从Token泛滥到 Token 极度节俭:2026程序员必须掌握的推理成本优化指南
最近三个月,我身边越来越多的技术团队开始感受到一种压力。不是模型不够强,是账单涨得太快。我们组上个月刚把几个核心业务切到某新模型,效果确实好,但推理成本翻了4倍。老板问了一句:这钱能不能省一半?会议室沉默了十秒。更让人焦虑的是,身边已经有朋友因为API账单失控被约谈。不是个例。与此同时,Cursor、Claude Code、OpenClaw 这些工具在悄悄改变一件事:它们不再无脑堆Token,而是
最近三个月,我身边越来越多的技术团队开始感受到一种压力。
不是模型不够强,是账单涨得太快。
我们组上个月刚把几个核心业务切到某新模型,效果确实好,但推理成本翻了4倍。老板问了一句:这钱能不能省一半?会议室沉默了十秒。
更让人焦虑的是,身边已经有朋友因为API账单失控被约谈。不是个例。
与此同时,Cursor、Claude Code、OpenClaw 这些工具在悄悄改变一件事:它们不再无脑堆Token,而是开始精打细算每一个Token的用途。
Token泛滥的时代正在结束。2026年,不会做推理成本优化的工程师,会发现自己写的代码根本跑不进生产环境。
目录
-
一、Token从资源变成负债
-
二、本质是推理效率模型的重构
-
三、核心机制:三层缓存 + 动态采样控制
-
四、三个产品的成本策略对比
-
五、工程落地:你现在就能做的四件事
-
六、趋势判断:优化能力将成为基本功
一、Token从资源变成负债
去年大家还在比谁能塞进更长的上下文。128K不够,上1M。1M不够,上10M。
但那是资本充裕时期的玩法。
2026年的现实是:企业开始算每一笔API调用的ROI。一个请求出去,输入输出加起来几万Token,返回的结果质量只比精简版高5%。这5%的边际收益,值不值得多付300%的成本?
很多团队已经给出答案:不值得。
真正的变化发生在工程侧。一线工程师开始被要求做三件事:
-
测量每次调用的Token消耗
-
设计降本不减效的prompt结构
-
在延迟和成本之间做显式取舍
这不是架构师的事,是每个写代码的人都要面对的事。
二、本质是推理效率模型的重构
很多人以为优化推理成本就是缩短prompt。错。
核心在于重新理解一件事:你花出去的Token到底用在哪里了。
拆解一次典型的大模型推理调用:
-
输入Token:prompt + 历史对话 + 检索到的文档
-
输出Token:模型生成的内容
-
隐藏成本:冗余的Attention计算、重复编码的公共前缀、无效的拒绝采样
本质问题是:我们一直在用处理长文档的方式处理多轮对话和智能体任务。这就像每次聊天都把整本百科全书重读一遍。
正确的优化方向不是“少说两句”,而是“复用已算过的结果”和“动态控制生成路径”。
三、核心机制:三层缓存 + 动态采样控制
当前主流推理优化方案,本质上都在做同一件事:减少重复计算。
我把它总结为三层缓存架构。
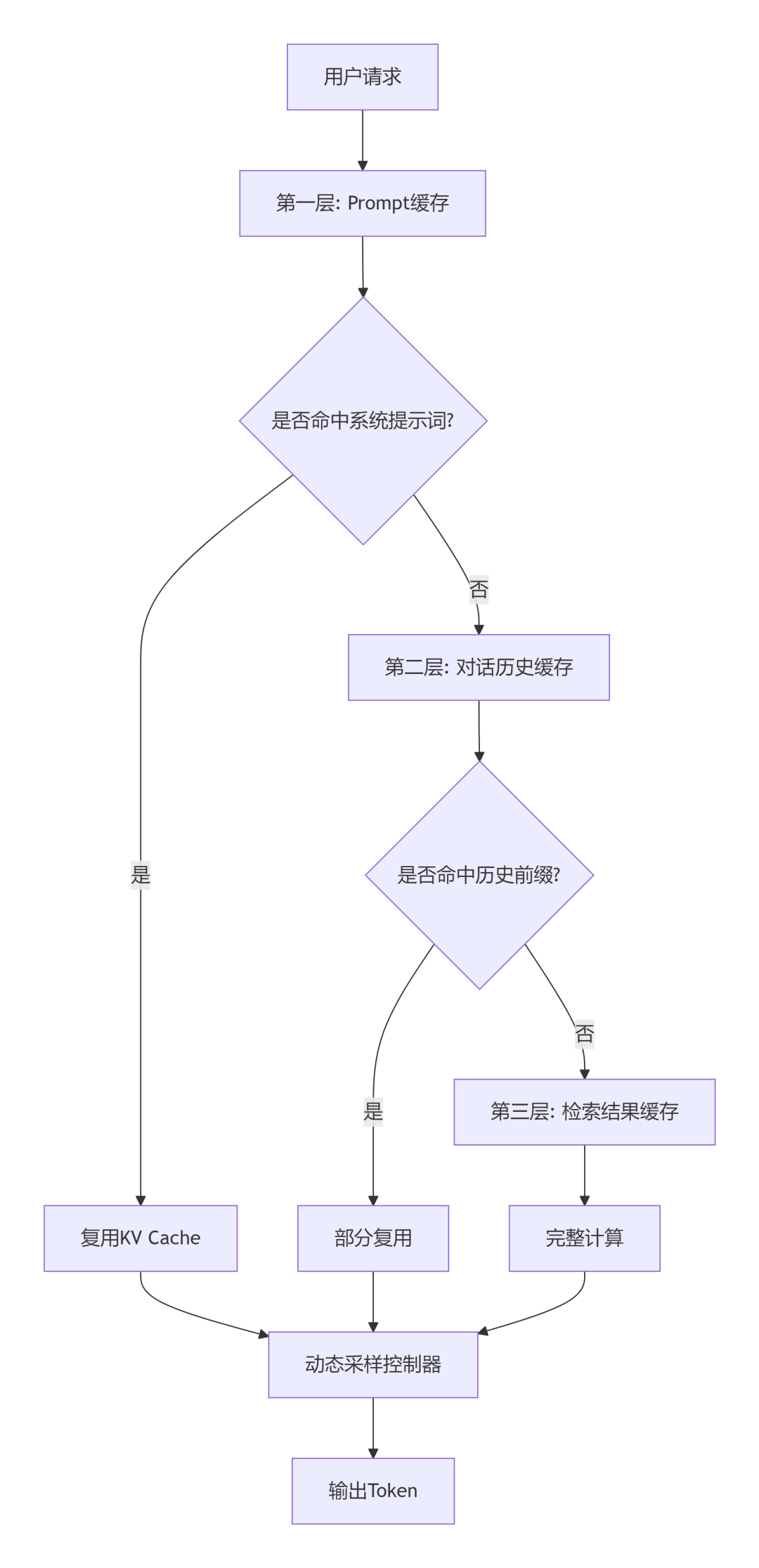
第一层:Prompt缓存。系统提示词、角色设定这些固定内容,一次计算后缓存KV值。后续请求直接复用。Claude在这一层做到了90%以上的命中率。
第二层:对话历史缓存。多轮对话中,前面的轮次不需要每轮重算。关键是把公共前缀识别出来。这是OpenClaw的主要优化点。
第三层:检索结果缓存。RAG场景中,相同或相似的查询不需要反复检索和embedding。缓存时间窗口根据业务动态调整。
动态采样控制是另一个被忽视的方向。
传统做法:设定temperature和top_p,让模型自由发挥。优化后的做法:根据任务类型动态调整采样参数。事实性问答用贪婪解码,创意生成才打开随机性。
OpenClaw在这块的实践很有参考价值:他们在同一个请求内分阶段切换采样策略。第一阶段确定性提取,第二阶段开放生成。整体Token消耗降低40%,质量几乎无损。
四、三个产品的成本策略对比
看几个具体产品的做法。
Cursor
策略:多模型路由 + 任务拆分。简单代码补全走小型专用模型,复杂重构才调用大模型。开发者无感知,背后有一套成本预估器在决策。
关键数据:据说有超过60%的请求被路由到小模型,整体成本降低约55%。
Claude Code
策略:极度激进的Prompt缓存。系统提示词长度超过5000 Token,但实际每次调用只传输变化部分。KV缓存的复用率在典型开发场景下超过80%。
代价是增加了约100ms的缓存查找开销。但相比重新计算5000 Token的Attention,这笔买卖很划算。
OpenClaw
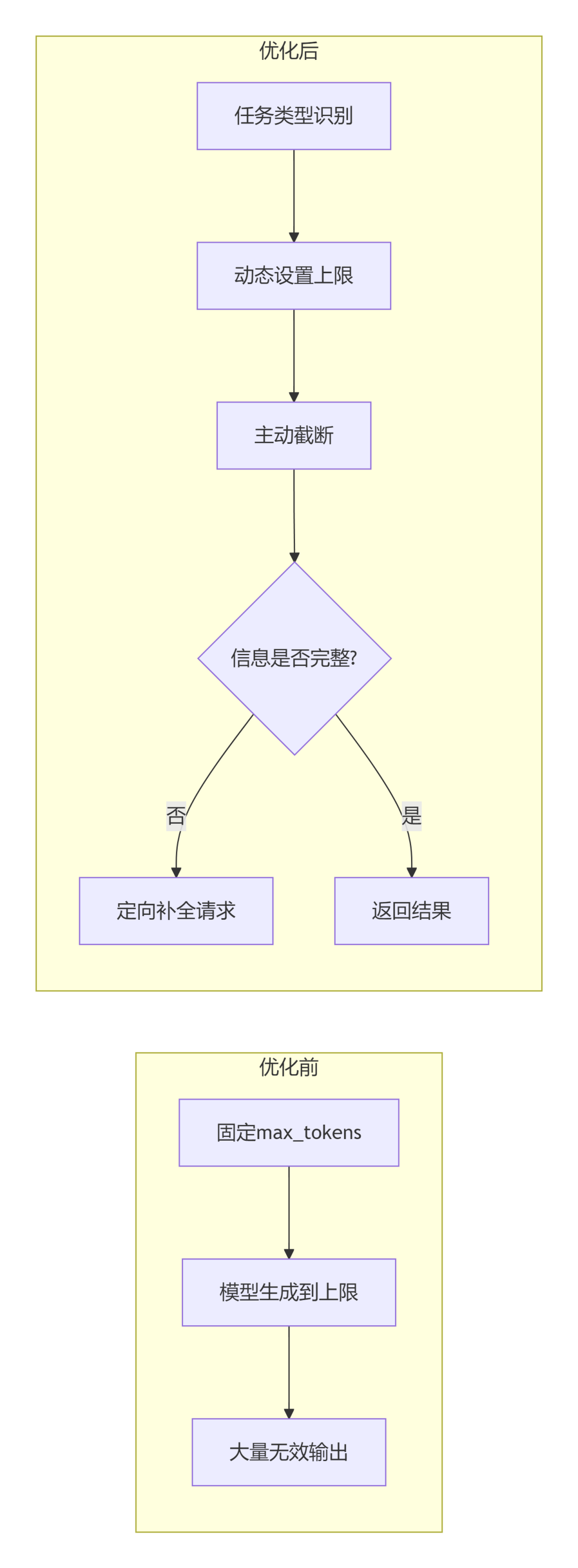
策略:动态采样控制 + 自适应输出长度。它会根据任务复杂度动态调整最大输出Token,并在生成过程中早停。不是等模型自己停,是主动判断已经获得了足够信息。
实测:在信息提取类任务中,平均输出长度减少了62%,准确率基本持平。
五、工程落地:你现在就能做的四件事
不说空话,直接给可执行方案。
第一,建立Token审计体系。
在调用入口和出口埋点,记录三个指标:输入长度、输出长度、实际有用输出占比(需要定义业务指标)。不用精确到小数点,知道量级就够了。
关键是要能回答:过去一周,哪个业务场景的Token消耗最高?
第二,实现Prompt缓存层。
不是依赖模型提供商的能力,是在应用层自己做。把系统提示词、固定示例、重复前缀抽出来,用一致性哈希做缓存key。
代码量不大,一个200行的缓存装饰器就能覆盖80%的场景。
第三,设计任务感知的路由器。
规则不要太复杂。先分三类:事实问答、创意生成、代码生成。每类预设不同的模型、采样参数、缓存策略。
路由逻辑用配置化方式实现,方便后续调整。
第四,引入输出长度的自适应控制。
这是最容易被忽视的。很多人习惯设一个较大的max_tokens,然后让模型自己停。问题在于模型不会主动节省。
更好的做法:根据请求类型动态设置上限。简单问题给500,复杂问题给2000,超出走截断+二次调用。
二次调用听起来更贵,实际上比一次生成5000 Token要便宜得多。
六、趋势判断:优化能力将成为基本功
未来十二个月,推理成本优化会从加分项变成准入门槛。
原因有两个。
一是模型层的能力差距在缩小。GPT-4级别的模型会商品化,成本控制能力成为区分团队水平的核心指标。
二是企业开始把Token消耗纳入预算管理。不是开发者想不想优化的问题,是财务会直接问:这个功能的边际成本是多少。
三个值得关注的方向:
-
推理感知的编程范式:写代码时就能预估Token消耗,类似现在的时间复杂度分析
-
本地化缓存网络:团队内部共享KV缓存,跨请求复用
-
模型自身的成本意识:未来的模型接口可能会直接返回“置信度+成本建议”
OpenClaw 和 Cursor 的做法会被标准化。2026年底之前,主流框架会内置推理优化模块,像今天内置日志和监控一样自然。
最后留一个问题。
你现在的系统,是否能够准确回答:上一周所有模型调用的边际收益是多少?哪个场景的Token浪费最严重?
如果答不上来,你可能已经在不知不觉中为低效支付了太多成本。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)