山东大学软件学院创新实训——MarketClaw(四):热点借势营销——从爬虫挣扎到API集成,让AI文案会“蹭热度”
本文实现了MarketClaw项目的热点采集与借势营销功能。通过调用聚合API获取实时百度热搜,设计了趋势对比算法,并让用户主动选择热点序号,由DeepSeek生成融合热点的营销文案。文章记录了爬虫失败、API切换、用户交互优化的完整过程,并展示了飞书机器人真实测试截图。
一、引言
营销的核心是“借势”。当一个话题冲上热搜,谁能最快、最自然地结合自身产品产出内容,谁就能获得巨大流量。在MarketClaw项目中,我希望机器人不仅能生成小红书文案,更能主动感知当前热点,并辅助用户创作与热点关联的营销内容。这正好对应了任务书中的Skill2(热点信息采集)和Skill1(商品分析)的结合。
本篇博客记录了我自己从零开始实现热点采集、趋势对比、再到“借势”生成文案的完整过程,包括技术选型、踩坑经历、最终方案以及真实测试截图。所有功能已集成到飞书机器人中,用户发送简单命令即可获得实时热搜、飙升话题以及针对热点的营销文案。
二、技术方案演进:为什么我放弃了写爬虫?
起初我打算使用传统爬虫直接抓取百度热搜页面。代码很简单:requests + BeautifulSoup,分析HTML结构提取标题和热度。然而在真实环境中,这套方案几乎寸步难行:
-
反爬机制:百度热搜页面会检测非浏览器访问,加上简单的User‑Agent仍会返回403或跳转验证页面。
-
页面结构变化:百度的class名经常变动(例如
.category-wrap_iQLoo这种动态命名),导致选择器频繁失效。 -
IP限制:即使在WSL中配置了代理,依然会遇到请求被重置或返回空HTML的情况。
随后我尝试了微博移动端API、知乎公开API、聚合API(uapis.cn、xygeng.cn等)。但微博返回401,知乎需要登录Cookie,部分聚合API也不稳定或返回空数据。在尝试了不下5种数据源之后,我最终找到了目前稳定可用的第三方聚合API:https://api.52hyjs.com/apis.php?api=baidu。它无需认证、返回标准JSON、数据更新及时,成功解决了数据源问题。
反思:对于个人开发项目,爬虫并非最优解。直接调用成熟、免费的聚合API,既保证了功能的稳定性,又能将精力集中在更有价值的“如何利用热点”上。
三、核心功能实现
3.1 获取实时热搜榜
我封装了get_baidu_hot_realtime(limit=10)函数:
def get_baidu_hot_realtime(limit=10):
url = "https://api.52hyjs.com/apis.php?api=baidu"
try:
response = requests.get(url, timeout=10)
data = response.json()
if data.get("code") == 200:
items = data.get("data", [])[:limit]
return [{"title": item["title"], "hot": item["hot"]} for item in items]
return []
except Exception as e:
logger.error(f"获取热搜失败: {e}")
return []
该函数每次调用都会获取最新的百度热搜前十名,返回包含标题和热度值的字典列表。当用户在飞书中发送“热点”时,机器人调用此函数并格式化输出。下图是我在手机飞书上的实测截图:
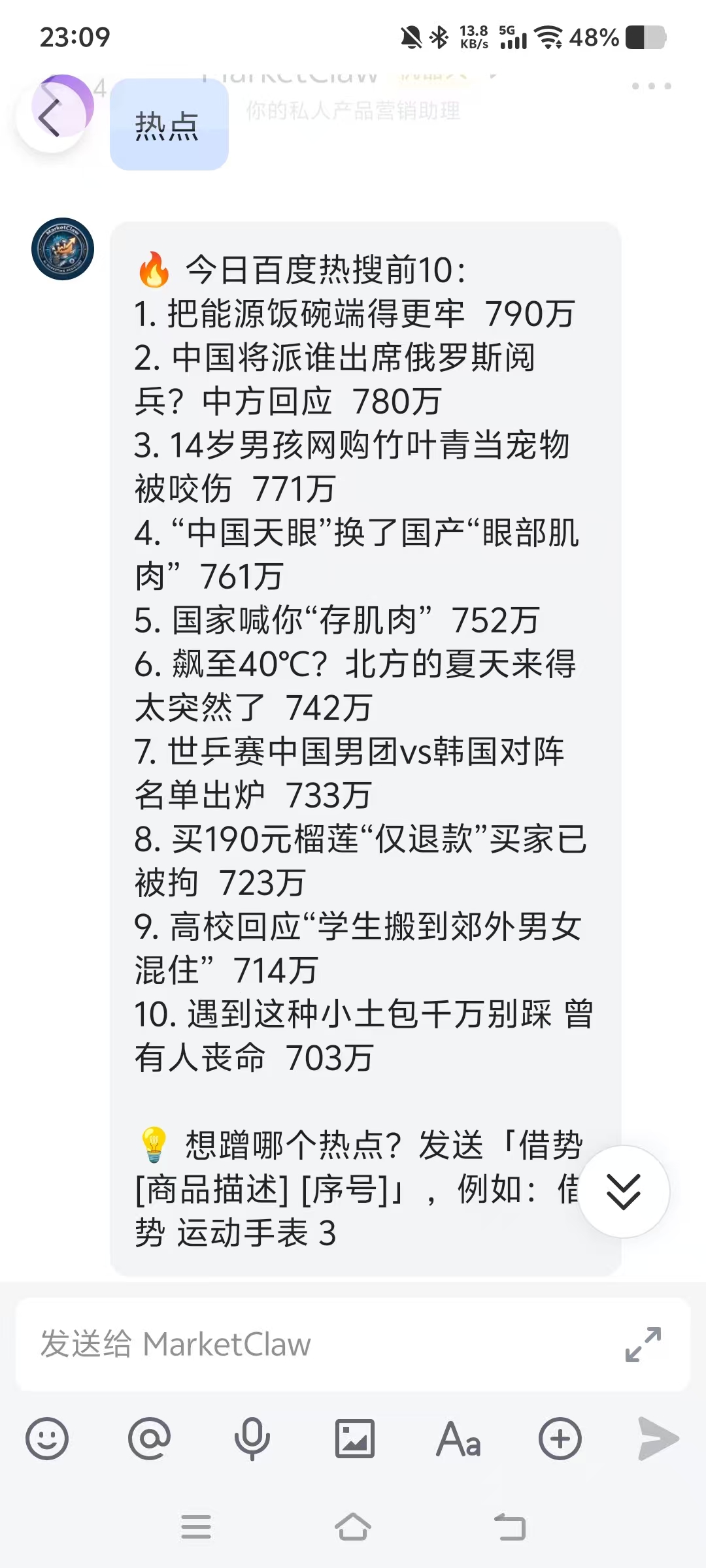
机器人返回了完整的前10条热搜,每条都带有序号和热度值,最后还提示如何借势。
3.2 热度趋势对比(飙升榜)
单纯的静态榜单缺乏时效性指导。我实现了一个轻量级的趋势对比功能:将每次获取的热搜快照保存在本地JSON文件last_hot.json中。用户再次请求“热点趋势”时,对比当前热度与上一次快照,计算每个话题的热度增量,并输出上升最快的前三条。
核心逻辑:
def get_hot_trend():
current = get_baidu_hot_realtime(10)
last_snap = load_last_snapshot()
if not last_snap:
save_snapshot(current)
return "首次查询,已保存基准数据。请再次发送「热点趋势」查看变化。"
trends = []
for item in current:
if item['title'] in last_map:
delta = float(cur_val) - float(last_val)
if delta > 0:
trends.append(...)
save_snapshot(current)
return 排名前三的上升话题
例如第二次查询会返回:“📈 热度上升最快的话题:1. 把能源饭碗端得更牢 +12.3万 (790万) ……” 这能直观告诉用户哪些话题正在快速发酵,值得优先借势。
3.3 借势营销:用户主动选择热点生成文案
早期我曾尝试用关键词匹配算法自动推荐相关热点,但实际测试发现商品关键词(如“运动手表”)与热搜标题(“把能源饭碗端得更牢”)交集几乎为零,匹配度永远是0%,功能形同虚设。因此我改变了交互模式:让用户自己选择想蹭的热点,机器人则负责生成结合该热点的文案。
具体流程:
-
用户发送“热点” → 机器人返回带序号的热搜列表。
-
用户发送“借势 商品描述 序号” → 机器人根据序号选取该条热搜,调用大模型生成融合热点的营销文案。
飞书消息处理代码片段:
if user_text.startswith("借势 "):
parts = user_text.split()
product_desc = ' '.join(parts[1:-1])
idx = int(parts[-1])
hot_list = get_baidu_hot_realtime(10)
selected_hotspot = hot_list[idx-1]['title']
reply = generate_copy_with_hotspot(product_desc, selected_hotspot)
generate_copy_with_hotspot 函数专门构造DeepSeek提示词,要求模型产出的小红书文案必须巧妙融入所选热点:
system_prompt = f"""你是一个专业的小红书营销文案生成助手。用户需要为商品「{product_text}」写一篇种草笔记,并且要求结合当前热搜话题「{hotspot_title}」。
请严格按照JSON格式返回标题、正文和标签,正文中自然融入热点,标题最好包含热点关键词。"""
四、真实测试效果
我在飞书上进行了多轮测试,以下是一些截图:
-
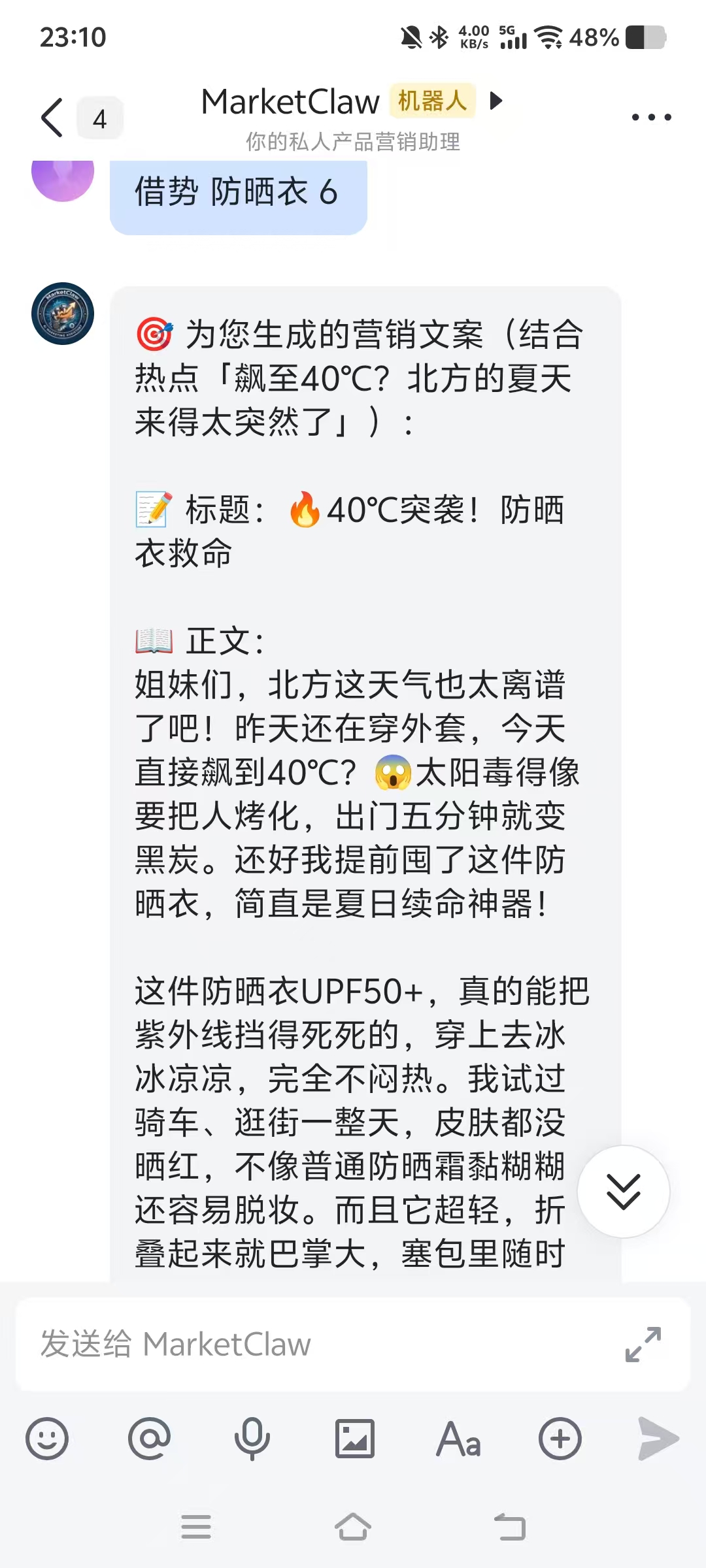
借势防晒衣:发送“借势 防晒衣 6”,第6条热搜是“飙至40℃?北方的夏天来得太突然了”。机器人生成的文案标题为“40°C突袭!防晒衣救命”,正文结合高温天气,突出了防晒衣的UPF50+、冰凉不闷热等卖点。
-
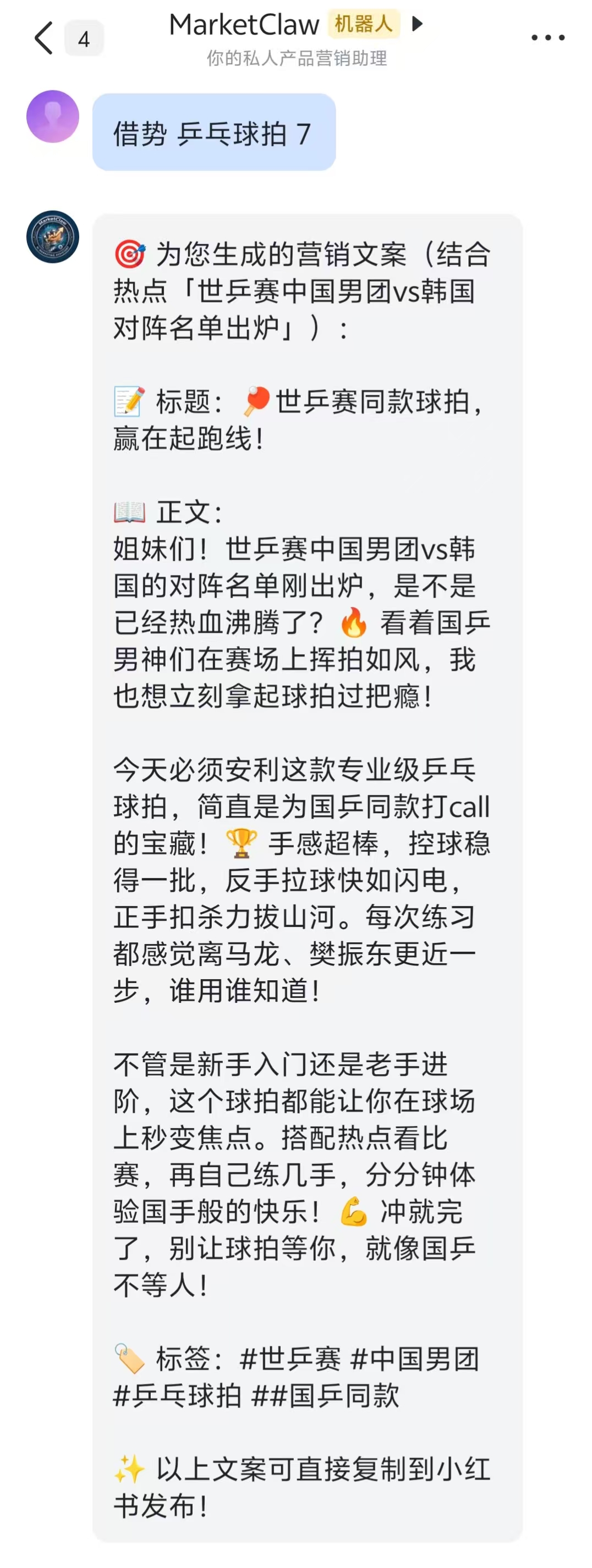
借势乒乓球拍:发送“借势 乒乓球拍 7”,第7条热搜是“世乒赛中国男团vs韩国对阵名单出炉”。生成的文案标题为“世乒赛同款球拍,赢在起跑线!”,正文借势国乒热度,专业又燃。
-
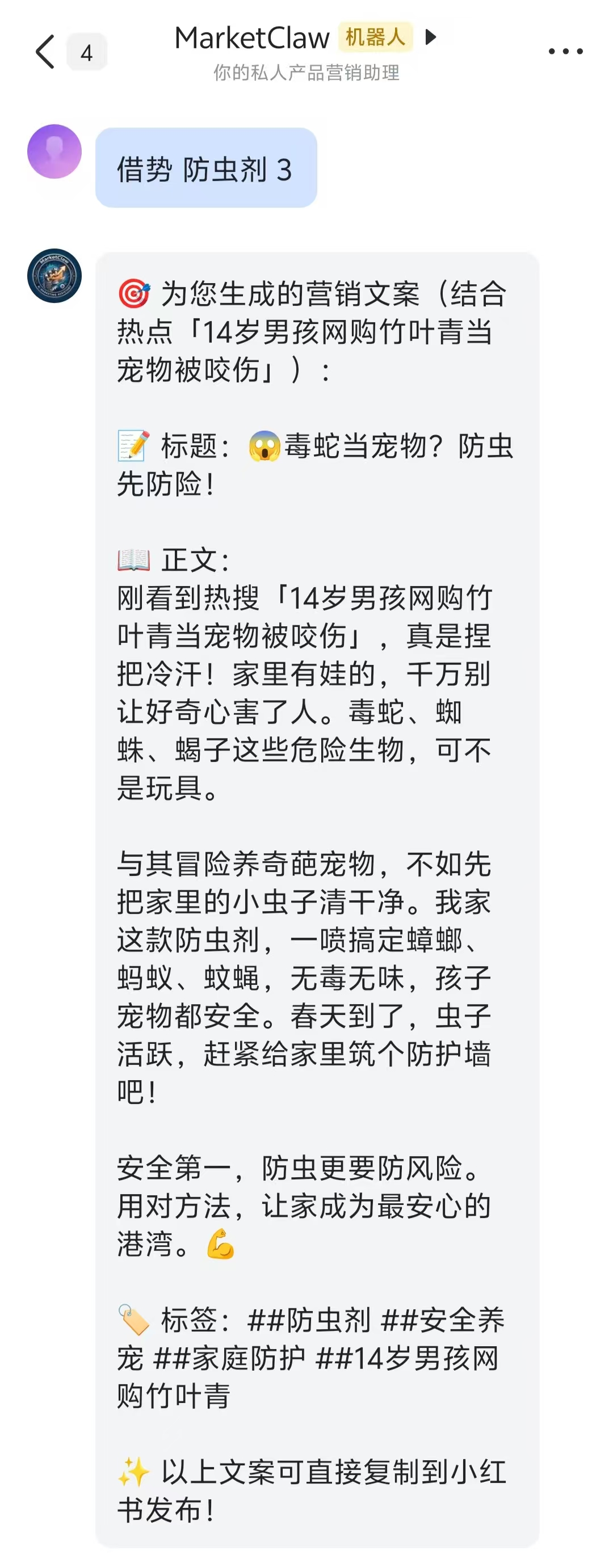
借势防虫剂:发送“借势 防虫剂 3”,第3条热搜是“14岁男孩网购竹叶青当宠物被咬伤”。机器人巧妙地将毒蛇风险转化为家庭防虫需求,文案标题“毒蛇当宠物?防虫先防险!”,安全又贴心。
所有文案均包含标题、正文和标签,格式完全符合小红书风格,可直接复制发布。
五、集成到飞书机器人
所有功能均已集成到bot.py的主消息处理函数do_p2_im_message_receive_v1中。机器人当前支持以下命令:
-
热点/热搜→ 返回百度热搜前10(带序号) -
热点趋势/趋势→ 返回热度上升最快的前3个话题(需要两次以上调用) -
借势 商品描述 序号→ 生成结合指定热点的营销文案(商品描述可含空格,序号来自热点列表) -
商品:xxx→ 普通文案生成(不带热点)
机器人回复使用飞书OpenAPI的HTTP接口,稳定可靠。同时保留了防重复请求机制,避免短时间内重复处理相同消息。
六、踩坑与解决
| 遇到的问题 | 解决方案 |
|---|---|
| 百度热搜页面反爬,requests返回403或空内容 | 放弃爬虫,改用稳定聚合API |
| 聚合API偶尔失效(uapis.cn、xygeng.cn) | 切换到api.52hyjs.com,并预留多源备用 |
| 自动匹配算法匹配度为零 | 改为用户主动选择热点序号,人机协作 |
| WSL环境代理不通导致请求超时 | 配置http_proxy环境变量指向Clash端口 |
| DeepSeek有时返回非JSON格式 | 增加正则抽取和json容错解析 |
七、总结
本次工作完成了任务书Skill2(热点信息采集)的全部核心要求,并创新性地实现了“借势”文案生成,将热点数据与营销内容深度结合。整个模块从写爬虫失败到改用API,从自动匹配改为用户选择,经历了不少波折,但最终效果令人满意。现在,我的MarketClaw机器人不仅会写文案,还学会了“蹭热度”——而这正是智能营销助手的应有之义。
博客代码仓库:https://gitee.com/cusir666/MarketClaw
个人博客:https://blog.csdn.net/2401_83356673

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)