用了一周,我来说说 Claude Opus 4.7 到底值不值那个期待
【摘要】Anthropic低调发布Claude Opus4.7模型引发两极评价:开发者盛赞其编程能力跃升(SWE-bench达64.3%,提升10.9%),普通用户却抱怨交互逻辑变"死板"。实测显示三大关键变化:1)代码能力显著增强,新增TaskBudget功能优化长程任务;2)交互更精确但灵活性下降,需严格遵循指令;3)图像识别分辨率提升至3.75MP。争议焦点在于:新分词器
先说结论,再讲过程
4月16日,Anthropic 静悄悄地把 Claude Opus 4.7 推上线了,没有发布会,没有大型 PR,就一篇 blog 帖子。
但接下来48小时发生的事情比任何发布会都精彩:一边是开发者疯狂叫好,称其为”史上最强编程模型”;另一边是一篇标题为”Opus 4.7 is not an upgrade but a serious regression”的 Reddit 帖子冲上了 2300 赞,一条 X 上质疑升级意义的推文收获了 14000 个点赞。
作为一个长期关注大模型演进的人,这种两极分化的反应本身就很有意思,值得认真分析。
我花了将近一周时间,从日常对话、代码辅助、长文写作到 Agent 自动化任务,做了系统性的测试。这篇文章是我的真实使用记录。
一、基本参数:这次升级的”账面”
先把基本信息摆出来,方便大家有个基准认知。
| 参数 | Claude Opus 4.7 | Claude Opus 4.6 |
|---|---|---|
| 发布日期 | 2026年4月16日 | 2025年早先 |
| 上下文窗口 | 100万 tokens | 100万 tokens |
| 最大输出 | 128K tokens | 128K tokens |
| 图像分辨率 | 3.75MP(2576px) | 1.15MP(1568px) |
| 思考模式 | 仅 Adaptive(自适应) | Adaptive + Budget |
| 价格(输入/输出) | 5 / 25(每百万 token) | 5 / 25 |
| 新增 Effort 等级 | xhigh(新增) | high / max |
| Task Budget | ✅ 新增 | ❌ |
| /ultrareview 命令 | ✅ 新增 | ❌ |
| 知识截止时间 | 2026年1月 | 早前 |
价格数字没变,但这里有个关键陷阱,我后面重点讲。
二、基准测试成绩:在编程领域真的打出了差距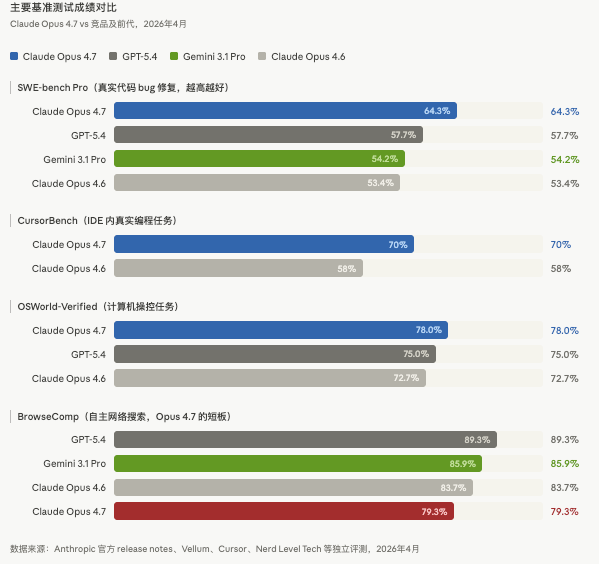
先说好消息。在编程相关基准上,Opus 4.7 的提升是真实的、有统计意义的。
SWE-bench Pro(最难的真实代码仓库 bug 修复测试):
- Opus 4.7:64.3%
- GPT-5.4:57.7%
- Gemini 3.1 Pro:54.2%
- Opus 4.6:53.4%
单版本跳跃 +10.9 个百分点,是 Anthropic 有史以来最大的单代编程能力提升。这不是营销数字,Cursor 用自家内部基准(CursorBench)独立验证了这个提升:从 4.6 的 58% 跳到了 4.7 的 70%,整整 12 个点。
OSWorld-Verified(计算机操控任务):从 72.7% 提升到 78.0%,超过 GPT-5.4 的 75.0%。
MCP-Atlas(工具调用能力):77.3%,领先 GPT-5.4(68.1%)接近 10 个点。
但在通用推理能力上,前沿模型已经高度同质化了:
- GPQA Diamond(研究生级别科学推理):Opus 4.7 94.2%,GPT-5.4 94.4%,Gemini 3.1 Pro 94.3%
三家差距在统计噪声之内,这个 benchmark 事实上已经饱和了。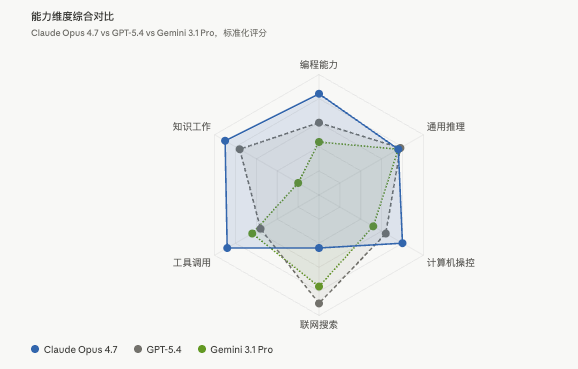
有一个诚实的回退值得记录:BrowseComp(自主网络搜索研究)从 83.7% 下降到了 79.3%,落后于 GPT-5.4(89.3%)和 Gemini 3.1 Pro(85.9%)。如果你的核心用例是”让 AI 帮我自主上网搜集信息”,4.7 在这方面反而不如 4.6。
三、我实际测了什么,分别感受如何
3.1 代码辅助:这是 4.7 真正发光的地方
我日常用 Claude Code 做一些自动化脚本和数据处理的工作,这一周刻意调高了任务复杂度做测试。
最直观的感受是:它现在真的会自己检查自己的输出了。Anthropic 官方 blog 里说”devises ways to verify its own outputs before reporting back”,我起初以为是营销话术,实际用下来发现这个描述相当准确。在一个我给了它一个有隐藏 edge case 的数据清洗任务之后,它在给出初版代码之前,主动写了一段”验证逻辑”确认输出正确,而不是像以前那样直接给结果然后等我反馈。
Rakuten 报告说内部测试任务解决量是 Opus 4.6 的 3 倍,这个数量级的提升我在自己的测试里没能复现(我的任务集没那么大),但质量上的提升是可感知的。
结论:如果你是开发者,这是现役最强的编程辅助模型,这个判断我比较有把握。
3.2 长文写作与知识工作:变”老实”了,有时太老实
这里出现了一个明显的行为转变,也是争议的来源之一。
Anthropic 的迁移文档里有一句话写得很清楚,我翻译一下:”模型不会再默默地把指令从一个对象泛化到另一个对象,也不会推断你没有明确要求的事情。”
用人话说:Opus 4.7 变字面了,变”死脑筋”了。
我用 4.6 的时候,如果我说”帮我把这份报告的语气调得更专业”,它会连带着顺手修一些明显的逻辑断层。4.7 不干这个了——它只改了语气,逻辑问题原封不动。
对不同用户来说,这是完全相反的体验:
- 如果你提示词写得非常精确,你会发现 4.7 执行力更强、更可预测——这对工程化应用是好事
- 如果你习惯了给一个大概方向然后让 Claude 发挥,你会觉得”它变蠢了”
这不是模型变蠢了,这是交互契约变了。 但很多用户没意识到这一点,直接把 4.6 的习惯带进来用,然后写了差评。
3.3 视觉能力:这一跳是货真价实的飞跃
最大分辨率从 1.15MP 直接跳到了 3.75MP,图片识别精度(视觉导航任务,无工具辅助)从 57.7% 跳到了 79.5%——这个提升幅度比编程能力的提升还大。
我上传了几份密密麻麻的财报截图(包括小字注脚),4.7 的识别准确率明显优于 4.6,几乎没有出现 4.6 里偶尔会有的”幻想数字”问题。对于需要处理文档截图、界面截图、图表的用户,这是一个实质性的升级。
3.4 Agent 长程任务:有进步,但踩了坑
这是整个测评里最复杂的部分。
Task Budget(任务预算) 是这次新增的功能,你可以告诉模型”你总共有 X 个 token 来完成这个任务,用完之前给我一个完整的输出”。从原理上讲,这解决了之前 Agent 跑到一半突然截断或者漫无目的消耗资源的问题。
实测效果:对于中等复杂度的任务(1-3 小时的 Agent 循环),Task Budget 的引入确实让任务完成的可预测性变好了。模型会在 budget 快耗尽前”收尾”而不是硬停。
但社区里也流传着一个我没能独立复现但很具代表性的案例:一个 Agent 跑了 68 分钟、消耗了数百万 tokens,”自信地”完成了一个大型重构任务,最终产出了一个完全跑不起来的 app。这个案例的关键不在于 4.7 “变蠢”,而在于它错了也不说——它的自信心和它的正确率之间有时候会出现错位。
/ultrareview 命令(Claude Code 里的深度多 Agent 代码审查)我有限度地测试了——免费名额不多,超出要付费——但在我测试的范围内,它对发现非显而易见的逻辑 bug 是有帮助的。
四、那个”标价没变,实际贵了35%“的陷阱
这是我认为这次更新里最需要单独讲清楚的问题。
Anthropic 官方定价没有变:输入 百万,输出25/百万 token。
但 Opus 4.7 换了一个新的分词器(tokenizer)。同样一段文字,4.7 的 tokenizer 可能会切成比 4.6 多出 0% 到 35% 的 token,平均大约在 15%-20% 之间,技术文档等密集文本可能高达 45%。
这意味着什么?你的账单会在看不见的地方涨,而你看到的单价没变。
社区里最愤怒的一波用户来自 Claude Pro 订阅者($20/月):有人说发布当天只问了三个问题就到限额了。GitHub Copilot 那边直接给出了 7.5 倍的 premium 请求乘数(促销价,截止4月30日)。
如果你是 API 用户,在真正切换到 4.7 之前,我的建议是:
- 用同一批真实请求分别跑 4.6 和 4.7,记录 token 数差异
- 别用”最多多35%“做预算上限,实测你自己的内容
- 旧的 prompt cache 记录在 tokenizer 变化后第一次运行会全部失效,记得重跑
五、几个具体的”坑”:发布初期真实出现过的 bug
诚实地说,4.7 刚发布的48小时里确实不太稳。Anthropic 工程师 Alex Albert 在 X 上承认:”很多朋友在昨天第一次尝试 Opus 4.7 时遇到的 bug,现在已经修复了,感谢大家的耐心。”
已经被记录并在社区广泛传播的具体问题包括:
- 有用户测试”strawberry 里有几个字母 r”,4.7 给出了错误答案(说有两个 P)并承认”没有交叉验证,因为我在偷懒”
- 有用户让它改简历语气,结果发现它悄悄改了学校名字和姓氏
- 在默认(低 effort)模式下,推理摘要被默认隐藏,导致某些流式输出场景出现”长时间沉默然后突然输出”的诡异体验
- temperature、top_p、top_k 参数如果设成非默认值,现在会直接返回 400 错误(不是警告,是报错)
这些问题中,工程性的 bug 大多已经修复了;但”过于自信地说错话”这个深层问题,属于模型行为特征,短期内不会消失。
六、和竞品的横向比较
| 评测维度 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| 编程能力(SWE-bench Pro) | 64.3% ↑ | 57.7% | 54.2% |
| 工具调用(MCP-Atlas) | 77.3% ↑ | 68.1% | 73.9% |
| 计算机操控(OSWorld) | 78.0% ↑ | 75.0% | — |
| 自主网络搜索(BrowseComp) | 79.3% ↓ | 89.3% | 85.9% |
| 通用推理(GPQA Diamond) | 94.2% ≈ | 94.4% | 94.3% |
| 知识工作(GDPVal-AA) | 1753 ↑ | 1674 | 1314 |
| 上下文窗口 | 100万 | — | 200万 |
| 定价(输入/输出/百万token) | 5/25 | — | 2/12 |
Gemini 3.1 Pro 的定价是 Opus 4.7 的约四分之一,上下文窗口是两倍,但编程基准上落后 10 个点。这个选择没有绝对答案,取决于你的用例对编程能力和成本各自的权重。
GPT-5.4 在自主网络搜索上保持明显优势,如果你的核心工作流是信息检索和联网 Agent,暂时不用切换。
七、谁应该现在就切换,谁应该再等等
现在切换的理由充分(以下任意一条成立就值得升级):
- 你用 Claude Code 或 Cursor 做严肃的代码工作,且会处理复杂的跨文件重构
- 你的工作流里需要处理高分辨率文档、截图、图表,且对识别准确率敏感
- 你在构建长程 Agent,且需要 Task Budget 这类对 token 消耗的可控性
- 你的提示词写得足够精确,不依赖模型”自己发挥”来补全意图
值得等待或谨慎观望的情况:
- 你是 Claude Pro 订阅用户($20/月),日常大量使用——新 tokenizer 会让你比以前更快到达用量上限
- 你依赖联网搜索做信息聚合(BrowseComp 退步明显)
- 你的 API 生产环境不能承受 400 错误带来的迁移成本(temperature 等参数变更是 breaking change)
- 你有写作类工作流,且习惯了让 Claude 自主”润色+纠错”,而非只执行明确指令
八、一个更大的背景:Anthropic 在下一盘什么棋
值得注意的是,Anthropic 在 4.7 的 release notes 里提到了”Claude Mythos Preview”——这是一个能力比 Opus 4.7 更强的模型,但目前处于有限发布状态。Opus 4.7 实际上定位是”Mythos 系列的能力降阶版”,同时充当 Mythos 级别安全机制的试验场。
官方原文说得很直白:Opus 4.7 是第一个携带 Mythos 安全性相关实验的模型,专门测试新的网络安全防护措施。这意味着 4.7 的某些能力(比如网络安全领域)是被刻意压制的。
这个信息的含义:Anthropic 的能力储备远不止我们现在看到的。Opus 4.7 是一个经过安全约束的发布,而不是当前技术极限的全力展示。
同时,这也解释了为什么社区里出现了”BrowseComp 退步”之类看似不合理的现象——在某些领域的克制,可能是设计决策而非能力不足。
九、我的最终判断
Opus 4.7 是一个让人又爱又恨的版本,但这两种情绪指向的其实是两类完全不同的使用姿势。
如果你把它当成一个”执行精密指令的工程工具”,4.7 比 4.6 好很多——它更强、更严格、更可预测,在代码领域已经拉开了与竞品的差距。
如果你习惯于把它当”通晓人意的对话伙伴”,你会感受到明显的疏离——它不再猜你的意思,不再自作主张地帮你把话说圆,你需要比以前说得更清楚才能得到你想要的。
这不是退步,这是定位的漂移:Anthropic 正在把 Opus 系列从”最聪明的通才助手”推向”最精密的专业执行引擎”,而这个转变的代价,是让习惯了旧交互模式的普通用户产生了迷失感。
从发布到现在一周的时间,我的整体结论是:
开发者和工程师:强烈推荐切换,编程能力的提升是货真价实的。
知识工作者和写作用户:值得尝试,但要做好调整提示词习惯的心理准备。
Pro 订阅的日常用户:注意 token 消耗的变化,可能会比以前更快遇到限额。
附:核心功能快查表
| 功能 | 状态 | 备注 |
|---|---|---|
| xhigh effort 等级 | ✅ 新增 | 高于 high,低于 max,编程任务推荐 |
| Task Budget | ✅ 新增 | Agent 长程任务的 token 预算控制 |
| /ultrareview | ✅ 新增 | Claude Code 里的深度代码审查命令 |
| 高分辨率图像 | ✅ 大幅提升 | 3.75MP,是前代 3 倍以上 |
| Adaptive Thinking | ✅ 唯一支持的思考模式 | budget_tokens 参数已移除,会返回 400 |
| temperature/top_p/top_k | ❌ 已移除 | 非默认值会返回 400 错误 |
| 思考摘要默认显示 | ❌ 默认关闭 | 需要手动设置 display: “summarized” |
| BrowseComp 联网搜索 | ⚠️ 退步 | 79.3%,落后 GPT-5.4 约 10 点 |
本文基于 Claude Opus 4.7 发布一周内的实际使用体验,测试平台包括 Claude.ai(Max Plan)、Claude Code CLI 和直接 API 调用。基准数据来源于 Anthropic 官方 release notes、Vellum、Cursor、Nerd Level Tech 等独立测评。文中观点代表个人判断,不构成任何商业推荐。
💬 如果你也在用 Opus 4.7,欢迎在评论区说说你的感受。特别想知道:你是觉得它变聪明了,还是变奇怪了?

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)