LangGraph中常见的工作流模式与持久化能力
一.常见的工作流模式
此部分其实大多数工作流模式我们都在上一篇文章多少见过,或者之前学习langchain时见过,所以我们这里仅详细介绍没有见过的工作流模式(都不是很难就是了)
1.1提示链模式
提示链就像流水线一样,前一个步骤的输出作为下一个步骤的输入。这就跟进行内容创作时,需要 大纲 → 初稿 → 润色 → 最终稿,且每个步骤的输出需要传输给下一个步骤,才能确保内容质量逐步提升。
再说直白些就是我们langchain中一直使用的链式思维编程模式,这里不再多说。
1.2并行模式
并行化是指多个任务同时进行,提高效率,最终汇总结果。在多角度处理同一问题时,常用该模式。
例如,现在需要研发一款主打城市通勤的智能电动自行车,具有导航、社交、防盗等功能。在开始研发前,需要进行多维度分析,如:
- 市场分析:用户关注续航里程、车身重量、防盗能力,并对“骑行社交”(组队、分享路线)有新兴兴趣。
- 竞品分析:传统品牌车型智能化不足;互联网品牌车型续航和线下售后服务是其短板。
- 技术分析:评估更轻量化的电池材料与车身设计以提升续航和便携性,并开发基于 GPS 和 移动网络 的智能防盗系统与社交功能 App 的集成。
那么这三个方面就可以定义为三个节点,也就是从开始START节点定义三个固定边让这三个任务并行执行(实际langgraph实现时底层是通过异步形式来执行的)。这个也比较简单不再多说。
1.3路由模式
路由模式也被称为“智能分流”,根据输入内容决定执行哪个分支。这里以我们上篇文章写的案例一作为例子来直白解释。
那个例子里,当包裹经过派送站时,会根据最开始设置的标记位,进行不同方式的派送,这就是路由模式的一种体现。也比较简单不再多说。
1.4协调者-工作者模式
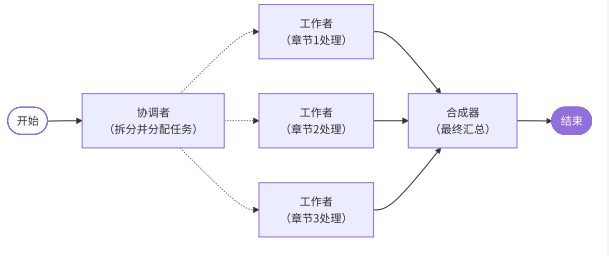
我们来看上面一个图,假设此时我们有一个软件开发项目小组。此小组中的协调者就是项目经理,三个工作者分别是前端,后端,和测试。有的时候,如果我们仅需要去开发一个纯后端软件,有可能是不需要前端来干活的。
那么此时就可以仅选择后端,测试参与到软件的开发中。那么具体的协调者工作者模式就是,通过协调者对任务的综合判断之后,选择工作者参与到工作流程中,可能全部选择,但也可能只选择一个。那么怎么达到上面那种可以进行节点选择的效果呢,条件边也只能选一个啊,这里就需要使用到langgraph为我们提供的Send:
1.4.1 Send
在 LangGraph 中,Send 是一个数据类,用于动态分发任务。它的构造函数签名通常是:
Send(node: str, arg: Any)
常用参数只有两个:
-
node(必需)
类型:str
作用:指定目标节点的名称(即图中已添加的节点)。LangGraph 会根据这个名称去执行对应的节点函数。 -
arg(必需)
类型:Any,通常是dict(部分状态)
作用:传递给目标节点的输入数据。
当并行执行多个Send时,每个Send的arg会与当前状态合并(或覆盖),形成该子任务独立的状态副本。
常见的用法是传入一个字典,包含该子任务所需的最小字段(例如{"subject": "cats"})。
1.4.2 案例
下面是一个协调者-工作者模式举例(按照我们上面给的例子进行编写):
import operator
from typing import TypedDict, Annotated, Optional
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import Send
from matplotlib import image as mpimg, pyplot as plt
from pydantic import BaseModel, Field
llm_model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
#协调者-工作者模式->主题大致方向:开发一个软件
#1.定义状态类
class State(TypedDict):
app_descript: str #软件的详细描述
task_list : dict #由协调者生成的任务字典
result_list : Annotated[list[str],operator.add]
final_result : str
class Structure(BaseModel):
front : Optional[str] = Field(default="",description="前端的任务大纲,如没有则不用填写")
behind : Optional[str] = Field(default="",description="后端的任务大纲,如果没有则不用填写")
testing : Optional[str] = Field(default="",description="测试的任务大纲,如果没有则不用填写")
TASK_QUESTION_FORMAT = (
"你是一个项目经理,请你基于客户对软件的描述,为前端后端及测试写三份任务大纲(可以不用使用全部人),每份大纲内容不超过200。\n"
"客户对软件的简单描述如下:\n"
"{topic}"
)
#2.定义各个函数节点
#协作者函数节点
def Coordinator(state: State):
"""调用llm基于给定主题给一个任务大纲"""
struct_llm = llm_model.with_structured_output(Structure)
result = struct_llm.invoke([HumanMessage(content=TASK_QUESTION_FORMAT.format(topic=state["app_descript"]))])
task_list : dict = {}
#空字符串和None都会被判定为False
if result.front:
task_list["front"] = result.front
if result.behind:
task_list["behind"] = result.behind
if result.testing:
task_list["testing"] = result.testing
return {
"task_list" : task_list
}
#后端函数节点
def Behind(state: State):
#task_seaction在条件边Send中设置
result = "我是一个后端,我的任务大纲如下:\n" + state["task_seaction"]
return {
"result_list" : [result]
}
#前端函数节点
def Front(state: State):
#task_seaction在条件边Send中设置
result = "我是一个前端,我的任务大纲如下:\n" + state["task_seaction"]
return {
"result_list" : [result]
}
#测试函数节点
def Testing(state: State):
#task_seaction在条件边Send中设置
result = "我是一个测试,我的任务大纲如下:\n" + state["task_seaction"]
return {
"result_list" : [result]
}
def SummaryResult(state: State):
result = "\n\n".join(state["result_list"])
return {
"final_result" : result
}
#3.添加节点与连接边
graph = StateGraph(State)
graph.add_node(Coordinator)
graph.add_node(Behind)
graph.add_node(Front)
graph.add_node(Testing)
graph.add_node(SummaryResult)
graph.add_edge(START,"Coordinator")
graph.add_edge("Behind","SummaryResult")
graph.add_edge("Front","SummaryResult")
graph.add_edge("Testing","SummaryResult")
graph.add_edge("SummaryResult",END)
def conditional_judge(state : State):
result : list[Send] = []
if "front" in state["task_list"]:
result.append(Send("Front",{"task_seaction" : state["task_list"]["front"]}))
if "behind" in state["task_list"]:
result.append(Send("Behind",{"task_seaction" : state["task_list"]["behind"]}))
if "testing" in state["task_list"]:
result.append(Send("Testing",{"task_seaction" : state["task_list"]["testing"]}))
return result
graph.add_conditional_edges(
"Coordinator",
conditional_judge
)
#4.编译图
graph_system = graph.compile()
#5.测试系统是否能够正常运行
State_datas = [
State(
app_descript="请帮我写一个程序能够在linux服务端部署然后我可以通过浏览器和其进行ai对话,此程序不需要前端人员",
task_list={},
result_list=[],
final_result=""
),
]
print(graph_system.invoke(State_datas[0])["final_result"])
最后给的请求中明确要求了不需要前端,我们来看下最终结果:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test4.py
我是一个后端,我的任务大纲如下:
1. 开发环境配置:设定Linux服务器及所需软件(Python,Flask/Django)。
2. 接口设计:设计与前端交互的API,使用RESTful风格。
3. AI集成:选择合适的AI模型,整合进后端服务。
4. 数据存储:选择数据库(如MySQL/PostgreSQL),设计数据表结构,编写增删改查操作。
5. 安全性:实现用户认证和API安全。
6. 部署:编写Dockerfile和相关部署脚本,确保后端服务可在Linux环境下稳定运行。
我是一个测试,我的任务大纲如下:
1. 测试计划:制定整体测试计划,明确测试范围与策略。
2. 单元测试:对后端接口及AI模型功能进行单元测试,确保逻辑准确。
3. 集成测试:测试前后端交互,包括API的正确返回及性能测试。
4. 功能测试:验证所有需求功能是否实现,确保无严重bug。
5. 性能测试:评估系统在并发情况下的响应时间与稳定性。
6. 安全测试:检查系统是否存在安全漏洞,如SQL注入、XSS等。
进程已结束,退出代码为 0
可以看到系统并没有为前端分配对应的任务。
1.5评估器-优化器模式
评估器-优化器模式的流程是:
- 先进行生成内容
- 再进行评估质量
- 如果需要改进就重新生成,不断改进直到满足质量标准
经典的场景就是内容质量优化、代码生成和改进等。评估器-优化器流程图如下所示: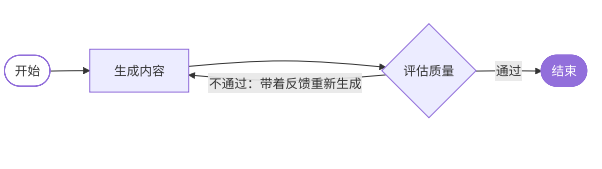
这个模式的例子我们前文的案例三中也已经见过了,就是重写问题那一部分,这里我们不再多说。
二.LangGraph提供的持久化能力
Tips:本部分例子均由上文案例二改造而来
2.1线程级持久化
像我们在使用ds或者gemini这些对话式ai应用网站时,页面左边都会有对话列表,存储着我们与ai先前的所有对话记录。那么在LangGraph中也是这样子去管理不同的对话的,每一组对话记录在LangGraph中被称为一个线程,他们彼此之间通过thread_id进行唯一标识符区分。
LangGraph 的持久化机制——线程级持久化是其核心功能,它通过**【线程】和【检查点】**这两个核心部分来实现。具体如下:
2.1.1 Threads(线程)
在 LangGraph 中,Thread 代表一个独立的工作流执行会话。可以把它想象成**【与某个用户的一次完整对话历史】或【处理某个特定任务的一次完整执行过程】**。例如在 DS 中的一次完整对话:
Thread 的关键特性如下:
- 隔离性:每个 Thread 都是完全独立的,它们的状态互不干扰
- 持久化单元:Thread 是状态持久化的基本单位
- 标识符:通过唯一的
thread_id来识别
2.1.2 Checkpoints(检查点)
Checkpoint 是 Thread 在特定时刻的**【状态快照】。它记录了工作流执行到某个节点时的完整状态。例如在刚才的会话中,每一次用户输入和对话结束后,都可以保存一个最新的【状态快照】**(在LangGraph中是每经过一个节点保存一个快照)
Checkpoint 的关键特性:
- 状态快照(StateSnapshot):保存了工作流在某个时间点的完整状态。包含**【状态值】、【下一步要执行的节点】、【与此检查点关联的配置】和【与此检查点关联的元数据】**等信息。
StateSnapshot 结构如下:
StateSnapshot(
# 当前状态值(如:对话消息列表)
values={'messages': [用户消息, AI回复, 用户消息...]},
# 接下来要执行的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写入信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# 父检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id': 'def...'}},
# 创建时间
created_at=''
)
2.1.3内存存储与postgres数据库存储对象定义
想要实现持久化能力,那么你当然需要给我一个空间让我去存储我历史的对话数据。内存持久化因为仅仅是用于测试时进行使用,而且不方便观察,所以我们着重说明数据库存储的方式(不过定义出二者存储对象之后,二者的使用姿势基本一致,所以数据库存储例子中怎么使用,内存存储那里就可以照猫画虎)
我们先来看下怎么去定义一个内存存储对象吧:
from langgraph.checkpoint.memory import InMemorySaver
# 定义存储⽅式
checkpointer = InMemorySaver()
# ⽤ checkpointer 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
然后我们直入主题,来进行postgres数据库存储,首先你需要在本地或你的云服务器安装好postgres数据库,接下来需要在 pycharm中安装如下包:
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
连接数据库的url格式如下:
postgresql://<user>:<password>@<host>:<port>/<database_name>
使用 PostgresSaver.from_conn_string() 方法从连接字符串创建一个新的 PostgresSaver 实例。
注意:第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer)
# ...后续调用...
关键说明:
- PostgresSaver.from_conn_string():根据 PostgreSQL 连接字符串创建检查点存储实例
- checkpointer.setup():初始化数据库表结构(仅在首次使用时调用)
- compile(checkpointer=checkpointer):将检查点集成到编译后的图中,启用持久化功能
- 使用 上下文管理器(with 语句) 可以自动管理资源生命周期
2.1.4LangGraph线程级持久化的一些食用方式
获取状态快照
当使用 checkpointer 编译图时,执行时就会在每个步骤处保存状态快照。在 LangGraph 中状态快照就是 StateSnapshot 对象,其具有的关键属性可翻阅 2.1.2。
我们可以使用 get_state(config) 方法,获取编译后的图的最新状态快照。让我们分别获取一下执行前与执行后的最新状态快照:
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
# 调用前的状态快照
snapshot = agent.get_state(config)
print(snapshot)
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 调用后的状态快照
snapshot = agent.get_state(config)
print(snapshot)
获取状态历史记录
我们可以通过调用 get_state_history(config) 来获取给定线程的图执行的完整历史记录。这将返回与配置中提供的线程 ID 关联的 StateSnapshot 对象列表。
from langchain.messages import HumanMessage
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [HumanMessage(content="你好")]},
config
)
# 查看状态历史记录
history = list(agent.get_state_history(config))
print(history)
返回结果将按时间倒序排序,列表中的第一个检查点(StateSnapshot)是最新的。
重放
如果我们用一个 thread_id 和一个 checkpoint_id(表示检查点标识符,用于指代线程内的特定检查点)来调用一个图,那么我们将重新执行对应于 checkpoint_id 之后的步骤。如下所示:
- 先执行一次完整的流程,获取一次完整历史记录;
- 保存中间过程某一次快照,并重新执行快照后的步骤;
- 获取第二次调用后的完整历史记录,验证是否重放成功;
这部分在下面2.1.5部分结合案例理解更合适些。
更新状态
我们还可以编辑图状态。我们使可以使用 update_state() 方法来做到这⼀点。
这部分在下面2.1.5部分结合案例理解更合适些。
2.1.5结合案例理解线程级持久化
首先来看已经编写好的案例:
import operator
from typing import TypedDict, Annotated
from langchain_core.messages import AnyMessage, ToolMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import Overwrite
#1.定义llm调用对象与搜索工具
model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
DB_URI = "postgresql://postgres:123456@ip:8091/postgres"
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
#绑定工具,否则ai不会去进行工具调用
tool_bind_model = model.bind_tools(tools=[tavilySearchTool,])
#2.定义状态类
class dialogue_data(TypedDict):
"""记录过往对话数据与简单的对话消耗"""
#此messages中包含三种message:ToolMessage,HumanMessage,AiMessage
messages: Annotated[list[AnyMessage],operator.add]
#简单记录下llm调用次数与工具调用次数
llm_calls: Annotated[int,operator.add]
tool_calls: Annotated[int,operator.add]
#3.定义节点函数
#llm调用节点
def llm_call_node(state: dialogue_data):
#让ai总结先前对话内容并给出答案-同时决定是否需要进行工具调用
ai_message = tool_bind_model.invoke(state["messages"])
#追加对话消息
return {
"messages" : [ai_message],
"llm_calls" : 1
}
#工具调用节点
def tool_call_node(state: dialogue_data):
#获取末尾AiMessage
conclusion_message = state["messages"][-1]
#此时是由条件边判断之后确定需要工具调用时才进来的-简单些直接进行工具调用不再二次判断
return_tool_messages:list[ToolMessage] = []
tool_calls = 0
for tool in conclusion_message.tool_calls:
select_tool = {"tavily_search": tavilySearchTool}[tool["name"].lower()]
tool_message = select_tool.invoke(tool)
return_tool_messages.append(tool_message)
tool_calls += 1
#工具调用完毕
return {
"messages" : return_tool_messages,
"tool_calls" : tool_calls
}
#4.定义 StateGraph 图
llm_dialogue = StateGraph(dialogue_data)
#5.添加节点
llm_dialogue.add_node(llm_call_node)
llm_dialogue.add_node(tool_call_node)
#6.添加边
llm_dialogue.add_edge(START,"llm_call_node")
def judge_tool_call(state: dialogue_data):
conclusion_message = state["messages"][-1]
if conclusion_message.tool_calls:
return "tool_call_node"
return END
llm_dialogue.add_conditional_edges(
"llm_call_node",
judge_tool_call,
["tool_call_node", END],# path_map:可选,将路径映射到节点名称->此处不写生成可视化图时tool_call_node会显示为一个独立节点但不影响功能
)
llm_dialogue.add_edge("tool_call_node","llm_call_node")
with PostgresSaver.from_conn_string(DB_URI) as checkpoint:
#7.编译图
#第一次使用需要setup
checkpoint.setup()
config = {"configurable" : {"thread_id" : "2222"}}
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint)
stateSnapshotList = result_llm_dialogue.get_state_history(config=config)
#8.检验成果
# dialogue_datas = [
# dialogue_data(
# messages=[HumanMessage(content="你直接复述一遍你刚才回答的内容,我在测试一些功能,记得加上前缀->我刚才回答的内容为:"),],
# tool_calls=0,
# llm_calls=0
# ),
# ]
#
# for data in dialogue_datas:
# result = result_llm_dialogue.invoke(data,config=config)
# final_message = result["messages"][-1]
# print(f"{'=' * 20}本次调用结束{'=' * 20}")
# print(f"结果:{final_message.content}\n")
# print(f"llm调用次数为:{result["llm_calls"]}\n")
# print(f"工具调用次数为:{result["tool_calls"]}\n\n")
持久化能力验证
我们先来改下8.检验成果部分的with as语句以下的代码(后面演示重放和更新也都是仅改此部分代码),然后问它几个问题,检验下线程级持久化是否有效:
with PostgresSaver.from_conn_string(DB_URI) as checkpoint:
#7.编译图
#第一次使用需要setup
checkpoint.setup()
config = {"configurable" : {"thread_id" : "2222"}}
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint)
# stateSnapshotList = result_llm_dialogue.get_state_history(config=config)
#8.检验成果
dialogue_datas = [
dialogue_data(
messages=[HumanMessage(content="你直接复述一遍你刚才回答的内容,我在测试一些功能,记得加上前缀->我刚才回答的内容为:"),],
tool_calls=0,
llm_calls=0
),
]
for data in dialogue_datas:
result = result_llm_dialogue.invoke(data,config=config)
final_message = result["messages"][-1]
print(f"{'=' * 20}本次调用结束{'=' * 20}")
print(f"结果:{final_message.content}\n")
print(f"llm调用次数为:{result["llm_calls"]}\n")
print(f"工具调用次数为:{result["tool_calls"]}\n\n")
然后问它如下问题:
你好我叫小明,你可以为我介绍下世界计划这款游戏中的Yoisaki Kanade吗,最好是结合活动剧情进行介绍,尽量简洁。
请问下我的名字是什么啊?
结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test5.py
====================本次调用结束====================
结果:宵崎奏(Yoisaki Kanade)是《世界计划》中“25点,Nightcord见。”团队的核心人物,实际上的团长,擅长作曲。她的生日是2月10日,兴趣包括听音乐、观赏电影、漫画、动画和艺术作品。宵崎奏来自一个音乐家庭,父母均为音乐人,她有超群的作曲才能。
在活动剧情中,她性格温柔善良,经常为他人着想,却很少考虑自己。由于母亲的早逝和父亲的健康问题,奏以创造“让人幸福的音乐”为目标,常常闭门不出,长期在阴暗环境中工作,导致不喜欢阳光。在某次为父亲创作音乐的尝试中却导致了悲剧,受此影响而感到深深的内疚和责任感。
通过与团队的合作,宵崎奏逐渐克服了自己的心理阴影,和队友们一起创作出充满温暖和希望的音乐,体现了她对人性和情感的探索与理解。她与其他成员的互动与成长也是整个剧情的重要部分,展现了友情、支持与音乐的力量。
相关活动如“Colors of Pure Sense”中的剧情进一步推动了她的角色发展,聚焦于她的内心挣扎和最终的救赎。
llm调用次数为:2
工具调用次数为:1
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test5.py
====================本次调用结束====================
结果:你的名字是小明。
llm调用次数为:3
工具调用次数为:1
再来看下我们案例二的结构图示: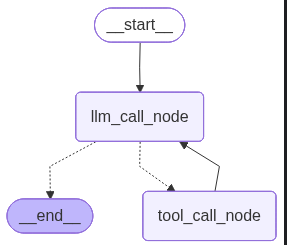
注意,检查点是在每个节点运行完毕之后进行保存的,所以运行时经过图中的每条边时会进行一个检查点保存,第一次调用时有工具调用,图中所有节点均经历过,所以此过程应该保存了四个checkpoint,加上start节点之前的输入的checkpoint一共5个。
第二次没有工具调用一共应该是有3个checkpoint。我们来使用navicat来验证下: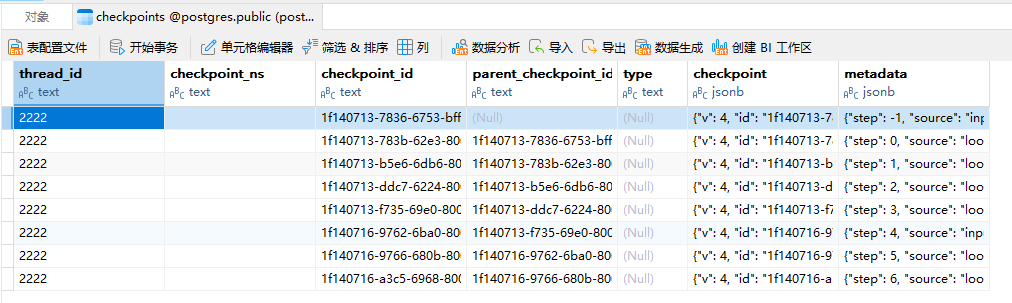
确实是8条checkpoint记录。
理解重放
我们上面也说过了,重放是将某一个checkpoint拿出来,然后让LangGraph从此处开始重新运行。
但是有些问题,重新运行后的结果是怎么保存的呢?需要注意,LangGraph有一个原则,每次运行时都会从时间最新的checkpoint处开始运行,这是一个铁律,我们先记下。然后就是如何保存的问题,我们先来看一个图,就以上面验证部分的checkpoint为例子: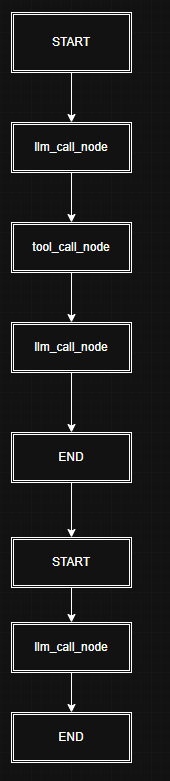
每个快照的结构如下:
StateSnapshot(
# 当前状态值(如:对话消息列表)
values={'messages': [用户消息, AI回复, 用户消息...]},
# 接下来要执行的节点
next=('generate_response',),
# 配置信息
config={'configurable': {'thread_id': '123', 'checkpoint_id': 'abc'}},
# 元数据(步骤号、来源、写入信息等)
metadata={'step': 2, 'source': 'loop', 'writes': {...}},
# 父检查点(形成链表)
parent_config={'configurable': {'thread_id': '123', 'checkpoint_id': 'def...'}},
# 创建时间
created_at=''
)
可以使用如下代码查看调用流程(也是改with部分):
with PostgresSaver.from_conn_string(DB_URI) as checkpoint:
#7.编译图
#第一次使用需要setup
checkpoint.setup()
config = {"configurable" : {"thread_id" : "2222"}}
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint)
stateSnapshotList = result_llm_dialogue.get_state_history(config=config)
for stateSnapshot in stateSnapshotList:
print('=' * 40)
print(f"下一个节点为{stateSnapshot.next}。")
print(f"当前节点的checkpoint_id为:{stateSnapshot.config["configurable"]["checkpoint_id"]}。")
print('=' * 40)
这个例子中走的流程大致如上。然后我们重放第二个节点前的checkpoint,也就是第二次问问题时,我们来改下代码并看下结果(我这里此checkpoint的id为1f140716-9766-680b-8005-536e8be17edf):
with PostgresSaver.from_conn_string(DB_URI) as checkpoint:
#7.编译图
#第一次使用需要setup
checkpoint.setup()
config = {"configurable" : {"thread_id" : "2222"}}
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint)
stateSnapshotList = result_llm_dialogue.get_state_history(config=config)
tar_snapshot = None
for stateSnapshot in stateSnapshotList:
if stateSnapshot.config["configurable"]["checkpoint_id"] == "1f140716-9766-680b-8005-536e8be17edf":
tar_snapshot = stateSnapshot
#重放操作-必须是绑定有线程存储的编译图对象才能有效调用
result = result_llm_dialogue.invoke(None,config=tar_snapshot.config)
result["messages"][-1].pretty_print()
结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test5.py
================================== Ai Message ==================================
你的名字是小明。
可以猜测的是它将所有的流程重新走了一遍,结果好像没变,但是我们看navicat: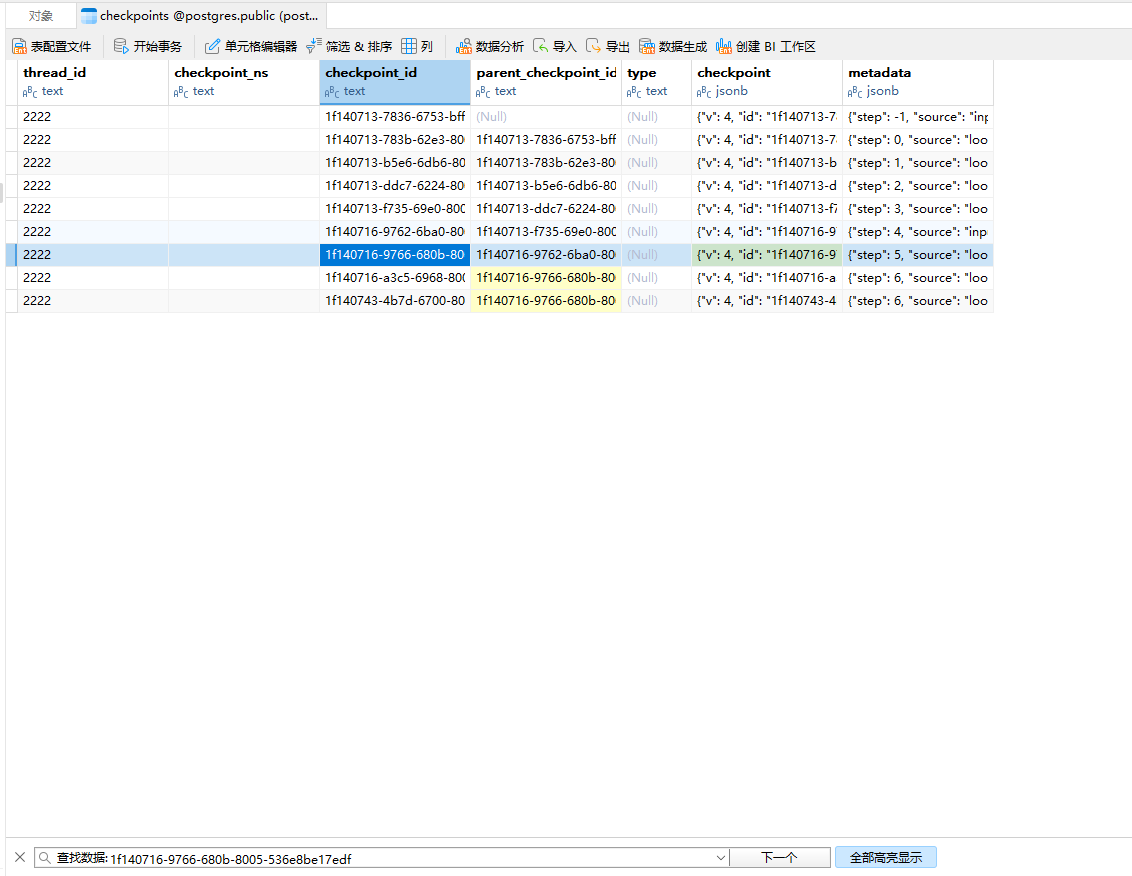
可以看到多出来了一个checkpoint,并且他和上面一个checkpoint的step是一样的。同时他和前面的checkpoint的父亲checkpoint_id也是一致的,也就是说重放之后整个图变成了如下样子:
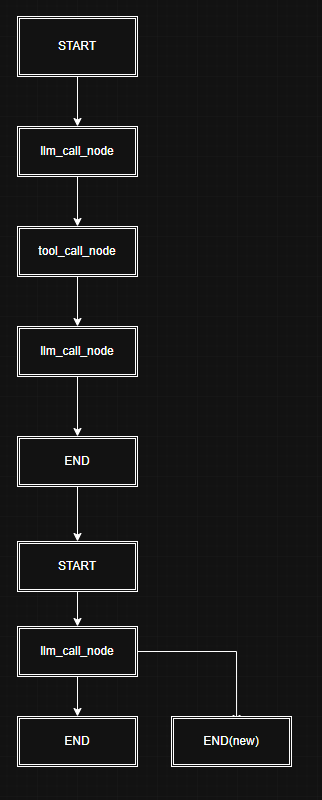
这样我们就基本上能明白重放是怎么一个流程了,不过还有一个东西我们没有验证,它是不是按照最新分支走的呢,很简单,我们再随便问一个问题,然后来看navicat,验证这个新分支的祖宗是不是我END(new)的即可:
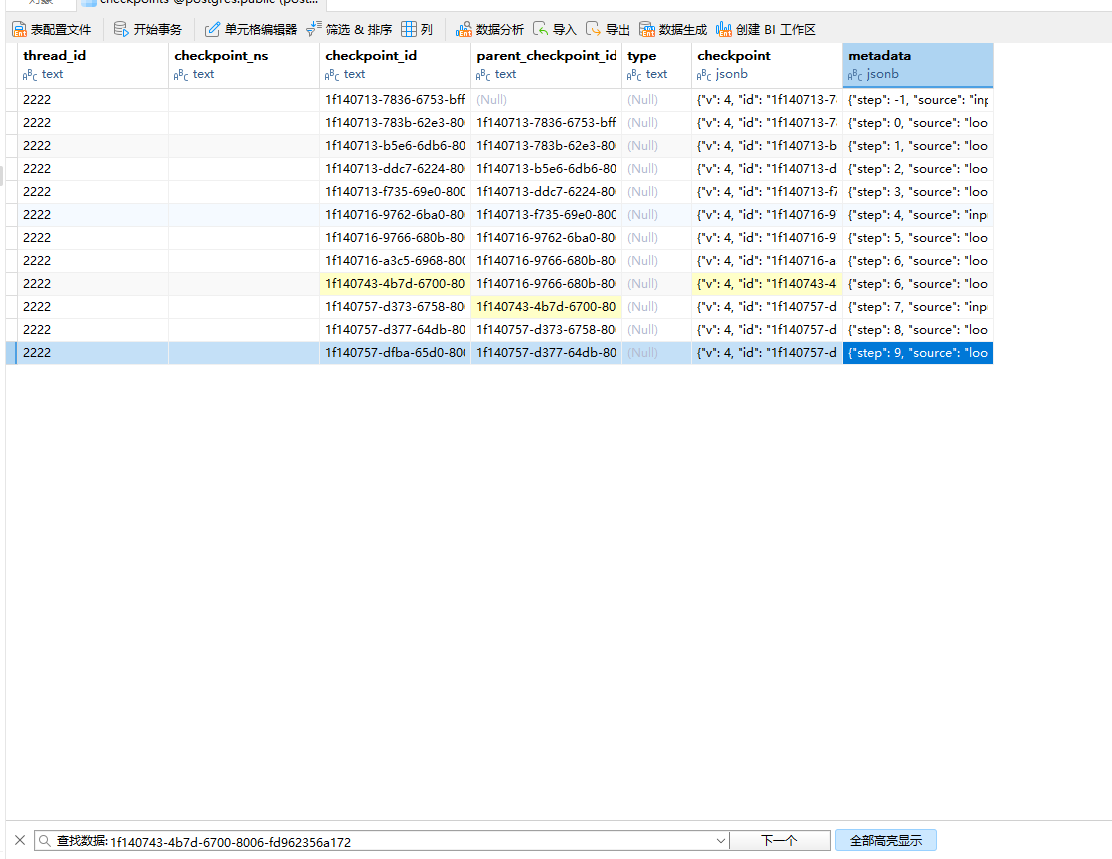
可以看到确实是的。
理解更新
我们这里接着上面已经进行过的部分实验,这里我们更新最开始的问题,然后来看看LangGraph的树形结构:
with PostgresSaver.from_conn_string(DB_URI) as checkpoint:
#7.编译图
#第一次使用需要setup
checkpoint.setup()
config = {"configurable" : {"thread_id" : "2222"}}
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint)
stateSnapshotList = result_llm_dialogue.get_state_history(config=config)
select_snapshot = None
for stateSnapshot in stateSnapshotList:
#第一个问题开始时当然只有一条消息
if len(stateSnapshot.values["messages"]) == 1:
select_snapshot = stateSnapshot
new_config = result_llm_dialogue.update_state(
select_snapshot.config,
{"messages": Overwrite([HumanMessage(content="可以介绍下世界计划中25时团体的角色东云绘名吗,最好是结合其活动剧情进行介绍")])} # 清空消息,重新写⼊
)
print("-" * 80)
print(f"更新后配置:{new_config}")
# 第⼆次执⾏:重放更新后的配置
result = result_llm_dialogue.invoke(None, config=new_config)
final_message = result["messages"][-1]
print(f"{'=' * 20}本次调用结束{'=' * 20}")
print(f"结果:{final_message.content}\n")
print(f"llm调用次数为:{result["llm_calls"]}\n")
print(f"工具调用次数为:{result["tool_calls"]}\n\n")
结果如下
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test5.py
--------------------------------------------------------------------------------
更新后配置:{'configurable': {'thread_id': '2222', 'checkpoint_ns': '', 'checkpoint_id': '1f14076a-b36e-6e66-8001-a01944002772'}}
====================本次调用结束====================
结果:东云绘名是手游《世界计划》中25时团体的一员。25时团体是游戏中的一个重要角色团队,致力于进行音乐活动和演出。绘名作为团队的一员,负责创作和表演音乐,展现了她的才华和个性。
### 角色背景
东云绘名是一个充满活力和梦想的少女,她拥有出色的音乐才华,特别是在作曲和歌词创作方面。她的性格开朗且积极,总是努力追求自己的梦想,并希望能够通过音乐 touch 到更多人。
### 活动剧情
在游戏的活动剧情中,东云绘名经常与25时团体的其他成员一起参与各种音乐活动和比赛。在剧情发展中,她面临着许多挑战,包括创作灵感的枯竭、团队合作的摩擦等。不过,正是在这些困难中,她不断成长,强化了与团队成员之间的情感纽带。
例如,在某些活动故事中,绘名可能会因为一次失误而感到沮丧,但在朋友的鼓励下,她又重新振作,最终创作出了一首感动人心的歌曲。这样的情节不仅展示了她的音乐才能,也强调了团队合作和友谊的重要性。
### 角色特色
绘名的角色设计也很有特色,她的服装通常色彩鲜艳,体现出她活泼的个性。在音樂演出中,她的表现总是充满热情,能够带动观众的情绪。她有时还会通过讲故事或与观众互动来增加演出的趣味性。
### 总结
东云绘名作为25时团体的一员,通过她的音乐创作和表演,为《世界计划》的故事增添了不少色彩。她的角色不仅仅是音乐的代表,更是梦想追求和团队合作精神的体现。通过各种活动剧情,玩家能够更深入地了解她的性格和成长历程。
llm调用次数为:1
工具调用次数为:0
进程已结束,退出代码为 0
我们来看下navicat: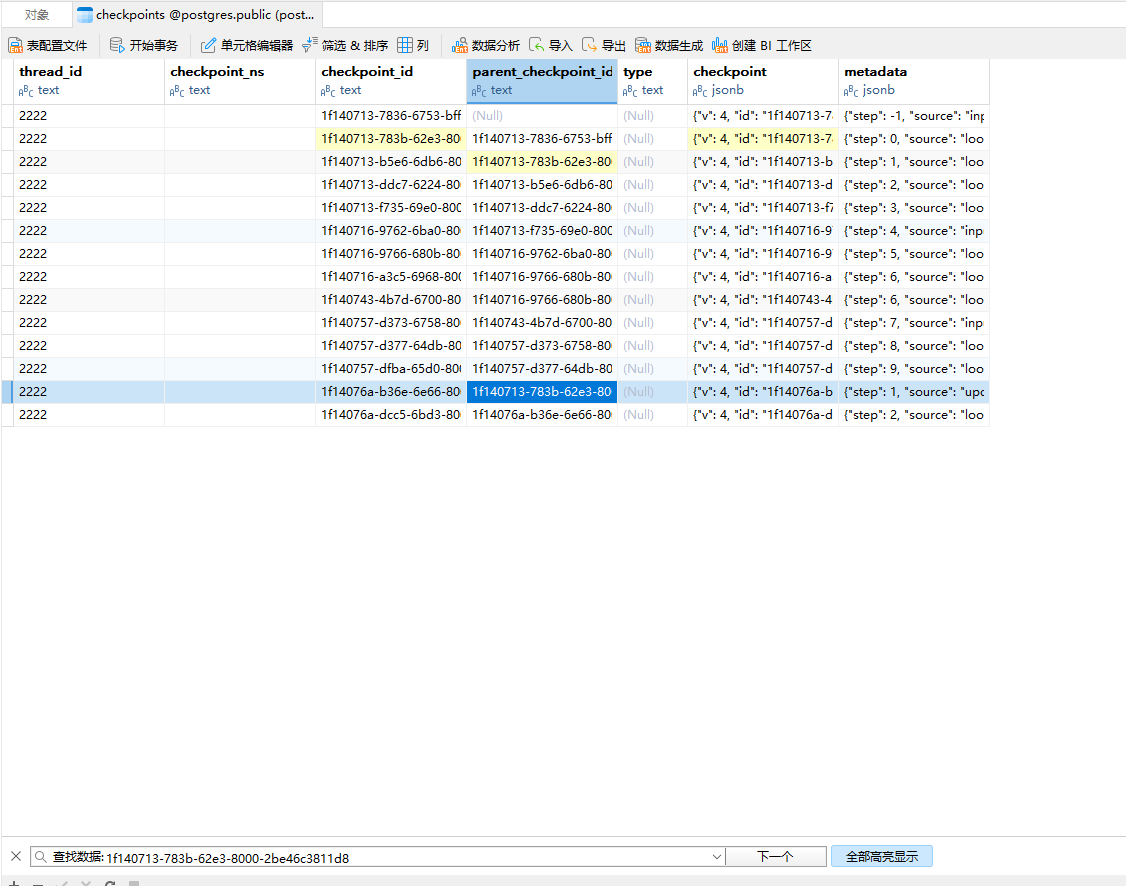
可以看到此时的整个checkpoint的图结构变成这样(为了看着更顺眼我加了一个input初始化节点):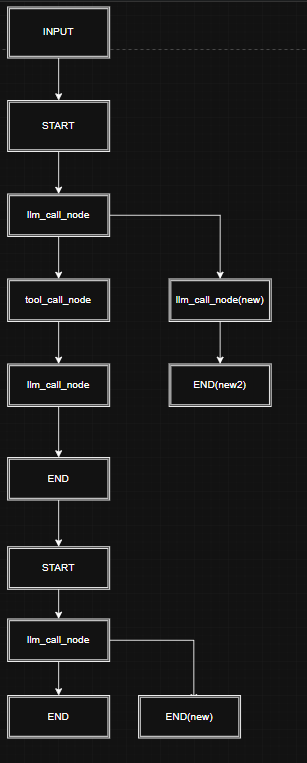
后面如果我们继续问问题,当然是会从new2位置继续向下走。
2.2跨会话持久化
我们平时在使用ai工具时,会发现一旦切换对话也就是开启新会话,ai貌似忘记了我们之前谈过什么了(当然也有例外,比如geimini)。跨会话持久化最简单能够想到的一种方式就是,每个用户有独立的user_id,然后设置一片空间存储过往此用户所有对话记录的总结,然后在每次当前用户开启新对话时,将过往对话记录的总结提取出来,作为初始的SystemMessage喂给ai,这样ai就能有先前对话的记忆了.
LangGraph中实现跨会话持久化的方式也类似上面的说法,我们来认识下:
2.2.1跨会话持久化使用姿势
总结出来的对话数据存到那里,当然是数据库中啦,就和上面checkpoint那里一样,常见的两种方式为内存存储和数据库存储。我们这里介绍的着重点和上文一致。
Store的使用方式
无论是内存定义出来的存储对象还是依附于数据库定义出来的存储对象,使用方式都和下面介绍的一样。
Store 本身是通过 Namespace 区分不同数据,如下所示: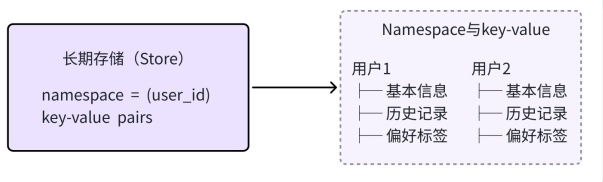
在 LangGraph 中,其提供了一个简单的内存实现 InMemoryStore。想要进行存储,需要:
- 先定义命名空间:为了区分不同用户的记忆,需要一个“命名空间”。这就像在数据库里为每个用户创建一个独立的文件夹。命名空间用于组织记忆,通常按业务逻辑划分。一般用元组来定义命名空间。如:
# 使用元组 - 层次清晰,易于扩展
namespace1 = ("user_123", "preferences", "food") # 用户食物偏好
namespace2 = ("user_123", "preferences", "music") # 用户音乐偏好
namespace3 = ("user_123", "conversations", "2025-05") # 用户某天的对话历史
# 使用字符串 - 扁平且易混淆
namespace4 = "user_123_preferences_food" # 需要解析,容易出错
namespace5 = "user_123_preferences_music"
namespace6 = "user_123_conversations_2024"
- 当在对话中获取到用户的重要信息时,使用
store.put()方法将内存保存到存储中的命名空间。该方法参数包含:namespace:决定这个记忆属于谁以及是什么类型。memory_id:是这个记忆条目的唯一键。memory_content:是记忆的具体内容,一个字典。
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
store.put(namespace, memory_id, memory_content)
一个代码示例如下:
# 1. 导入并创建存储
from langgraph.store.memory import InMemoryStore
import uuid # 用于生成唯一ID
store = InMemoryStore()
# 2. 定义命名空间 (Namespace)
# 命名空间用于组织记忆,通常按业务逻辑划分,例如按用户。
# 这里我们用一个元组 (用户ID, 记忆类型)
user_id = "user_123"
namespace = (user_id, "preferences") # 用户 user_123 的偏好记忆
# 3. 存入一条记忆 (Memory)
# 每条记忆需要一个唯一的 memory_id 和一个 value (通常是字典)
memory_id = str(uuid.uuid4()) # 生成唯一ID,如 "abc-123-def-456"
memory_value = {"favorite_food": "汉堡", "allergy": "花粉"}
store.put(namespace, memory_id, memory_value)
print("记忆已存入!")
# 4. 读取记忆
# 可以搜索某个命名空间下的所有记忆
all_memories = store.search(namespace)
for mem in all_memories:
print(mem.dict()) # 记忆对象转成字典查看
结果如下:
记忆已存入!
{
'namespace': [
'user_123', 'preferences'
],
'key': 'db826e33-c68c-4669-a79a-3579bff02ff1',
'value': {
'favorite_food': '汉堡',
'allergy': '花粉'
},
'created_at': '2025-12-03T08:16:14.134568+00:00',
'updated_at': '2025-12-03T08:16:14.134576+00:00',
'score': None
}
内存跨会话持久化
要想使用 store,我们需要创建一个存储实例,其也有**【内存级存储】与相关【存储库存储】两种方式。例如内存级存储**:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
接着只需像以前一样使用 Checkpoints 和 Store 变量编译图表即可。如下所示:
graph = builder.compile(checkpointer=checkpointer, store=store)
数据库跨会话持久化
Postgres 存储库适用于生产环境或需要状态持久化的场景。由于之前已经启动过 PostgreSQL,这里可以直接连接到数据库,作为 PostgresStore 使用。只需在编译时设置 store 即可。
注意:第一次使用 Postgres store 时需要调用 store.setup()
DB_URI = "postgresql://postgres:bit@192.168.100.233:5432/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpointer,
PostgresStore.from_conn_string(DB_URI) as store,
):
# 第一次使用 Postgres 检查点时需要调用 checkpointer.setup()
checkpointer.setup()
# 第一次使用 Postgres store 时需要调用 store.setup()
store.setup()
# 编译图
agent = agent_builder.compile(checkpointer=checkpointer, store=store)
# ...后续调用...
通过示例认识跨会话持久化的使用姿势
下面是一个示例:
import operator,uuid
from typing import TypedDict, Annotated, Optional
from langchain_core.messages import AnyMessage, ToolMessage, HumanMessage, SystemMessage
from langchain_core.runnables import RunnableConfig
from langgraph.store.base import BaseStore
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.store.postgres import PostgresStore
from pydantic import BaseModel, Field
#1.定义llm调用对象与搜索工具
model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
#绑定工具,否则ai不会去进行工具调用
tool_bind_model = model.bind_tools(tools=[tavilySearchTool,])
#2.定义状态类与用户信息结构
class dialogue_data(TypedDict):
"""记录过往对话数据与简单的对话消耗"""
#此messages中包含三种message:ToolMessage,HumanMessage,AiMessage
messages: Annotated[list[AnyMessage],operator.add]
#简单记录下llm调用次数与工具调用次数
llm_calls: Annotated[int,operator.add]
tool_calls: Annotated[int,operator.add]
class UserInformation(BaseModel):
"""用户个人信息"""
name : Optional[str] = Field(default=None,description="用户给自己取定的名称")
age : Optional[int] = Field(default=None,description="用户的年龄")
interest : Optional[str] = Field(default=None,description="用户个人的兴趣爱好")
#3.定义节点函数,用户id以及一个用户相关的命名空间-固定uuid值便于观察
user_id = "user_id_1"
namespace1 = (user_id,"base_information")
uuid1 = "550e8400-e29b-41d4-a716-446655440000"
namespace2 = (user_id,"interest")
uuid2 = "b2a8d3e1-7f90-4e3c-8a12-6d5b4c3a2e1f"
INIT_FORMAT = (
"请必须参照如下的用户信息与用户进行对话:,"
"用户姓名:{name},"
"用户年龄:{age},"
"用户的个人兴趣爱好:{interest}。"
)
#初始化用户信息-从store中提取用户信息并设置初始SystemMessage
def initialize_user_information_node(state: dialogue_data,config : RunnableConfig,*,store : BaseStore):
#在 LangGraph 的设计哲学中,节点(Node)通常应该是纯粹的处理逻辑。
#input理应来说不应该放在节点内,但是为了好看些,并演示跨会话聊天
#其实也可以用条件边写更加优雅。不过,这仅仅只是一个示例,就先这样写了
user_input = input("请输入你的问题:\n")
#查询用户信息并添加初始SystemMessage
if len(state["messages"]) == 0:
#没有过往对话数据时再决定是否添加
namespace = (config["configurable"]["user_id"],)
result = store.search(namespace) #查询为空返回空列表
system_msg = INIT_FORMAT
user_info = {
"name": "未知",
"age": "未知",
"interest": "未知"
}
if result:
for mem in result:
mem_dict = mem.dict()
if "name" in mem_dict["value"]:
user_info["name"] = mem_dict["value"]["name"]
if "age" in mem_dict["value"]:
user_info["age"] = mem_dict["value"]["age"]
if "interest" in mem_dict["value"]:
user_info["interest"] = mem_dict["value"]["interest"]
#一次性填充所有占位符(使用 ** 字典解包)
system_msg = INIT_FORMAT.format(**user_info)
return {
"messages" : [
SystemMessage(content=system_msg),
HumanMessage(content=user_input),
]
}
#此时说明已经进行了一些对话了,直接插入用户问题即可
return {
"messages" : [HumanMessage(content=user_input)]
}
#提取信息节点
EXTRACT_FORMAT = (
"你是一个信息提取的专家,请你根据上述对话内容提取用户的个人信息,"
"并填充到给定好的输出结构中,如果并没有提取到相关信息返回None即可。"
)
def extract_information_node(state: dialogue_data,config : RunnableConfig,*,store : BaseStore):
print(state["messages"])
#当消息条目数仅为2时不进行信息提取(说明此时用户并未进行对话,消息列表中仅仅只有一条SystemMessage与HumanMessage)
if len(state["messages"]) == 2:
return {}
#将数据提取出来并按照上面定义好的命名空间进行存储-直接把所有的聊天消息塞给llm,除了对话初始的SystemMessage
struct_output_model = model.with_structured_output(UserInformation)
result = struct_output_model.invoke(
[
SystemMessage(content=EXTRACT_FORMAT)
]
+ state["messages"][1:]
)
key_id = uuid.uuid4()
#分两个命名空间插入,验证仅给相同前缀便可查到所有用户相关信息
#基本信息直接覆盖插入数据-当年龄与姓名同时能够提取到再进行数据填入
if (result.name) and (result.age):
info1 = {}
info1["name"] = result.name
info1["age"] = result.age
store.put(
namespace=namespace1,
key=uuid1,
value=info1
)
#兴趣信息原本应该追加传入,此处为了方便就直接覆盖了
info2 = {}
if result.interest:
info2["interest"] = result.interest
store.put(
namespace=namespace2,
key=uuid2,
value=info2
)
return {
"llm_calls" : 1
}
#llm调用节点
def llm_call_node(state: dialogue_data):
#让ai总结先前对话内容并给出答案-同时决定是否需要进行工具调用
ai_message = tool_bind_model.invoke(state["messages"])
#追加对话消息
return {
"messages" : [ai_message],
"llm_calls" : 1
}
#工具调用节点
def tool_call_node(state: dialogue_data):
#获取末尾AiMessage
conclusion_message = state["messages"][-1]
#此时是由条件边判断之后确定需要工具调用时才进来的-简单些直接进行工具调用不再二次判断
return_tool_messages:list[ToolMessage] = []
tool_calls = 0
for tool in conclusion_message.tool_calls:
select_tool = {"tavily_search": tavilySearchTool}[tool["name"].lower()]
tool_message = select_tool.invoke(tool)
return_tool_messages.append(tool_message)
tool_calls += 1
#工具调用完毕
return {
"messages" : return_tool_messages,
"tool_calls" : tool_calls
}
#4.定义 StateGraph 图
llm_dialogue = StateGraph(dialogue_data)
#5.添加节点
llm_dialogue.add_node(llm_call_node)
llm_dialogue.add_node(tool_call_node)
llm_dialogue.add_node(extract_information_node)
llm_dialogue.add_node(initialize_user_information_node)
#6.添加边
llm_dialogue.add_edge(START,"initialize_user_information_node")
llm_dialogue.add_edge("initialize_user_information_node","extract_information_node")
llm_dialogue.add_edge("extract_information_node","llm_call_node")
def judge_tool_call(state: dialogue_data):
conclusion_message = state["messages"][-1]
if conclusion_message.tool_calls:
return "tool_call_node"
return END
llm_dialogue.add_conditional_edges(
"llm_call_node",
judge_tool_call,
["tool_call_node", END],# path_map:可选,将路径映射到节点名称->此处不写生成可视化图时tool_call_node会显示为一个独立节点但不影响功能
)
llm_dialogue.add_edge("tool_call_node","extract_information_node")
#7.编译图
DB_URI = "postgresql://postgres:123456@111.231.81.4:8091/postgres"
with (
PostgresSaver.from_conn_string(DB_URI) as checkpoint,
PostgresStore.from_conn_string(DB_URI) as store
):
#同样第一次使用需要setup
store.setup()
checkpoint.setup()
result_llm_dialogue = llm_dialogue.compile(checkpointer=checkpoint,store=store)
config = {"configurable" : {"thread_id" : "121","user_id" : user_id}}
#这里暂时不自定义消息,在extract_information_node节点让用户手动输入询问消息,模拟平常我们使用的对话模型app
data = dialogue_data(
messages=[],
tool_calls=0,
llm_calls=0
)
result = result_llm_dialogue.invoke(data,config=config)
final_message = result["messages"][-1]
print(f"{'=' * 20}本次调用结束{'=' * 20}")
print(f"结果:{final_message.content}\n")
print(f"llm调用次数为:{result["llm_calls"]}\n")
print(f"工具调用次数为:{result["tool_calls"]}\n\n")
整个流程的图示如下: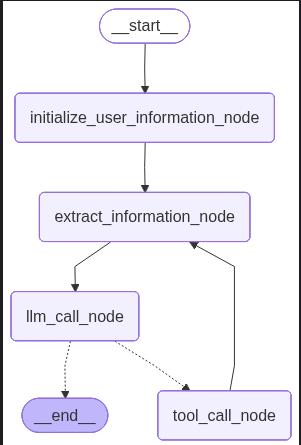
我们先来和ai进行几次对话,问的问题如下:
第一个问题:我叫小明,今年18岁,我喜欢追番剧和听音乐,你是谁?
第二个问题:我们刚才聊了些什么?
此时我们看下存储内容(1.注意因为我们是最开始或调用工具后再进行信息提取,所以需要第二次对话或确保调用工具才会总结第一次对话内容信息2.注意自我介绍时必须把年龄和名字同时说出来才会进行提取,否则ai不提取–这样设计确实有些怪,但是仅仅是示例就不要纠结那么多啦,因为后面有更好的解决办法):
接下来我们更换下线程id,看换了对话记录它是否能记住我们的名字和兴趣爱好(初始线程id为121,更换后的线程id为114514):
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test6.py
请输入你的问题:
我叫什么,我喜欢什么?
[SystemMessage(content='请必须参照如下的用户信息与用户进行对话:,用户姓名:小明,用户年龄:18,用户的个人兴趣爱好:追番剧和听音乐。', additional_kwargs={}, response_metadata={}), HumanMessage(content='我叫什么,我喜欢什么?', additional_kwargs={}, response_metadata={})]
====================本次调用结束====================
结果:你叫小明,喜欢追番剧和听音乐!有什么相关的内容想聊聊吗?
llm调用次数为:1
工具调用次数为:0
进程已结束,退出代码为 0
可以看到他是记得住我们的,也就实现了一个简单的跨会话持久化。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)