Qwen3-VL全家桶再进化!通义千问推出最强多模态检索双子星
总而言之,Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 不仅为多模态检索领域树立了新的技术标杆,其灵活的部署选项(2B/8B参数规模、MRL、QAT)也极大地降低了工业界应用的门槛。正如论文中的 Figure 1 所生动展示的那样,无论是文字“城市建筑”,还是其对应的实景照片,都会被编码成空间中邻近的点,从而实现了跨模态的语义对齐。它的输入格式非常直观,通过一个明确

在信息爆炸的时代,我们早已不满足于仅用文字搜索。想找一张“赛博朋克风格的城市夜景”?想从海量视频中找出“那个穿红衣服跳舞的人”?甚至想根据一份复杂的财报截图提问?这些跨模态的复杂需求,正推动着搜索技术进入一个全新的纪元。
今天,通义千问(Qwen)团队正式推出其多模态检索领域的最新力作——Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型系列。它们不是简单的工具,而是一对配合默契的“AI搭档”,共同构建了一个端到端的高精度多模态搜索管道,旨在彻底打通文本、图像、文档和视频之间的语义壁垒。

一套组合拳:从海量召回,到精准排序
想象一下你在电商平台搜索“有落地窗的现代简约风客厅”。理想情况下,系统不仅应该返回相关的文字描述,更应该直接展示符合这一美学风格的实景照片或视频。这背后,其实是一个两阶段的精密过程:
第一阶段:快速召回(Embedding)
系统需要将你的文字查询(Query)和数据库里成千上万的图片、视频(Documents)都转换成一种通用的“语言”——即高维向量(Embedding)。然后通过计算向量间的相似度(如余弦相似度),快速筛选出最相关的几百个候选结果。这个过程要求快且准。
第二阶段:精细排序(Reranking)
在第一阶段召回的候选结果中,哪些才是真正最贴切的?这就需要一个更“聪明”的模型,对查询和每个候选文档进行深度交互和理解,给出一个精确的相关性打分,从而对结果进行重新排序。这个过程要求深且精。
Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 正是为这两个核心任务量身打造的“黄金搭档”,共同构建了一个端到端的高性能多模态检索管道。
01
Qwen3-VL-Embedding:
强大的多模态“翻译官”
作为召回阶段的核心,Qwen3-VL-Embedding 的目标是将文本、图像、文档图像乃至视频,全部映射到一个统一的语义表示空间中。正如论文中的 Figure 1 所生动展示的那样,无论是文字“城市建筑”,还是其对应的实景照片,都会被编码成空间中邻近的点,从而实现了跨模态的语义对齐。

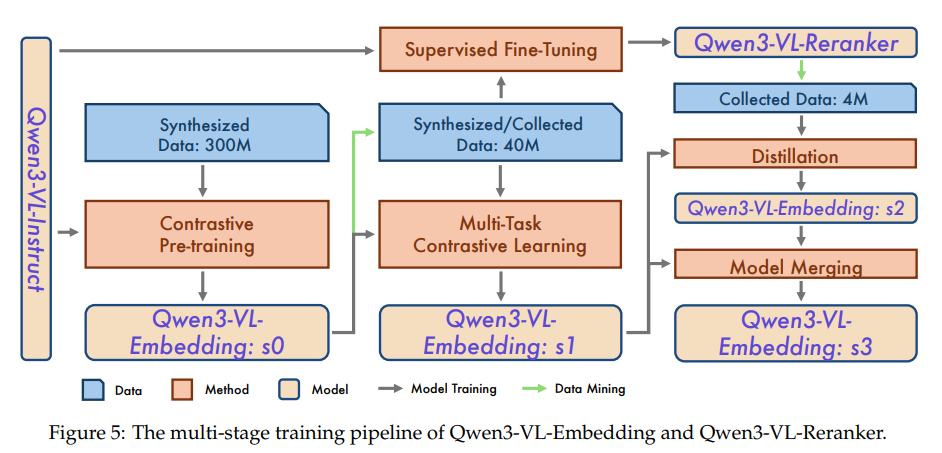
为了让这位“翻译官”能力超群,研究团队设计了一套复杂的多阶段训练范式(见论文 Figure 5):
-
第一阶段:大规模对比预训练,在海量合成数据上建立基础的跨模态理解能力。
-
第二阶段:多任务对比学习,结合高质量的公开和内部数据,针对不同任务(如分类、问答、检索)进行精细化训练。
-
第三阶段:重排序模型蒸馏,将更强大的Qwen3-VL-Reranker的“判断力”反哺给Embedding模型,使其生成的向量能更好地服务于最终的排序目标。
此外,该模型还集成了两大实用特性:
-
Matryoshka Representation Learning (MRL):支持灵活的嵌入维度。用户可以根据自己的存储和算力需求,在不重新训练的情况下,自由选择使用2048维(2B模型)或4096维(8B模型)的完整向量,或是更低维度的子向量。
-
量化感知训练 (QAT):确保模型在低精度(如int8)量化后,性能依然稳健,极大降低了部署成本。
02
Qwen3-VL-Reranker:
犀利的多模态“裁判员”
如果说Embedding模型是广撒网的侦察兵,那么Reranker模型就是一锤定音的裁判员。它采用交叉编码器(Cross-Encoder)架构(见论文 Figure 2),能够对查询和文档进行深度的交叉注意力交互,捕捉二者之间最细微的语义关联。
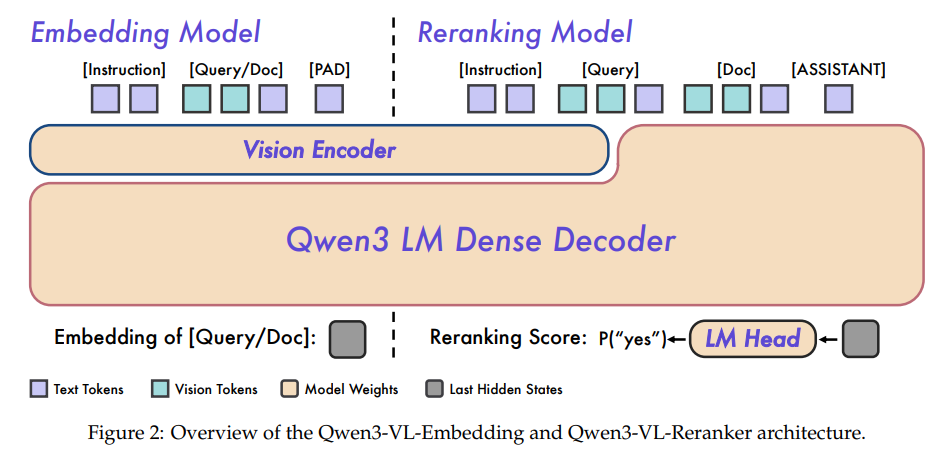
它的输入格式非常直观,通过一个明确的指令(Instruction),让模型判断“文档是否满足查询的要求”,并输出“yes”或“no”的概率。最终的相关性得分由这两个token的logit差值通过Sigmoid函数计算得出。
全面领先:SOTA性能与强大泛化能力
这套组合拳的威力,在多个权威基准测试中得到了充分验证。
01
多模态检索的绝对王者
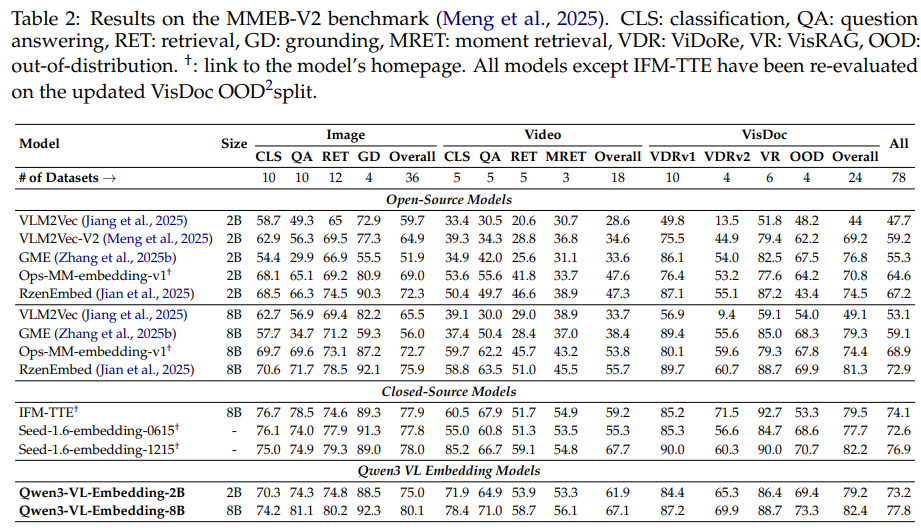
在目前最全面的多模态嵌入评测基准 MMEB-V2 上,Qwen3-VL-Embedding-8B 以 77.8 的总分强势登顶,超越了所有开源和闭源模型,包括OpenAI、Gemini等业界巨头(截至2025年1月8日)。这一辉煌战绩在论文的 Table 2 中有完整呈现。无论是在图像、视频还是视觉文档领域,它都展现出了卓越且均衡的性能。
02
视觉文档检索的新标杆
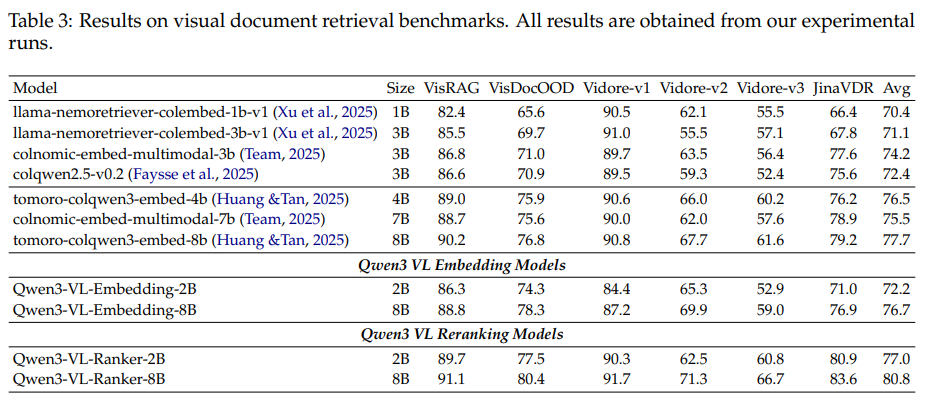
在专门针对PDF、扫描件等视觉文档的检索任务上(如JinaVDR, Vidore-v3),Qwen3-VL-Embedding的表现甚至可以媲美计算成本高昂的ColPali系列模型。而Qwen3-VL-Reranker则更进一步,大幅超越了同规模的ColPali模型。具体数据请参考论文 Table 3。
03
纯文本任务也不落下风
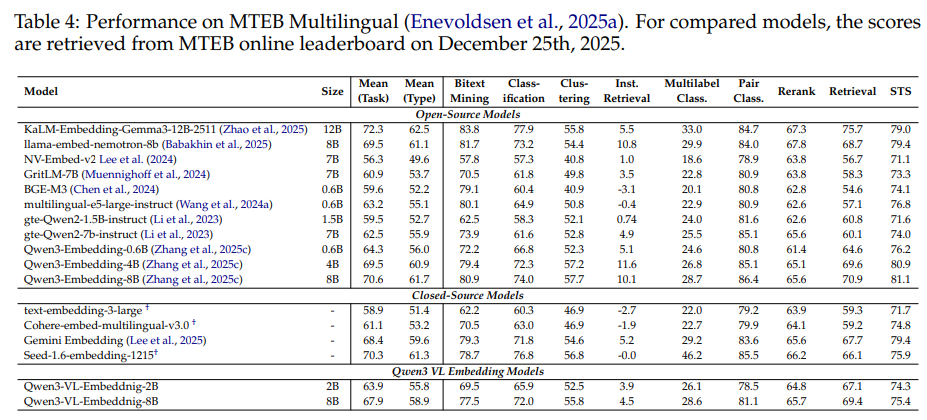
尽管是为多模态而生,但得益于其强大的Qwen3-VL基座,该系列模型在纯文本任务上同样表现出色。在 MMTEB 多语言文本嵌入基准上,Qwen3-VL-Embedding-8B取得了 67.9 的平均分,与同体量的纯文本嵌入模型相比毫不逊色(见论文 Table 4)。
04
重排序能力全面提升
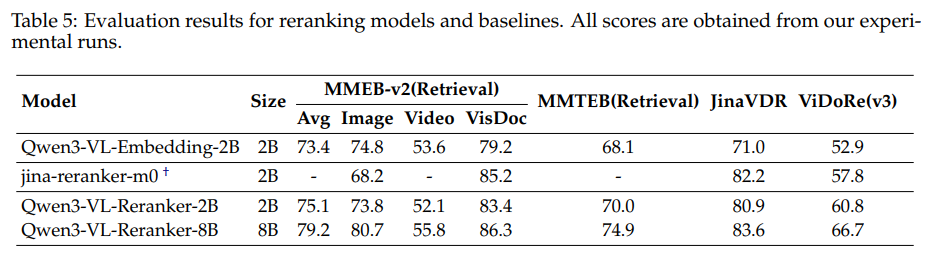
最后,Qwen3-VL-Reranker自身的能力也极为强悍。在对Embedding模型召回的Top-100结果进行重排后,各项指标均得到显著提升。其中,8B版本的Reranker在几乎所有任务上都取得了最佳性能(见论文 Table 5)。
结论
总而言之,Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 不仅为多模态检索领域树立了新的技术标杆,其灵活的部署选项(2B/8B参数规模、MRL、QAT)也极大地降低了工业界应用的门槛。它们不仅是强大的技术工具,更是推动下一代智能搜索、内容推荐和多模态RAG(检索增强生成)系统发展的关键基石。

行业领先的AI服务供应商
探索智能边界
发现无限可能

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)