LangGraph-持久化能力补充及其余核心能力
LangGraph-持久化能力补充及其余核心能力
一.持久化能力补充部分
1.1删除消息
当我们想要在状态中对messages进行部分消息的删除,以现在已经有的知识可以遍历对应区间然后使用Overwrite进行重写,但是这样太麻烦了。有没有更简便的方式呢?有的有的,LangGraph提供了RemoveMessage接口供我们使用,看下面的一个例子就明白它怎么去使用了,很简单:
from typing import TypedDict, Annotated, Any
from langchain_core.messages import AnyMessage, RemoveMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
#1.定义llm调用对象与搜索工具
model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
class State(TypedDict):
messages : Annotated[list[AnyMessage],add_messages] #若想要使用RemoveMessage对保存的消息进行裁剪,需要设置messages列表为add_messages
def remove_message_node(state : State):
#对话列表中消息数大于等于4条时删除前四条记录
if len(state["messages"]) >= 4:
return {"messages" : [RemoveMessage(id=msg.id) for msg in state["messages"][:4]]}
return {}
def call_node(state : State):
result = model.invoke(state["messages"])
return {"messages" : [result]}
llm_dialogue = StateGraph(State)
llm_dialogue.add_node(remove_message_node)
llm_dialogue.add_node(call_node)
llm_dialogue.add_edge(START,"call_node")
llm_dialogue.add_edge("call_node","remove_message_node")
llm_dialogue.add_edge("remove_message_node",END)
result_llm_dialogue = llm_dialogue.compile()
message = State(
messages=[]
)
while True:
question = input("请输入你的问题:\n")
message["messages"].append(HumanMessage(content=question))
message = result_llm_dialogue.invoke(message)
for msg in message["messages"]:
msg.pretty_print()
print(f"{'=' * 40}")
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\Graph-test7.py
请输入你的问题:
你好喵,我叫小明喵
================================ Human Message =================================
你好喵,我叫小明喵
================================== Ai Message ==================================
你好,小明喵!很高兴认识你喵。有什么我可以帮你的吗喵?
========================================
请输入你的问题:
你是谁
========================================
请输入你的问题:
我叫什么喵?
1.2中断
1.2.1基本使用
像我们上一篇文章的最后一个案例编写时,我们是把用户的输入放到了节点中。上面的例子则是将输入放到了主函数中。其实这样都不够优雅,而LangGraph为我们提供了一种更为便捷的方式–中断。
在工作流中,想要实现暂停与恢复很简单,只需要:
- 通过调用
interrupt()方法中断执行流程,依靠持久化能力,保存当前状态。 - 外部用户通过发送
Command对象,使得工作流恢复执行流程。
交互流程如下图所示: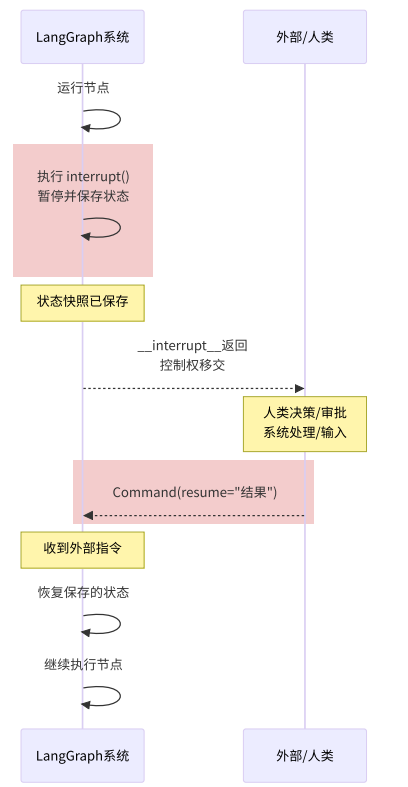
看下面一个例子:
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class State(TypedDict):
input: str
output: str
def hello_node(state: State):
# 主动喊“停!”,并传递提示信息
human = interrupt("暂停,是否继续?") # 第一次运行会停在这里
if human == "yes":
return {"output": "你好,我是你的贴心助手!"}
else:
return {"output": "拜拜"}
builder = StateGraph(State)
builder.add_node(hello_node)
builder.add_edge(START, "hello_node")
# 必须指定 checkpointer,以在每个步骤后保存图状态。
graph = builder.compile(checkpointer=InMemorySaver())
# 必须使用 thread_id 运行 Graph,相当于告诉系统读哪个存档。
config = {"configurable": {"thread_id": "human_1"}}
# 步骤1:启动,触发暂停
first = graph.invoke({"input": "hi"}, config=config)
print(first) # 看到提问: __interrupt__
# 步骤2:恢复,把答案交回去-此时需要传入的是一个Command对象
second = graph.invoke(Command(resume="no"), config=config)
print(second["output"])
结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test8.py
{'input': 'hi', '__interrupt__': [Interrupt(value='暂停,是否继续?', id='309936a276398cebe91ab47d8012fcbe')]}
拜拜
进程已结束,退出代码为 0
需要注意的几个点如下:
- 编译图时:必须指定
checkpointer,以在每个步骤后保存图状态。 - 调用
interrupt()时:表示主动喊停,并传递提示信息。 - 使用
invoke/stream恢复执行,需使用Command(resume=...)语法。resume表示传回 AI 的响应值- 必须使用
thread_id运行 Graph,相当于告诉系统读哪个存档。
因此实现了中断,便是实现了人机交互模式。
1.2.2注意事项
不要捕获interrupt抛出的异常
需要注意的是,当我们调用interrupt时实际上是代码抛出了一个异常,但是这个异常会被LangGraph系统捕获从而触发中断。如果我们在调用interrupt时自己去try-catch了,那么需要注意最好是捕获特定异常而不是捕获所有异常,否则就会导致LangGraph的中断失效。
def node_a(state: State):
# ❌ 错误:在try/except中包装中断
try:
interrupt("What's your name?")
except Exception as e:
print(e)
return state
仅使用interrupt传能序列化的简单数据
复杂值无法进行传递,例如不要传递函数、类实例、数据库连接等。只传递能序列化的简单数据,如字符串、数字、布尔、简单字典/列表。
不要在中断前进行有副作用的代码运行
需要注意的是,当我们使用中断时,它恢复的时候并不是说我从你调用中断的位置重新继续向下运行,而是从调用中断的节点重新运行。如果说我们在中断前进行了数据库存储等有副作用的操作,那么就会导致一系列的问题产生。
def node_a(state: State):
# ❌ 错误:每次恢复都会重复追加相同条目
db.append_to_history(
state["user_id"],
"approval_requested"
)
approved =
interrupt("Approve this change?")
return {"approved": approved}
确保中断的顺序固定
在同一个节点中使用多个 interrupt() 调用时需要注意的顺序和索引匹配规则。LangGraph 使用严格的索引顺序来匹配恢复值:
- 恢复执行从头开始:节点恢复时会从开头重新运行,而不是从中断的精确行继续。
- 索引匹配:LangGraph 为每个执行任务维护一个恢复值列表。遇到
interrupt()时,按顺序从这个列表中取对应的值。 - 顺序必须一致:中断调用的顺序在每次执行中必须完全相同。
这么说可能不好看,我们看下面几个例子就明白了:
def node_a(state: State):
# ✅ 正确:中断调用顺序固定
name = interrupt("What's your name?") # 索引0
age = interrupt("What's your age?") # 索引1
city = interrupt("What's your city?") # 索引2
return {"name": name, "age": age, "city": city}
# 条件性跳过中断
def node_a(state: State):
name = interrupt("What'syour name?") # 索引0
# ❌ 错误:第⼀次可能跳过,恢复时可能不跳过,导致索引错乱
if state.get("needs_age"):
age = interrupt("What'syour age?") # 索引1(有时存在)
city = interrupt("What'syour city?") # 索引1或2(不确定)
# 基于⾮确定性数据的循环中断
def node_a(state: State):
# ❌ 错误:中断数量随动态列表变化
results = []
for item in state.get("dynamic_list", []):
# 列表可能在不同执行中变化
result = interrupt(f"Approve {item}?") #中断数量不确定
results.append(result)
总的来说就是当我们把代码编写好的时候就可以直接能看出来同一节点中的所有中断的调用顺序,此顺序必须唯一。
二.LangGraph其他核心能力
2.1运行时上下文
2.1.1定义与分类
上下文(Context) 是程序运行时可访问的数据和环境信息。在 LangGraph 中,上下文用于传递:
- 用户身份、配置参数
- 数据库连接、API 密钥
- 会话状态、历史记录等
上下文可按两个维度分类:
| 维度 | 类型 | 描述 | 示例 |
|---|---|---|---|
| 可变性 | 静态上下文 | 运行中不变的数据 | 用户ID、数据库连接 |
| 动态上下文 | 运行中会变化的数据 | 对话记录、中间结果 | |
| 生命周期 | 运行时上下文 | 单次运行/线程有效 | 当前请求的临时数据 |
| 跨会话上下文 | 多次会话持久化 | 用户偏好、历史记录 |
因此,在 LangGraph 中,包含三种上下文:
| 类型 | 可变性 | 生命周期 | 访问方式 |
|---|---|---|---|
| 静态运行时上下文 | 静态 | 单次运行/线程 | context 参数传入 |
| 动态运行时上下文 | 动态 | 单次运行 | 图状态对象 |
| 动态跨会话上下文 | 动态 | 跨会话 | 存储(Store) |
关于我们之前学习过的 checkpoints 和 store,则分别代表动态运行时上下文和动态跨会话上下文。接下来一起来看静态运行时上下文的使用方式。
2.1.2在LangGraph中定义静态运行时上下文
运行图时传入上下文
我们来看如下一个示例:
⾸先需要定义⼀个上下文的数据结构(通常用 dataclass 或 TypedDict )。这里为了和状态定义那里做区分,我们使用dataclass进行定义(用法和TypedDict差不多,不过dataclass是一个类装饰器):
from dataclasses import dataclass
@dataclass
class Context:
user_id : str
user_mother_tongue : str = "ch" #默认用户母语为中文
然后就是使用静态运行时上下文,我们来看如下一个完整例子:
from dataclasses import dataclass
from typing import TypedDict, Annotated
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import add_messages, StateGraph
from langgraph.runtime import Runtime
from langgraph.types import interrupt, Command
@dataclass
class Context:
user_id : str
user_mother_tongue : str = "ch" #默认用户母语为中文
model = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://api.kourichat.com/v1"
)
class State(TypedDict):
messages : Annotated[list[AnyMessage],add_messages]
def init_node(state : State,runtime : Runtime[Context]):
systemMessage = []
if runtime.context.user_mother_tongue == "en":
systemMessage.append(SystemMessage(content="请以英文形式为用户解答问题"))
else:
systemMessage.append(SystemMessage(content="请以中文形式为用户解答问题"))
return {
"messages" : systemMessage
}
def llm_call_node(state : State):
user_msg = interrupt(value="请输入你的问题")
msgs = state["messages"] + [HumanMessage(content=user_msg)]
result = model.invoke(msgs)
return {
"messages" : [HumanMessage(content=user_msg),result]
}
graph = StateGraph(State,context_schema=Context)
graph.add_node(init_node)
graph.add_node(llm_call_node)
graph.add_edge(START,"init_node")
graph.add_edge("init_node","llm_call_node")
graph.add_edge("llm_call_node",END)
result_graph = graph.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "human_1"}}
result = result_graph.invoke(
{"messages" : []},
context=Context(user_id="user_id_1",user_mother_tongue="en"),
config=config
)
print(result)
user_input = input("请输入你的问题")
result = result_graph.invoke(Command(resume=user_input),config=config)#graph指定context_schema后可以以传字典的形式传上下文
result["messages"][-1].pretty_print()
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test9.py
{'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={}, id='1a726748-ed01-418a-8a93-0af21fe2b7fb')], '__interrupt__': [Interrupt(value='请输入你的问题', id='c85ff251b9a421d83538a31b27b8fa3c')]}
请输入你的问题 你是谁啊
================================== Ai Message ==================================
I am an AI language model created by OpenAI, designed to assist with providing information and answering questions. How can I assist you today?
进程已结束,退出代码为 0
运行工具时传入上下文
工具可以通过 ToolRuntime 参数访问运行时信息。这个参数为工具提供包括:
- State:图状态数据
- Context:静态上下文
- Store:持久化存储等
使用 ToolRuntime 时,只需在工具签名中添加 runtime: ToolRuntime,它会自动注入。调用时,无需手动传输。
定义一个带有运行时信息的工具如下所示:
from langchain.tools import tool, ToolRuntime
@tool
def get_user_info(runtime: ToolRuntime) -> str:
"""获取当前用户的信息"""
user_id = runtime.context.user_id # 访问上下文
user_state = runtime.state["user_name"] # 访问状态
return f"User {user_id}, state: {user_state}"
我们来看如下一个完整示例:
构建一个支持搜索的 AI 系统,假设调用搜索 API 需要用户数据作为参数,则需要向工具中传入相关信息。关键步骤如下:
- 定义状态、上下文结构
- 定义工具节点(
ToolNode)、定义 LLM 节点 - 构建并编译图,需加入状态和上下文参数
- 执行并验证结果
from dataclasses import dataclass
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage
from langchain.tools import tool, ToolRuntime
from langchain.messages import AnyMessage
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
user_name: str = ""
@dataclass
class Context:
user_id: str
@tool
def search(runtime: ToolRuntime[Context]) -> str:
"""调用搜索工具"""
user_id = runtime.context.user_id # 访问上下文
user_name = runtime.state["user_name"] # 访问状态
print(f"日志记录:user_id: {user_id}, user_name: {user_name} 调用查询工具")
return f"查询天气:晴天,15-20度" # 模拟调用
# 绑定工具
model_with_tools = init_chat_model("gpt-4o-mini", temperature=0).bind_tools([search])
def llm_call(state: dict):
"""LLM决定是否调用工具"""
return {
"messages": [
model_with_tools.invoke(
[SystemMessage(content="你是一个乐于助人的助手,支持调用工具进行搜索。")]
+ state["messages"]
)
]
}
# 定义并编译图
builder = StateGraph(MessagesState, context_schema=Context)
builder.add_node("llm_call", llm_call)
builder.add_node("tool_node", ToolNode([search]))
builder.add_edge(START, "llm_call")
builder.add_conditional_edges(
"llm_call",
tools_condition,
{
"tools": "tool_node", # 将条件输出转换为图中的节点
"__end__": END,
},
)
builder.add_edge("tool_node", "llm_call")
graph = builder.compile()
for chunk in graph.stream(
{
"messages": [HumanMessage(content="今天西安的天气如何?")],
"user_name": "小明"
},
context={"user_id": "123"}
):
for node, update in chunk.items():
update["messages"][-1].pretty_print()
# 打印结果如下:
# ================================== Ai Message ==================================
# Tool Calls:
# search (call_YU9O02F9JBdiz3J7CMmUYLNE)
# Call ID: call_YU9O02F9JBdiz3J7CMmUYLNE
# Args:
# 日志记录:user_id: 123, user_name: 小明 调用查询工具
# ================================= Tool Message ==================================
# Name: search
#
# 查询天气:晴天,15-20度
# ================================== Ai Message ==================================
#
# 今天西安的天气是晴天,气温在15到20度之间
2.2流
在LangChain中,model执行之后生成的消息我们可以设置其为流式输出,当然LangGraph这里也可以让我们经过某个节点之后流式输出节点中的相关内容,比如状态信息等。
2.2.1五种流模式
LangGraph 支持以下五种流模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
values |
流式输出完整状态 | 需要知道每一步的完整状态 |
updates |
流式输出状态变化 | 关注每一步更新了哪些字段 |
messages |
流式输出 LLM 生成的 token | 实时展示 LLM 生成内容 |
custom |
流式输出自定义数据 | 自定义进度条、日志等 |
debug |
输出所有调试信息 | 开发调试阶段 |
values模式
这是LangGraph的最基本流输出模式,我们还是以上面2.1.2部分的运行图时传入上下文的代码为基础进行修改,涉及到的修改内容如下:
for chunk in result_graph.stream(
{"messages" : []},
context=Context(user_id="user_id_1",user_mother_tongue="en"),#graph指定context_schema后可以以传字典的形式传上下文
config=config,
stream_mode="values"
):
print(chunk)
user_input = input("请输入你的问题\n")
for chunk in result_graph.stream(Command(resume=user_input),config=config):
print(chunk)
我们来看输出结果:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test9.py
{'messages': []}
{'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={}, id='e5740d64-7f0b-47c9-b26e-9a8201b6d055')]}
{'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={}, id='e5740d64-7f0b-47c9-b26e-9a8201b6d055')], '__interrupt__': (Interrupt(value='请输入你的问题', id='ecd203ddfcfb6e1cc5d2674e8f922aa9'),)}
请输入你的问题你是谁啊
{'llm_call_node': {'messages': [HumanMessage(content='你是谁啊', additional_kwargs={}, response_metadata={}, id='d613d87a-1904-4f5c-bc95-c24f550e2c73'), AIMessage(content='I am an AI language model created by OpenAI, designed to assist with a wide range of ...
进程已结束,退出代码为 0
可以看到他是当前节点结束或中断时把状态或中断信息全部打印出来。很容易理解这里不再解释
updates模式
修改后的代码如下:
for chunk in result_graph.stream(
{"messages" : []},
context=Context(user_id="user_id_1",user_mother_tongue="en"),#graph指定context_schema后可以以传字典的形式传上下文
config=config,
stream_mode="updates"
):
print(chunk)
user_input = input("请输入你的问题\n")
for chunk in result_graph.stream(Command(resume=user_input),config=config,stream_mode="updates"):
print(chunk)
可以看到打印结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test9.py
{'init_node': {'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={}, id='e8b6e825-86e3-4a51-9213-d3008d645910')]}}
{'__interrupt__': (Interrupt(value='请输入你的问题', id='bbb0363ea41298dbe94ae63384d051cf'),)}
请输入你的问题
你是谁啊
{'llm_call_node': {'messages': [HumanMessage(content='你是谁啊', additional_kwargs={}, response_metadata={}, id='2675b20a-e5c7-4db2-8cd7-4a86c449af36'), AIMessage(content='I ...
进程已结束,退出代码为 0
对比values模式,我们发现updates输出的全是经过每个中断或节点后更新的值,前一个节点或中断结束时的值将不再进行输出。
custom自定义模式及与其他模式同时使用
有的时候我们觉得它自己给的这些打印太冗余了,那么我们边可以自定义输出:
LangGraph 不仅支持输出状态类的数据,还支持从节点或工具中输出用户自定义的数据。步骤如下:
- 使用
get_stream_writer()访问流编写器并发出自定义数据。 - 调用
.stream()或.astream()时设置stream_mode="custom"以获取流中的自定义数据。还可以组合多种模式(如["updates", "custom"]),但至少必须有一个是"custom"。
基于updates部分的代码,我们再进行如下修改(比如我们想在init_node处看看用户的id与母语情况):
def init_node(state : State,runtime : Runtime[Context]):
systemMessage = []
if runtime.context.user_mother_tongue == "en":
systemMessage.append(SystemMessage(content="请以英文形式为用户解答问题"))
else:
systemMessage.append(SystemMessage(content="请以中文形式为用户解答问题"))
writer = get_stream_writer()
writer({
"user_id" : runtime.context.user_id,
"user_mother_tongue" : runtime.context.user_mother_tongue
})
return {
"messages" : systemMessage
}
for chunk in result_graph.stream(
{"messages" : []},
context=Context(user_id="user_id_1",user_mother_tongue="en"),#graph指定context_schema后可以以传字典的形式传上下文
config=config,
stream_mode=["updates","custom"]
):
print(chunk)
输出结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test9.py
('custom', {'user_id': 'user_id_1', 'user_mother_tongue': 'en'})
('updates', {'init_node': {'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={})]}})
('updates', {'__interrupt__': (Interrupt(value='请输入你的问题', id='1c877f508c965fcfb8eed41789a32e7e'),)})
请输入你的问题
你是谁啊
{'llm_call_node': {'messages': [HumanMessage(content='你是谁啊', additional_kwargs={}, response_metadata={}, id='6f2b6cd7-9438-46c0-aa34-5721f83d85b1'), AIMessage(content='I am an AI language model created by OpenAI, designed to assist with a wide range of ...
进程已结束,退出代码为 0
可以看到,组合模式下输出的结果是一个元组,第一个位置表明此为什么流模式输出的信息。
messages模式
我们先来看此模式的输出信息结构:
('messages',
(
# 消息内容
AIMessageChunk(
content='',
additional_kwargs={},
response_metadata={'model_provider': 'openai'},
id='lc_run--019dd316-c529-7fb2-a98b-170f5e348b68',
tool_calls=[],
invalid_tool_calls=[],
tool_call_chunks=[]
),
# 元数据字典
{
'thread_id': 'human_1',
'ls_integration': 'langgraph',
'langgraph_step': 2,
'langgraph_node': 'llm_call_node',
'langgraph_triggers': ('branch:to:llm_call_node',),
'langgraph_path': ('__pregel_pull', 'llm_call_node'),
'langgraph_checkpoint_ns': 'llm_call_node:91d7d02c-e85b-2e04-5490-32ca95053bc0',
'checkpoint_ns': 'llm_call_node:91d7d02c-e85b-2e04-5490-32ca95053bc0',
'ls_provider': 'openai',
'ls_model_name': 'gpt-4o-mini',
'ls_model_type': 'chat',
'ls_temperature': None
}
))
此模式比较特殊,它仅会输出整个图中调用llm的节点的llm的输出信息并流式输出,这里我们再基于custom部分的代码做如下修改:
#因为有llm调用在中断之后,所以对此部分代码修改即可
user_input = input("请输入你的问题\n")
for mode_name,metadata in result_graph.stream(Command(resume=user_input),config=config,stream_mode=["messages","custom"]):
#模式过滤-仅输出llm的信息-注意最后的一个chunk是HumanMessage,所以需要判断下
if mode_name == "messages" and isinstance(metadata[0],AIMessage):
print(metadata[0].content,end="",flush=True)
输出结果如下:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test9.py
('custom', {'user_id': 'user_id_1', 'user_mother_tongue': 'en'})
('updates', {'init_node': {'messages': [SystemMessage(content='请以英文形式为用户解答问题', additional_kwargs={}, response_metadata={})]}})
('updates', {'__interrupt__': (Interrupt(value='请输入你的问题', id='85dcb9e5e99304a794d574b6022162da'),)})
请输入你的问题
你是谁啊
I am an AI language model created by OpenAI. I'm here to help you with information, answer questions, and assist you in various topics. How can I help you today?
进程已结束,退出代码为 0
至于debug模式则是更为详细的输出,有兴趣的读者可以自行进行了解下。
2.3子图
2.3.1基本使用
像我们之前做的所有的示例其实都仅仅只有一张主图,那么在主图中调用其他图,这个被调用的其他图就是子图。我们来看下两种子图的调用方式:
在主图节点中调用子图
这个调用方式很简单就能够想到,那就是先编译好一个图,然后在主图中调用其invoke方法就可以实现,来看这样一个例子:
from typing_extensions import TypedDict
from langgraph.graph.state import StateGraph, START
# 1. 定义子图
class SubState(TypedDict):
# 注意,这些键都不与父图状态共享
sub_1: str
sub_2: str
def sub_node_1(state: SubState):
return {"sub_1": "sub_1"}
def sub_node_2(state: SubState):
return {"sub_2": state["sub_2"] + state["sub_1"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
def node_2(state: ParentState):
# 将状态转换为子图状态
response = subgraph.invoke({"sub_2": state["parent"]})
# 将响应转换回父状态
return {"parent": response["sub_2"]}
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()
# 要在流式输出中包含子图的输出,可以在父图的 .stream() 方法中设置 subgraphs=True。
# subgraphs 默认为 False
for chunk in graph.stream({"parent": "parent"}, subgraphs=True):
print(chunk)
输出结果为:
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test10.py
((), {'node_1': {'parent': 'hi! parent'}})
(('node_2:70366965-6cbf-d97a-9b62-a1e2f0b0bffc',), {'sub_node_1': {'sub_1': 'sub_1'}})
(('node_2:70366965-6cbf-d97a-9b62-a1e2f0b0bffc',), {'sub_node_2': {'sub_2': 'hi! parentsub_1'}})
((), {'node_2': {'parent': 'hi! parentsub_1'}})
进程已结束,退出代码为 0
子图作为主图的一个节点被调用
顾名思义,就是在主图进行编译之前将子图作为一个子节点加入到主图中,让主图像调用节点一样调用子图,来看下面一个简单的例子:
from typing_extensions import TypedDict
from langgraph.graph.state import StateGraph, START
# 1. 定义子图
class SubState(TypedDict):
parent: str # 共享父图状态
sub: str # Sub私有
def sub_node_1(state: SubState):
return {"sub": "sub"}
def sub_node_2(state: SubState):
return {"parent": state["parent"] + state["sub"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", subgraph) # 直接将子图作为节点
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()
for chunk in graph.stream({"parent": "parent"}):
print(chunk)
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test10.py
{'node_1': {'parent': 'hi! parent'}}
{'node_2': {'parent': 'hi! parentsub'}}
进程已结束,退出代码为 0
为子图添加持久化功能
如果图包含子图,则只需在编译父图时提供 checkpointer。LangGraph 会自动将 checkpointer 传播到子图。
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from typing import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
return {"foo": state["foo"] + "bar"}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph = subgraph_builder.compile()
# 主图
builder = StateGraph(State)
builder.add_node("node_1", subgraph) # 将子图作为节点
builder.add_edge(START, "node_1")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer) # 仅在父图编译时传入 checkpointer
2.3.2子图中使用中断
子图中当然也可以使用中断,但是对于基本使用部分的前两种子图调用方式,中断后的恢复各不相同,我们来看当子图作为主图的一个节点时被调用的情况:
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from typing_extensions import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
print("sub_node_1")
return {}
def subgraph_node_2(state: State):
print("sub_node_2")
value = interrupt("输入值:")
return {"foo": state["foo"] + value}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 主图
builder = StateGraph(State)
builder.add_node("node_1", subgraph)
builder.add_edge(START, "node_1")
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"foo": ""}, config)
print(graph.invoke(Command(resume="bar"), config))
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test10.py
sub_node_1
sub_node_2
sub_node_2
{'foo': 'bar'}
进程已结束,退出代码为 0
此时和我们之前认识的中断恢复流程基本没差。
但是当子图是被主图中的一个节点调用时就不一样了,我们看下面一个例子:
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from typing_extensions import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
print("sub_node_1")
return {}
def subgraph_node_2(state: State):
print("sub_node_2")
value = interrupt("输入值:")
return {"foo": state["foo"] + value}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 主图
def node_1(state: State):
print("node_1")
response = subgraph.invoke({"foo": state["foo"]})
return {"foo": response["foo"]}
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_edge(START, "node_1")
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"foo": ""}, config)
print(graph.invoke(Command(resume="bar"), config))
C:\code\LangChain\.venv\Scripts\python.exe C:\code\LangChain\LangGraph\Graph-test10.py
node_1
sub_node_1
sub_node_2
node_1
sub_node_2
{'foo': 'bar'}
进程已结束,退出代码为 0
可以看到此时中断恢复时是先到调用子图的目标节点起始位置开始往下走,然后进入子图到子图调用中断的对应节点开始继续向下走。和子图作为一个节点时恢复的情况有所不同。
至此,LangGraph部分的基本内容我们已经学习完毕,下文我们开始做一个比较综合的大案例。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)