强化学习与目标检测王炸组合,IEEE Trans顶刊发表!
小伙伴们好,我是小嬛。专注于人工智能、计算机视觉、AI大模型领域相关分享研究。【目标检测、图像分类、图像分割、目标跟踪等项目都可做,相关领域论文辅导也可以找我;需要的可联系(备注来意)】
-------正文开始--------
今天和大家分享一个发文黄金组合:强化学习+目标检测!
这组合的核心优势明显,不仅能解决传统检测的低效、泛化弱等痛点,还能适配小样本、复杂场景等难点问题。而且最关键的是,这方向创新空间足、接收度高,CCF/SCI都好发,也很适合冲顶会!难怪这两年它的热度一路猛涨。
不过卡点也有:RL训练慢、奖励难设计、检测器融合容易不稳...所以最好找到靠谱的切入点和已验证的组合套路再下手,比如轻量融合、奖励函数改进、小样本适配这三点,容易落地、好出对比优势。当然,光 有个方向肯定是不行的,建议多关注顶会最新论文和工业界挑战,从中找到自己感兴趣也有优势的切入点。这里我为了帮大家节省查找的时间,我给大家提供更多的发文思路和方向,大家扫码获取!!!
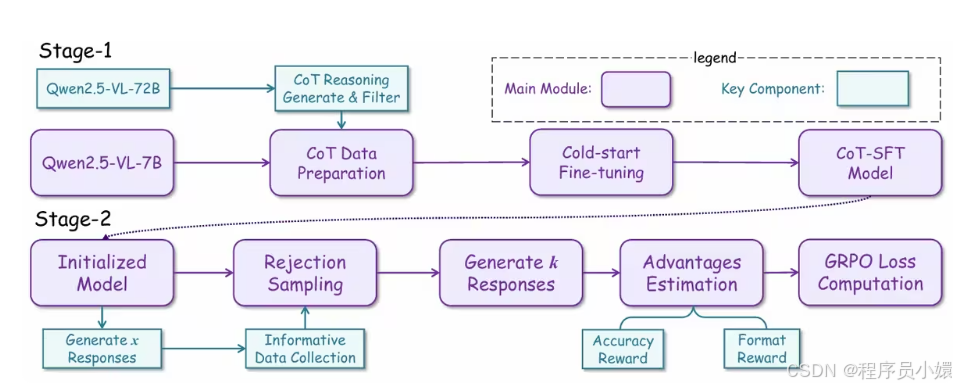
【ICASSP 2026】Improving the reasoning of multi-image grounding in mllms via reinforcement learning
研究方法:论文以Qwen2.5‑VL‑7B为基础模型,先通过大模型生成高质量思维链数据并做 LoRA 监督微调完成冷启动,再结合拒绝采样与基于GRPO 的规则化强化学习,用精度与格式双奖励优化多图定位推理路径,显著提升多图目标检测与跨图推理能力。
创新点:
-
提出两阶段训练框架,先通过Qwen2.5‑VL‑72B构建高质量思维链数据,结合LoRA做冷启动监督微调,让模型具备基础多图像推理能力。
-
采用基于GRPO的规则化强化学习,搭配精度奖励与格式奖励双激励机制,引导模型学习正确推理路径,提升跨图像定位与泛化能力。
-
在强化学习前加入拒绝采样策略,过滤全对或全错的无信息样本,保证奖励方差有效,显著提升RL训练效率与最终定位精度。
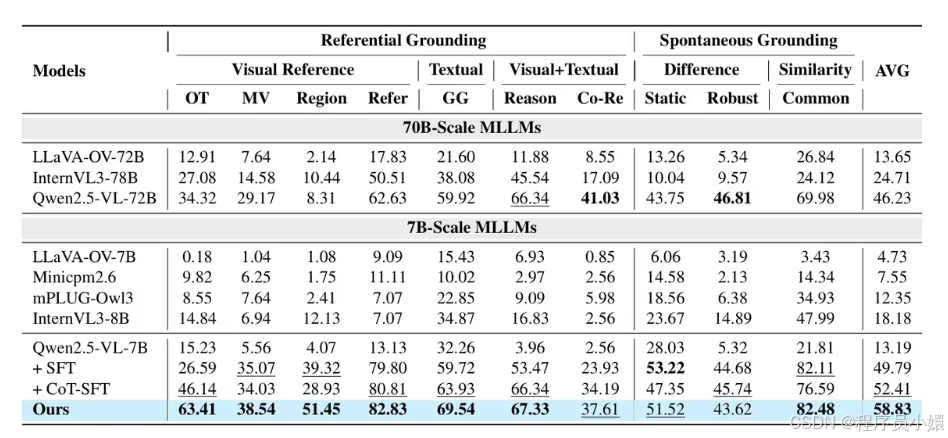
研究价值:论文提出冷启动思维链监督微调 + 规则化强化学习+拒绝采样的两阶段训练方案,有效解决多模态大模型在多图像定位中跨图推理弱、泛化差的问题,在多类权威基准上实现显著性能提升,为真实场景下的多图视觉推理与定位提供了高效可行的技术路径。
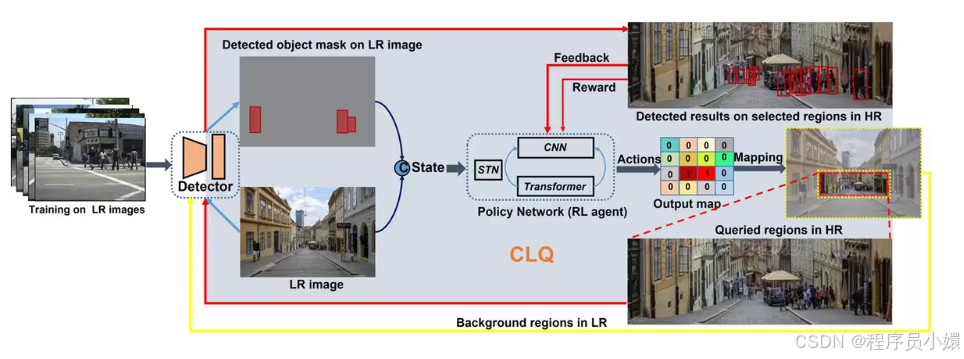
【IEEE TCSVT】Enhancing Representation Learning With Spatial Transformation and Early Convolution for Reinforcement Learning-Based Small Object Detection
研究方法:论文提出一种结合强化学习的小目标检测两阶段方法:先由 RL 智能体在低分辨率图像上完成小目标粗定位查询,再对候选区域用高分辨率检测、背景区域用低分辨率检测,同时搭配空间变换网络与 CNN-Transformer 策略网络,在提升小目标检测精度的同时大幅降低计算开销。
创新点:
-
提出强化学习驱动的粗到精小目标检测框架,在低分辨率图上并行完成小目标区域粗定位,仅对候选区域高分辨率检测,降低计算量。
-
设计融合空间变换网络、早期卷积与Transformer的策略网络,强化状态表征与特征提取,让RL智能体更精准定位小目标区域。
-
采用单步多动作强化学习机制与兼顾检测精度、计算代价的奖励函数,相比传统序列查询方式更高效稳定,且跨域泛化能力更强。
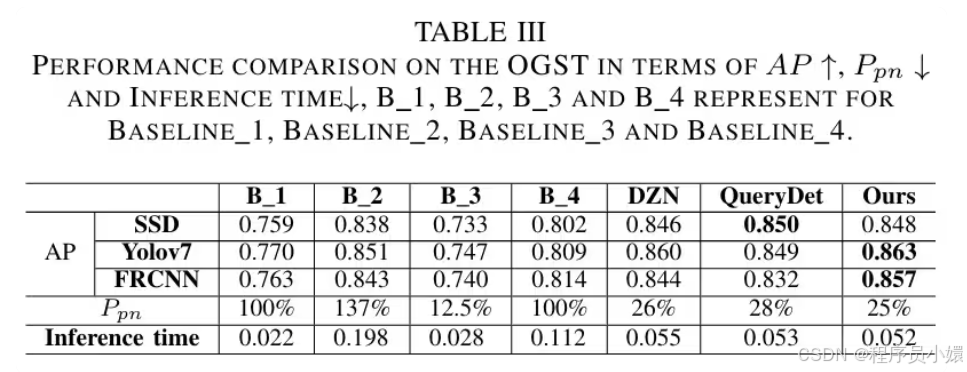
研究价值:论文提出的强化学习 + 粗到精检测方案,显著提升小目标检测精度并大幅降低计算开销,在行人、无人机航拍、遥感等多场景数据集上超越现有方法,为高效、轻量化的小目标检测提供了可落地的通用技术路径。
感谢各位观众的观看和支持,祝大家的论文早日accept!!
希望论文一路绿灯的朋友可以找我,我有团队,有资源,有背景,一条龙服务~~~~

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)