保姆级教程!利用vLLM部署自己的大模型(glm-4-9b-chat)
(在JupyterLab的最下方),可以看到下图所示界面,按箭头指示复制相应命令。图24将上述复制好的命令粘贴到本地打开的命令行中运行,注意要做一些修改,具体如图25所示。左侧的是本地想使用的服务端口,右侧是服务器上的服务端口,因此我们将右侧改为8000,左侧改为5000(便于区分,可以自定义修改)。运行命令后需要输入密码,我们从图24中复制密码并粘贴输入进去,按下回车就行(注意,这里粘贴好了密码
首先简单介绍一下vLLM框架。vLLM 是一个快速且易于使用的 LLM 推理和服务库。
vLLM官方文档地址:欢迎来到 vLLM!— vLLM
开始部署模型
首先,打开AutoDL官网:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL。注册登录后,点击算力市场选择相应算力的服务器进行租用。本文中部署的glm-4-9b_chat采用3090服务器就足够,根据图1的流程进行租用。
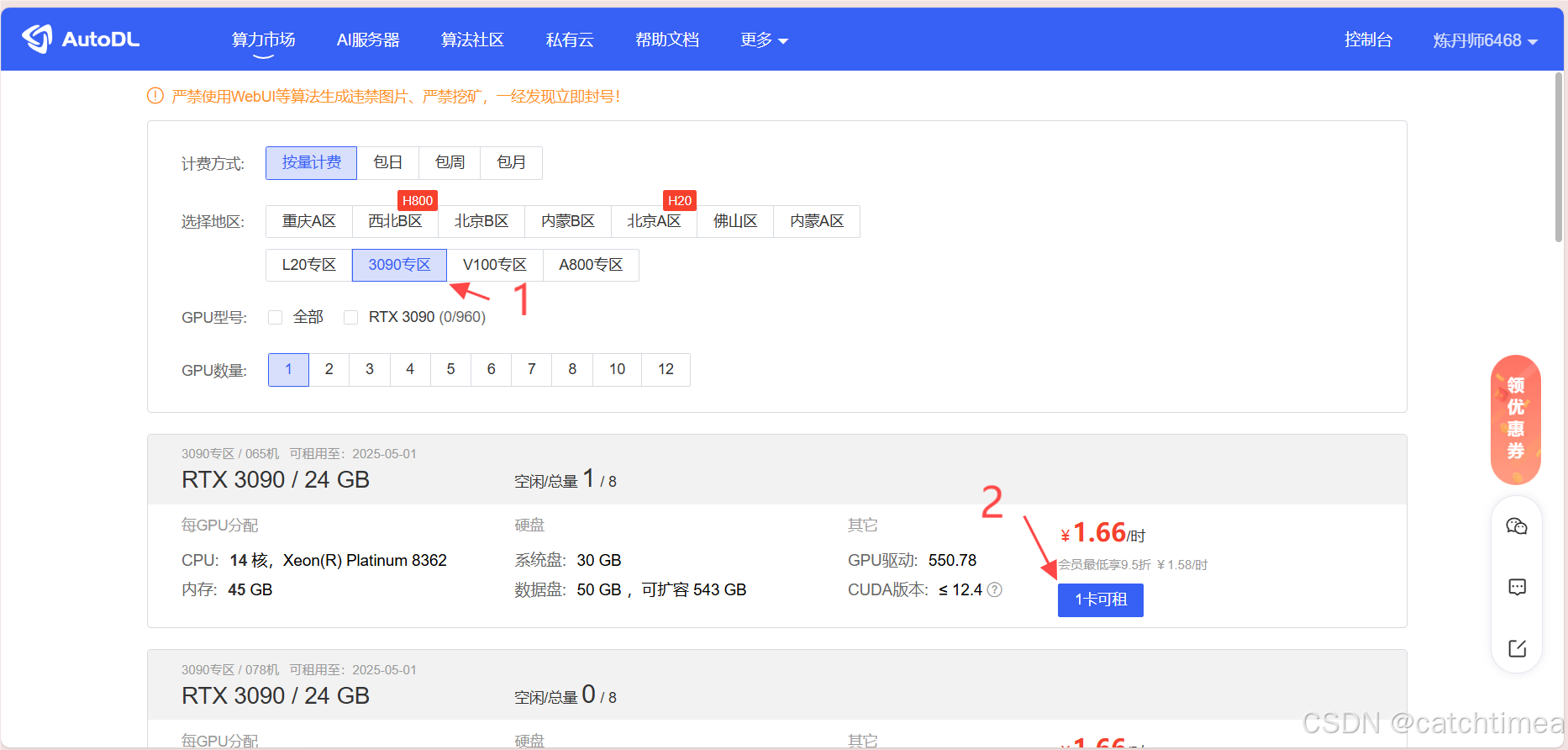
图1
接下来按图2和图3指示选择基础镜像(若无具体要求,一般选择最高版本即可),选择好基础镜像后点击右下角的立即创建。
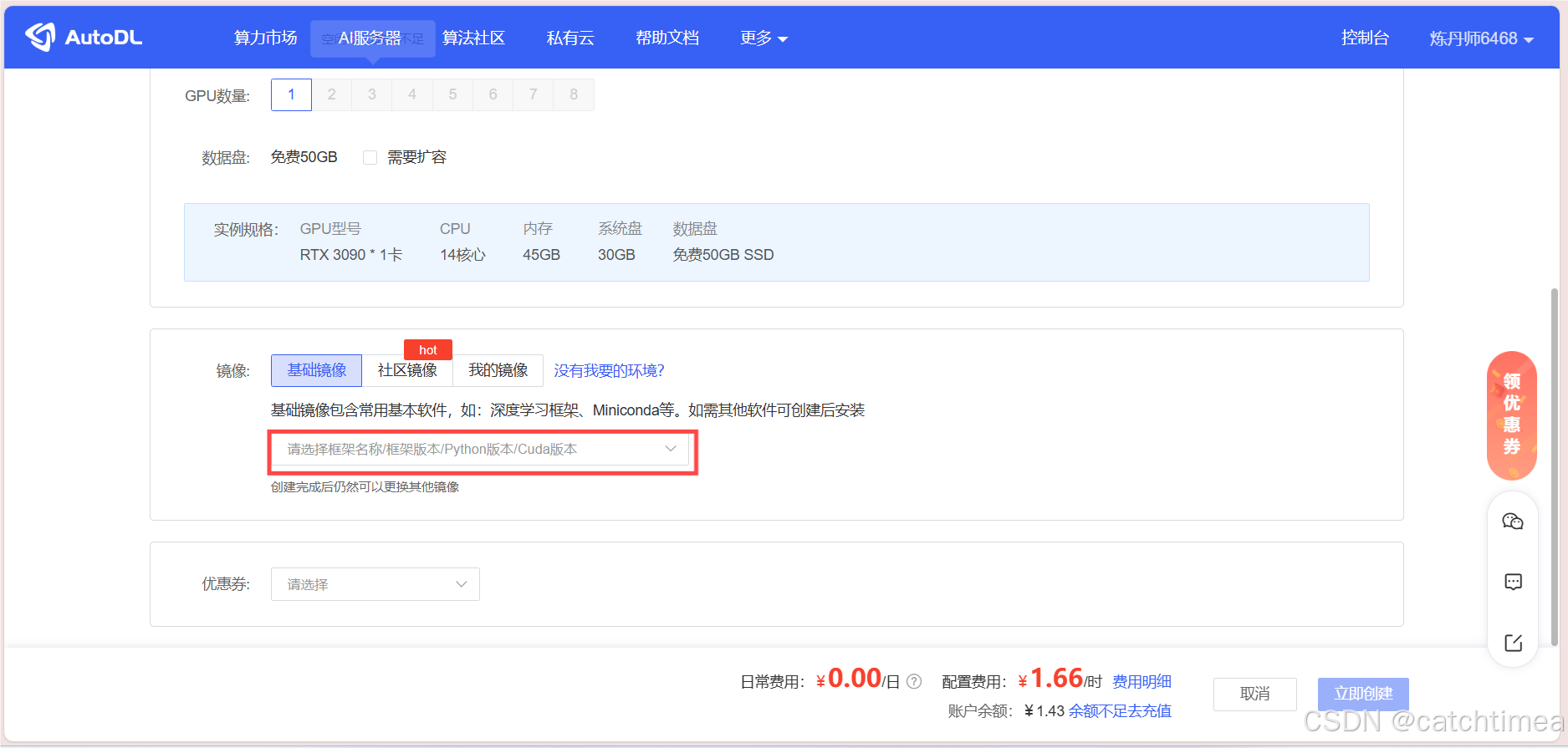
图2
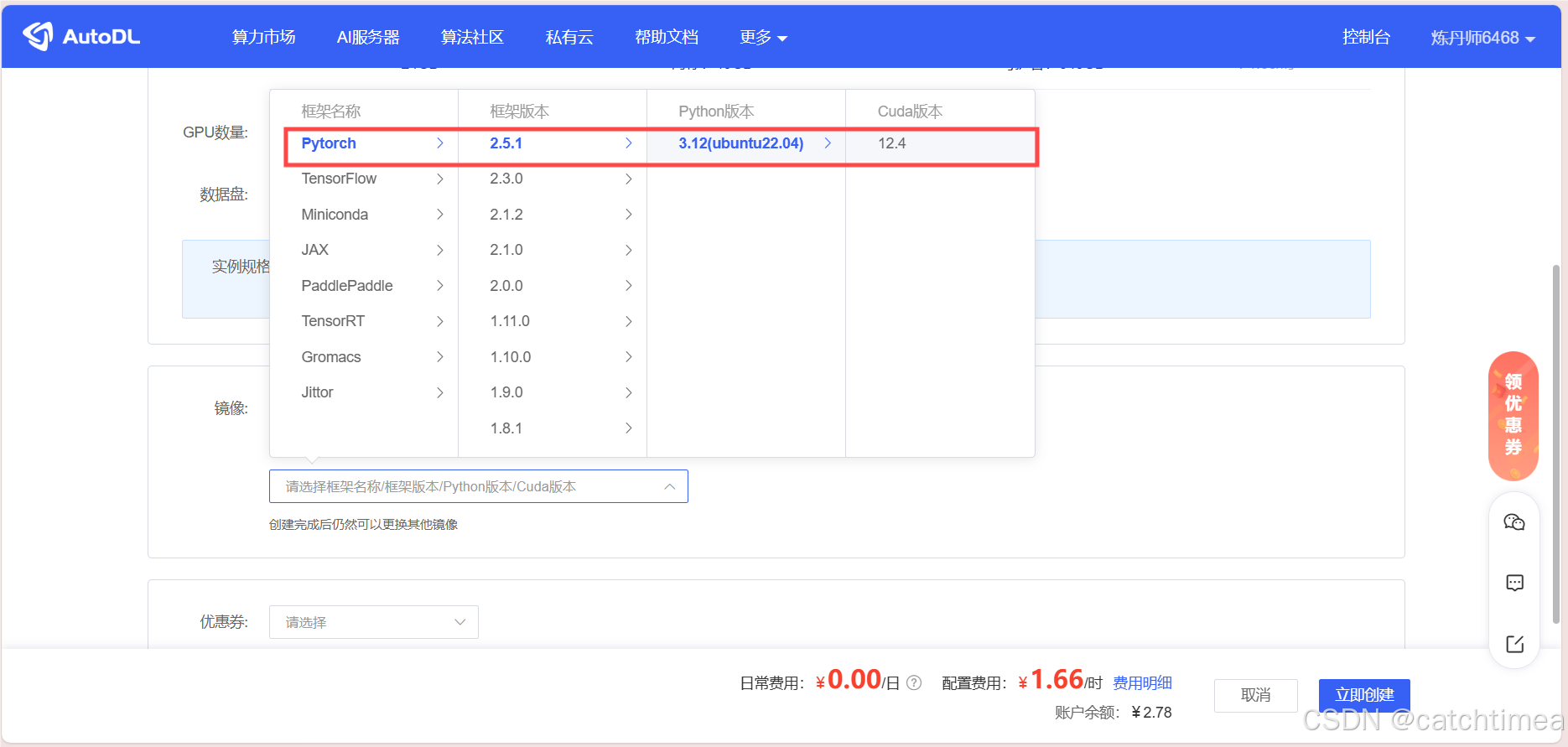
图3
创建完实例后会跳转到图4所示的页面,点击 JupyterLab 进入可视化界面。
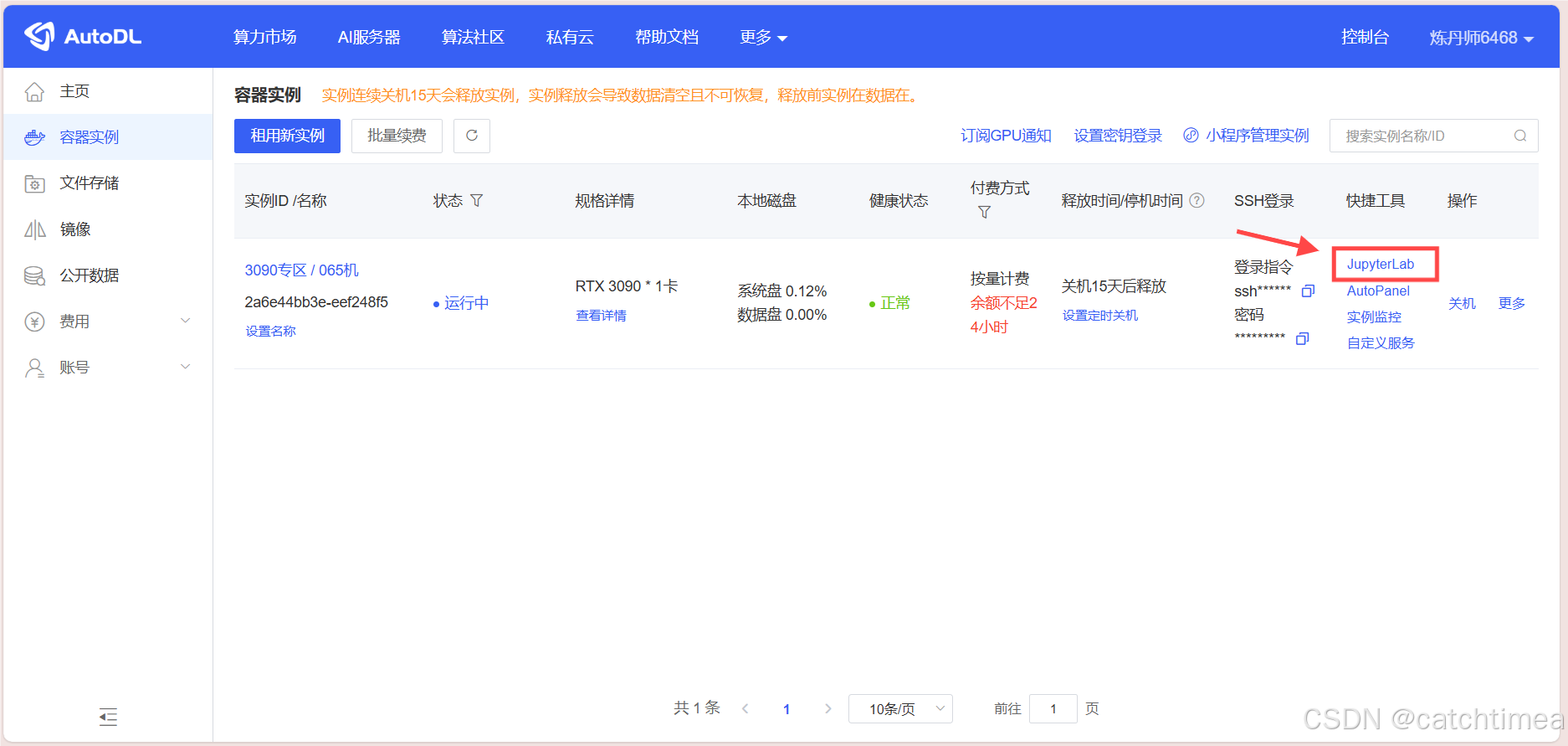
图4
接着按图5指示双击 autodl-tmp 进入服务器的数据盘,如图6所示。
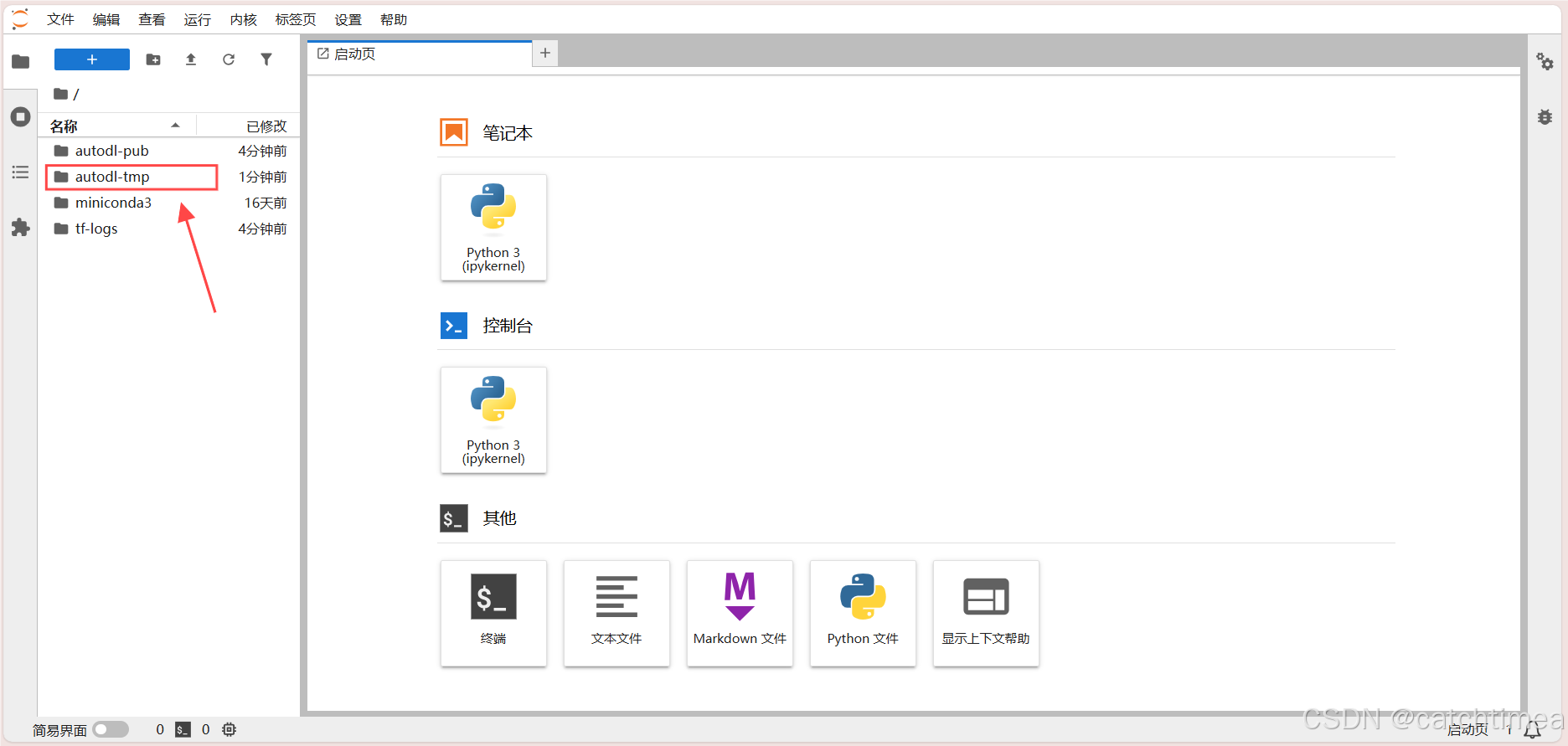
图5

图6
接着回到AutoDL官网的主页,点击上方导航栏的帮助文档。
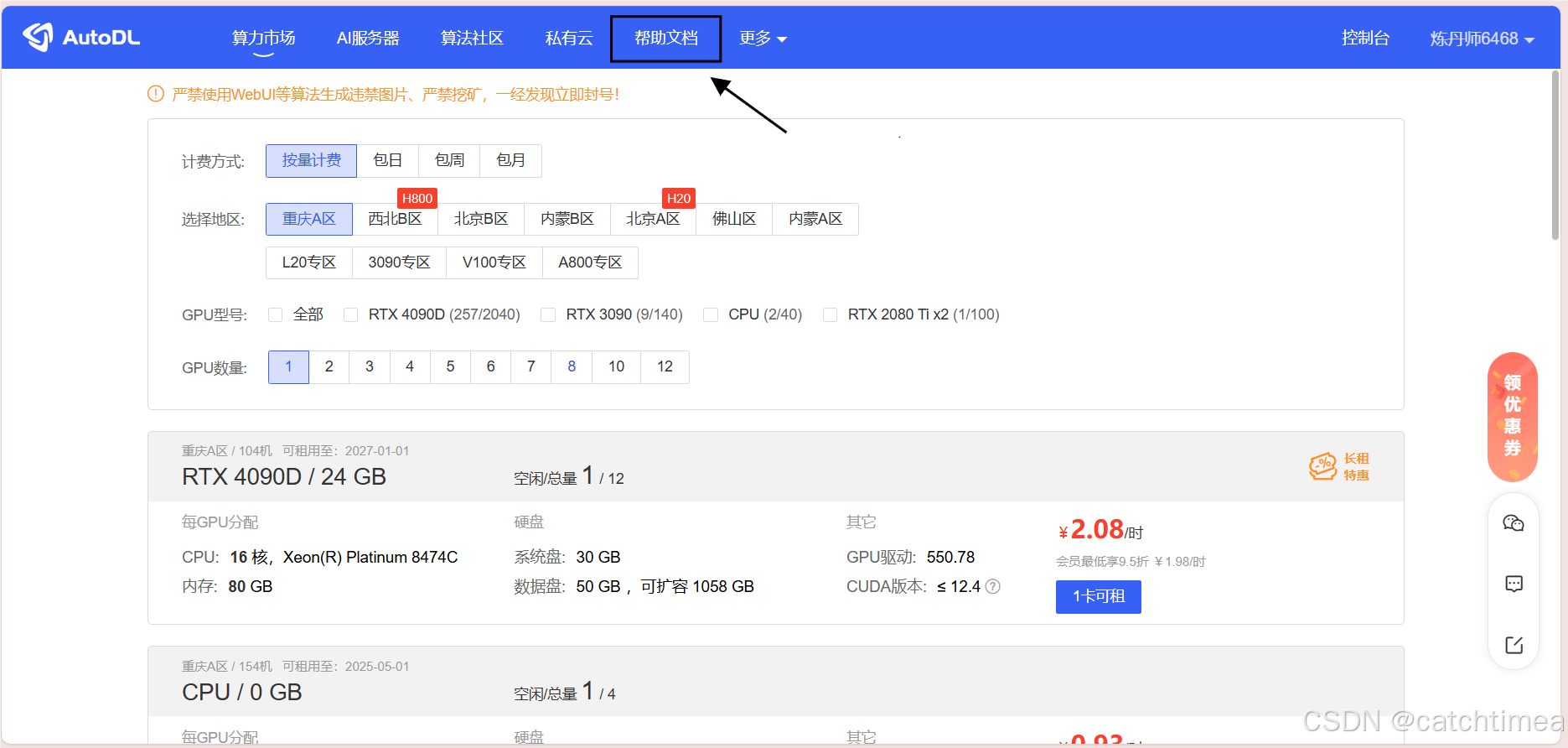
图7
点击学术资源加速,复制图8中所示的代码。
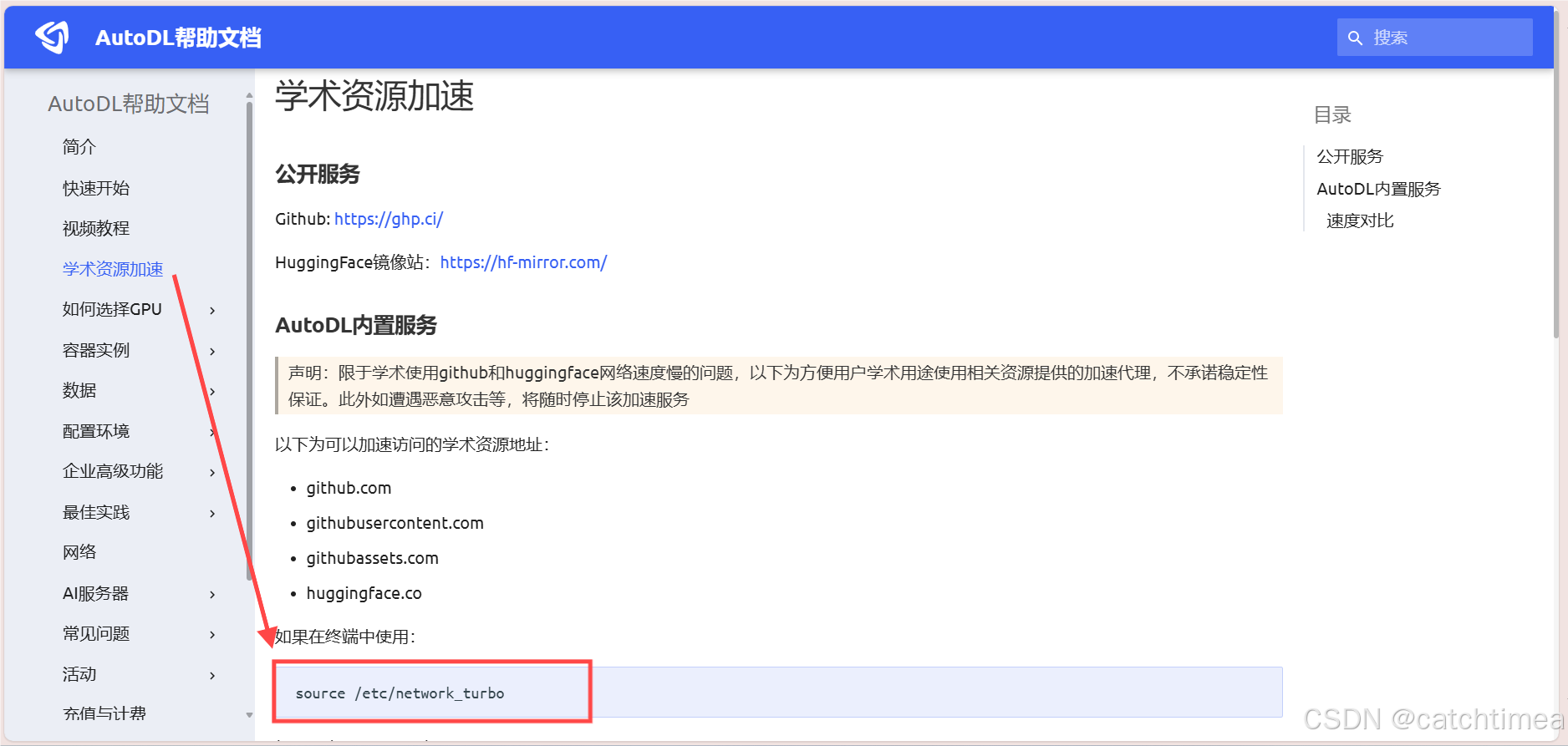
图8
回到图6所示的JupyterLab页面,在启动页中点击终端进入Linux命令行。将上面复制好的学术资源加速代码粘贴到命令行中并回车运行,如图9所示。
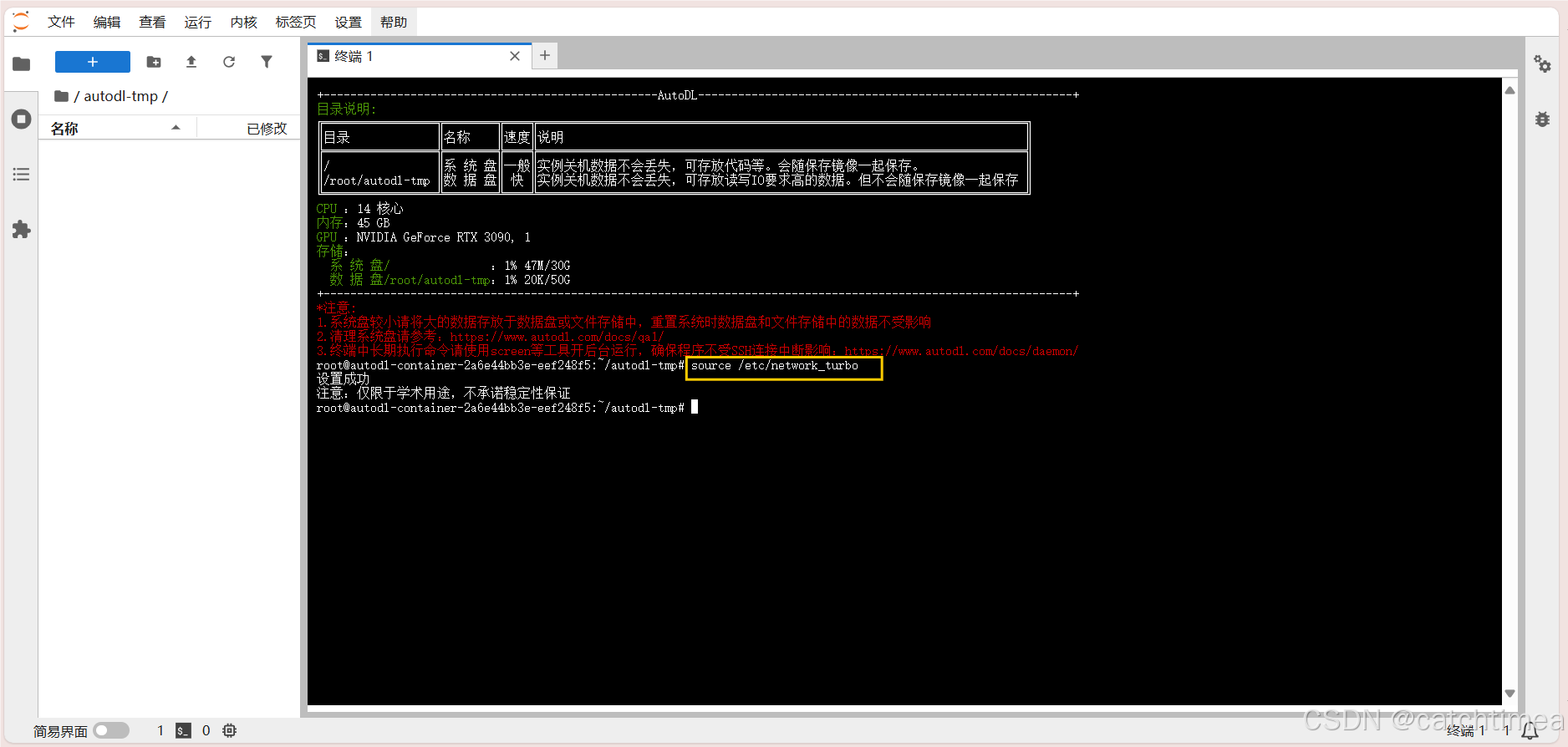
图9
接下来安装部署模型所需要的依赖,将以下命令复制到终端中回车运行,如图10所示。
pip install torch
pip install torchvision
pip install transformers
pip install huggingface-hub
pip install sentencepiece
pip install jinja2
pip install pydantic
pip install timm
pip install tiktoken
pip install accelerate
pip install sentence_transformers
pip install gradio
pip install openai
pip install einops
pip install pillow
pip install sse-starlette
pip install bitsandbytes
pip install modelscope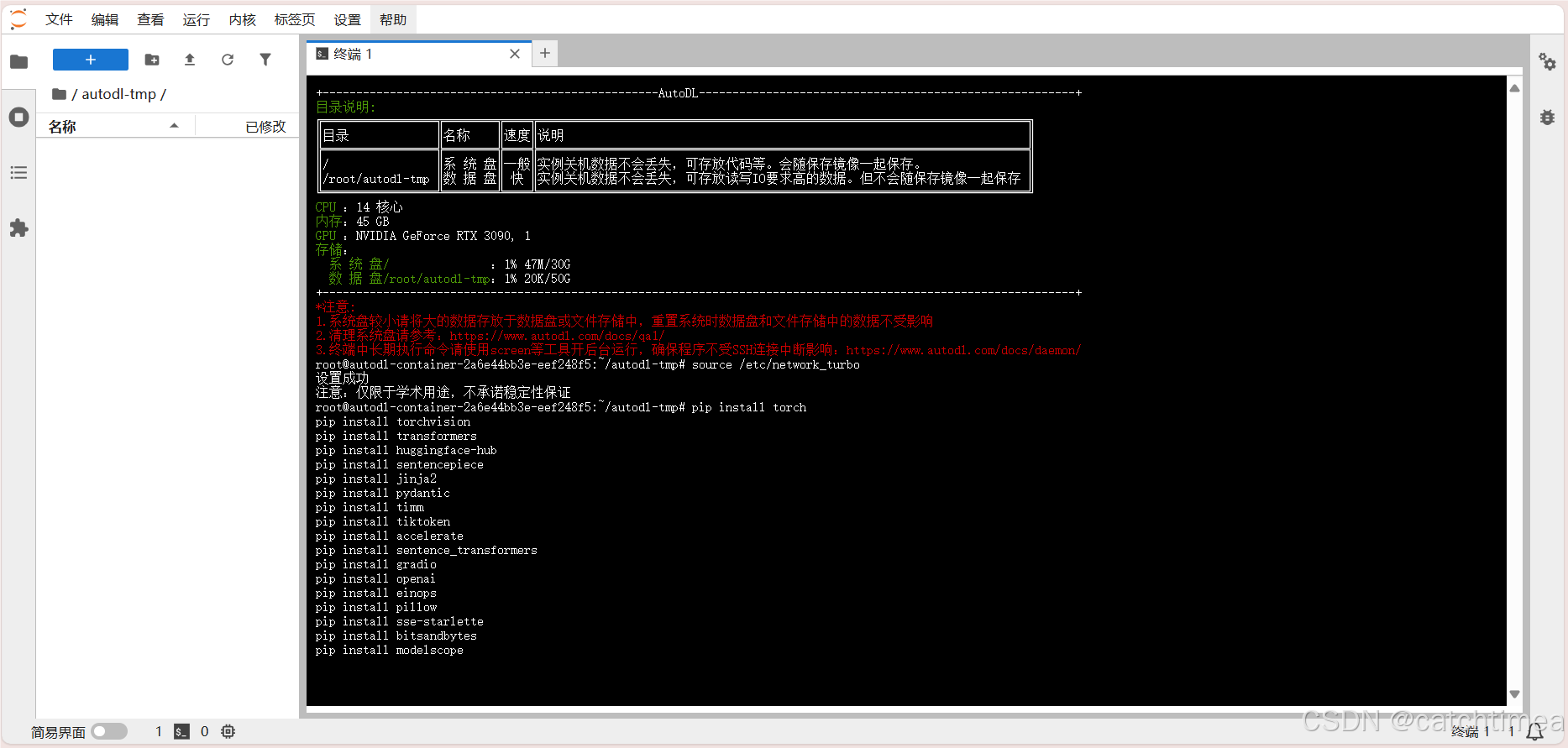
图10
安装完依赖后,安装vllm,如图11所示。
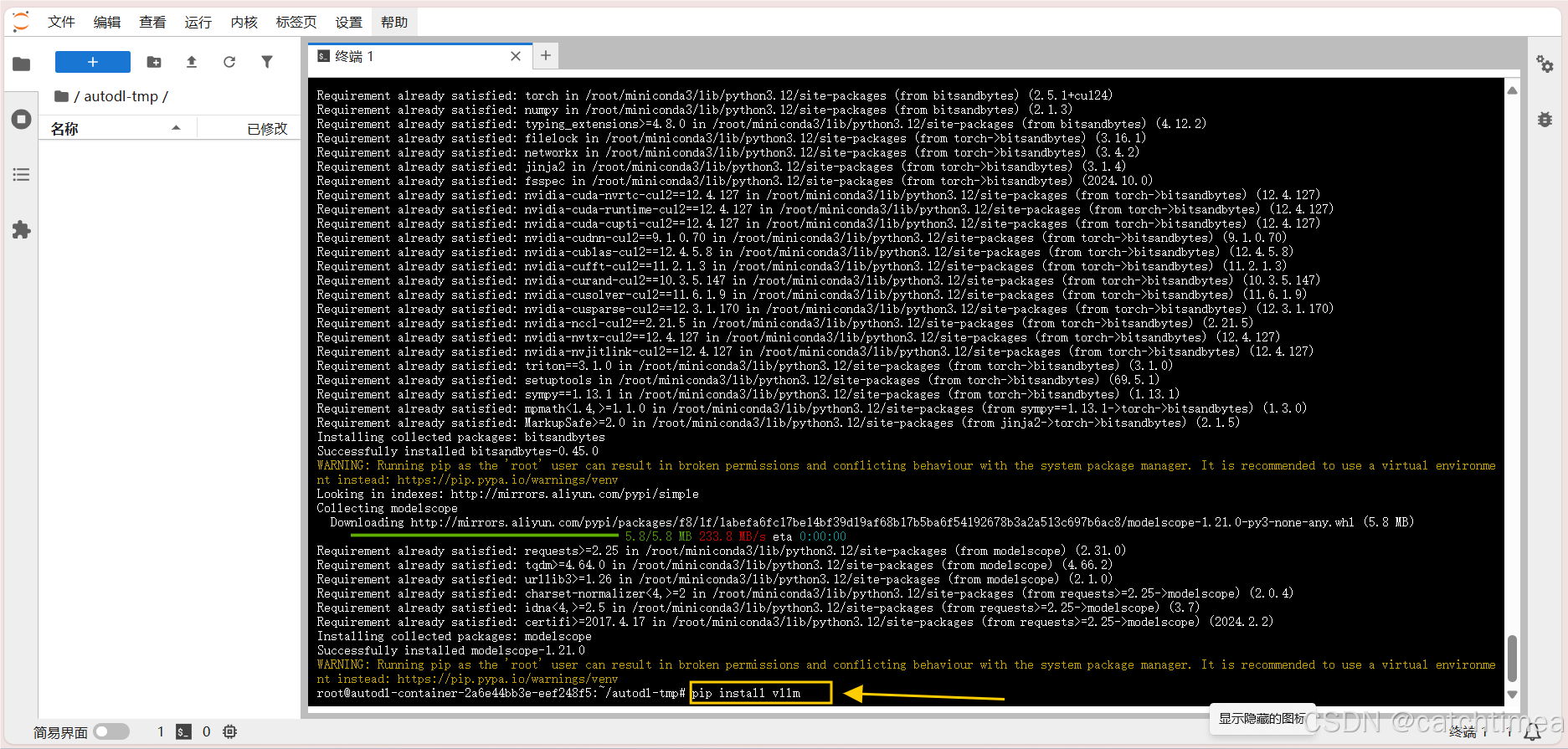
图11
安装完依赖后,在左侧空白处单击右键新建 model_download.py 文件和 model 文件夹。 modelmodel_download.py 文件用于下载模型,model 文件夹用于存放模型。具体分别如图12和图13所示。
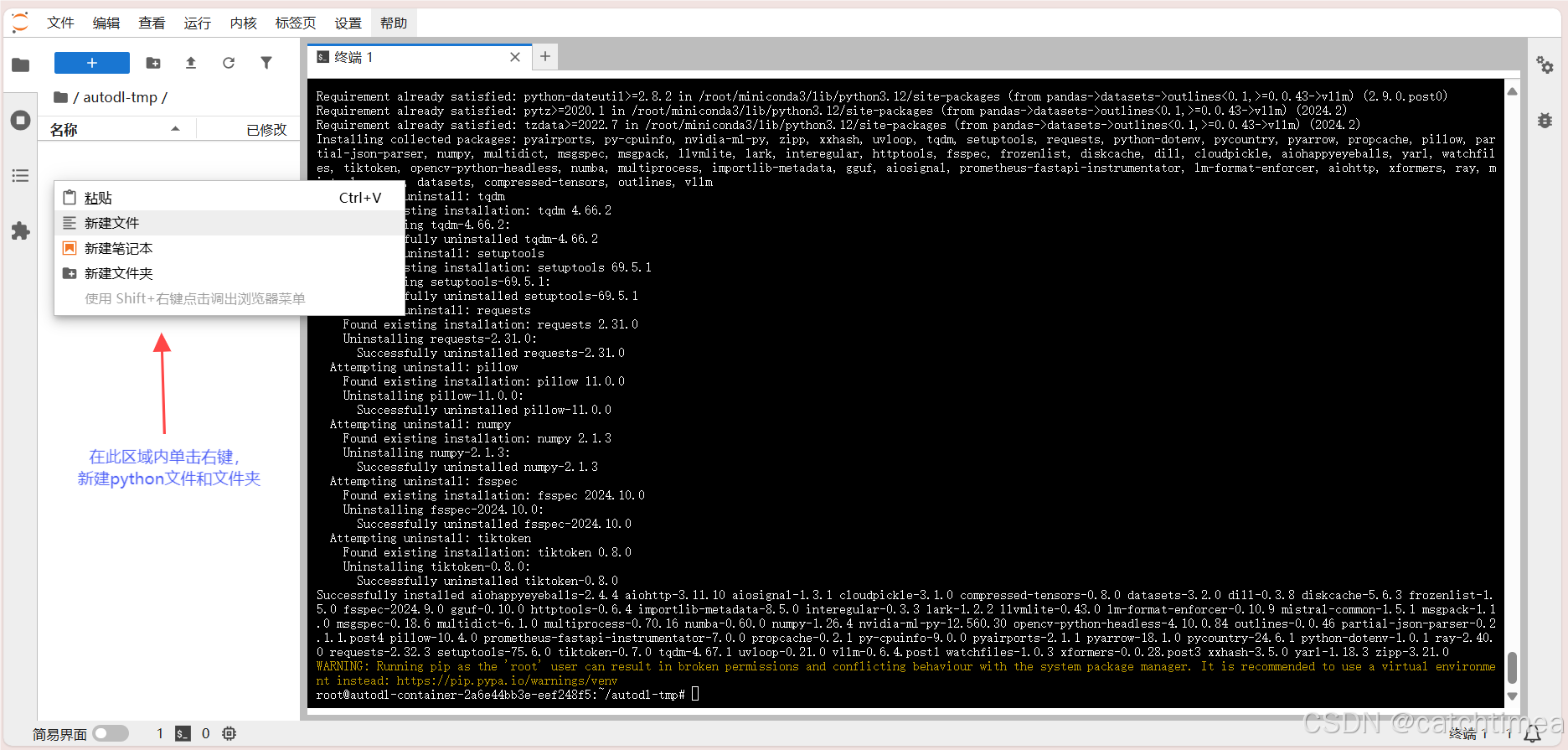
图12
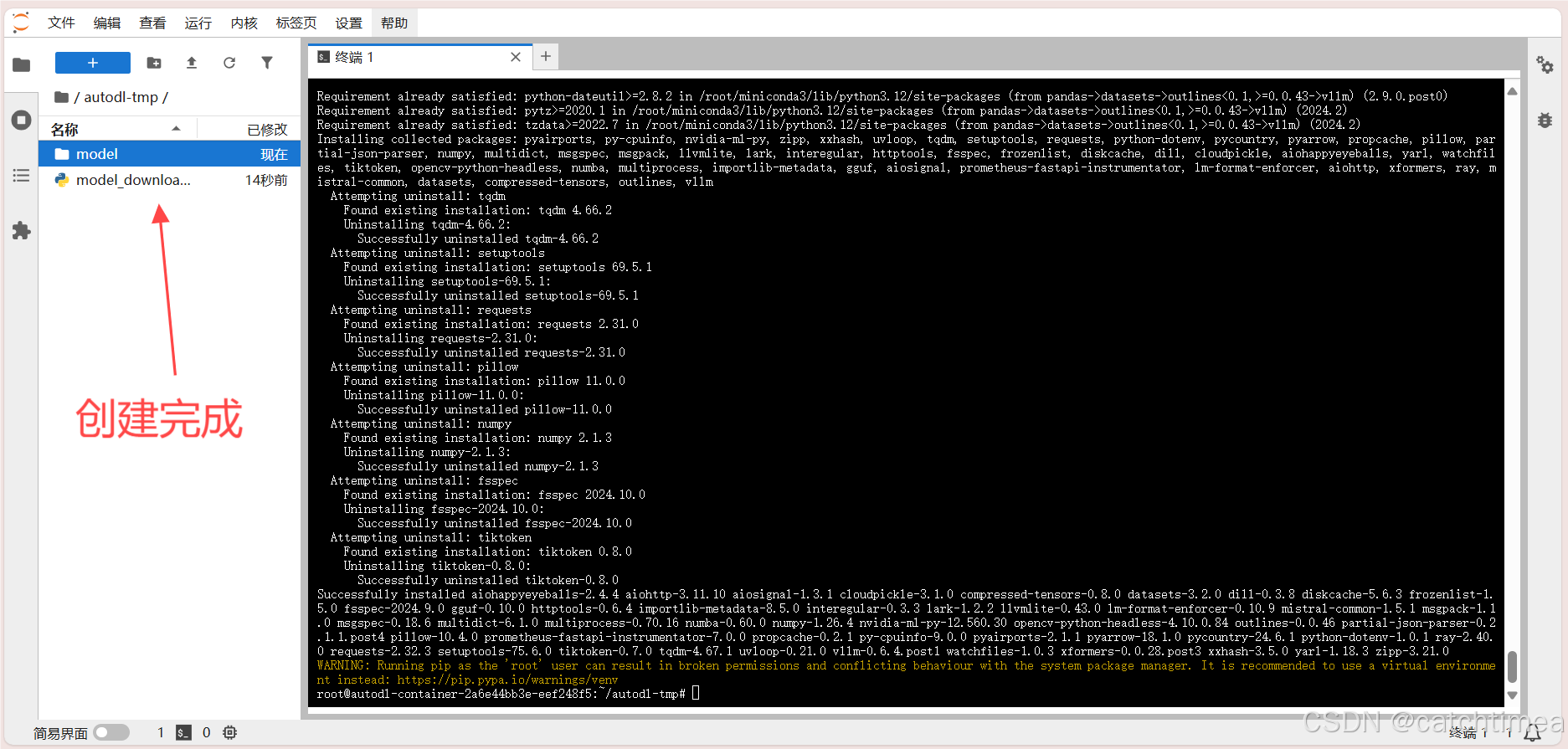
图13
上述文件和文件夹新建完成后就打开魔塔社区官网(用于下载模型,相当于国外的Huggingface):概览 · 魔搭社区。点击右上角搜索框输入glm查找glm-4-9b-chat模型。具体分别如图14和图15所示。
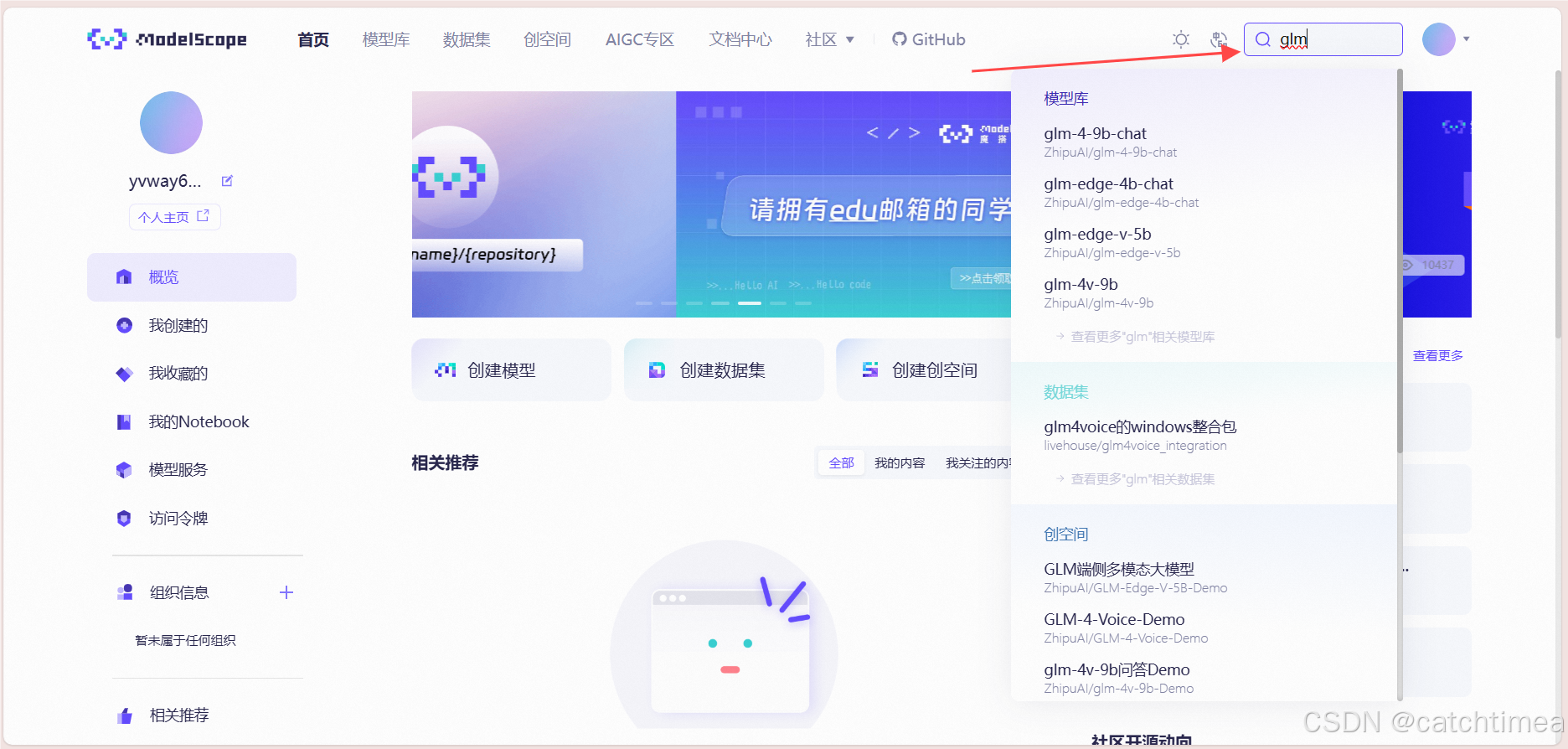
图14
点击glm-4-9b-chat,进入模型详情页。
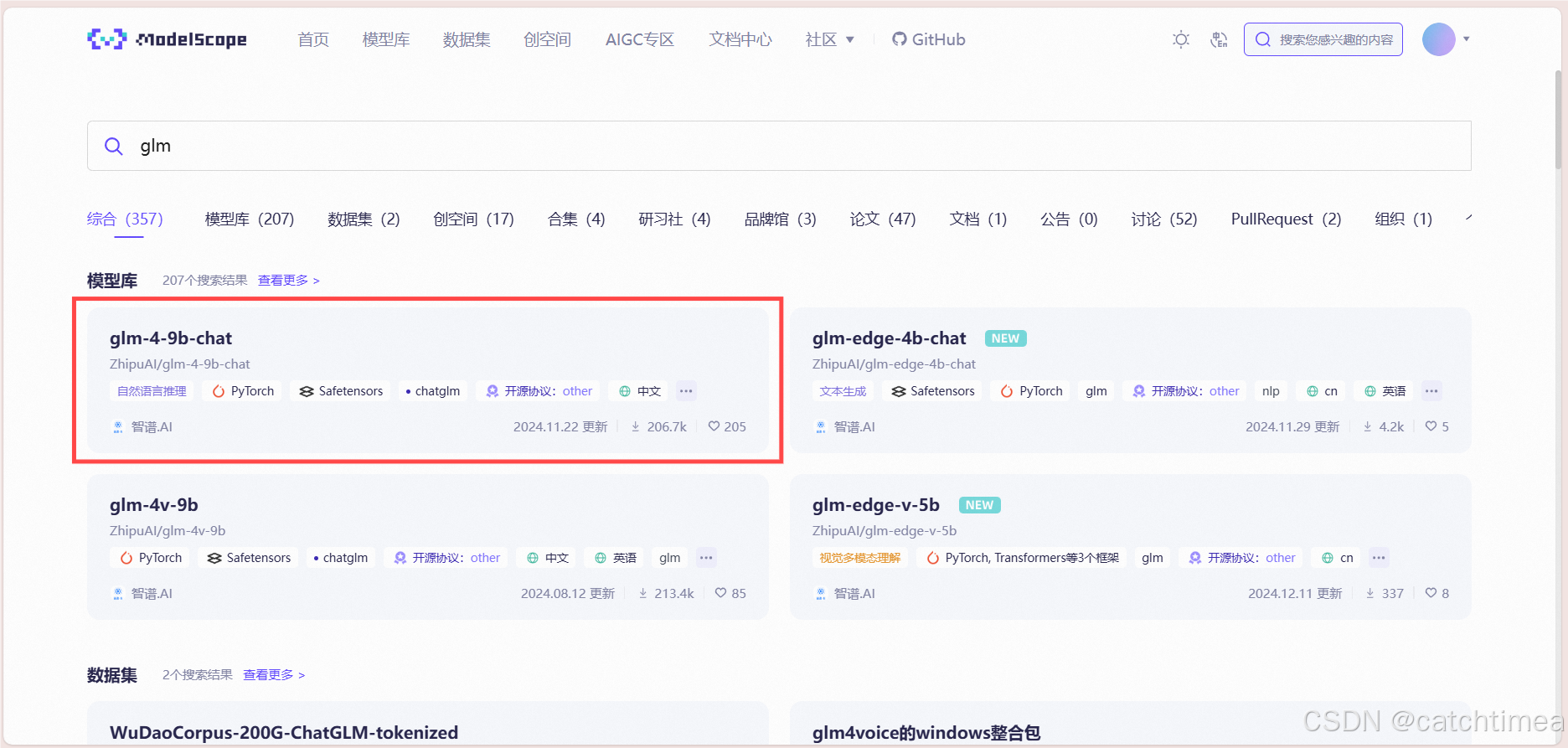
图15
接着点击模型文件,再点击右侧的下载模型,如图16所示
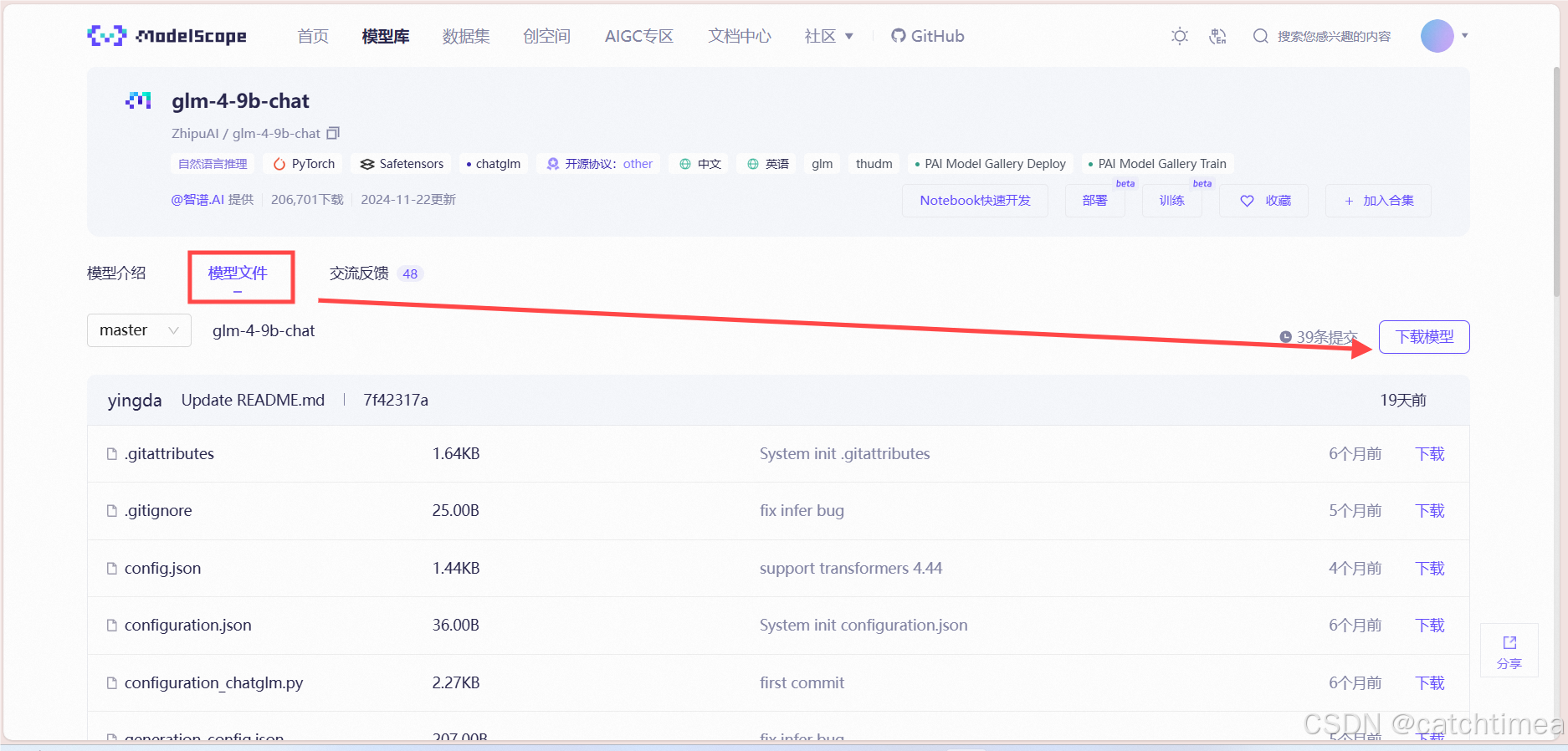
图16
复制SDK下载的代码。
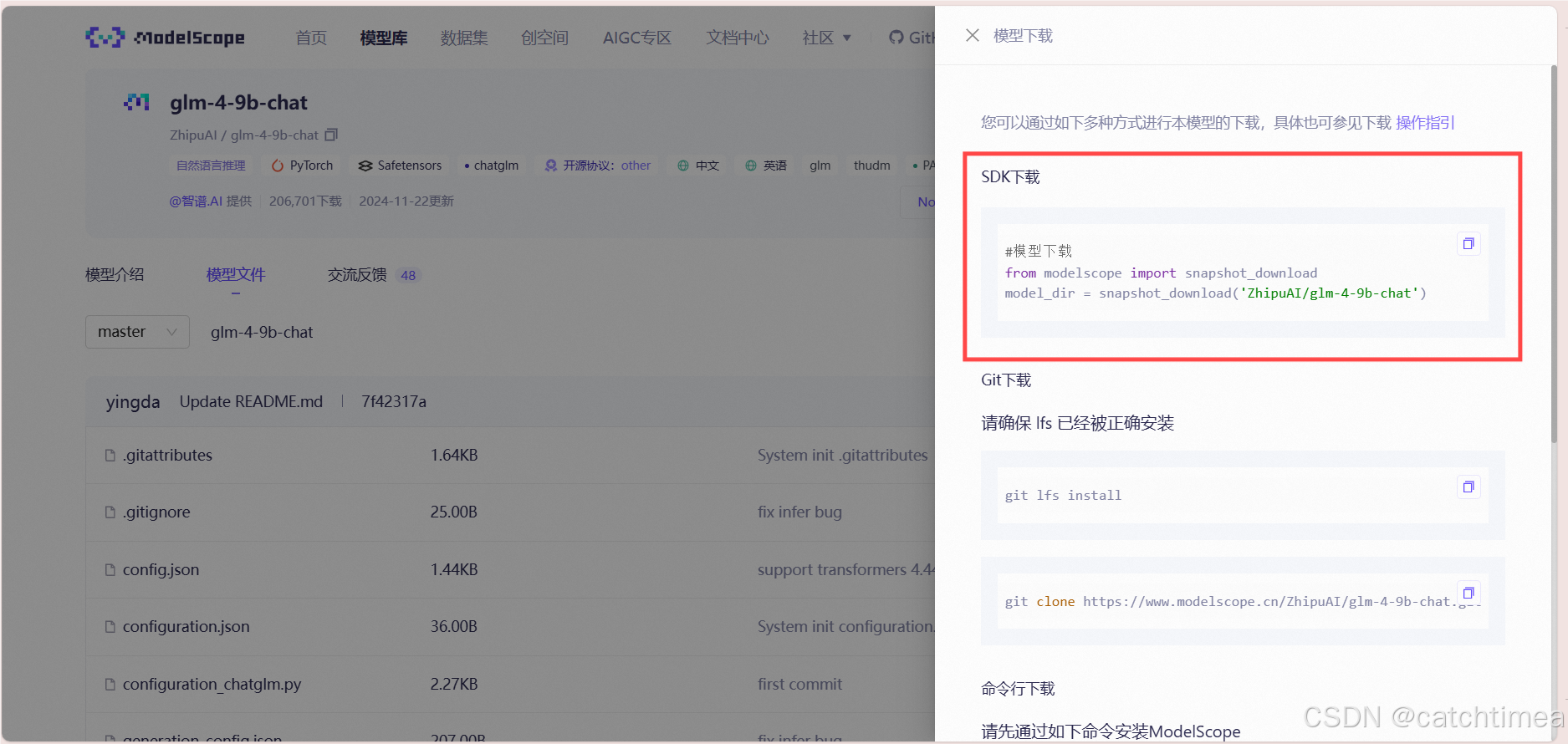
图17
回到服务器的JupyterLab页面,双击打开 model_download.py 文件,将上述SDK下载的代码粘贴到该文件中。注意,在代码中增加了一个参数 cache_dir 用于指定模型下载后的保存位置。
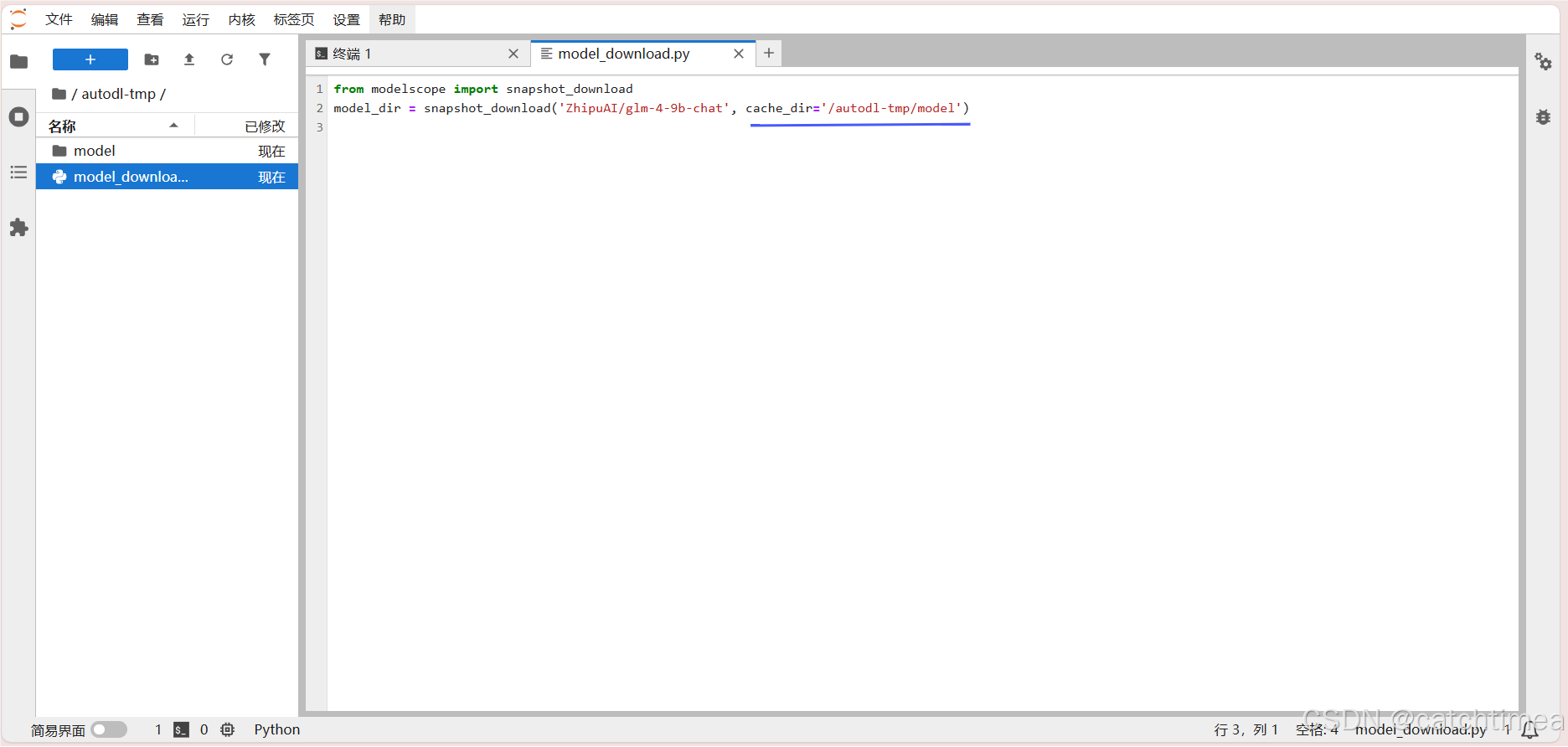
图18
点击终端1,回到命令行,输入 python model_download.py 并回车运行该文件开始下载模型,具体如图19所示。
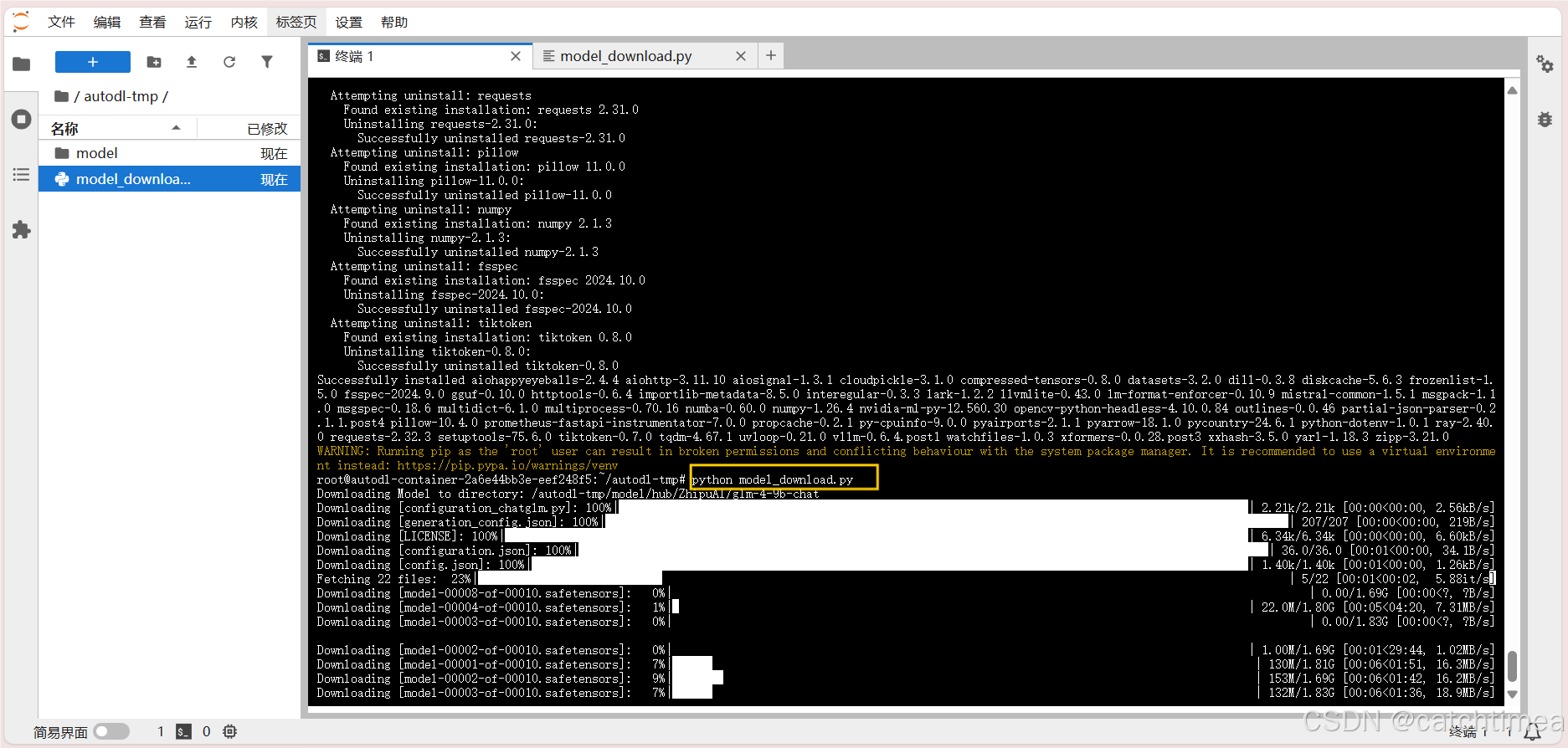
图19
模型下载完成后,在命令行中输入以下代码开始使用vllm工具运行模型,最后可以openAI API的形式提供服务,开启过程如图20所示。
python -m vllm.entrypoints.openai.api_server --model /autodl-tmp/model/ZhipuAI/glm-4-9b-chat --served-model-name glm-4-9b-chat --max-model-len=2048 --trust-remote-code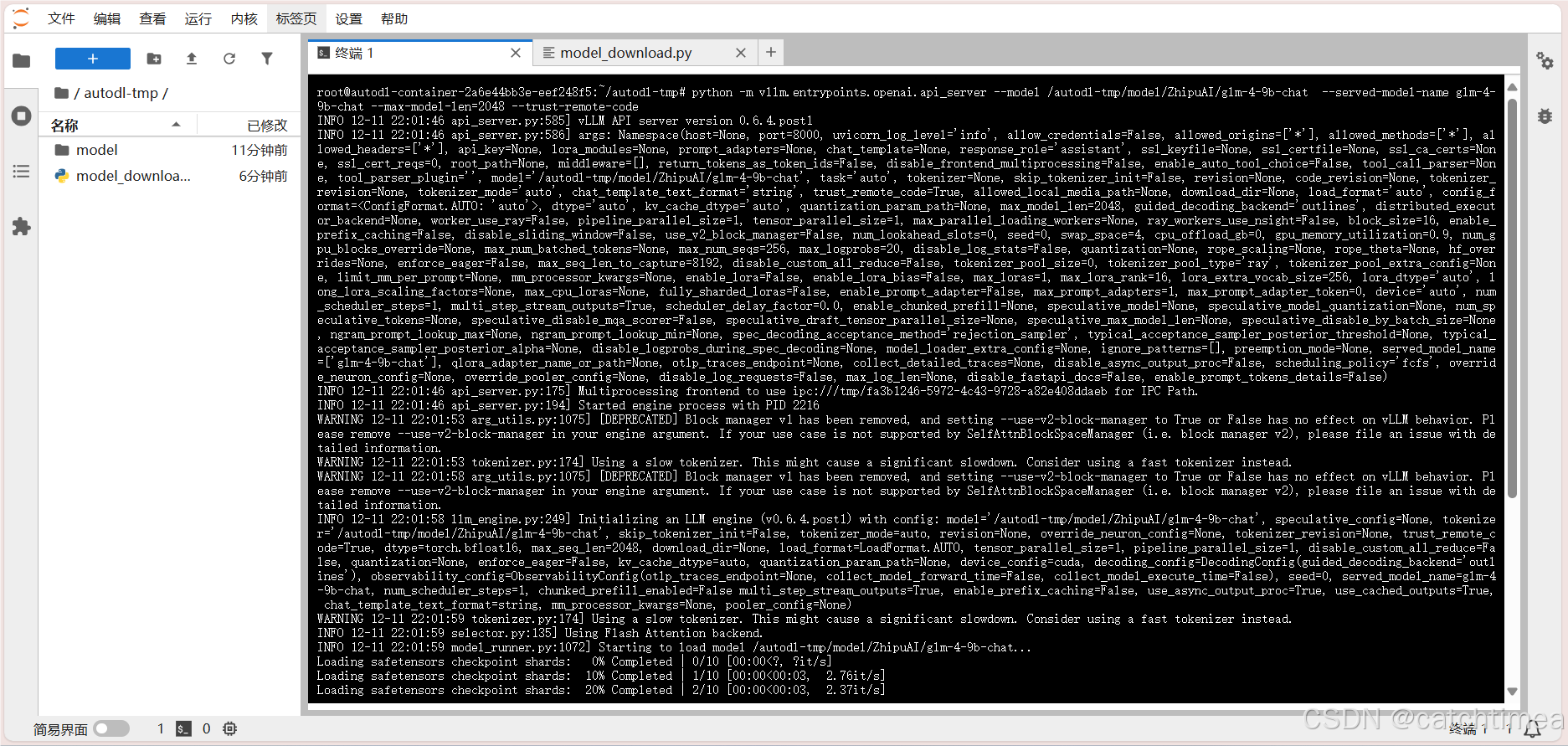
图20
运行成功后,可以看到vllm提供模型服务的端口为8000,如图21所示,但这是服务器上的服务端口,可以在服务器上直接使用。而本地需要使用的话需要服务端口映射到本地,下面将展示具体的映射操作。
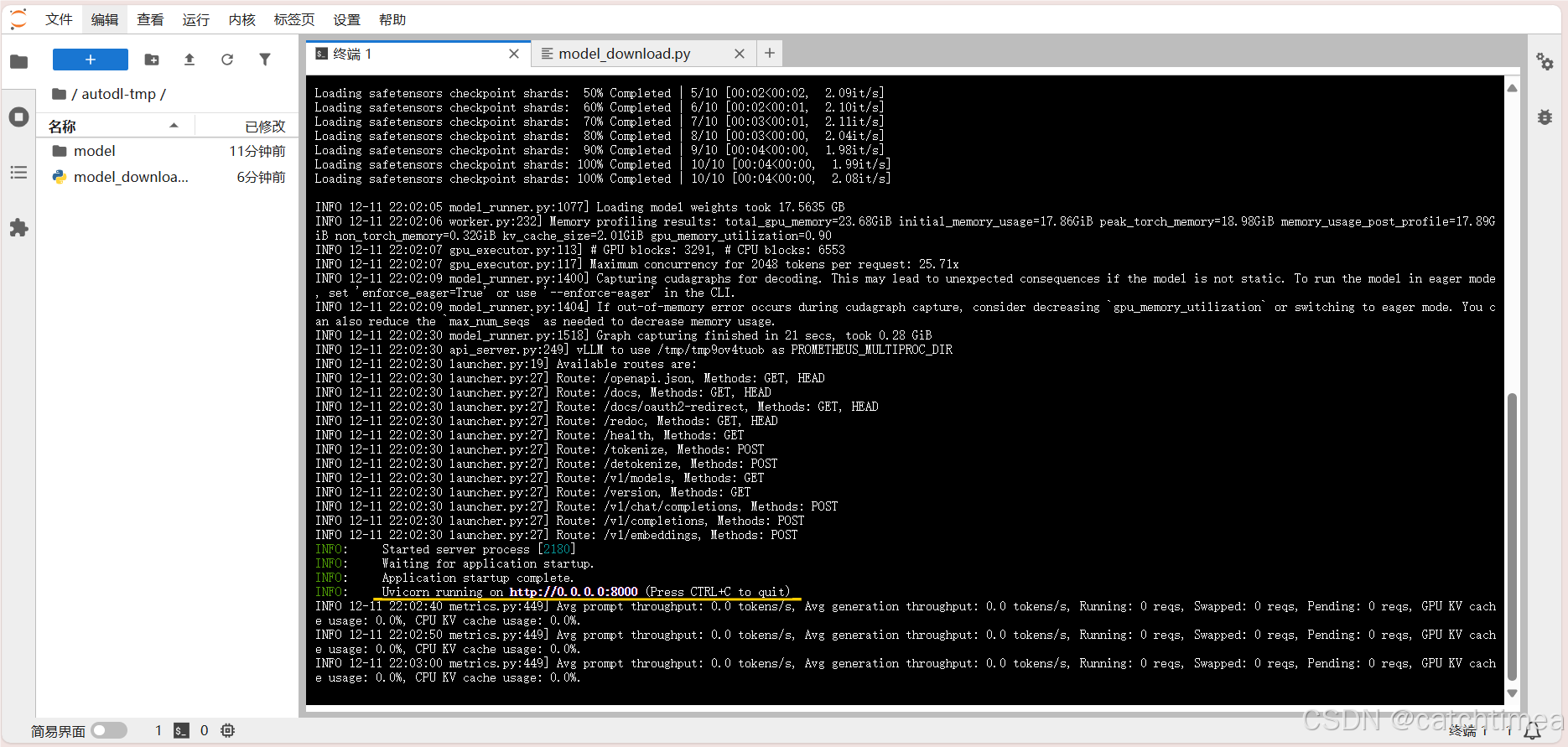
图21
首先在本地电脑上按下 win+R 键,输入CMD进入命令行。具体分别如图22和图23所示。
图22
图23
回到AutoDL官网首页,点击右上角的控制台,可以看到图4所示的页面,点击自定义服务(在JupyterLab的最下方),可以看到下图所示界面,按箭头指示复制相应命令。
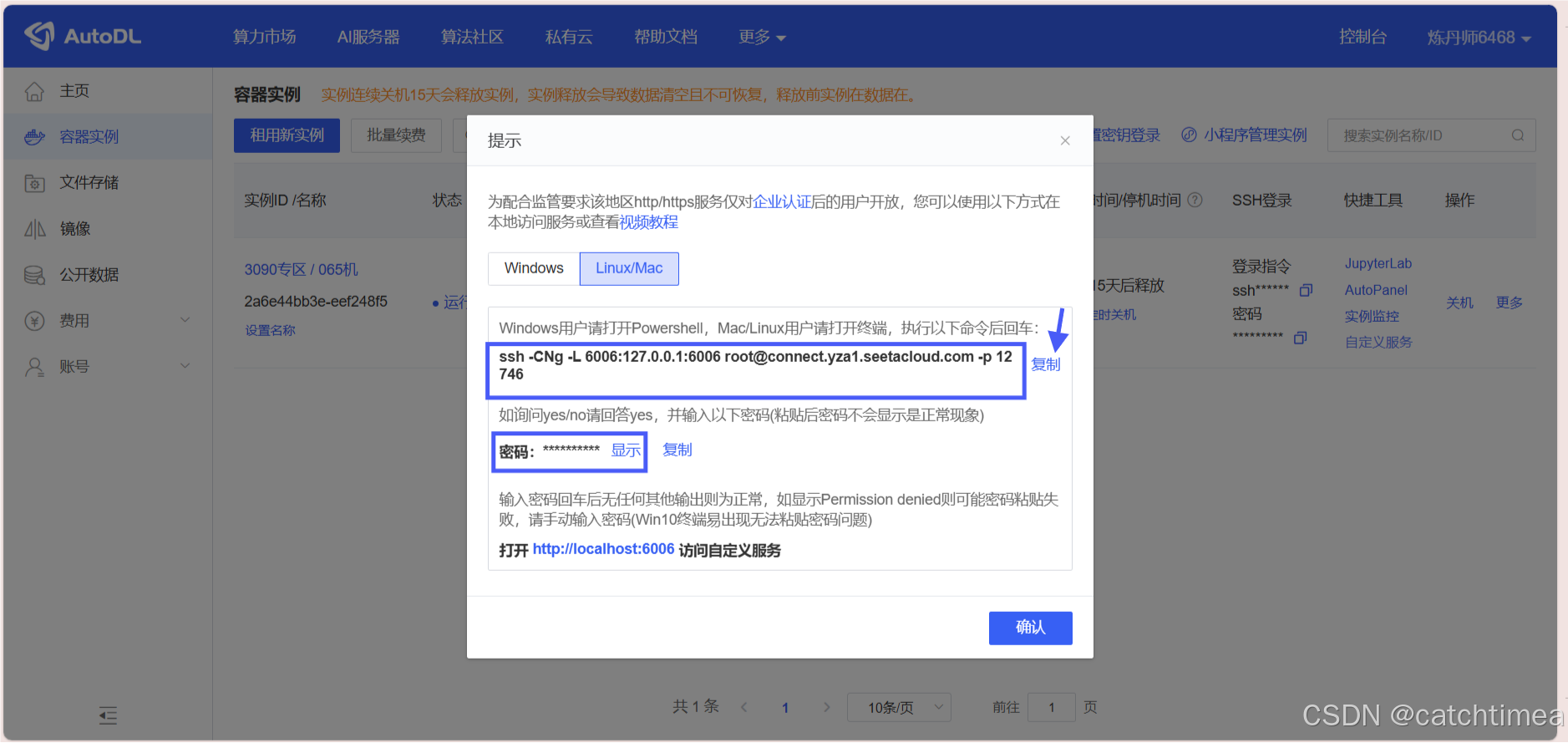
图24
将上述复制好的命令粘贴到本地打开的命令行中运行,注意要做一些修改,具体如图25所示。左侧的是本地想使用的服务端口,右侧是服务器上的服务端口,因此我们将右侧改为8000,左侧改为5000(便于区分,可以自定义修改)。运行命令后需要输入密码,我们从图24中复制密码并粘贴输入进去,按下回车就行(注意,这里粘贴好了密码并不会显示,粘贴完按下回车键即可)。
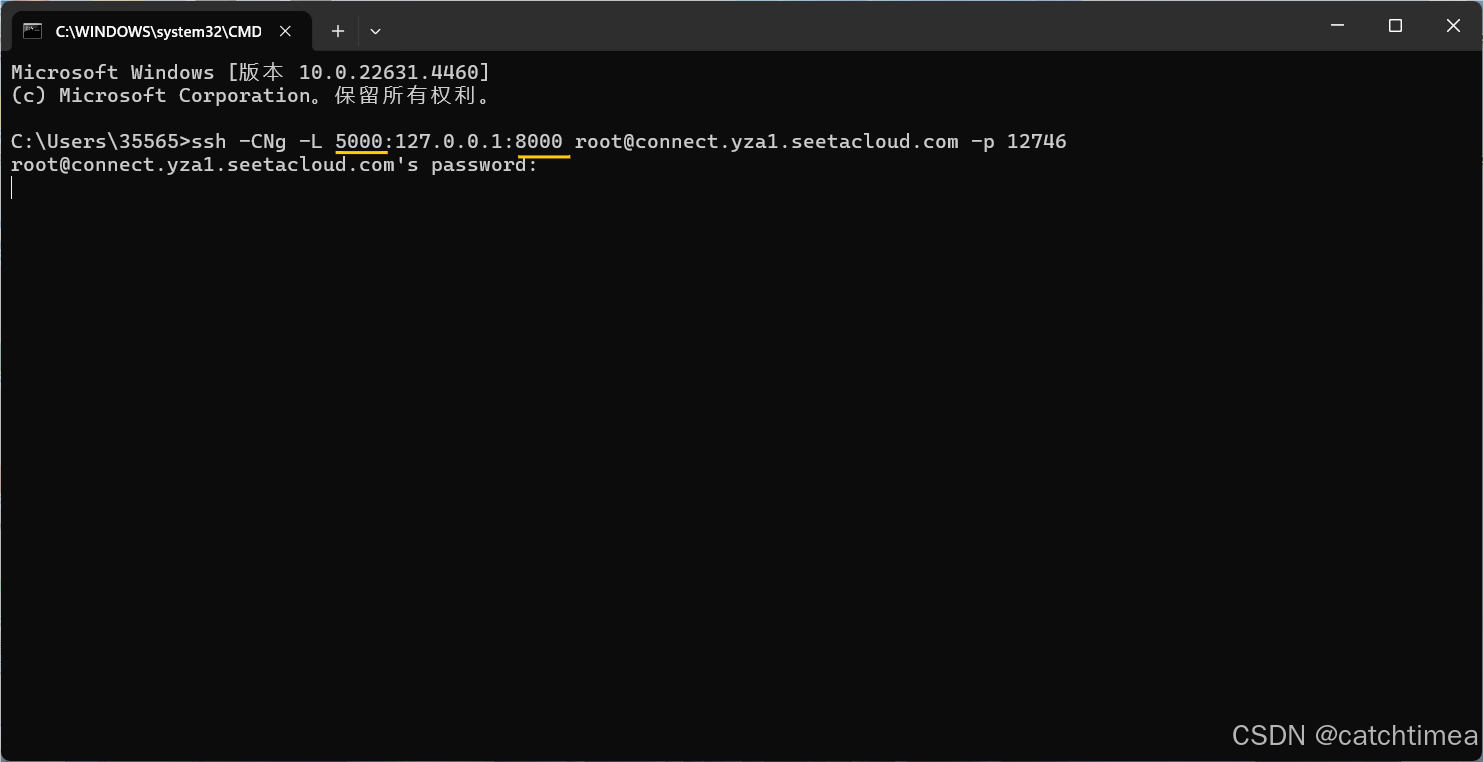
图25
经过上述操作,本地就能通过5000端口直接调用模型服务了。例如,在本机pycharm中新建一个文件开始调用模型服务,具体如图26所示。以下调用模板来自vllm官方文档中的示例。
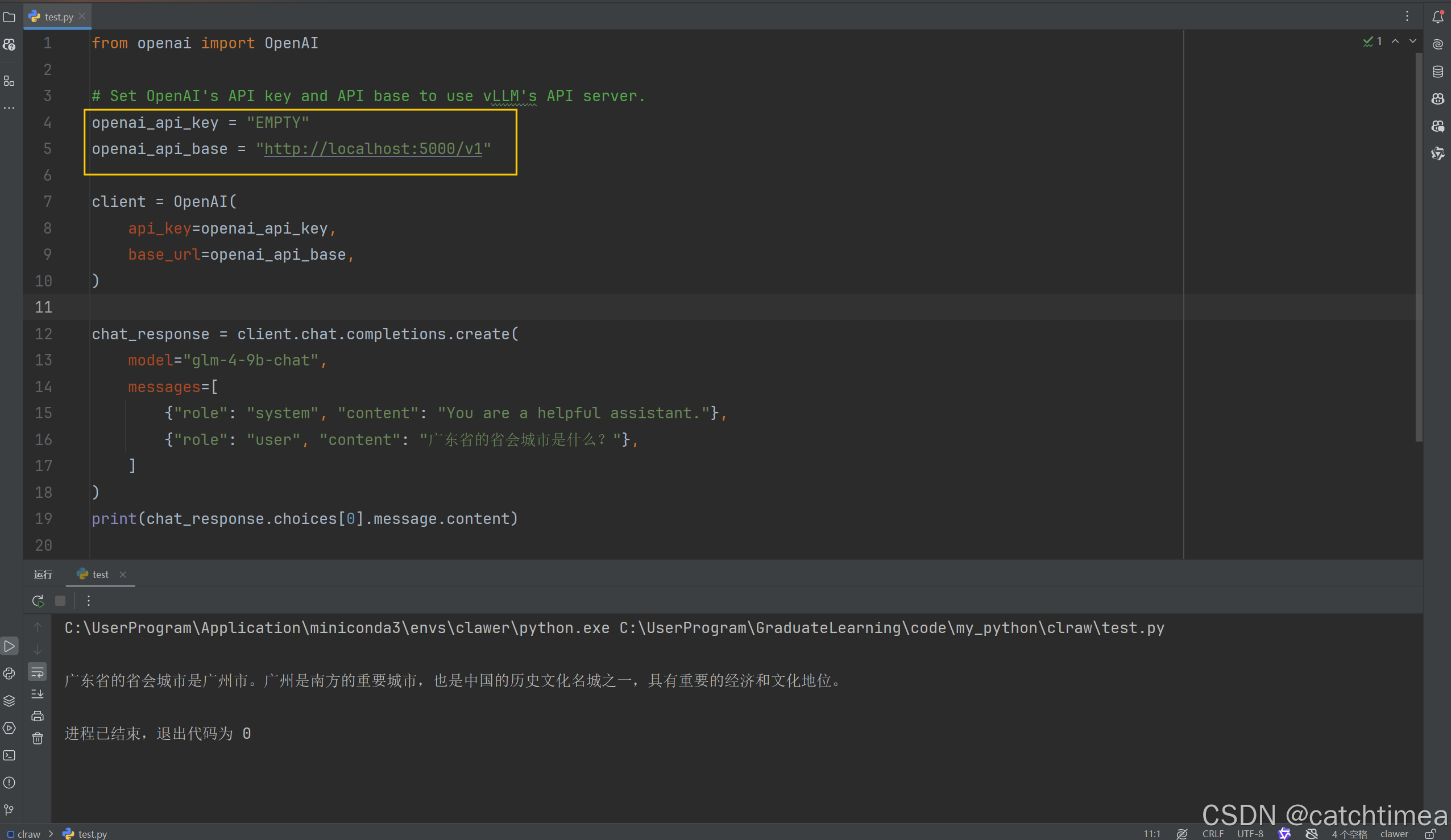
图26
至此,你就已经学会使用vllm部署你自己的大模型(glm-4-9b-chat)了。我们既可以在服务器上通过8000端口直接使用模型服务,也可在本机上通过5000端口调用模型服务。使用完服务后记得关闭服务器,避免不必要的花费。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)