PaperMind:学术论文阅读平台开发(二)
摘要:
上周我们完成了 PDF 解析功能,通过 MinerU 实现了文献内容的自动解析,并通过前端渲染对解析结果进行修复,修复了 LaTeX 公式渲染乱码的问题。
本周在此基础上继续推进。首先完成了文献解析的收尾工作——从解析后的 Markdown 中提取论文的标题、作者、期刊来源、发表时间等元数据,并在前端展示。其次,为后续的智能问答、文献检索、学术翻译等复杂功能做铺垫,搭建了 LangGraph 多智能体框架,定义了 Router 意图路由和 QA、Retrieval、Translate 等 Agent 节点,接入了 DeepSeek LLM 和本地 Embedding 模型,完成了论文分块向量化入库(ChromaDB)的流程。同时重构了前端页面,加入了功能导航栏,将平台从单一的解析工具升级为多功能的学术分析平台骨架。
一:实现文献作者,期刊等信息
首先是回答标题、作者、期刊是怎么拿到的?我们的PDF 经过 MinerU 解析后得到的其实是一份 Markdown 文本,里面没有结构化的"标题""作者"字段,就是一堆文本。因为在学术文献场景喜爱的PDF,这些信息一般都是在文档的开头处,因此我实现这个功能的时候没有使用LLM进行理解分析提取,而是选择使用正则匹配, 这样的方式我个人认为来说应该是更容易实现,元数据提取需要在每次解析完成后自动执行,如果调 LLM 就多了一次 API 请求的延迟和费用。同时由于论文元数据的格式虽然多样,但规律性还是比较强的,正则 + 启发式规则能覆盖大部分情况。
我们的做法是:先定位一些看起来像作者行的文本(在标题之后、摘要之前的区域),排除掉邮箱行和明显是机构名的行,然后用正则把上标数字、星号等标注符号去掉,按逗号或多空格切分得到人名列表。
这个过程在开发过程中迭代了好几轮,由于这个功能比较简单,ai可以直接编码完成,因此我选择使用cursor,调取里面的claude4.6opus模型,并告诉他我想要做的事情,给的提示词如下:
我们现在使用Mineru已完成对PDF文献的解析,接下来需要你对我们的解析结果实现一个附加功能,找到文献中的作者,发表时间,发表期刊等元数据,然后显示在我们文献解析的头部,虽然是较简单的功能,但是最后也是迭代了好几轮,才成功实现,具体遇到了如下一些问题:第一版把邮箱识别成了作者名,第二版把"Peking University"这种机构名带了进来,后来加了机构关键词过滤才基本稳定
最后成功实现之后我们的识别结果如下图所示:

二:Langgraph框架的介绍
由于我们的后序功能需要使用到多个agent以及他们之间的协同工作,及一些简单的代理功能,因此我们在了解后认为Langgraph框架是必要的,在搭建Langgraph框架之前需要知道Langgraph框架是什么,以及他能干什么?
2.1为什么选择的是Langgraph
考虑过几个方案:
纯 if-else 分发:能跑,但扩展性差。每加一个 agent 就要在分发逻辑里加分支,agent 之间如果有依赖关系(比如先检索再总结),代码会迅速耦合,现在有的agent一般来说都会选择一个合适的agent编排架构(目前我知道的有langchain和朗),而不是if-else分支判断。
LangChain Agent + Tools: LangChain 的 Agent 模式是让 LLM 自己决定调什么工具。听起来很智能,但实际用下来有两个问题:一是 DeepSeek 对 function calling 的格式支持不太稳定,经常解析失败;二是学术场景下我们很清楚有哪几类任务,不需要 LLM 自由发挥,反而需要流程可控。
LangGraph StateGraph: 显式定义节点和边,流程由我们控制,LLM 只负责"判断意图"这一步。节点之间通过共享状态传递数据,加新 agent 就是加一个节点 + 一条边,不影响其他节点。
最终选了 LangGraph,核心原因:流程是我们定义的,不是让 LLM 自己决定调什么工具。 可控性 > 灵活性
2.2Langgraph定义:
LangGraph 是由 LangChain 团队开发的 基于状态机的 Agent 编排框架,专为构建复杂、可循环、多步骤、带条件分支的 AI 工作流而设计。它是对传统线性 Chain 和简单 Agent 的重大升级,特别适合需要规划、反思、协作或多轮迭代的任务。
简单理解为:它让你用“图(Graph)”的方式定义 Agent 的执行流程 —— 节点是动作,边是跳转逻辑,状态在节点间传递。
本质上 LangGraph 就是一个状态机框架。 你定义一组节点(Node),每个节点是一个处理函数;定义节点之间的边(Edge),决定执行顺序;所有节点共享一个状态对象(State),通过读写状态来传递数据。
和传统状态机的区别在于:边可以是条件的——由一个函数根据当前状态动态决定下一步走哪个节点。这个"条件分发"能力就是 LangGraph 最有用的地方。
2.3几个核心概念:
StateGraph:整个图的容器。你往里面加节点和边,最后 .compile()得到一个可执行的图。
State:一个 TypedDict,在所有节点之间共享。每个节点从 state 里读取输入,处理完把结果写回 state。这里理解的话是节点之间唯一的通信方式——不是函数调用,不是消息队列,就是读写同一个字典。
Node: 一个 (state) -> state的函数。接收当前状态,返回更新后的状态。节点不知道也不关心自己前面是谁、后面是谁,只管处理自己的逻辑。这样做的好处是让agent之间完全接偶尔,使得他们是一个独立的agent
Conditional Edge):从一个节点出发,根据一个路由函数的返回值决定下一步走哪个节点。路由函数也是读 state 里的字段来做判断。在我们的场景里,Router 节点把 intent 写入 state,条件边读 intent 的值来分发。
END: 特殊的终止节点,表示图执行结束。
同时这里也可以和另一个agent框架langchain对比:
LangChain Agent 是LLM 自己决定下一步做什么(ReAct 模式),适合开放式任务;LangGraph 是我们定义好所有可能的路径,LLM 只负责在岔路口选方向,适合流程明确的任务。我们的场景明显是后者——学术平台就那几类操作,不需要 LLM 自由发挥。
三、我们项目的Langgraph的设计以及实现过程
3.1完整示意图
我们项目的整个agent协作关系大概如下所示:
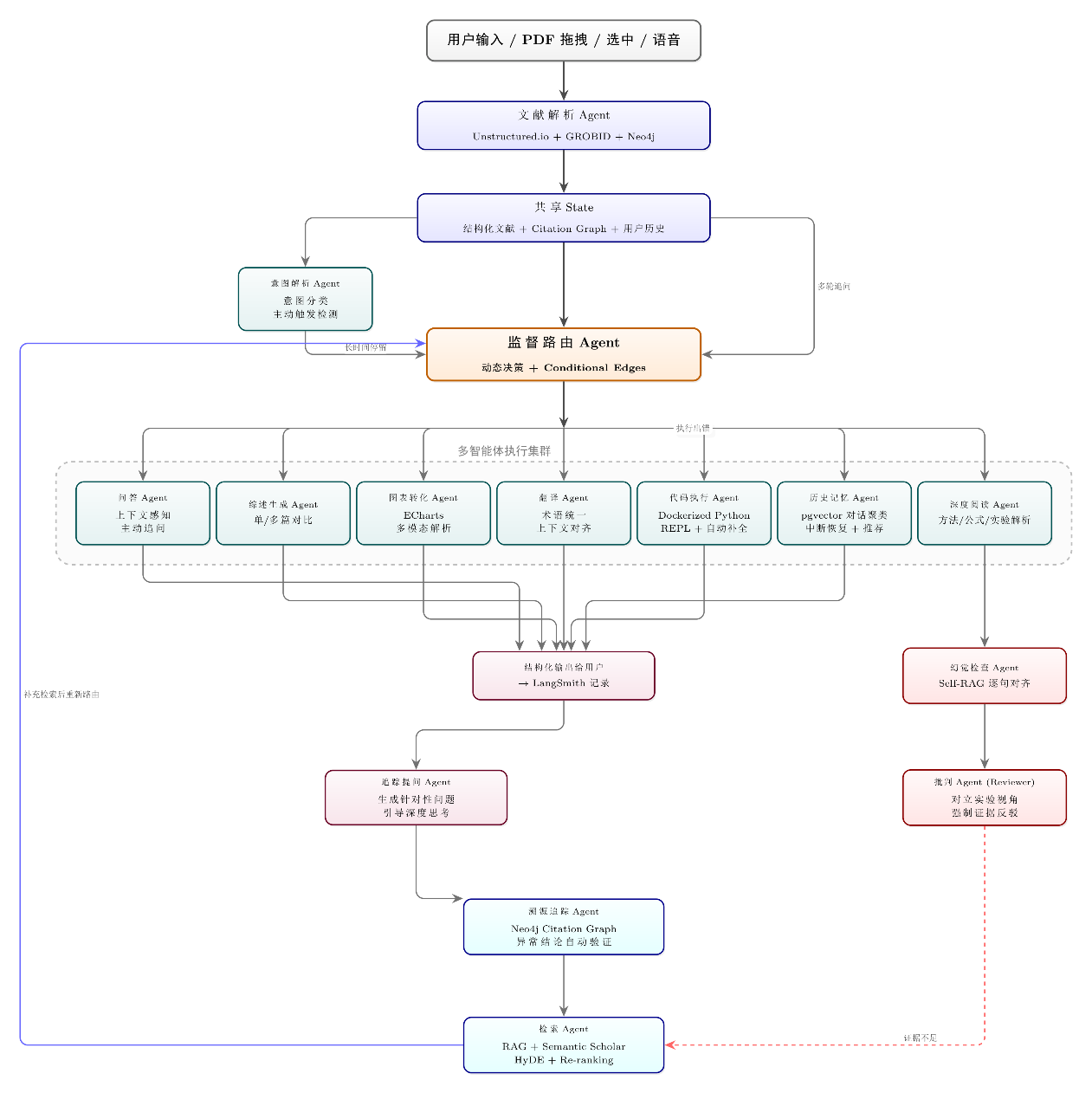
3.2本周实现的示意图:
本周我们进行了一些简单的实现,还不完全与上述我们设计一致,
我们目前实现的大概如下所示,后续会逐步迭代到上述我们的最初构想:
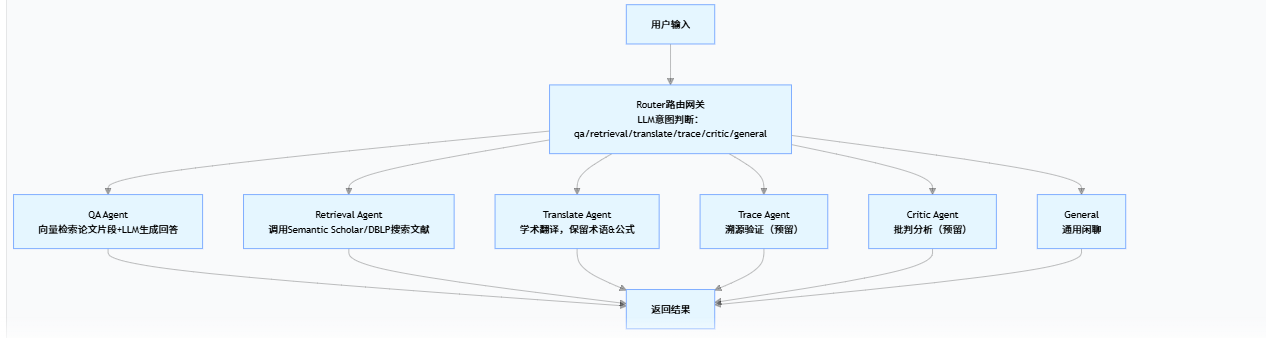 我们目前实现的几个关键设计决策如下:
我们目前实现的几个关键设计决策如下:
Router 用 LLM 分类而不是规则匹配。比如用户说"这个公式怎么推导的"和"帮我把 abstract 翻译成中文",靠关键词匹配很难覆盖所有表述方式,LLM 天然理解语义意图。Router 的 prompt 就是列出所有类别和说明,让 LLM 只返回类别名,不解释。
fallback 到 qa 而不是 general。 如果 Router 返回了不在合法列表里的值,我们默认走 QA 而不是通用闲聊。因为用户大多数时候是在问论文相关的问题,宁可多走一次 RAG 检索也不要给一个不着边际的回答。
所有节点共享一个 AgentState。 这是一个 TypedDict,包含 query(用户输入)、intent(路由结果)、paper_id(当前论文)、paper_context(检索到的片段)、response(最终回复)。每个节点只读自己需要的字段、写自己的输出,互不干扰
3.3关于Langgraph的组装:
LangGraph 的 API 比想象中简洁。核心就三步:
1. 注册节点:每个 agent 函数注册为一个节点
2. 设置入口: 指定 Router 为入口节点
3. 添加条件边:Router 根据 intent字段的值分发到不同节点,所有 agent 节点执行完直接到 END
加一个新 agent 只需要:写一个 (state) -> state的函数,注册为节点,在条件边的 mapping 里加一条。不需要改任何已有节点的代码。
有个小细节:LangGraph 节点函数签名是 (state) -> state,但我们的 agent 都需要 settings 参数来获取 LLM 实例。用 functools.partial提前绑定 settings,LangGraph 调用时只传 state。
四、QA Agent 的 RAG 流程
QA Agent 是最核心的节点,也是最能体现智能体不只是调 API的地方。它的流程大概为:
1. 用户问题通过 embedding 模型转成向量
2. 从 ChromaDB 向量库里检索当前论文最相关的 5 个片段
3. 把检索到的片段拼成上下文,和用户问题一起发给 DeepSeek LLM
4. LLM 基于这些真实的论文内容生成回答
后续我们会继续改进到类似本地的效果,及该agent可以直接知道我们的文献全文,而不是一些片段,当前只是片段有一个问题就是在于他对文献的解读是不可能全面的,只能是片面的,因为对agent来说,他只知道的是文献的片段部分,对全文没有充分的理解与思考,但是由于本周的工作量较大,因此这里就先暂时进行这样的实现,相当于一个小demo
这里有个容易混淆的点:embedding 模型和 LLM 是两个独立的东西。 Embedding 只负责搜索——把文本变成向量用来算相似度,找到和问题最相关的论文段落。LLM 负责思考——理解问题和上下文,生成回答。回答质量取决于 LLM,embedding 影响的是找得准不准。
我们的 embedding 用的是本地的 all-MiniLM-L6-v2(22MB),CPU 上跑一次只要 10-30ms。LLM 用的是 DeepSeek Chat,通过 OpenAI 兼容接口调用。
五、本周开发过程中的一些小问题:
5.1、依赖版本连锁反应
装 sentence-transformers时,pip 自动把 torch从 2.5.1 升到了 2.11.0,transformers 从 4.52 升到了 4.57。结果 MinerU(PDF 解析引擎)在新版 torch 下行为异常,解析直接失败。
一个 pip install搅乱了整个依赖树。解决方法是锁定版本:pip install sentence-transformers<4",然后手动恢复 transformers 版本。教训是:在有复杂依赖的项目里,装任何新包之前先看看它会拉什么依赖。
5.2subprocess 管道死锁
MinerU CLI 解析 PDF 时会输出大量日志(进度条、模型加载信息)。之前用 subprocess.run(capture_output=True)把 stdout 缓存到内存管道。问题是管道缓冲区只有 64KB,MinerU 的日志远超这个量,缓冲区满了子进程写入阻塞,父进程在等子进程结束——经典的管道死锁。
解决:ai告诉我的解决办法是把 stdout/stderr 重定向到文件而不是内存管道。并且后来我也查阅了一些博主的介绍,关于这个问题这是 subprocess 的常见坑,但不踩一次真想不到。
最后是本周实现的大概的成果展示:
首先便是本周的文献作者期刊等的提取:

之后是实现的Langgraph架构,以及一些小的还有待改进的agent
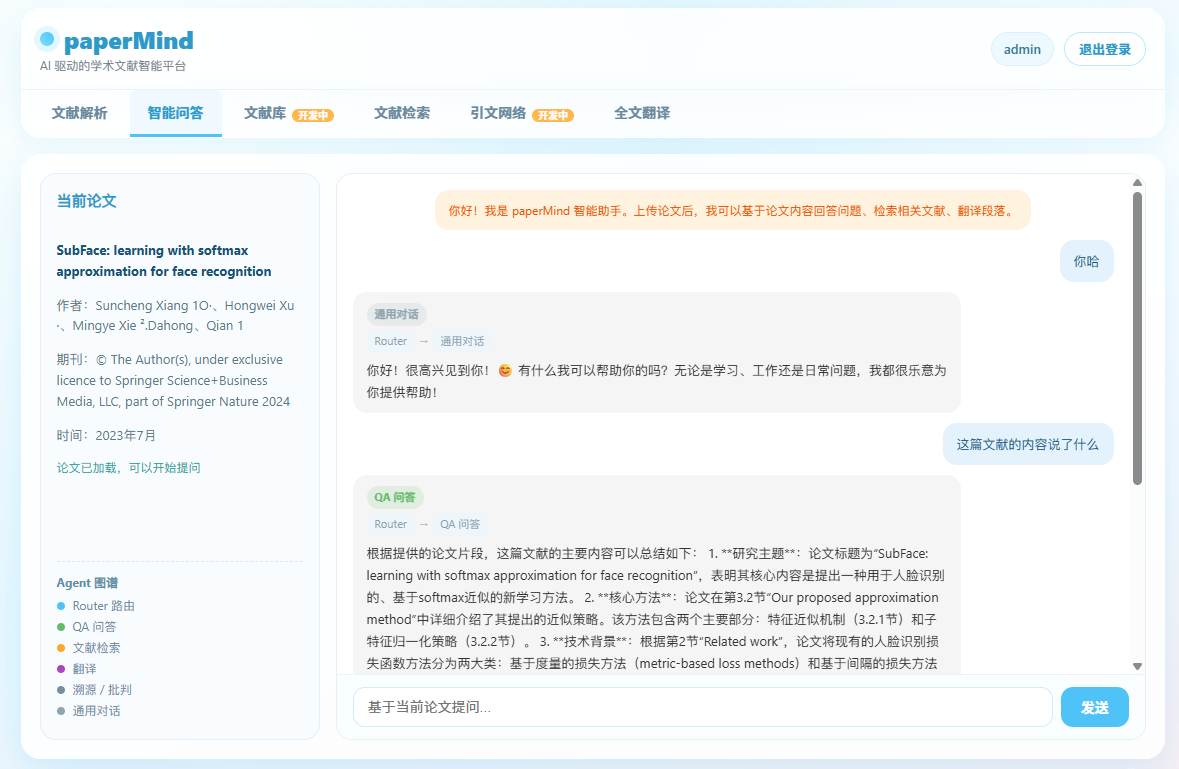
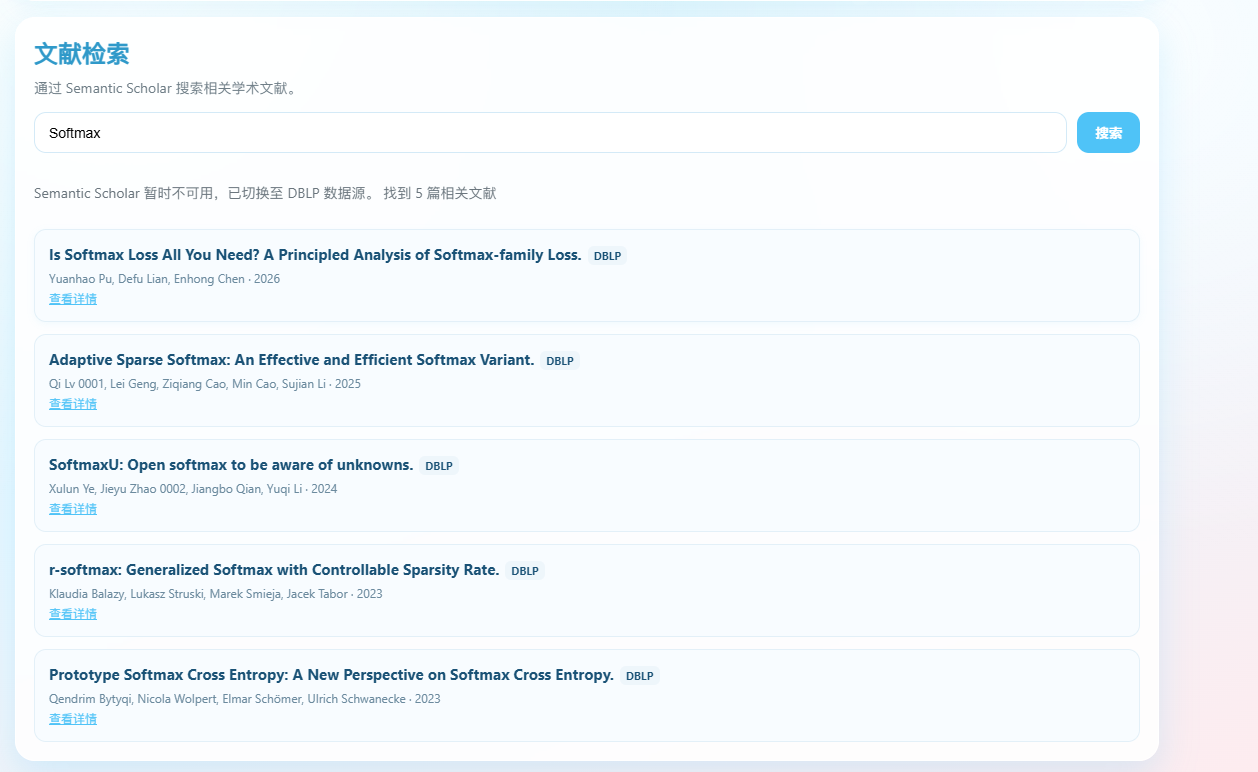
可以看到我们目前的实现QAagent已经可以基于我们上传的文献进行一些简单的问答,等之后的深度解读agent完善之后,便可以进行详细的问答。之后是一个简单未经agent筛选的相关学术文献搜索功能:我搜索Softmax便会返回一些列相关文献,后续将考虑使用agent进行智能筛选与推荐,而不是仅仅简单检索,同时我们目前实现了返回之后查看详情就可以直接跳转到原文献的地址,并进行查看:
以上便是本周的工作总结以及开发过程中的一些心得,包括对Langgraph的学习与理解等等

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)