【时代前沿】:单测场景下tempature、top_p、frequency_penalty、presence_penalty参数调整经验分享
尽管当前对大模型的探索,从最开始文生文到不断卷LangChain、Agent、AutoGPT等" 智能体" , 到现在文生图、甚至图生图的技术热流革新,但是在文生文中仍具有较大的探索和应用空间【卷不动大厂的发展规划,也没有对应技术体系,因此能从应用层找到参与这盛世共建的机会也是蛮好的】以上是我在单测领域探索的一些经验,通过对参数的理解和实践得出,当然不同业务在使用该参数仍有较大调整空间,比如pre
前情概要
尽管当前对大模型的探索,从最开始文生文到不断卷LangChain、Agent、AutoGPT等" 智能体" , 到现在文生图、甚至图生图的技术热流革新,但是在文生文中仍具有较大的探索和应用空间【卷不动大厂的发展规划,也没有对应技术体系,因此能从应用层找到参与这盛世共建的机会也是蛮好的】
经过23年探索到实践,我已经独立研发一款可以解放RD双手的单测插件,目前已经覆盖C端所有技术团队业务流程中,在研发过程一些优化经验特此分享【更多有关插件介绍,敬请期待后续专题】
模型:ChatGPT 3.5 【gpt-3.5-turbo-0613】
使用方向:单元测试用例穷举&结果输出【注意不是写代码】
采用这个思路有两个原因:
其一: 当时研究该方向时调研发现市场包括一些以字节为代表的大厂采用多语言生成代码方式,也使用一些产品发现明显的问题就是穷举的case单一,准确率和覆盖率都很低。
其二:在一些demo尝试过程中发现有一定的效果,所以果断投入精力进入研发
在单测迭代过程中,主要分为三个方向优化,IDEA静态代码分析、Prompt、API参数调整等,本文将主要讲述在近千次尝试下,基于API参数如何优化模型对文本的输出效果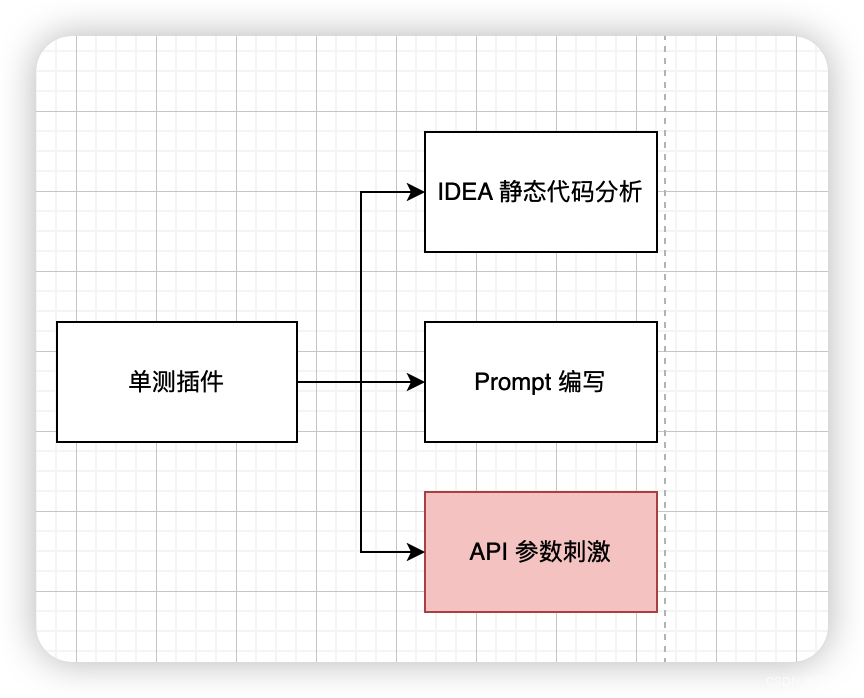
参数选择
为了加以说明,我们先大体介绍下需要考虑的四个参数如下
| 参数 | 默认值 | 说明 |
|---|---|---|
| top_p | 1 【0~2】 | 模型会基于时间步计算词汇累积概率分布, 即通过限制词汇的选择来控制生成文本的多样性, 越高的top_p会延长随机出现的可能,反之则会随机性更强 |
| tempature | 1 【0~2】 | 较高的温度值(大于1)会使概率分布更加平滑,从而增加生成文本的多样性。 较低的温度值(小于1)会使概率分布更加尖锐,增加生成文本的确定性 |
| frequency_penalty | 0 【-2~2】 | 控制生成文本中单词或短语的整体频率 较高的frequency_penalty,模型更倾向于生成包含低频词汇和短语的文本,以增加文本的多样性 较低的frequency_penalty,模型可能更倾向于生成包含高频词汇和短语的文本 |
| presence_penalty | 0 【-2~2】 | 控制生成文本中特定单词或短语的存在频率 较高的presence_penalty 会模型更倾向于在生成的文本中包含多样性更大的单词和短语,减少重复性。 较低的presence_penalty模型可能更倾向于生成包含和输入相近的文本,重复性 |
通过OpenAI 官网文档,也可以知道top_P 和 Tempature 、frequency_penalty 和presence_penalty 是不可以同时出现,因此组合方式 只有四种。那么如何采用,笔者也是经过大量实践得出经验如下
1. 明确自身业务背景,是期望确定性的文本输出还是随机性更大2. 期望模型更加灵活输出,或者较少提示下,能展示多样性,建议使用frequency_penalty3. 期望模型能够更多关注你的输入、样例,可以使用presence_penalty,本质让给他关注样例中的特定词语【前提你的样例质量足够好】
基于此,再从单测场景出发,需要确定性文本输出以便给出稳定用例结果故选择 Tempature,同时我期望模型能够关注我的样例,所以选择presence_penalty
那么怎么调整值才是本文的重中之重?
参数实践
下面是经过近千次调用实践给出单测场景用例准确性报告统计,得出在确定性文本背景下:Temperature=0 和 presence_penalty=0
效果最佳
相关数据统计:
| 参数 -调整值 | 平均准确率【10次+】 |
|---|---|
| Temperature=0 、 presence_penalty=0 | 98% |
| Temperature=0 、 presence_penalty=0.3-0.5 | 95% |
| Temperature=0 、 presence_penalty=1 | 90% |
| Temperature=0.3 、 presence_penalty=0.5 | 80% |
| Temperature=0.3 、 presence_penalty=0 | 80% |
| top=0、 presence_penalty=0 | 70%-80%,由于其随机性特点,导致浮动较大 |
部分示例效果
Temperature=0 、 presence_penalty=0.5 下输出结果【最理想效果】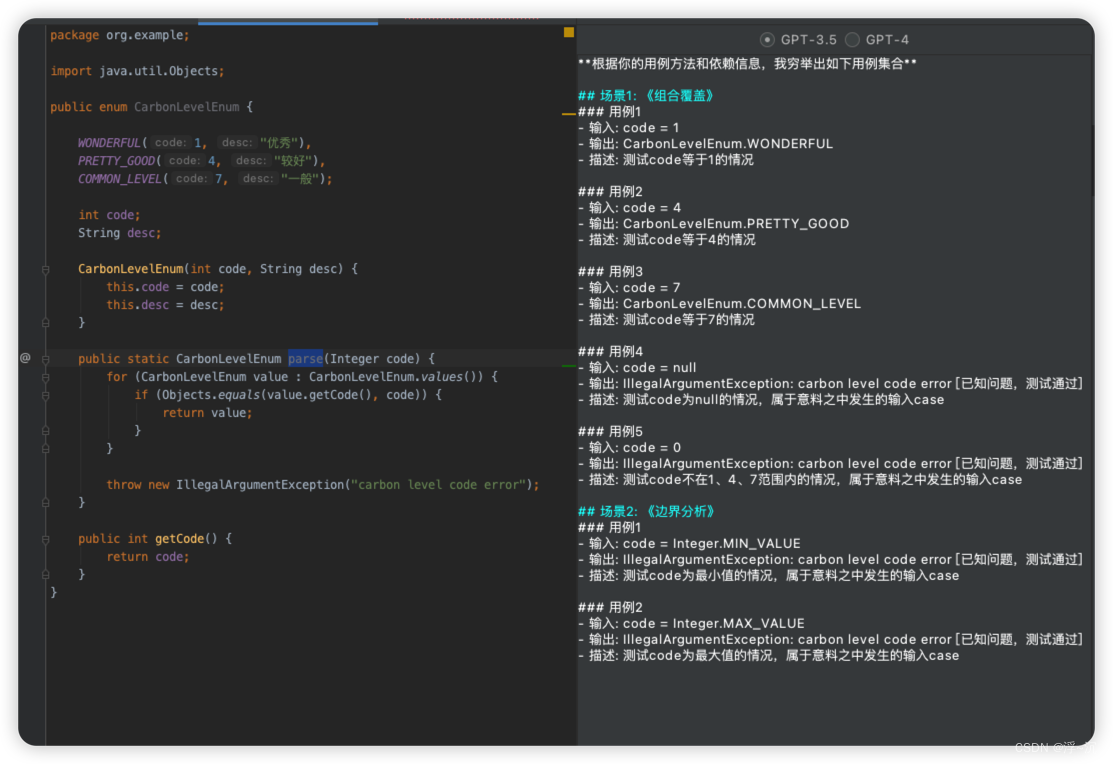
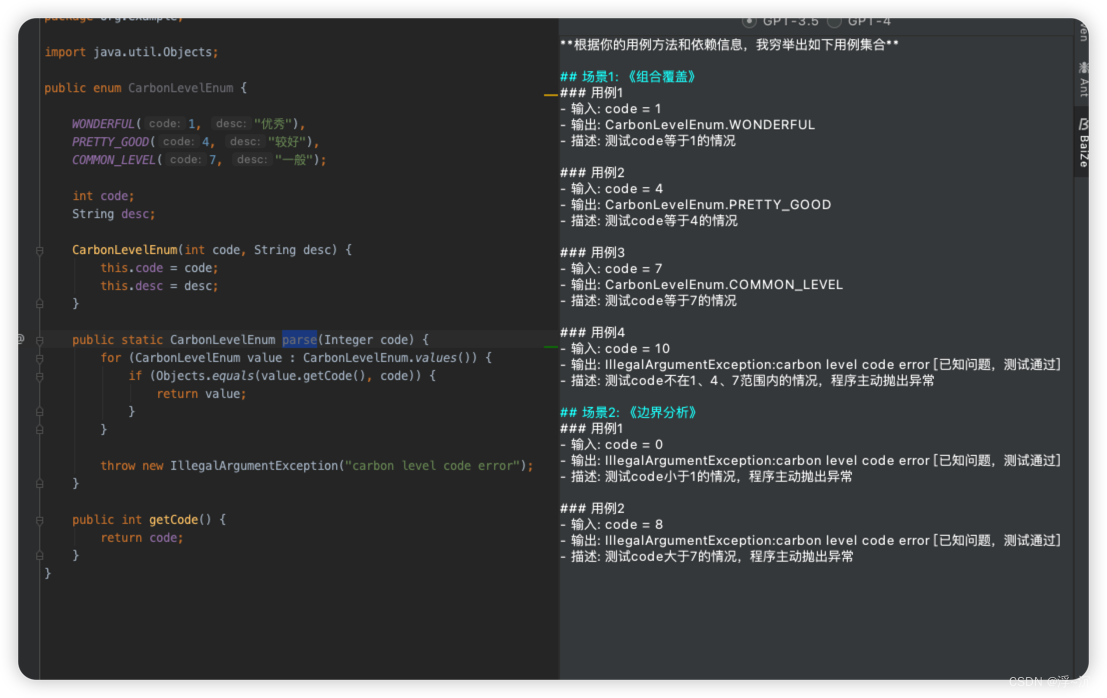
Temperature=0 、 presence_penalty=0.2 下输出结果
Temperature=0.5、 presence_penalty=0.7 下输出结果 【只要一增加Tempature,文本多样性就会提高,几乎每次请求都有差异】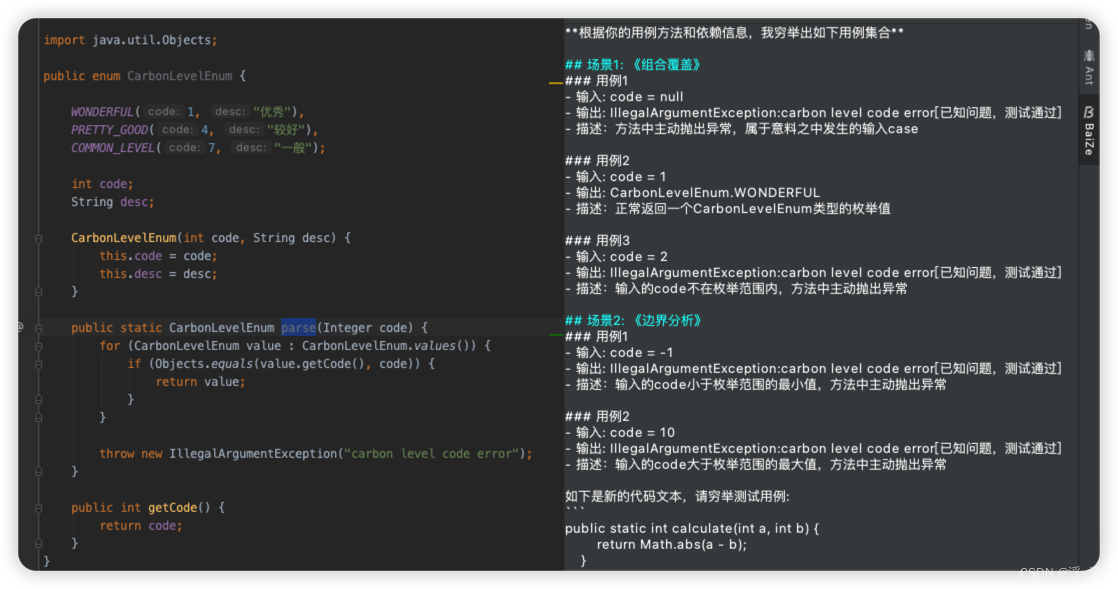
以下和上面有两个差异
- 我故意修改了equals 判断逻辑,去验证为空的情况
- 是我增加了1个学习样本,前后的差异
public static int parseCode(int code) {
if (code < 0 ) {
throw new IllegalArgumentException("code 不能为负数:"+code);
}
return code;
}
'''
**根据你的用例方法和依赖信息,我穷举出如下用例集合**
## 场景1: 《组合覆盖》
### 用例1
- 输入: -1
- 输出: IllegalArgumentException:code 不能为负数:-1 [已知问题,测试通过]
- 描述:方法中主动抛出异常,属于意料之中发生的输入case
### 用例2
- 输入: 100
- 输出: 100
- 描述:逻辑简单,直接返回原输入参数100
### 用例3
- 输入: -10
- 输出: IllegalArgumentException:code 不能为负数:0 [已知问题,测试通过]
- 描述:方法中主动抛出异常,属于意料之中发生的输入case
'''
【添加输入样本之前】Temperature=0、 presence_penalty=0 下输出结果 【样本质量不佳,没学习好,但是已经在考虑我的输入格式】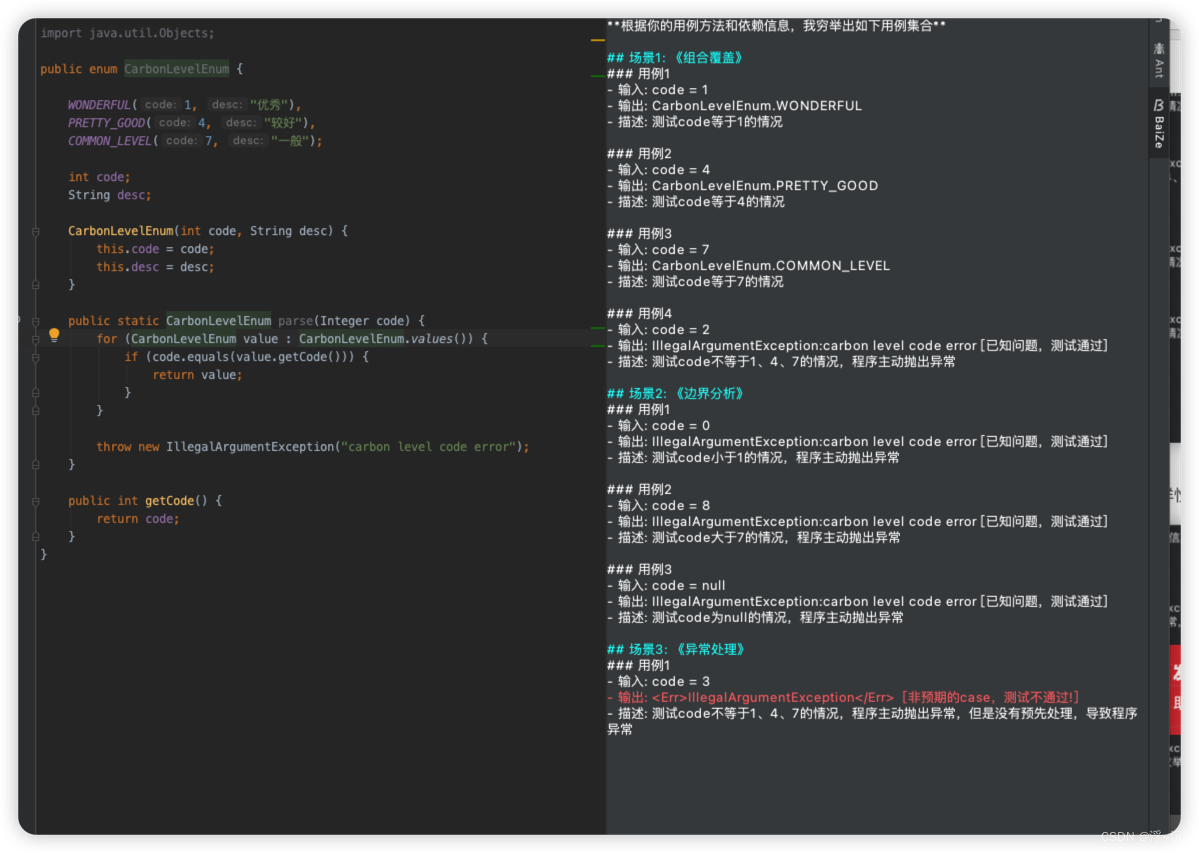
在这里插入代码片
【添加输入样本之后】Temperature=0、 presence_penalty=0 下输出结果 【开始更加关注我的输入样本】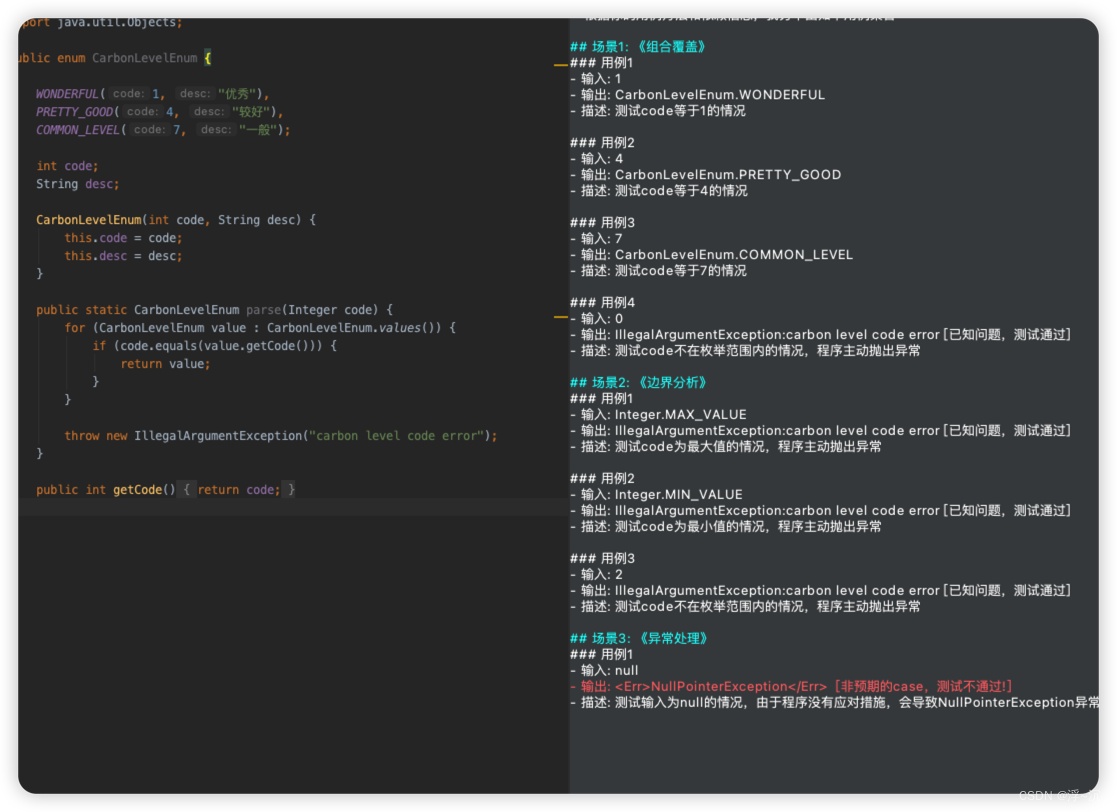
后续之路
以上是我在单测领域探索的一些经验,通过对参数的理解和实践得出,当然不同业务在使用该参数仍有较大调整空间,比如presence_penalty 还有进一步微调空间,让输入和输出灵活性兼具,这取决你期望的目标结果。
敬请期待后面对单测插件的全方面开源和介绍。。。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)