【宠粉赠书】大语言模型:原理、应用与优化
在数字化时代,大模型已经成为技术和商业领域的焦点。《大语言模型:原理、应用与优化》围绕个性化、多功能以及多模态这三大发展方向进行解读,列举大模型的现状与挑战,分析改进与发展趋势,并畅想未来应用场景,以提供一种前瞻性视角,对大模型的应用部署及优化提供一些参考。小智为回馈粉丝们的支持,特意准备了这本专业书籍,希望能带你走进大语言模型的世界。
在数字化时代,大模型已经成为技术和商业领域的焦点。《大语言模型:原理、应用与优化》围绕个性化、多功能以及多模态这三大发展方向进行解读,列举大模型的现状与挑战,分析改进与发展趋势,并畅想未来应用场景,以提供一种前瞻性视角,对大模型的应用部署及优化提供一些参考。小智为回馈粉丝们的支持,特意准备了这本专业书籍,希望能带你走进大语言模型的世界。接下来我将详细介绍这本书的内容,文末会附上领取方式。
一、图书介绍
在训练大规模模型时,除了采用分布式训练降低单节点内存使用之外,还有一些其他的内存优化策略。
首先我们分析一下 训练过程中内存的开销,主要可分为以下4部分。
模型参数:神经网络权重。
优化器状态:与优化算法相关,不同算法需要不同的中间变量存储。
中间结果:前向计算得到的激活中间结果,存储待反向传播时计算梯度使用。
临时存储:模型实现中的其他计算临时变量,用完后尽快释放。
其中,模型参数与临时存储在训练和推断中都需要,而优化器状态和中间结果仅在训练中使用。
本文将介绍的几种显存优化方案从模型训练本身入手,对上面一个或多个部分进行优化:
混合精度训练可以优化模型参数、优化器状态和中间结果存储
梯度检查点和梯度累积主要优化中间结果存储
FlashAttention是专为处理Transformer中的注意力层内存限制而设计的
混合精度训练
更大的模型需要更多的计算和存储资源进行训练和推理,而模型性能由3个因素决定:存储带宽、算术带宽和延迟。
降低精度可以解决前两者的瓶颈:用更少的比特存储同样参数量减少存储带宽压力,低精度计算也会带来更高的吞吐。
混合精度训练(Mixed Precision Training)可以在尽量不损失模型精度的条件下,加速模型训练并减少显存占用。同时,它也不需要改变模型结构和参数,是大模型训练的重要技术之一。
现代深度学习系统默认使用单精度(FP32)格式进行训练。所谓混合精度训练,并不是简单地将模型参数和激活精度降至半精度(FP16),这么做可能导致严重的模型精度损失或参数溢出问题。因此,混合精度训练主要解决的问题是如何在不损失模型精度的条件下使用FP16进行训练。具体来说需要结合3项技术:维护一套单精度的模型权重、缩放损失和使用FP32进行加法累积。
先回顾半精度浮点数FP16的定义,IEEE754标准定义了半精度浮点数的格式:
符号位:1bit。
指数位宽:5bit。
尾数精度:10bit。
单精度与半精度浮点数格式对比如图1所示,与单精度浮点数相比,半精度浮点数的指数位宽由8bit缩为5bit,尾数精度由23bit缩为10bit。
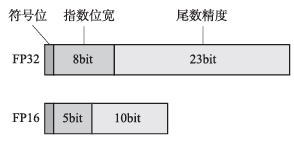
图1 浮点数定义格式
我们具体介绍混合精度训练的关键技术与细节,主要包括母版权重复制(Master Copy of Weight)、损失缩放(Loss Scaling)与精度累加(Precision Accumulated)三部分。
母版权重复制
首先,需要额外存储一套FP32模型权重,即母版权重,而中间结果如激活和梯度都存储为FP16格式。图2对神经网络中的一层的训练过程进行示意。对于一层神经网络,在每轮迭代中,先将母版权重复制成FP16格式权重(float2half),然后参与前向计算和后向计算,从而降低一半的存储和带宽开销。最后将FP16的权重梯度更新至母版权重,一轮迭代完成。
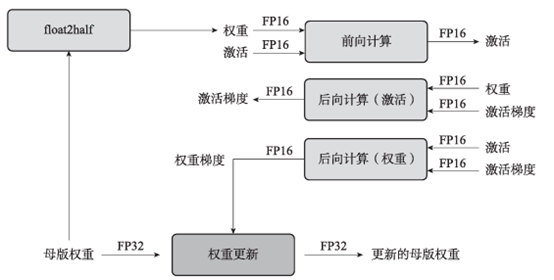
图2 混合精度训练过程示意
存储FP32的母版权重有两个原因:
-
第一,待更新的梯度值非常小,以至于FP16无法表示。经验统计,约有5%的权重更新值小于
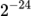
,此时更新梯度归零,影响模型精确度。
-
第二,权重值与权重更新值之间的差异过大(两者比值大于2048)时,浮点数计算右移对齐可能导致权重更新值归零。
这两种归零情况都可以通过使用FP32母版权重进行参数更新来解决。
损失缩放
虽然存储FP32参数复制会带来一些额外的存储开销,但考虑到训练过程中主要的存储开销来源于较大的批次和用于反向传播的中间结果,而这些激活值使用FP16进行存储,所以总体存储开销还是可以降低大约一半。
如图3所示,统计Multibox SSD detector network训练中所有神经网络层的梯度值,其中,梯度为0的激活值约占67%,单独表示。显然,大部分的指数表示都偏左(偏小),超出了FP16的最小表示范围,因此会归零。
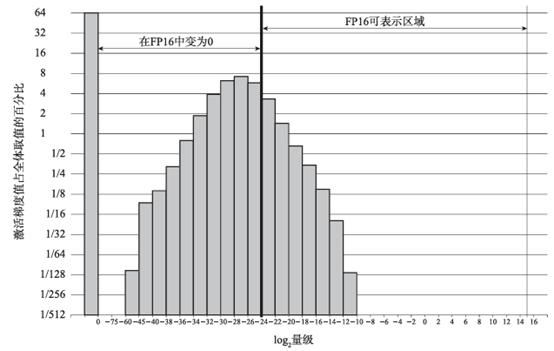
图3 Multibox SSD detector network训练梯度值柱状图
考虑到梯度取值都很小,一种简单、高效的做法是将它们在前向计算时扩大数倍,而在反向传播后更新参数前再同比缩小,从而减少计算精度损失,这种方法被称为损失缩放。
缩放的倍数选择对结果影响不大,只要缩放后的计算不产生溢出就不会对模型带来负面影响。在计算过程中如果发现有溢出,直接将本次迭代忽略即可。
对于图3中的示例,将在FP16中变为0的部分缩放至FP16可表示区域即可,即缩放倍数为8(将
![]()
平移至
![]()
)即可达到与FP32训练相同的模型准确度,这在一定程度上说明当梯度小于
![]()
时,这些更新对模型精度的影响已然微乎其微,而处于
![]()
之间的梯度更新对最终结果有显著影响。
精度累加
最后,点乘和向量元素累加归约算术操作(如批归一化和Softmax)需要用FP32格式,而在写入内存前转换成FP16,可以减少模型精度损失。在训练过程中,这些运算的瓶颈是存储带宽,变为FP32后虽然算术操作速度本身变慢,但对总体的训练速度影响不大。
表1对混合精度训练的性能进行了对比,实验证明,混合精度训练对模型精度的影响不大,但可以减少约一半的显存开销。
|
模型 |
基线 |
混合精度 |
|
AlexNet |
56.77% |
56.93% |
|
VGG-D |
65.40% |
65.43% |
|
GoogleLeNet(Inception v1) |
68.33% |
68.43% |
|
Inception v2 |
70.03% |
70.02% |
|
Inception v3 |
73.85% |
74.13% |
|
Resnet50 |
75.92% |
76.04% |
表1 混合精度训练性能对比
梯度检查点
前文提到显存的主要开销之一是反向传播所需要的中间结果,梯度检查点(Gradient Checkpointing)的主要优化点就在于此。梯度检查点是个典型的用时间换空间节省显存开销的方案,可以将训练的显存开销由
![]()
降至
![]()
。
训练过程中显存的开销主要是模型参数、参数梯度、优化器状态及中间结果。大多数算子都依赖前向计算的中间结果进行反向传播,因此我们需要
![]()
的显存存储这些前向中间结果。
为了节省显存开销,梯度检查点仅保留少量前向计算结果,而在反向传播需要这些结果时,再进行一次前向计算将中间结果恢复。更具体来说,将神经网络切分成几段,仅记录每段的输出而扔掉在此段中的所有中间结果,这些丢弃的中间结果在反向传播时重新计算并恢复。对于前馈神经网络,梯度检查点技术可用牺牲20%训练时间的代价,训练10倍于原始方案的模型,显著降低显存的占用。
图4所示为五节点前馈神经网络,可在前向计算过程中仅保留1、3、5三个节点的中间结果,而在反向传播需要时,通过前向计算恢复2(最近节点为1)、4(最近节点为3)节点的中间结果。

图4 五节点前馈神经网络
图5展示了使用梯度检查点技术后,在GTX1080上训练不同规模ResNet所用内存和训练时间的变化,训练过程中的峰值显存使用显著降低,代价是训练时长的些许增加。
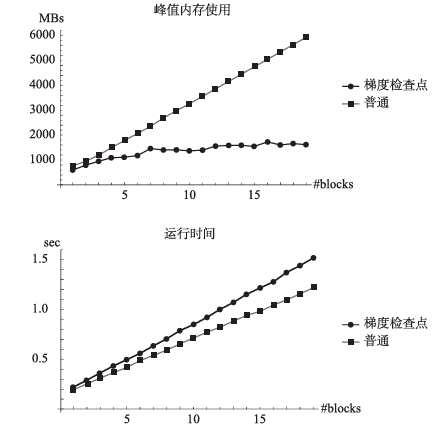
图5 应用梯度检查点后,在GTX1080上训练不同规模ResNet所用内存和训练时间对比
梯度累积
在训练模型时,不同的批次大小对最终结果的影响很大。研究证明,更大的批次可以使训练更加高效,模型性能更好。但更大的批次占用更多显存,GPU显存的硬件限制导致批次的扩展受限。
为解决此问题,梯度累积(Gradient Accumulation)应运而生,通过累积多个批次的梯度,可将一个大批次分割成多个迷你批次,从而降低每次计算的显存开销。
如前所述,训练时显存占用主要由模型参数、优化器状态、中间结果和临时存储构成。随着批次增大,更多样本的计算结果如激活需要在前向计算过程中存储,也就导致中间结果所需显存增加。可以认为,激活所占存储与批次大小成正比。
为了突破显存的限制,还是采取分治的思想切分批次,有两种不同的实现方式:梯度累积或数据并行。
梯度累积是在同一GPU上串行计算多个迷你批次的结果,最后将它们的梯度累加并更新模型参数。具体来说,梯度累积修改了训练的最后一个步骤,原始实现是在每个批次计算完毕后都更新模型参数,梯度累积则是继续进行下一个批次,并将梯度累加,在多个批次执行完毕之后,将累加后的梯度一并更新模型参数。
如图6所示,假设全局批次有128个样本,将原本的一个批次分为4个迷你批次后,每个迷你批次含有32个样本,每个批次仅需要对32个样本进行梯度计算,对4个迷你批次计算完成后,将累积的4个梯度一并更新模型参数即可。
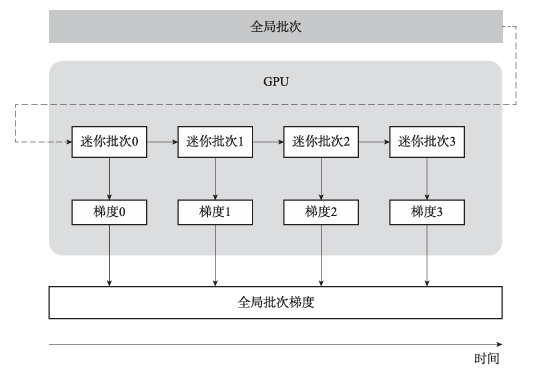
图6 梯度累积示意
数据并行则是一种分布式训练架构,用多个GPU分别训练更小的批次,在每个迭代的末尾将梯度归约,更新模型参数。
对比图6与图7可以发现,数据并行与梯度累积的主要区别在于切分的维度不同,数据并行按空间切分,将迷你批次放置于不同GPU上,而梯度累积按时间切分,将迷你批次分时计算。
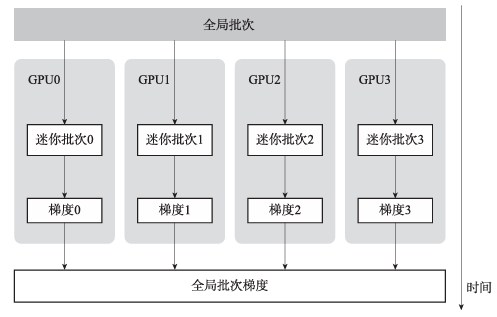
图7 数据并行示意
显然,数据并行可以加速训练,梯度累积会消耗更多的训练时间。但是数据并行与梯度累积可以结合使用,用多个GPU并进行梯度累积,更高效地训练大模型。
值得注意的是,由于某些网络层如批正则(Batch Normalization)将会在迷你批次中计算而非在原始批次中计算,梯度累积的结果可能与原始训练的结果稍有不同。
FlashAttention
FlashAttention是专为处理Transformer中的注意力层内存限制而设计的。
在原始的Transformer模型中,由于注意力层的内存需求与序列长度呈平方增长(
![]()
)关系,大模型受到了计算和存储的双重制约。
FlashAttention通过减少GPU高带宽内存和GPU片上SRAM之间的内存读写次数,解决了Transformer在处理长序列时速度较慢和内存占用过高的问题。
如图8所示,从访问速度来看,GPU SRAM优于GPU高带宽内存(High Bandwidth Memory,HBM),而GPU HBM又优于CPU内存。
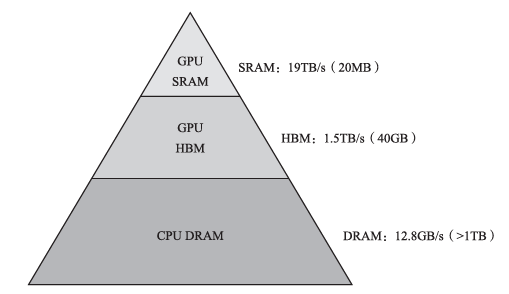
图8 内存访问速度与大小层次示意
基于此观察,FlashAttention通过将注意力矩阵分解为多个小块,将内存读写次数降至最低。具体来说,FlashAttention将注意力矩阵分解为多个子矩阵,并将每个子矩阵存储在GPU SRAM中。这样,当计算注意力矩阵时,仅需要在GPU HBM和GPU SRAM之间进行少量的内存读写操作,从而大大减少了内存读写次数,提高了计算效率。
与传统实现不同,FlashAttention在前向传递期间避免存储大型注意力矩阵,而在反向传播期间在SRAM中重新计算(思路与梯度检查点类似),从而显著降低了内存占用,同时为长序列计算带来了显著的加速(2~4倍)。
此外,FlashAttention还具有IO感知能力,它可以根据不同的硬件配置和数据集特征,自动调整注意力矩阵的分解方式,以最大程度地减少内存读写次数。这使得FlashAttention可以在不同的硬件平台上实现高效的计算,并且具有更好的可移植性。该算法不仅实现了更快的Transformer训练,而且在模型性能上也优于现有的注意力方法。
四种策略的适用情况
- 混合精度训练通过使用半精度浮点数(FP16)替代传统的单精度浮点数(FP32),减少了内存占用,同时引入了母版权重复制、损失缩放和精度累加等机制来保证模型精度不受影响。
- 梯度检查点技术则通过在反向传播时重新计算中间结果来节省内存,尽管这会增加一定的计算时间。
- 梯度累积允许将大批次划分为多个小批次进行计算,从而降低单次计算的内存需求,适用于显存受限的情况。
- FlashAttention专注于解决Transformer模型在处理长序列时遇到的内存和计算效率问题,通过将注意力矩阵分解为多个小块并利用GPU的快速存储,减少了内存读写次数,提高了计算效率。
这些内存优化策略各有侧重,能够有效应对大规模模型训练中面临的内存挑战,提升训练效率和模型性能。
作者简介
苏之阳(博士),现任微软资深应用科学家,小冰前研发总监,专注于搜索排序算法和对话系统研发,曾主导了小冰智能评论和小冰框架等项目的架构设计和开发,在大语言模型的研发与应用方面具有丰富的经验。
王锦鹏(博士),致力于自然语言处理和推荐系统的研发,拥有在微软亚洲研究院等科技公司担任关键技术岗位的经验,参与了Office文档预训练、推荐大模型等多个重要项目的研发和优化工作。
姜迪(博士),拥有十余年工业界研发和管理经验,在雅虎、百度等知名互联网企业工作期间,为企业的多个关键业务研发了核心解决方案。
宋元峰(博士),曾就职于百度、腾讯等互联网公司,在人工智能产品开发领域拥有丰富的经验,研究涉及自然语言处理、数据挖掘与可视化等方向。
文章来源:IT阅读排行榜
本文摘编自《大语言模型:原理、应用与优化》,苏之阳、王锦鹏、姜迪、宋元峰 著,机械工业出版社出版,经出版方授权发布,转载请标明文章来源。
延伸阅读

《大语言模型:原理、应用与优化》
苏之阳 等著
微软等大厂的4位博士撰写
为研究人员和开发者提供系统性参考
零基础理解大模型、构建大模型和使用大模型
内容简介
这是一本从工程化角度讲解大语言模型的核心技术、构建方法与前沿应用的著作。首先从语言模型的原理和大模型的基础构件入手,详细梳理了大模型技术的发展脉络,深入探讨了大模型预训练与对齐的方法;然后阐明了大模型训练中的算法设计、数据处理和分布式训练的核心原理,展示了这一系统性工程的复杂性与实现路径。
除了基座模型的训练方案,本书还涵盖了大模型在各领域的落地应用方法,包括低参数量微调、知识融合、工具使用和自主智能体等,展示了大模型在提高生产力和创造性任务中的卓越性能和创新潜力。此外,书中进一步介绍了大模型优化的高级话题和前沿技术,如模型小型化、推理能力和多模态大模型等。最后,本书讨论了大模型的局限性与安全性问题,展望了未来的发展方向,为读者提供了全面的理解与前瞻性的视角。
购书渠道:
欢迎支持本书~
《大语言模型:原理、应用与优化》https://item.jd.com/14817784.html
二、赠书领取
为了鼓励更多人了解和探索大语言模型技术,我们特别推出了《大语言模型:原理、应用与优化》赠书活动。扫描下方二维码加入Damon小智的赠书群,参与抽奖,有机会获得这本书,提升你的LLM知识,与我们一起在大语言模型发展的道路上不断前行。
扫码加入:👇👇👇

本次抽奖赠书本着公平、公正、公开的原则,从群内抽出多名幸运粉丝寄送《大语言模型:原理、应用与优化》(包邮)。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)