DeepSeek V4 发布:1.6 万亿参数,百万上下文,击穿地板价
DeepSeek v4 的发布直接把国产大模型的性价比拉上了一个台阶,这波直接能给到夯。无论是追求极致性能的 Pro 版本,还是兼顾速度与经济性的 Flash 版本,都通过底层架构的创新解决了长文本推理的瓶颈。如果你要处理深度分析、长文档解析或复杂代码逻辑的用户而言,DeepSeek v4 绝对是目前市面上极具性价比的选择。
盼星星盼月亮,在经过3次跳票之后,国产AI之光 DeepSeek 终于发布了最新的 DeepSeek V4。

这段时间全国人民都在催,友商也一直在不断发布新模型,各种跑分,但是 DeepSeek 岿然不动,一直在做自己,终于在上周,DeepSeek V4 默默地发布了。
DeepSeek V4 系列包含了 1.6T 参数的 DeepSeek-V4-Pro(激活参数 49B)以及 284B 参数的 DeepSeek-V4-Flash(激活参数 13B)。这两款模型均原生支持一百万 token 的超长上下文处理,通过架构层面的深度改进,在长文本推理效率上实现了显著突破。
混合注意力架构:解决长文本推理瓶颈
在处理超长上下文时,传统的注意力机制往往面临计算复杂度呈平方级增长的困境。DeepSeek v4 引入了混合注意力架构,通过两种不同的压缩策略来优化这一过程。
混合架构由压缩稀疏注意力(CSA)和重度压缩注意力(HCA)组成。CSA 会将每 4 个 token 的键值缓存(KV Cache)压缩为一个条目,并配合稀疏注意力策略,使得每个查询 token 仅需关注少量的压缩 KV 条目。HCA 则采取更激进的方案,将每 128 个 token 压缩为一个条目,同时保持稠密注意力。
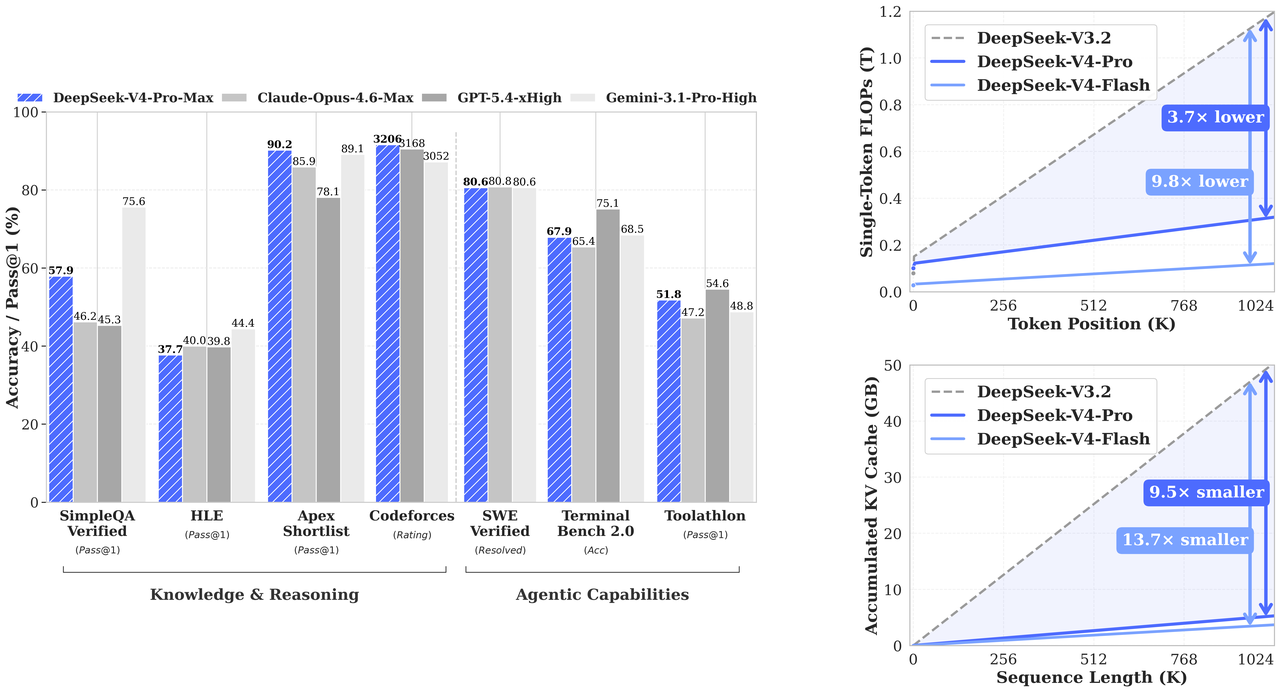
这种设计在百万 token 的上下文场景下表现优异。相比之前的 DeepSeek-V3.2,DeepSeek-V4-Pro 的单 token 推理计算量下降到了原先的 27%,而 KV 缓存的显存占用更是缩减到了 10%。对于硬件资源有限的开发者而言,这种效率提升降低了超长文本应用的门槛。
架构优化:mHC 链接与 Muon 优化器
除了注意力机制的改进,DeepSeek v4 在模型稳定性和收敛速度上也进行了底层升级。
模型引入了流形约束超连接(mHC)技术,这是对传统残差连接的一种升级。mHC 通过将残差映射约束在特定的流形上,增强了信号在多层网络中传播的稳定性,保证了模型在参数规模扩大时的表达能力。
在优化算法方面,DeepSeek v4 采用了 Muon 优化器。该优化器在大多数模块中取代了常用的 AdamW,利用牛顿-舒尔茨迭代进行正交化处理。Muon 带来的优势在于更快的收敛速度和更强的训练稳定性。为了防止注意力分值出现数值爆炸,团队在查询和键值输入端直接应用了 RMSNorm,从而弃用了传统的 QK-Clip 技术。
基础设施支持:TileLang 与 FP4 训练
高效的模型离不开底层基础设施的支撑。DeepSeek v4 采用了领域特定语言 TileLang 进行内核开发,通过融合内核取代了数百个细碎的算子,在保证运行效率的同时提升了开发灵活性。
针对显存占用问题,DeepSeek v4 在后期训练阶段引入了 FP4 量化感知训练。MoE 专家权重和 CSA 索引器的 QK 路径均实现了 FP4 量化。值得一提的是,从 FP4 到 FP8 的反量化过程是无损的,这使得模型能够复用现有的 FP8 训练框架,同时在部署阶段获得近 2 倍的选择速度提升。
训练数据与性能表现
DeepSeek v4 的预训练数据量超过了 32T token。在后期训练中,团队采用了两阶段范式,先独立培养数学、代码、创意写作等领域的专家模型,再通过在线策略蒸馏(OPD)将这些专业能力整合进统一的模型中。
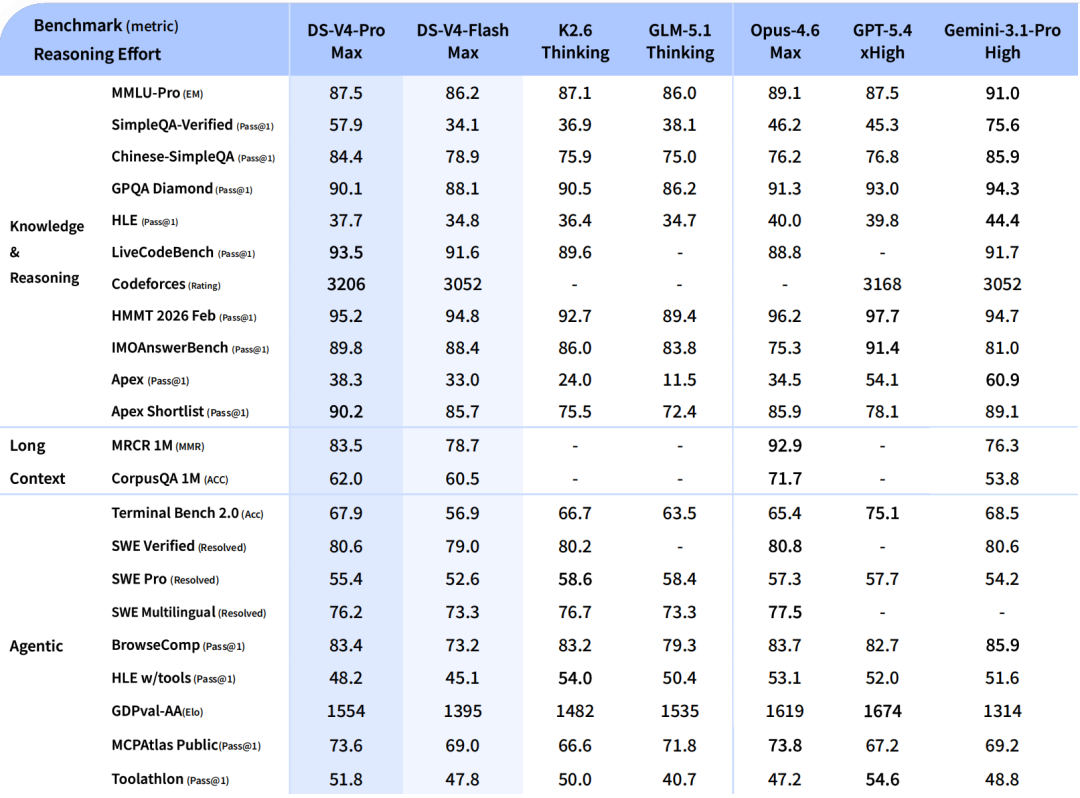
在 benchmark 评测中,DeepSeek-V4-Pro-Max 展现了极强的竞争力。在知识类测试 SimpleQA 中,其表现优于许多领先的开源模型。在长文本检索任务 MRCR 1M 中,即便上下文达到百万量级,该模型依然保持了极高的召回稳定性。
对于编程和 Agent 任务,DeepSeek v4 同样表现出色。在 LiveCodeBench 和 SWE Verified 等榜单中,Pro 版本已经能够与顶级闭源模型一较高下。
推理模式的灵活切换
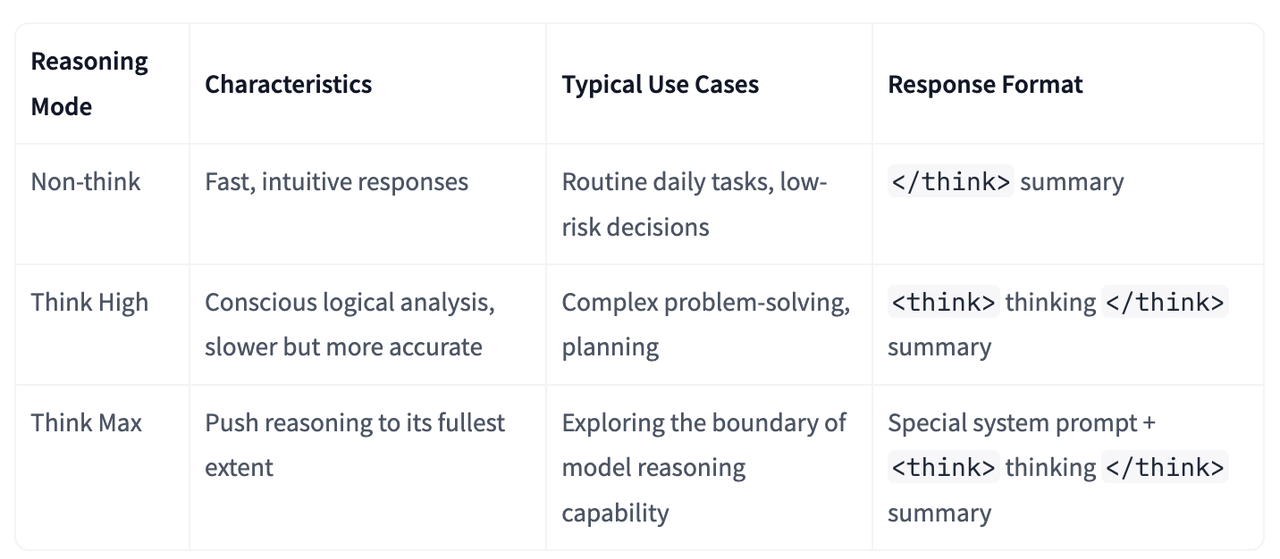
DeepSeek v4 提供了三种推理模式以适应不同的应用场景。
-
Non-think 模式:提供快速且直觉式的响应,适用于日常对话或低风险的决策。
-
Think High 模式:开启逻辑分析,速度稍慢但准确性更高,适用于复杂问题的解决。
-
Think Max 模式:通过注入特定的系统提示词并延长思考 token 长度,挑战模型推理能力的上限,适合处理边界难题。
DeepSeek V4 包含了 DeepSeek-V4-Pro 和 DeepSeek-V4-Flash,其中DeepSeek-V4-Pro 侧重于性能天花板,在编程、数学及 STEM 领域具备极强的竞争力。在 Agentic Coding 评测中,该模型已达到当前开源模型的高水准,交付质量在非思考模式下接近顶级闭源模型。
DeepSeek-V4-Flash 则侧重于推理速度与成本优势。虽然激活参数较少,但其推理能力在多数场景下逼近 Pro 版本,尤其在处理日常任务和基础智能体应用时表现出色。两款模型均支持非思考模式与思考模式,用户可根据任务复杂度灵活切换。
详细定价方案
我说 DeepSeek V4 是性价比最高的大模型,谁赞成谁反对?
DeepSeek-V4-Pro
-
缓存命中的输入单价为 1 元 / 百万 tokens
-
缓存未命中的输入单价为 12 元 / 百万 tokens
-
输出单价为 24 元 / 百万 tokens
DeepSeek-V4-Flash
-
缓存命中的输入单价为 0.2 元 / 百万 tokens
-
缓存未命中的输入单价为 1 元 / 百万 tokens
-
输出单价为 2 元 / 百万 tokens
根据官方数据对比,这个价格是同类竞争对手的 1/20 到 1/40。极低的缓存命中价格为频繁调用长文本背景的开发者提供了巨大的成本空间。
使用方法与调用指南
目前用户可以通过多种途径体验 DeepSeek v4。
网页端与移动端
访问官方聊天平台 chat.deepseek.com 或通过 DeepSeek 官方 App 就可以玩了。平台已集成专家模式与即时模式,支持百万字级别的全文阅读。几十篇深度报告或整个项目的背景文档并进行精准分析成为了可能。
API 调用
对于我们开发者,当然是要调用 API 啦。
eepSeek API 采用与 OpenAI 和 Anthropic 兼容的格式。通过简单的配置修改,开发者可以快速将现有应用迁移至 DeepSeek v4。
推理模式调用示例(以 Python 为例)
DeepSeek v4 支持通过参数控制思考深度。在此之前,请确保 Python 环境已经安装好;如果没有,可以使用 ServBay 一键安装 Python 环境。
以下是接入 deepseek-v4-pro 并开启深度思考模式的代码示例:
import os
from openai import OpenAI
# 需先安装 OpenAI SDK: pip3 install openai
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "你是一位专业的技术文档分析师"},
{"role": "user", "content": "请分析该项目的核心架构设计"},
],
stream=False,
# 开启思考模式的相关配置
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)
print(response.choices[0].message.content)接入建议
-
全文阅读能力:利用 1M 上下文窗口,开发者可以将整本书、N份行业报告或完整的代码库直接作为上下文输入。
-
参数调节:网页端或 App 用户可直接体验;API 开发者建议将
temperature设为 1.0,top_p设为 1.0。若使用Think Max模式处理极其复杂的逻辑,建议将上下文窗口预留至 384K 以上以获得最佳效果。
总结
DeepSeek v4 的发布直接把国产大模型的性价比拉上了一个台阶,这波直接能给到夯。无论是追求极致性能的 Pro 版本,还是兼顾速度与经济性的 Flash 版本,都通过底层架构的创新解决了长文本推理的瓶颈。
如果你要处理深度分析、长文档解析或复杂代码逻辑的用户而言,DeepSeek v4 绝对是目前市面上极具性价比的选择。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)