1.Deepseekv3论文的部分解释
1. DeepSeek-V3是一个强大的专家混合 (MoE) 语言模型,总共有 671B 个参数,每个令牌激活了 37B。2. DeepSeek-V3 采用了多头潜在注意力 (MLA) 和 DeepSeekMoE 架构,实现了高效的推理和具有成本效益的训练。3. DeepSeek-V3 开创了一种用于负载均衡的辅助无损策略,目的是最大限度地减少鼓励负载均衡对模型性能的不利影响。并设定了多标记预测训
论文下载地址:[2412.19437] DeepSeek-V3 Technical Report
1.摘要
1. DeepSeek-V3是一个强大的专家混合 (MoE) 语言模型,总共有 671B 个参数,每个令牌激活了 37B。
2. DeepSeek-V3 采用了多头潜在注意力 (MLA) 和 DeepSeekMoE 架构,实现了高效的推理和具有成本效益的训练。
3. DeepSeek-V3 开创了一种用于负载均衡的辅助无损策略,目的是最大限度地减少鼓励负载均衡对模型性能的不利影响。并设定了多标记预测训练目标以获得更强的评估基准的整体性能。
4. 综合评估表明,DeepSeek-V3 的性能优于其他开源模型,并实现了与领先的闭源模型相当的性能。模型的性能出色,并且只需要 2.788M H800 GPU 小时接受全面培训。模型检查点可在 https://github.com/deepseek-ai/DeepSeek-V3 获取。和其他模型性能对比如下:
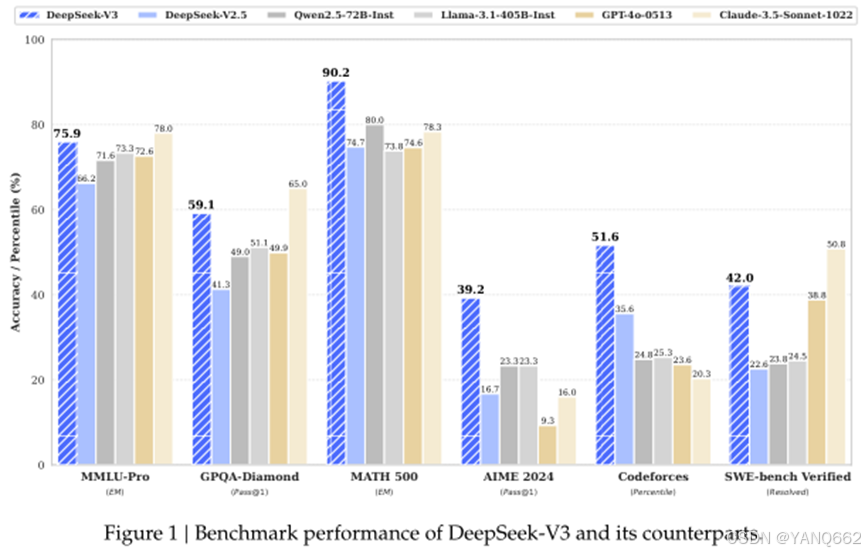
加的几条重要的文章内容:
5. DeepSeek-V3引入了FP8 混合精度训练框架,并首次进行了验证它在超大规模模型上的有效性。通过对 FP8 计算的支持和存储,我们实现了加速训练和减少 GPU 内存使用。
6. 对于训练框架,我们设计了 DualPipe 算法以实现高效的管道并行性,它具有较少的管道气泡,并在训练期间隐藏了大部分通信计算-通信重叠。此外,我们精心优化了内存footprint,从而可以在不使用昂贵的张量并行性的情况下训练 DeepSeek-V3。结合这些努力,我们实现了高培训效率。
2. 模型的基本架构
模型的基本架构如下:
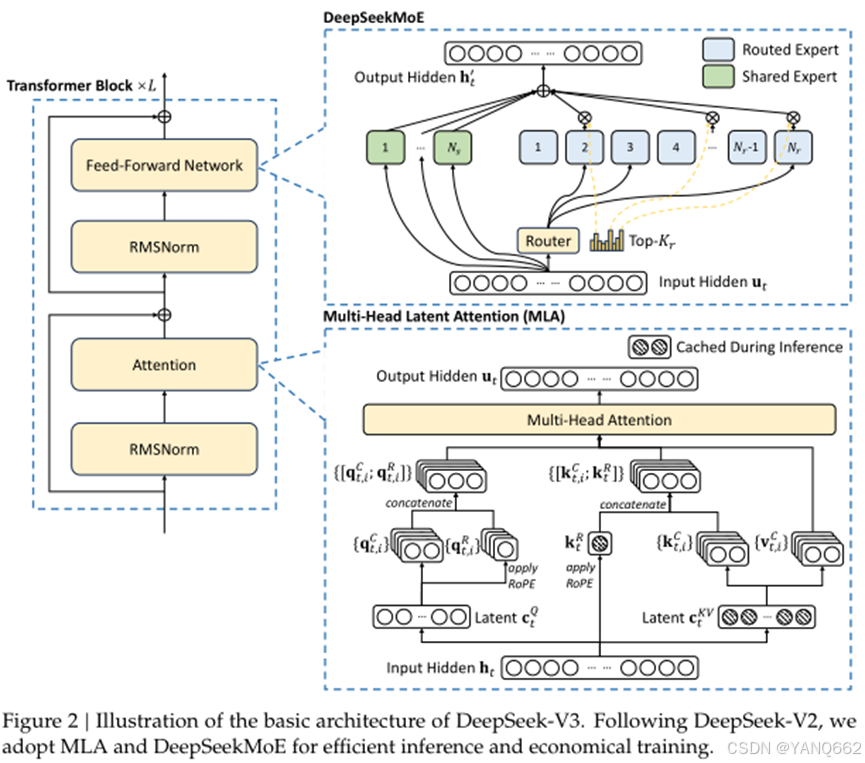
其实以上框架的主体部分是Transformer Block ×𝐿框架,显然,该框架由L个单元叠加而成,每个单元由Feed-Forward Network、Attention和两个RMSNorm构成,其中Feed-Forward Network就是上图中右边的DeepSeekMoE,Attention就是上图中右边的Multi-Head Latent Attention (MLA)。
下面对每个单元的Feed-Forward Network、Attention分别介绍:
2.1 Attention:Multi-Head Latent Attention(MLA)
1. 在深度学习领域,注意力机制已经成为处理序列数据(如文本、音频等)的关键技术。它允许模型在处理输入时,关注到输入中最重要的部分,而不是平等地对待所有信息。然而,传统的注意力机制,特别是多头注意力(Multi-Head Attention,MHA),在处理长序列时,计算量和内存消耗都会显著增加。为了解决这个问题,研究人员提出了 Multi-Head Latent Attention (MLA),一种更高效的注意力机制。
2. MLA 的核心思想:压缩与解压
MLA 的核心思想可以用一个生动的比喻来理解:想象你有一个装满玩具的大箱子。传统的 MHA 就像每次找玩具时,都要把所有玩具都翻一遍,既费时又费力。而 MLA 则像是给玩具箱里的玩具做了“压缩包”,将玩具分成几个小包,每个小包里只装最重要的玩具。当你需要找某个玩具时,只需要打开对应的小包,就能快速找到。
这种“压缩”和“解压”的思想,正是 MLA 的精髓所在。它通过引入“潜在变量”(Latent Variables),将原始输入信息压缩成更紧凑的表示,然后在需要时再将这些表示“解压”出来。
3.

4. 算法实现细节
MLA 的算法实现可以分为以下几个关键步骤:
(1)输入嵌入(Input Embedding):
- 与传统的 MHA 类似,MLA 首先将输入序列中的每个元素(例如,文本中的每个词)转换为一个向量表示,称为嵌入向量(Embedding Vector);
- 假设输入序列为 X,长度为 L,嵌入维度为 d,则嵌入后的表示为 X ∈ R^(L×d)。
(2)潜在变量生成(Latent Variable Generation):
- MLA 的核心在于引入潜在变量 Z,这些变量是对输入序列的压缩表示;
- 首先,将输入 X 通过一个线性变换,得到一个查询(Query)矩阵 Q ∈ R^(L×d);
- 然后,通过另一个线性变换,得到一个键(Key)矩阵 K ∈ R^(L×d);
- 通过一个可学习的参数矩阵 W_z ∈ R^(d×k),将 Q 映射到潜在变量空间,得到潜在变量 Z ∈ R^(L×k),其中 k 是潜在变量的维度,通常远小于 d;
Z = Q * W_z
5. 可以理解为,潜在变量 Z 是对输入序列 X 的一种“压缩”表示,它保留了输入序列的关键信息。
(3) 注意力权重计算(Attention Weight Calculation):
- 在潜在变量空间中,计算 Z 与 K 之间的相似度,得到注意力权重;
- 使用点积计算相似度,得到注意力矩阵 A ∈ R^(L×L);
A = softmax(Z * K^T / sqrt(k))
3.这里除以 sqrt(k) 是为了防止点积过大,导致 softmax 函数梯度消失。
(4)值向量计算(Value Vector Calculation):
通过一个线性变换,将输入 X 映射到值(Value)矩阵 V ∈ R^(L×d)。
(5)加权求和(Weighted Sum):
使用注意力权重 A 对值向量 V 进行加权求和,得到最终的输出 O ∈ R^(L×d)
O = A * V
这个过程可以看作是对潜在变量 Z 的“解压”,将压缩的信息还原到原始维度。
(6)多头机制(Multi-Head Mechanism):
2.2 MLA原理
在了解MLA原理之前,我们先对MHA机制做大概的了解,MHA机制通过并行计算多个注意力头来捕捉输入序列中的不同特征。每个注意力头都有自己的查询(Query, Q)、键(Key, K)和值(Value, V)矩阵:
查询矩阵 Q:用于计算输入序列中每个位置的注意力权重。
键矩阵 K:用于与查询矩阵 Q 计算注意力分数。
值矩阵 V:用于根据注意力分数加权求和,得到最终的输出。
MLA 的核心思想是通过低秩联合压缩技术,减少 K 和 V 矩阵的存储和计算开销。
2.2.1 低秩联合压缩
(1)压缩键和值:
设输入序列的第 t 个 token 的嵌入向量为 ![]() ,其中 d 是嵌入维度。
,其中 d 是嵌入维度。
通过一个下投影矩阵 ![]() ,将
,将 ![]() 压缩为一个低维的潜在向量
压缩为一个低维的潜在向量 ![]() ,其中
,其中 ![]() ,
, ![]() 是每个注意力头的维度,
是每个注意力头的维度,![]() 是注意力头的数量。
是注意力头的数量。
![]()
(2)重建键和值:
通过上投影矩阵 ![]() 和
和![]() ,将压缩后的潜在向量
,将压缩后的潜在向量 ![]() 重建为键和值矩阵:
重建为键和值矩阵:
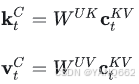
(3)应用旋转位置编码(RoPE):
为了引入位置信息,MLA 对键矩阵应用旋转位置编码(RoPE):
![]()
其中, ![]() 是用于生成解耦键的矩阵,
是用于生成解耦键的矩阵, ![]() 是解耦键的维度。
是解耦键的维度。
(4)最终键和值:
最终的键和值矩阵由压缩后的键和值以及旋转位置编码后的键组合而成:
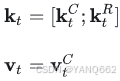
2.2.2 查询矩阵的低秩压缩
MLA 还对查询矩阵 Q 进行低秩压缩,以减少训练时的激活内存:
(1)压缩查询:
通过下投影矩阵 ![]() ,将
,将 ![]() 压缩为一个低维的潜在向量
压缩为一个低维的潜在向量 ![]() ,其中
,其中![]() 。
。
![]()
(2)重建查询:
通过上投影矩阵 ![]() ,将压缩后的潜在向量
,将压缩后的潜在向量 ![]() 重建为查询矩阵:
重建为查询矩阵:
![]()
(3)应用旋转位置编码(RoPE):
对查询矩阵应用旋转位置编码:
![]()
其中, ![]() 是用于生成解耦查询的矩阵。
是用于生成解耦查询的矩阵。
(4)最终查询:
最终的查询矩阵由压缩后的查询和旋转位置编码后的查询组合而成:
![]()
2.2.3 注意力计算
(1)计算注意力分数:
对于每个注意力头 i ,计算查询![]() 和键
和键 ![]() 的点积,并除以
的点积,并除以![]() 进行缩放:
进行缩放:
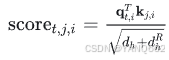
(2)计算注意力权重:
对注意力分数进行 softmax 归一化,得到注意力权重:
![]()
(3)加权求和:
使用注意力权重对值![]() 进行加权求和,得到每个注意力头的输出:
进行加权求和,得到每个注意力头的输出:
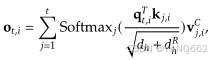
(4)合并多头输出:
将所有注意力头的输出拼接起来,并通过输出投影矩阵![]() 进行线性变换,得到最终的注意力输出:
进行线性变换,得到最终的注意力输出:
![]()
2.2.4 总结
Multi-Head Latent Attention (MLA) 通过低秩联合压缩技术,显著减少了推理时的键值缓存和训练时的激活内存,同时保持了与标准多头注意力机制相当的性能。MLA 的核心在于对键、值和查询矩阵进行低秩压缩,并通过旋转位置编码引入位置信息,从而在高效推理的同时捕捉输入序列中的复杂特征。
在实际应用中,低维潜在向量的维度 dc 和 dc′ 通常设置为原始嵌入维度 d 的1/4到 1/8 之间。
本文看了【AI学习】DeepSeek-V3 技术报告学习:总体架构_deepseek-v3 technical report-CSDN博客的博客,作为笔记用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)