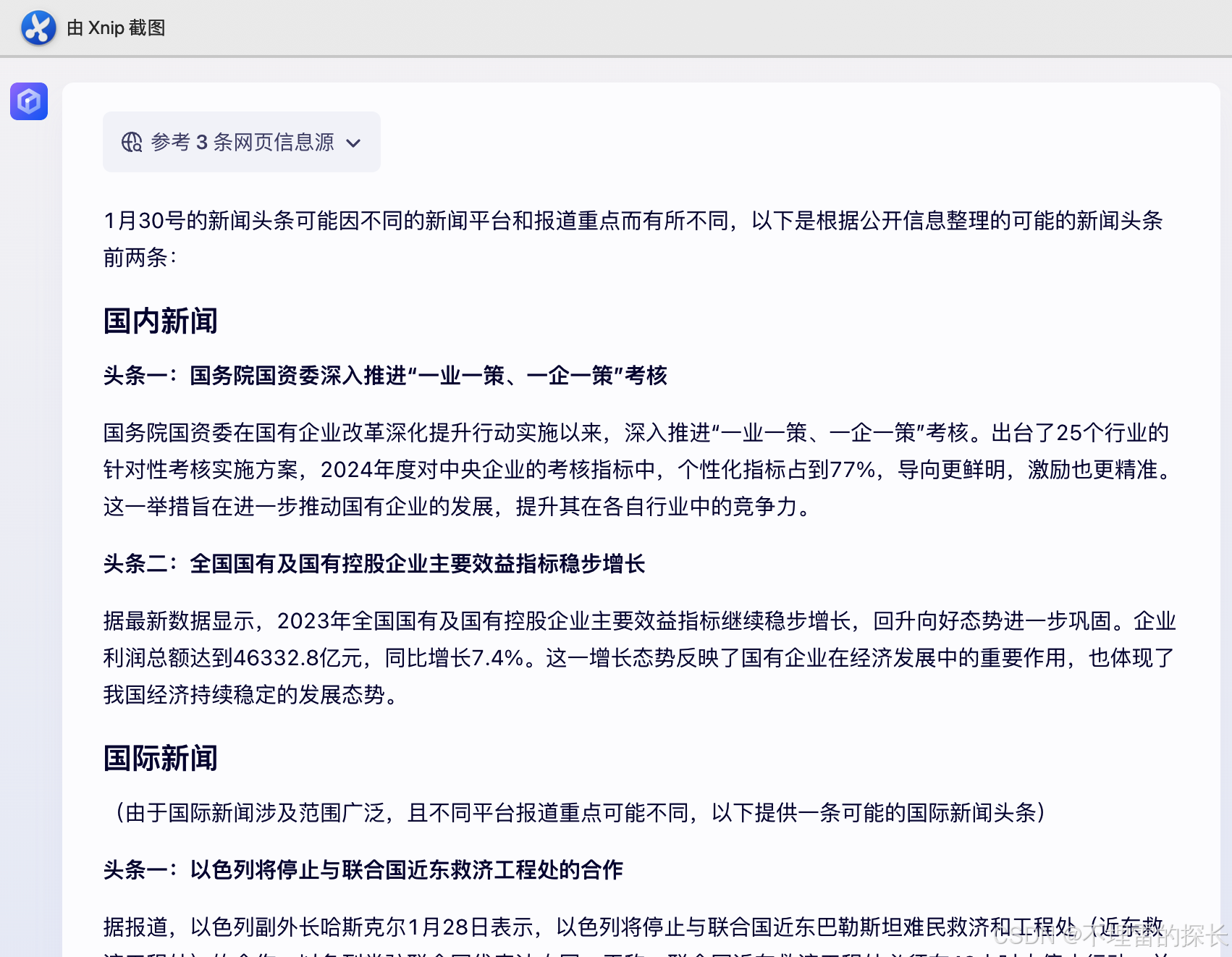
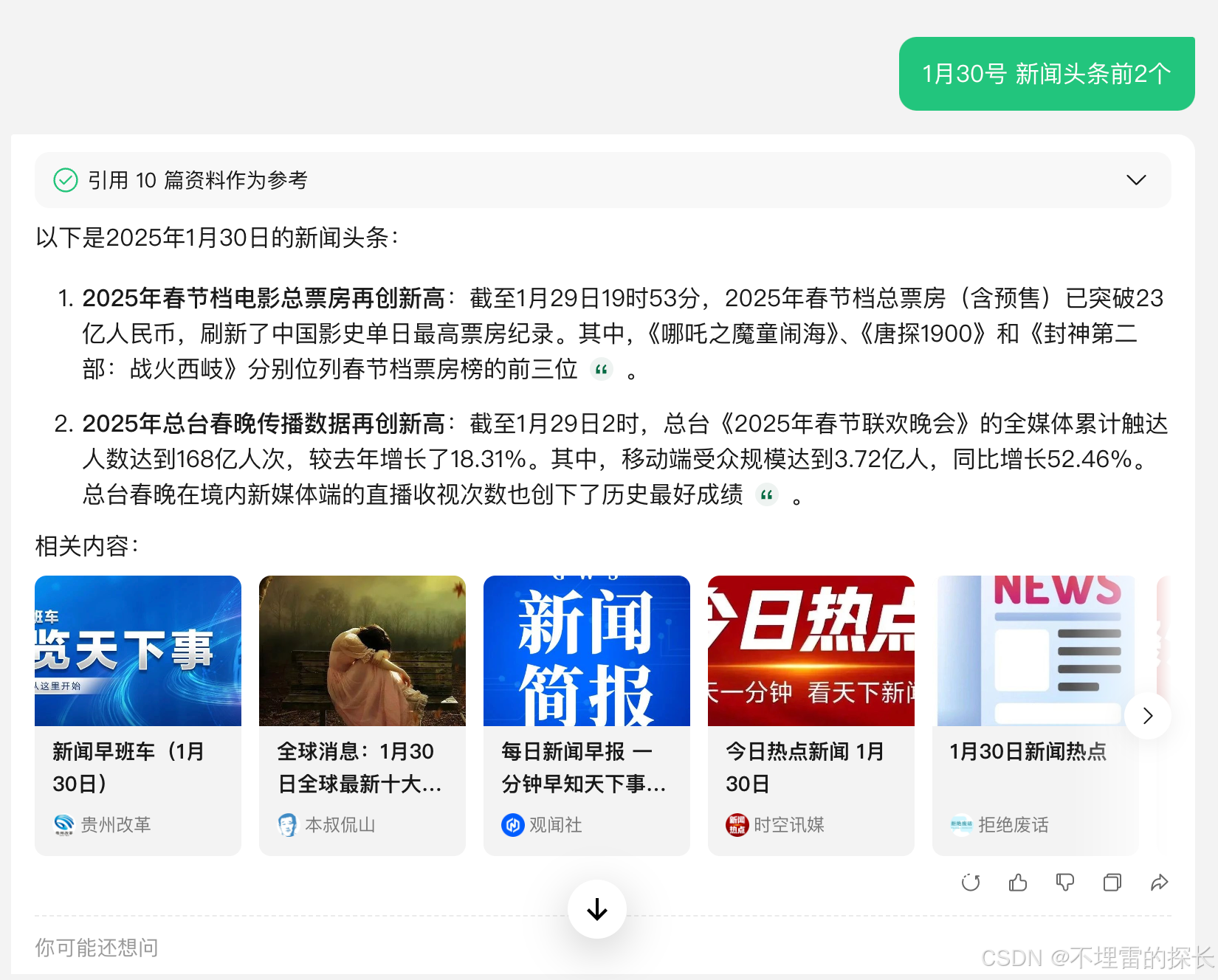
| 新闻搜索 | 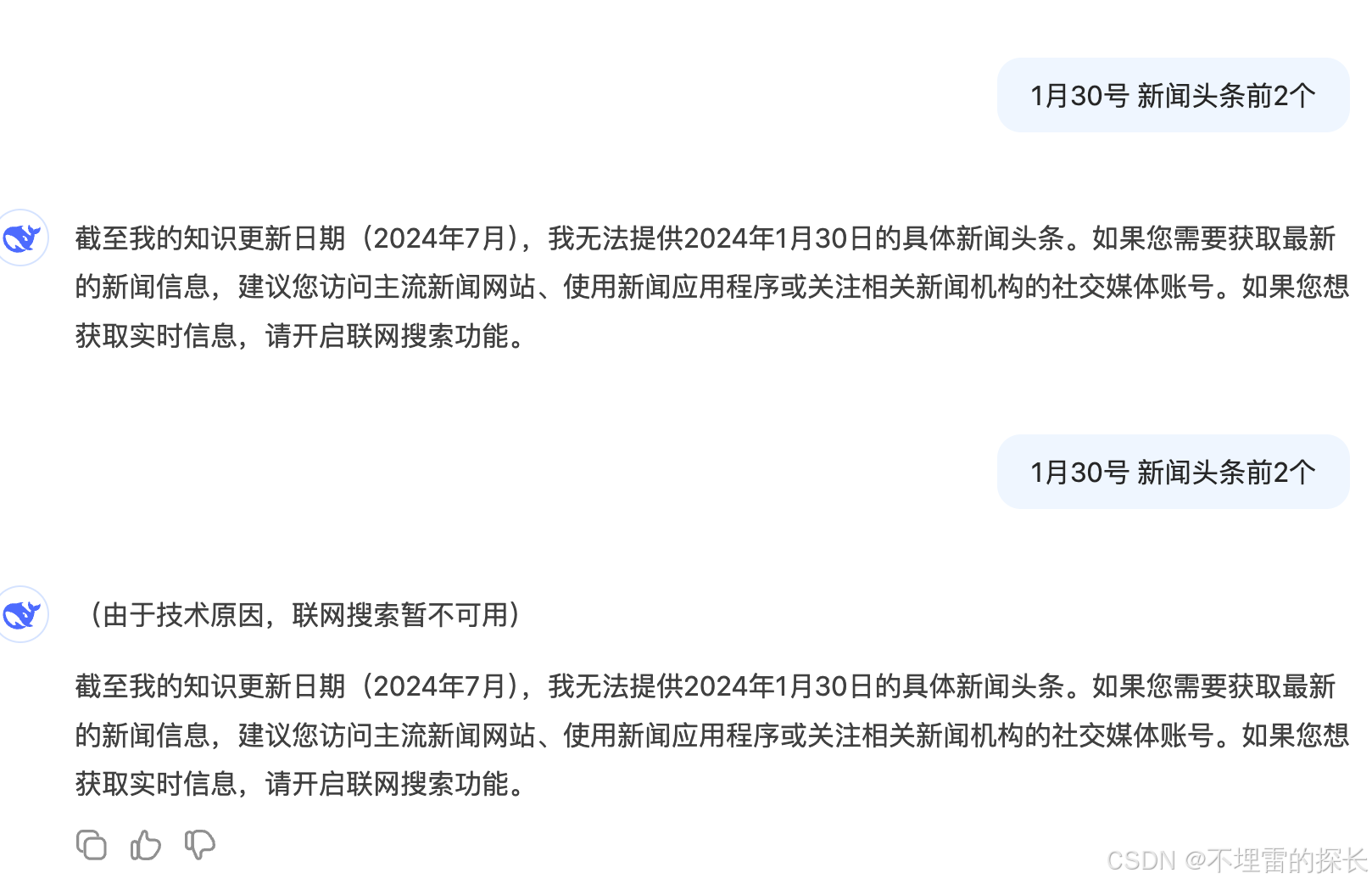 |
 |
 |
 |
 |
|
数学计算
|
|
正确 |
无法解题 |
正确 |
理解题目错误 |
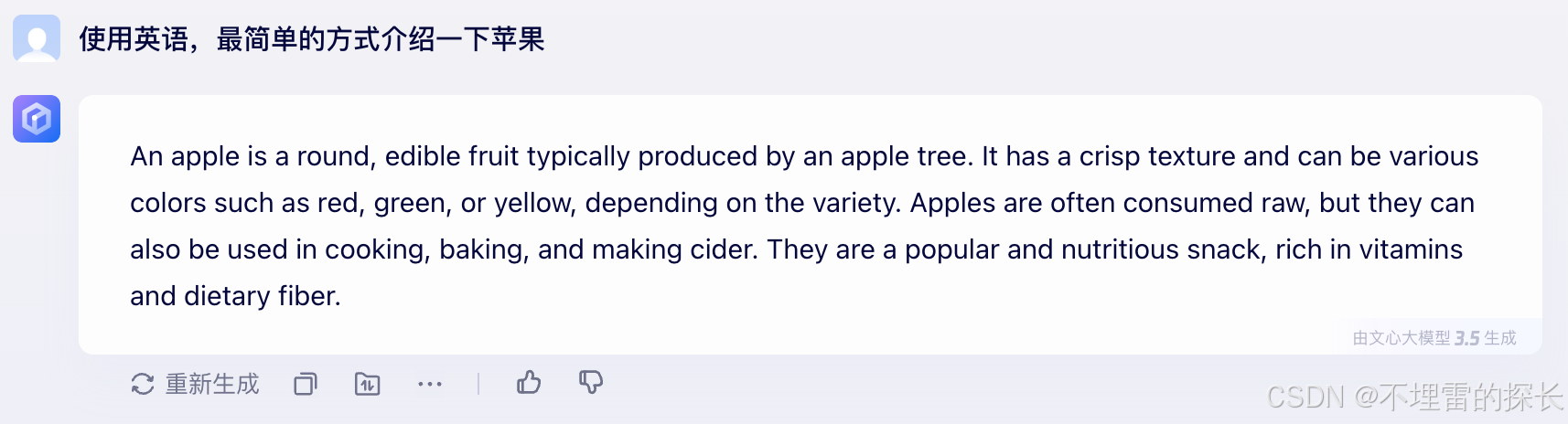
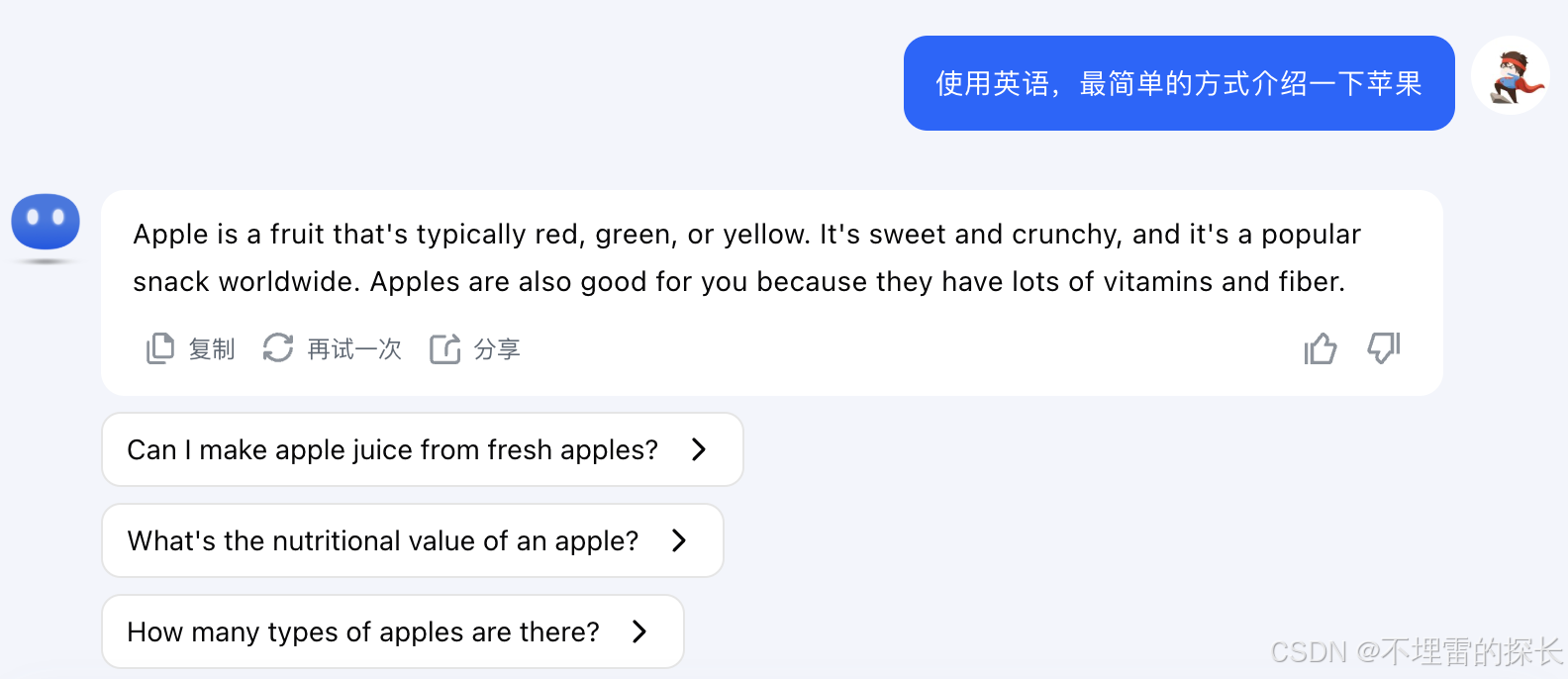
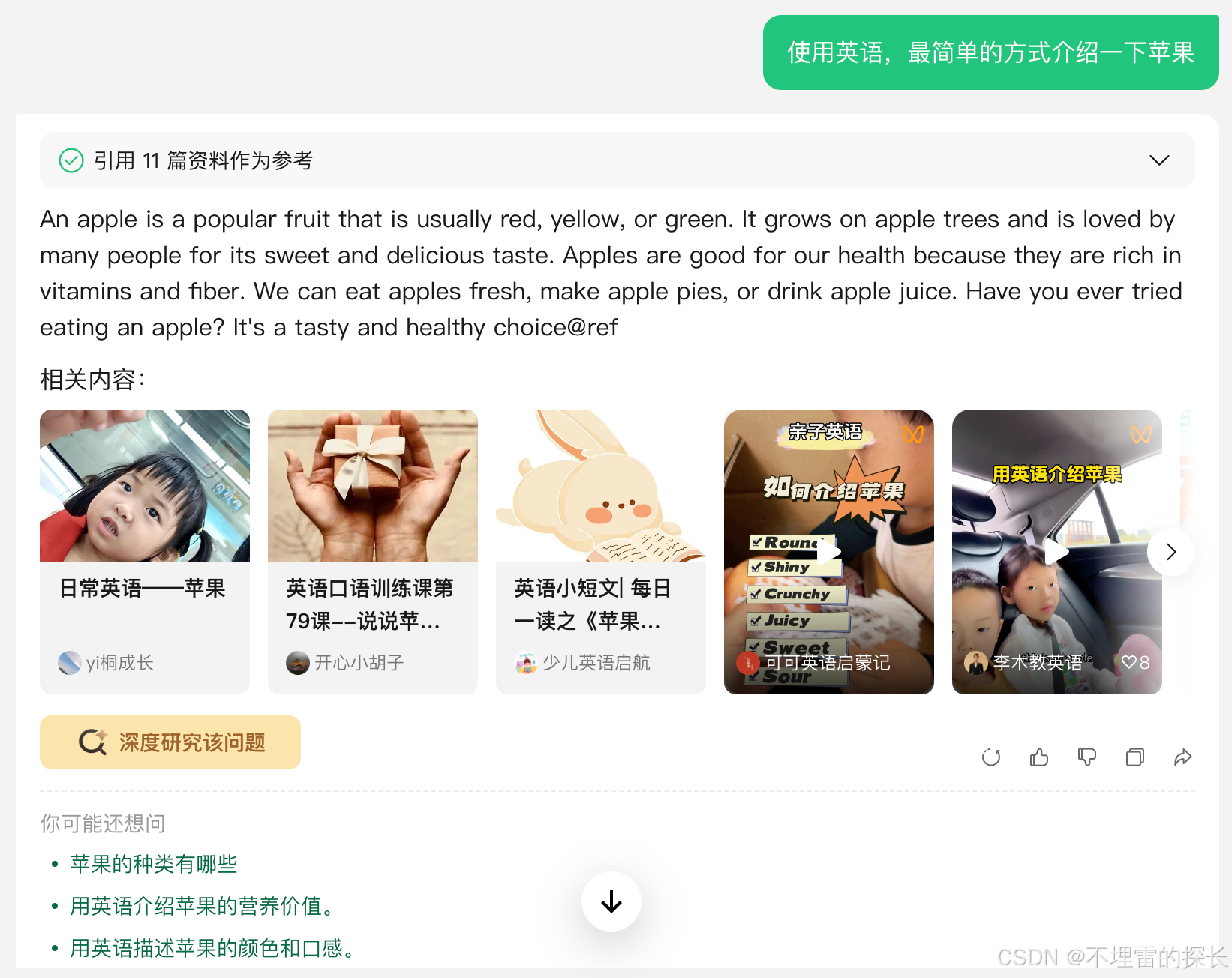
| 英语翻译 | 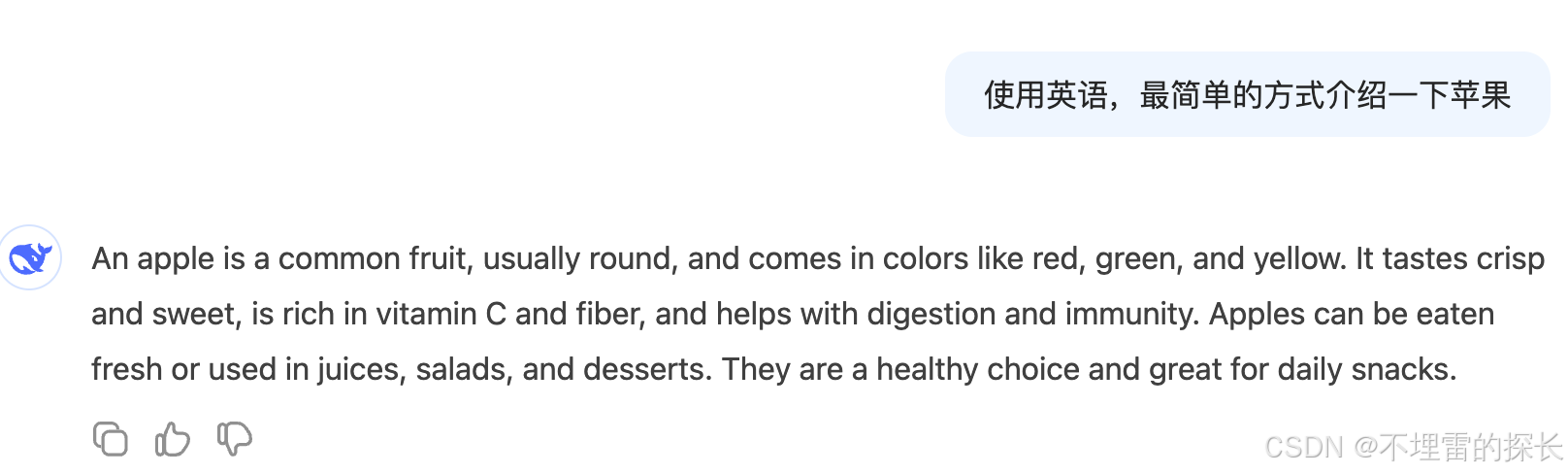 |
 |
 |
 |
 |
| 中文逻辑 | 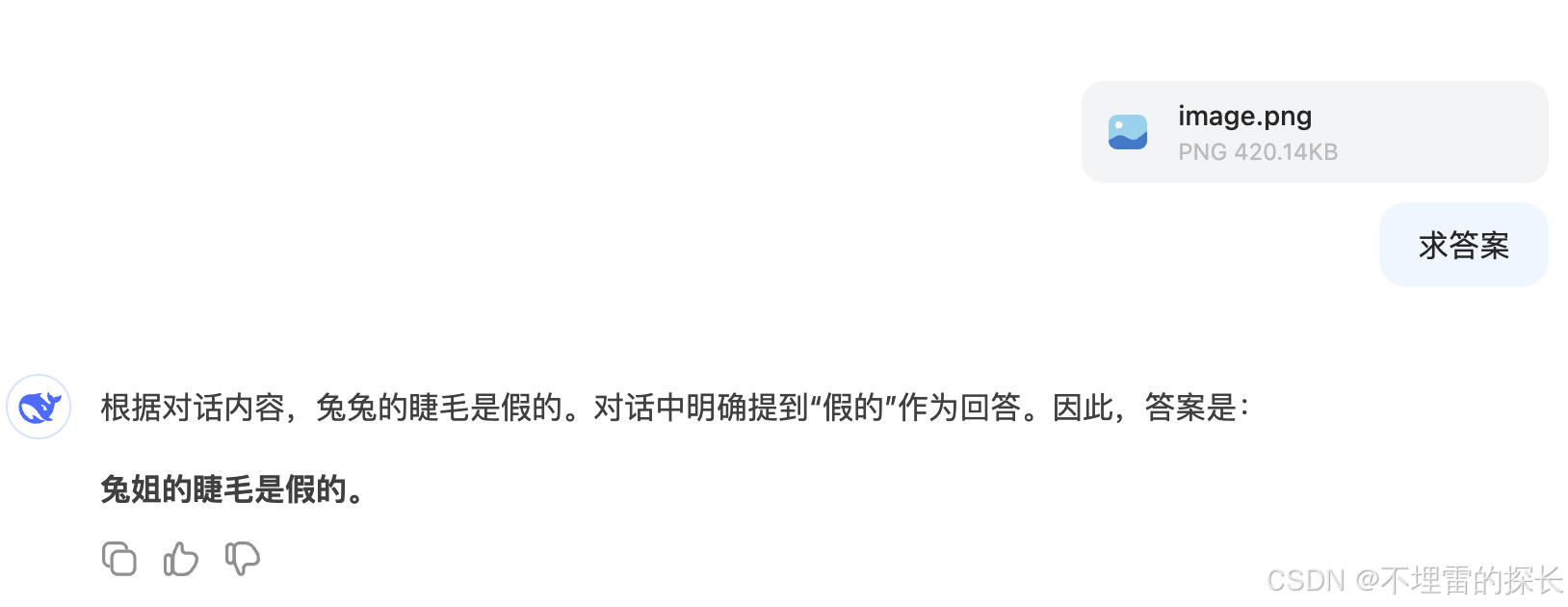 回答正确 |
回答正确 |
回答错误 |
回答正常 |
回答错误 |
| 代码code |
直接有运行按钮 |
|
效果一般 |
|
|
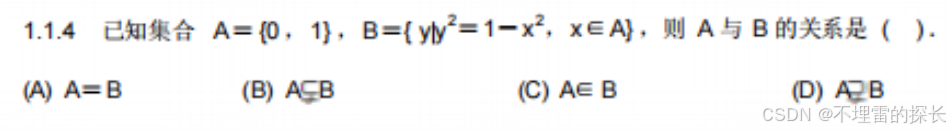







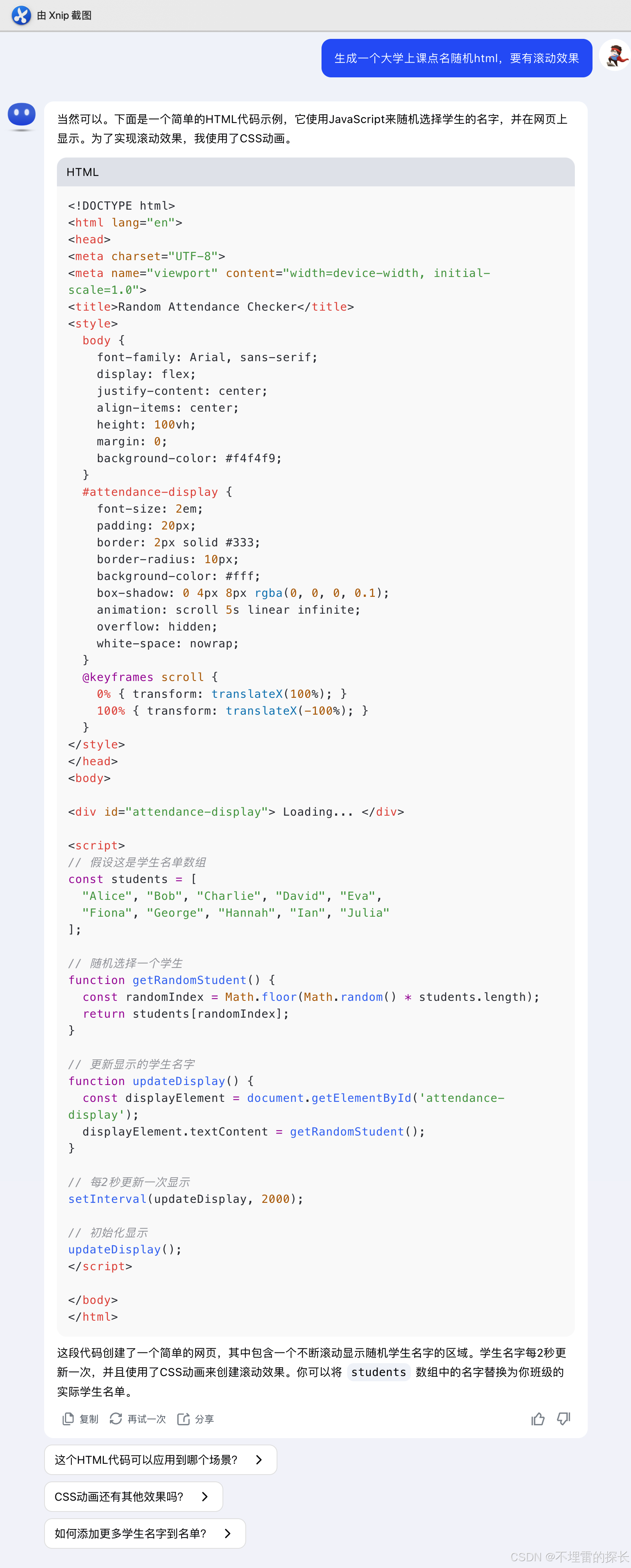

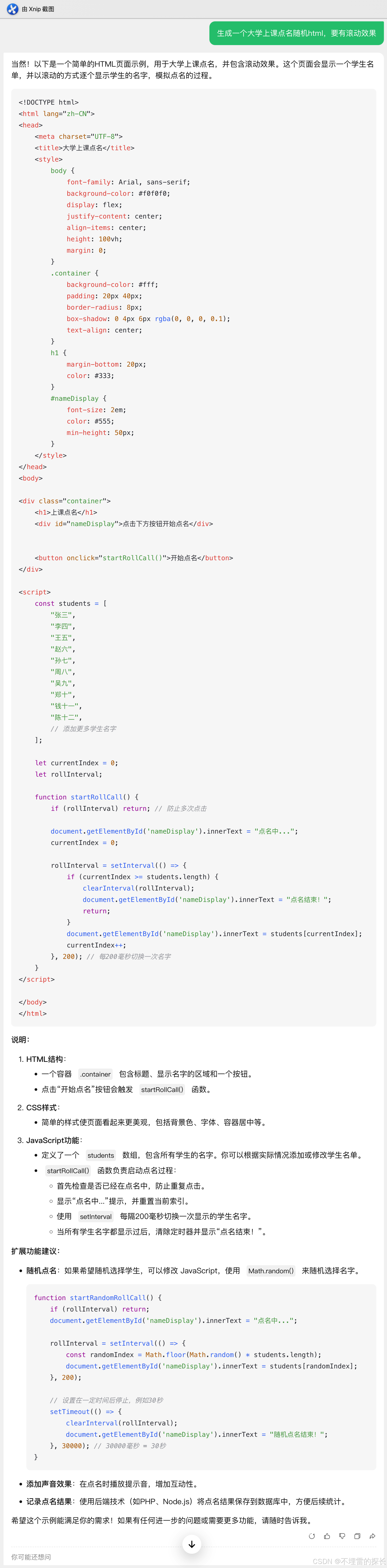

参考链接1:DeepSeek-R1/DeepSeek_R1.pdf at main · deepseek-ai/DeepSeek-R1 · GitHub
参考链接3:HAI-LLM:高效且轻量的大模型训练工具

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)