基于yolov8+django+deepseek的舌头舌象舌苔疾病诊断系统带登录界面python源码+onnx模型+精美web界面
基于 YOLOv8 的目标检测系统,支持图片、视频和实时摄像头检测,集成 DeepSeek AI 分析功能。访问 http://127.0.0.1:8000。训练精度(Precision)=96.0%训练召回率(Recall)=96.8%houhuang(厚黄)fenhong(粉红)训练map=98.9%houbai(厚白)huihei(灰黑)训练集图片数=720。
效果展示
登录界面
主界面
基于 YOLOv8 的目标检测系统,支持图片、视频和实时摄像头检测,集成 DeepSeek AI 分析功能。
功能特性
- 图片目标检测
- 视频文件检测
- 实时摄像头检测
- DeepSeek AI 智能分析
- 可调节的检测参数(置信度、IoU)
- 美观的用户界面
【测试环境】
windows10
anaconda3+python3.10
torch2.3.1
ultralytics8.4.7
Django==5.2.11
【模型可以检测出5类别】
houbai(厚白)
huihei(灰黑)
houhuang(厚黄)
fenhong(粉红)
bobai(薄白)
训练数据集信息
训练集图片数=720
验证集图片数=80
训练map=98.9%
训练精度(Precision)=96.0%
训练召回率(Recall)=96.8%
验证集精度: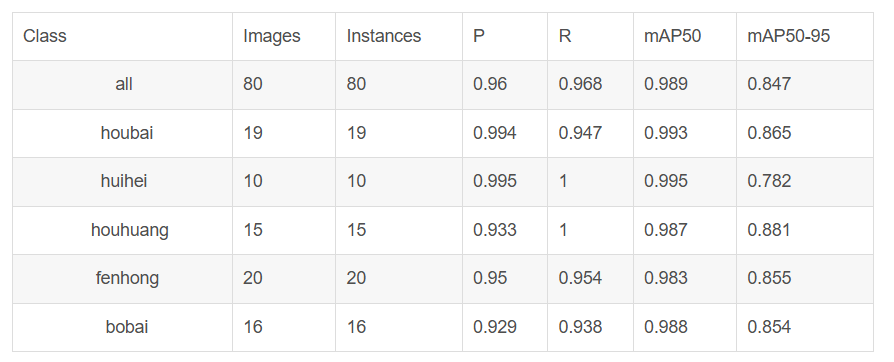
安装依赖
pip install -r requirements.txt
数据库迁移
python manage.py makemigrations
python manage.py migrate
运行项目
python manage.py runserver
访问 http://127.0.0.1:8000
默认登录信息
- 用户名: admin
- 密码: admin
项目主要文件结构
yolov8-django-deepseek-det-system/
├── manage.py # Django 项目管理脚本
├── requirements.txt # 项目依赖包列表
├── README.md # 项目说明文档
├── index.html # 主页面(备用或示例页面)
├── start_lan.bat # 一键启动批处理脚本
├── yolo_detection/ # Django 项目配置目录
│ ├── __init__.py # 初始化文件
│ ├── settings.py # 项目配置文件(数据库、API密钥等)
│ ├── urls.py # 项目总路由配置
│ └── wsgi.py # WSGI 部署配置
├── detection/ # 检测功能应用模块
│ ├── __init__.py # 初始化文件
│ ├── apps.py # 应用配置
│ ├── forms.py # 表单定义(如文件上传表单)
│ ├── models.py # 数据模型定义
│ ├── urls.py # 检测应用的路由配置
│ └── views.py # 核心视图函数(YOLO检测逻辑、文件处理等)
├── templates/ # Web 页面模板目录
│ ├── index.html # 主操作界面(上传、检测、结果显示)
│ └── login.html # 登录页面
├── media/ # 媒体文件存储目录
│ └── uploads/ # 用户上传文件存储目录
├── test_img/ # 测试图片目录
│ └── she_*.jpg # 舌象检测样本图片(舌白、灰黑、舌黄、粉红、薄白等舌诊图片)
技术栈
- Django 4.2+
- YOLOv8 (Ultralytics)
- OpenCV
- DeepSeek API
- Chart.js
- HTML5/CSS3/JavaScript
注意事项
- 确保
yolov8n.onnx模型文件在项目weights目录 - DeepSeek API 密钥需要在
settings.py中配置 - 建议使用 Python 3.8+
常用评估参数介绍
在目标检测任务中,评估模型的性能是至关重要的。你提到的几个术语是评估模型性能的常用指标。下面是对这些术语的详细解释:
Class:
这通常指的是模型被设计用来检测的目标类别。例如,一个模型可能被训练来检测车辆、行人或动物等不同类别的对象。
Images:
表示验证集中的图片数量。验证集是用来评估模型性能的数据集,与训练集分开,以确保评估结果的公正性。
Instances:
在所有图片中目标对象的总数。这包括了所有类别对象的总和,例如,如果验证集包含100张图片,每张图片平均有5个目标对象,则Instances为500。
P(精确度Precision):
精确度是模型预测为正样本的实例中,真正为正样本的比例。计算公式为:Precision = TP / (TP + FP),其中TP表示真正例(True Positives),FP表示假正例(False Positives)。
R(召回率Recall):
召回率是所有真正的正样本中被模型正确预测为正样本的比例。计算公式为:Recall = TP / (TP + FN),其中FN表示假负例(False Negatives)。
mAP50:
表示在IoU(交并比)阈值为0.5时的平均精度(mean Average Precision)。IoU是衡量预测框和真实框重叠程度的指标。mAP是一个综合指标,考虑了精确度和召回率,用于评估模型在不同召回率水平上的性能。在IoU=0.5时,如果预测框与真实框的重叠程度达到或超过50%,则认为该预测是正确的。
mAP50-95:
表示在IoU从0.5到0.95(间隔0.05)的范围内,模型的平均精度。这是一个更严格的评估标准,要求预测框与真实框的重叠程度更高。在目标检测任务中,更高的IoU阈值意味着模型需要更准确地定位目标对象。mAP50-95的计算考虑了从宽松到严格的多个IoU阈值,因此能够更全面地评估模型的性能。
这些指标共同构成了评估目标检测模型性能的重要框架。通过比较不同模型在这些指标上的表现,可以判断哪个模型在实际应用中可能更有效。
常见问题
目标检测训练中,Mean Average Precision(MAP)偏低可能有以下原因:
原因一:欠拟合:如果训练数据量过小,模型可能无法学习到足够的特征,从而影响预测效果,导致欠拟合,进而使MAP偏低。因此可以加大数据集数量
原因二:小目标:如果数据集包含大部分小目标则一般会有可能产生map偏低情况,因为小目标特征不明显,模型很难学到特征。
原因三:模型调参不对:比如学习率调整过大可能会导致学习能力过快,模型参数调节出现紊乱
原因四:过拟合(现在模型基本不存在这种情况):如果模型在训练数据上表现非常好,但在验证或测试数据上表现较差,可能是出现了过拟合。这通常是因为模型参数过多,而训练数据量相对较小,导致模型学习到了训练数据中的噪声或特定模式,而无法泛化到新的数据。如今现在目标检测模型都对这个情况做的很好,很少有这种情况发生。
原因五:场景不一样:验证集验证精度高,测试集不行,则有可能是与训练模型场景图片不一致导致测试map过低
针对以上原因,可以采取以下措施来提高MAP:
(1)优化模型结构:根据任务和数据集的特点选择合适的模型,并尝试使用不同的网络架构和构件来改进模型性能。
(2)增强数据预处理:对数据进行适当的预处理和增强,如数据归一化、缺失值填充、数据扩增等,以提高模型的泛化能力。
(3)调整损失函数:尝试使用不同的损失函数或组合多种损失函数来优化模型性能。
(4)优化训练策略:调整学习率、批次大小、训练轮数等超参数,以及使用学习率衰减、动量等优化算法来改善模型训练效果。
(5)使用预训练模型:利用在大规模数据集上预训练的模型进行迁移学习,可以加速模型收敛并提高性能。
(6)增加数据集数量
提供的文件
python源码
yolov8n.onnx模型(不提供pytorch模型)
训练的map,P,R曲线图(在weights\results.png)
测试图片(在test_img文件夹下面)
注意提供数据集在数据集地址.xlsx文件中

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 13
13 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)