开源大模型 “卷王” 诞生!Qwen3 凭什么超越 DeepSeek R1?
了解 Qwen3 套件,包括其架构、部署以及与 DeepSeek-R1 和 Gemini 2.5 Pro 相比的基准。
 Qwen3是目前为止发布的最完整的开放重量模型套件之一。
Qwen3是目前为止发布的最完整的开放重量模型套件之一。
它来自阿里巴巴的 Qwen 团队,包括可扩展到研究级性能的模型以及可以在更适中的硬件上本地运行的较小版本。
在这篇博客中,我将为您简要介绍完整的 Qwen3 套件,解释模型是如何开发的,并向您介绍基准测试结果。

🚀ALL IN ONE (AIO) 开放接口(API)平台
Qwen 3 是什么?
Qwen3 是阿里巴巴 Qwen 团队最新推出的大型语言模型系列。该系列中的所有模型均采用 Apache 2.0 许可证下的开放加权。
最吸引我眼球的是Qwen引入的思考预算功能,用户可以直接在Qwen应用内部控制。这让普通用户能够精细地控制推理过程,而这在以前只能通过编程来实现。
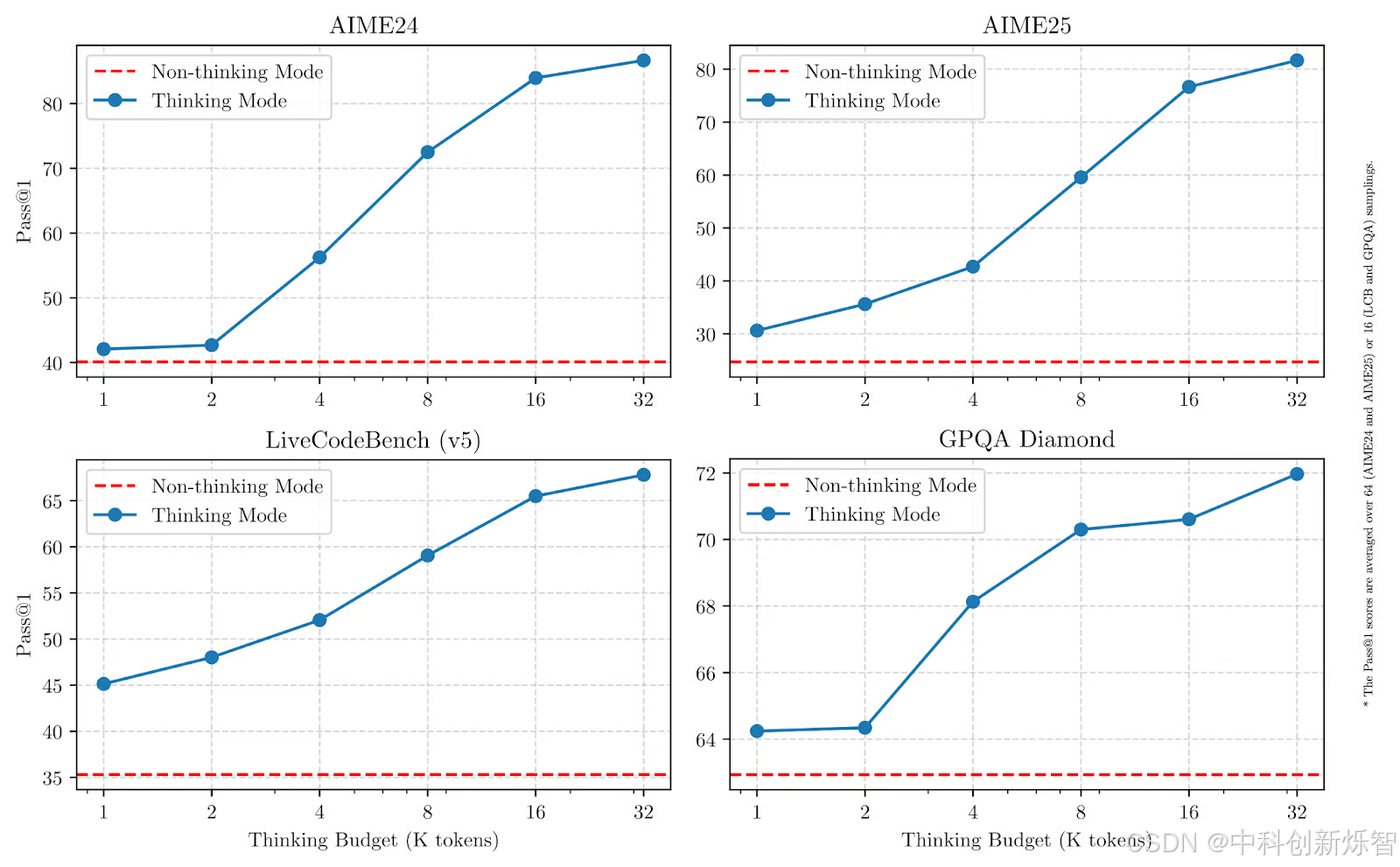
正如我们在下图中看到的,增加思考预算可以显著提高性能,尤其是数学、编码和科学方面。
在基准测试中,旗舰产品 Qwen3-235B-A22B 的表现与其他顶级模型相媲美,并且在编码、数学和一般推理方面表现出比DeepSeek-R1更佳的成绩。让我们快速探索每个模型,并了解其设计目的。
Qwen3-235B-A22B
这是 Qwen3 系列中最大的模型。它采用混合专家 (MoE)架构,总参数量达 2350 亿,每生成一步有 220 亿个活跃参数。
在 MoE 模型中,每一步只激活一小部分参数,与始终使用所有参数的密集模型(如 GPT-4o)相比,这使得运行速度更快、成本更低。
该模型在数学、推理和编码任务中表现良好,在基准比较中超越了 DeepSeek-R1 等模型。
Qwen3-30B-A3B
Qwen3-30B-A3B 是一个较小的 MoE 模型,总参数量为 300 亿,每一步仅激活 30 亿个参数。尽管激活参数数量较少,但其性能与QwQ-32B等规模更大的密集模型相当。对于希望兼顾推理能力和较低推理成本的用户来说,它是一个实用的选择。与 235B 模型一样,它支持 128K 上下文窗口,并在 Apache 2.0 下运行。
密集模型:32B、14B、8B、4B、1.7B、0.6B
Qwen3 版本中的六个密集模型遵循更传统的架构,其中所有参数在每一步都处于活动状态。它们涵盖了广泛的用例:
Qwen3-32B、14B、8B 支持 128K 上下文窗口,而 Qwen3-4B、1.7B、0.6B 支持 32K。所有模型均为开放加权模型,并采用 Apache 2.0 许可证。该组中较小的模型非常适合轻量级部署,而较大的模型则更接近通用 LLM。
您应该选择哪种型号?
Qwen3 提供不同的模型,具体取决于您需要的推理深度、速度和计算成本。以下是简要概述:
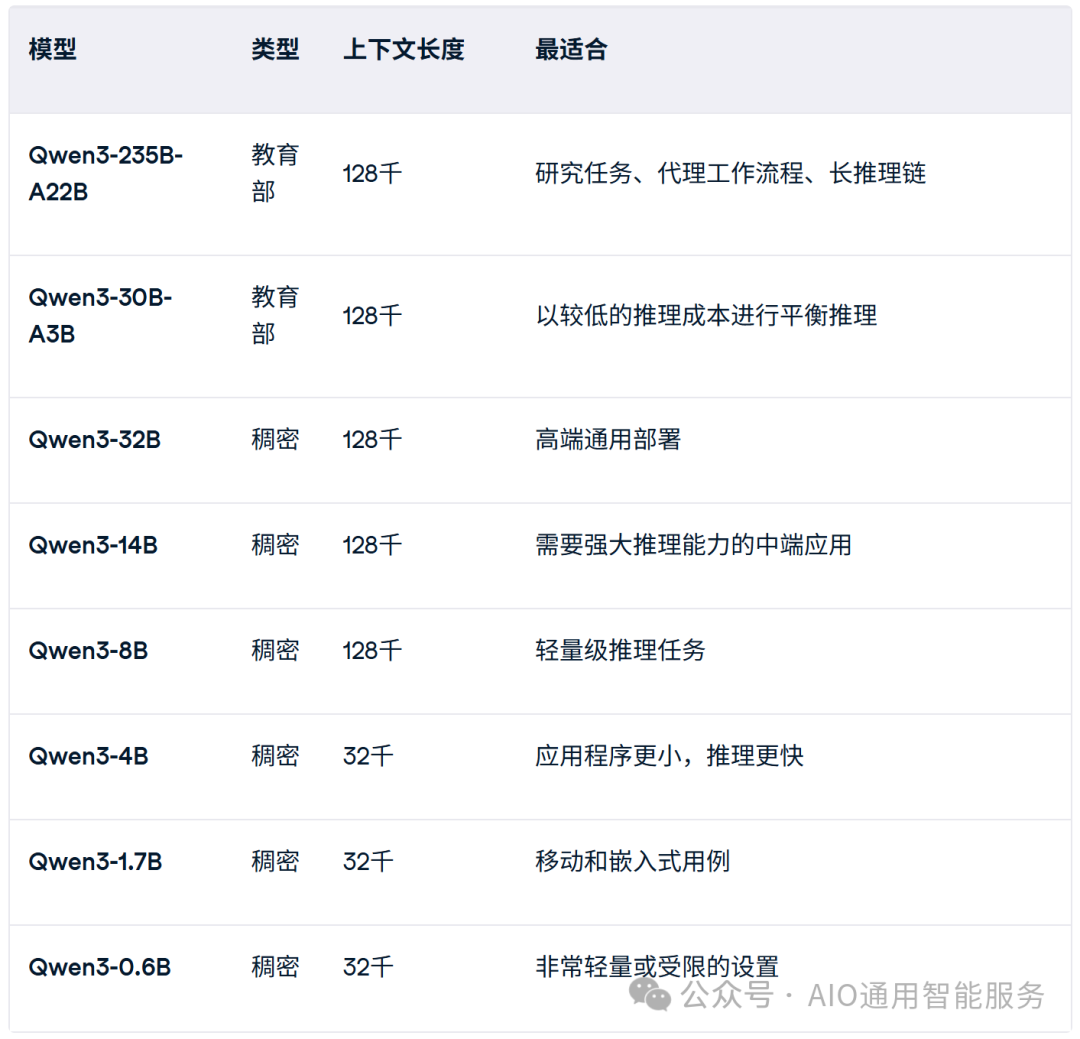
如果您正在执行需要更深入的推理、代理工具使用或长上下文处理的任务,Qwen3-235B-A22B 将为您提供最大的灵活性。
对于您希望保持推理更快、更便宜,同时仍处理中等复杂任务的情况,Qwen3-30B-A3B 是一个不错的选择。
密集模型提供更简单的部署和可预测的延迟,使其更适合小规模应用程序。
Qwen3 是如何开发的
Qwen3 模型是通过三阶段预训练阶段和随后的四阶段后训练流程构建的。
预训练是指模型从海量数据(语言、逻辑、数学、代码)中学习通用模式,而无需明确指定具体操作。后训练是指对模型进行微调,使其能够以特定方式运行,例如进行仔细推理或遵循指令。
我将用简单的术语介绍这两个部分,但不会深入讲解技术细节。
预训练
与 Qwen2.5 相比,Qwen3 的预训练数据集显著扩展。使用了约 36 万亿个标记,是上一代的两倍。数据包括网页内容、从文档中提取的文本以及 Qwen2.5 模型生成的综合数学和代码示例。
预训练过程分为三个阶段:
-
第一阶段:使用超过 30 万亿个标记、4K 上下文长度来学习基本的语言和知识技能。
-
第二阶段:对数据集进行改进,增加 STEM、编码和推理数据的份额,随后增加 5 万亿个标记。
-
第三阶段:使用高质量的长上下文数据将模型扩展到 32K 上下文窗口。
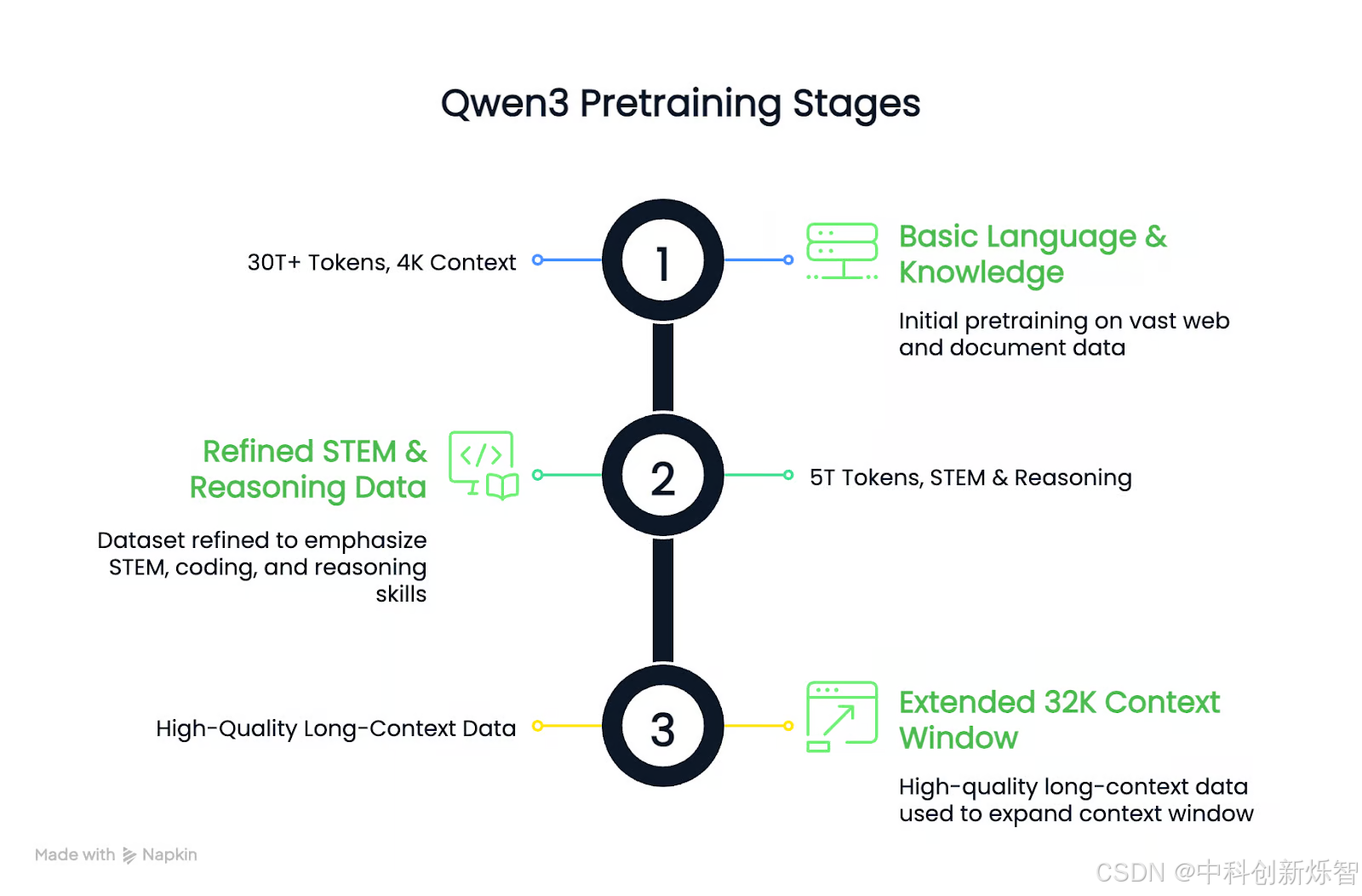
结果是,密集的 Qwen3 基础模型在使用更少参数的情况下匹配或优于更大的 Qwen2.5 基础模型,尤其是在 STEM 和推理任务中。
训练后
Qwen3 的训练后流程专注于将深度推理和快速响应能力融入到单个模型中。我们先来看一下下面的图,然后我会一步一步解释:
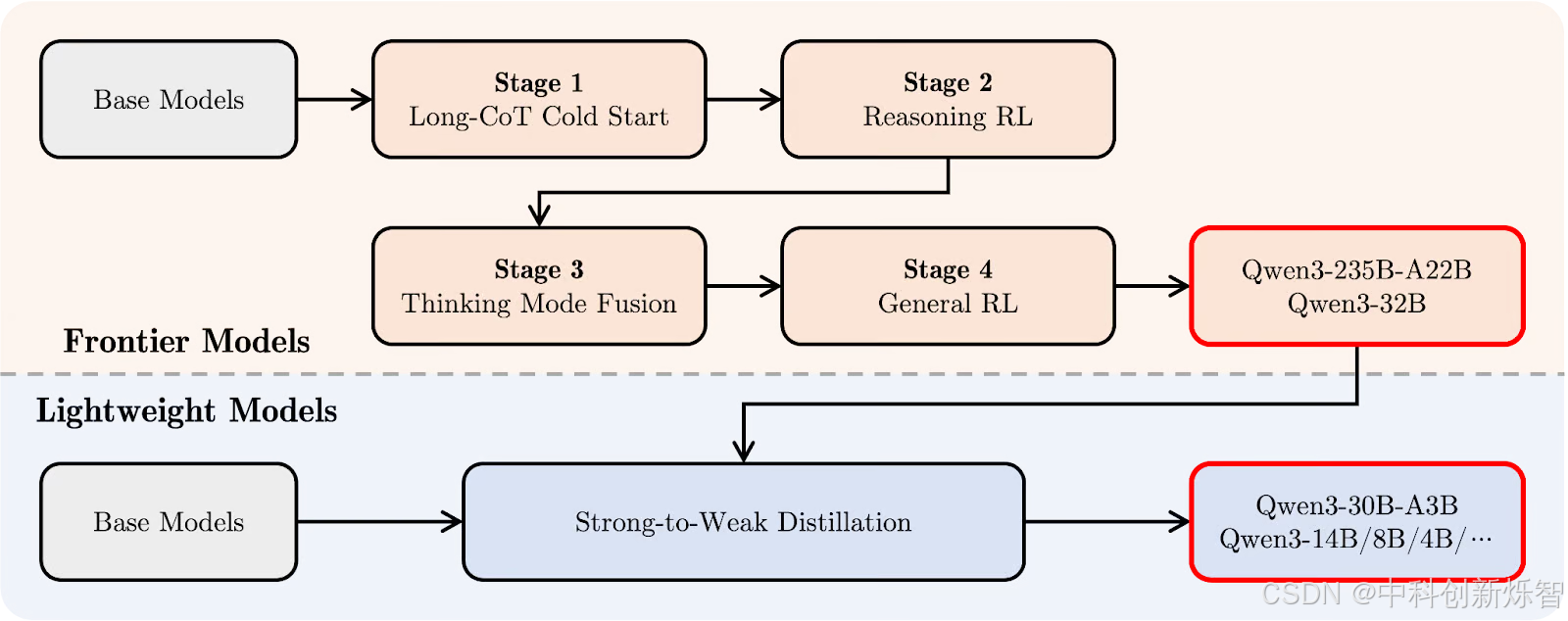
在顶部(橙色部分),你可以看到更大的“前沿模型”(例如 Qwen3-235B-A22B 和 Qwen3-32B)的开发路径。它始于长链思维冷启动(第一阶段),在此阶段,模型逐步学习对更困难的任务进行推理。
接下来是推理强化学习(RL) (第二阶段),旨在鼓励更优的解决问题策略。在第三阶段,即思维模式融合阶段,Qwen3 学习如何在缓慢、谨慎的推理和更快的反应之间取得平衡。最后,通用强化学习阶段将改进其在各种任务中的行为,例如遵循指令和代理用例。
在其下方(浅蓝色部分),您将看到“轻量级模型”的路径,例如 Qwen3-30B-A3B 和较小的密集模型。这些模型使用强到弱的蒸馏进行训练,这个过程将较大模型中的知识压缩到较小、更快的模型中,而不会损失太多推理能力。
简单来说:先训练大型模型,然后从中提炼出轻量级模型。这样,即使模型大小差异很大,整个 Qwen3 系列也拥有类似的思维方式。
Qwen 3 基准测试
Qwen3 模型在一系列推理、编码和常识基准测试中进行了评估。结果表明,Qwen3-235B-A22B 在大多数任务中处于领先地位,但较小的 Qwen3-30B-A3B 和 Qwen3-4B 模型也表现出色。
Qwen3-235B-A22B和Qwen3-32B
在大多数基准测试中,Qwen3-235B-A22B 都属于性能最佳的型号,尽管并不总是领先。
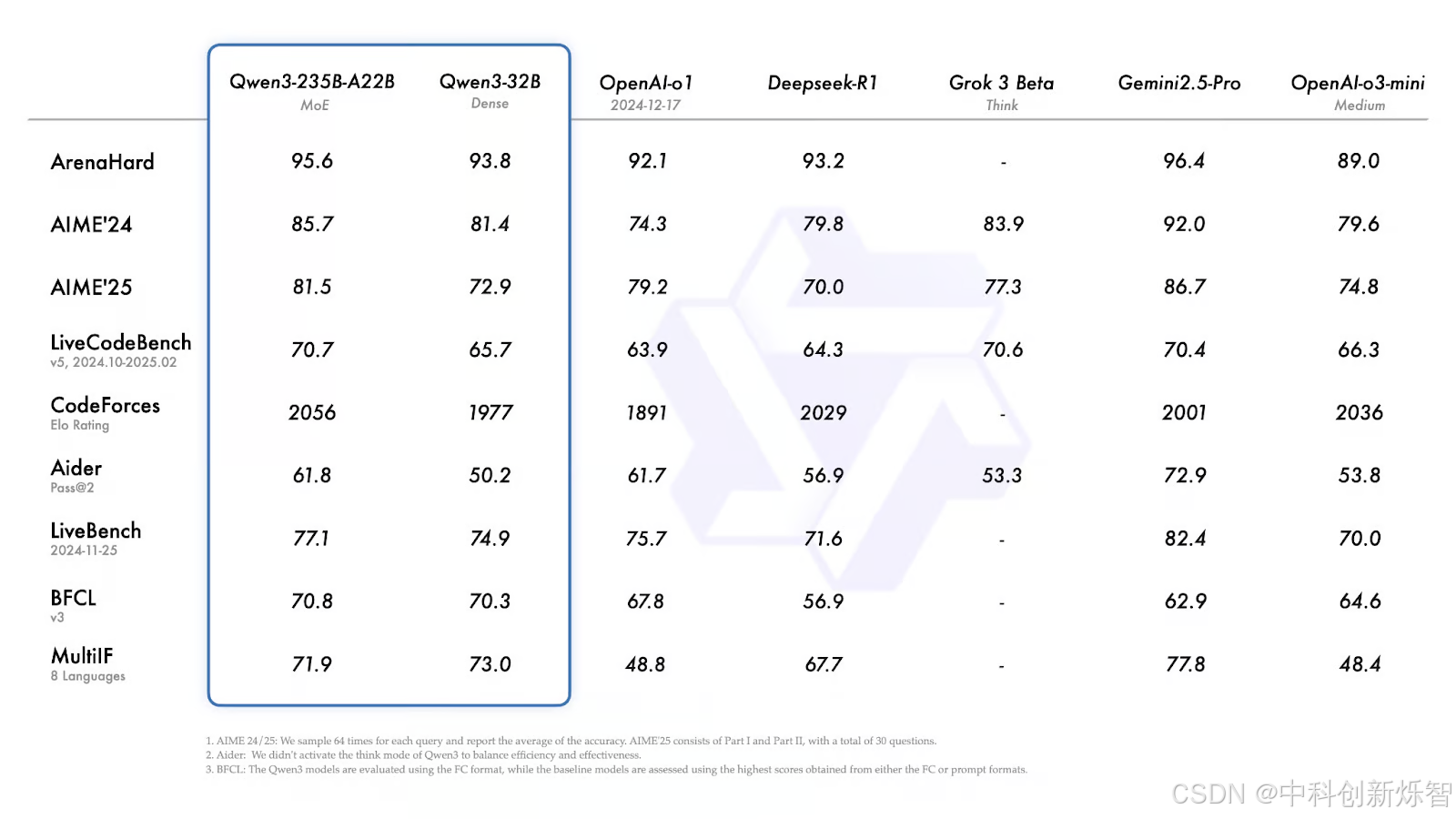
让我们快速探索一下上面的结果:
-
ArenaHard (总体推理):Gemini 2.5 Pro以 96.4 分领先。Qwen3-235B 紧随其后,得分为 95.6 分,领先于 o1 和 DeepSeek-R1。
-
AIME'24 / AIME'25 (数学):得分分别为 85.7 和 81.4。Gemini 2.5 Pro 再次排名更高,但 Qwen3-235B 的表现仍然优于 DeepSeek-R1、Grok 3 和 o3-mini。
-
LiveCodeBench (代码生成):235B 型号得分为 70.7——比 Gemini 以外的大多数型号都要好。
-
CodeForces Elo (竞技编程):2056,高于包括 DeepSeek-R1 和 Gemini 2.5 Pro 在内的所有其他列出的型号。
-
LiveBench (实际通用任务):77.1,再次仅次于 Gemini 2.5 Pro。
-
MultiIF (多语言推理):较小的 Qwen3-32B 在这里得分更高(73.0),但仍然落后于 Gemini(77.8)。
Qwen3-30B-A3B 和 Qwen3-4B
Qwen3-30B-A3B(较小的 MoE 模型)在几乎所有基准测试中都表现良好,始终匹敌或超越类似大小的密集模型。
-
ArenaHard:91.0——高于 QwQ-32B(89.5)、DeepSeek-V3(85.5)和 GPT-4o(85.3)。
-
AIME'24 / AIME'25 :80.4——略微领先于 QwQ-32B,但远远领先于其他型号。
-
CodeForces Elo :1974 年——略低于 QwQ-32B(1982 年)。
-
GPQA (研究生水平 QA):65.8——与 QwQ-32B 大致持平。
-
MultiIF:72.2——高于QwQ-32B(68.3)。
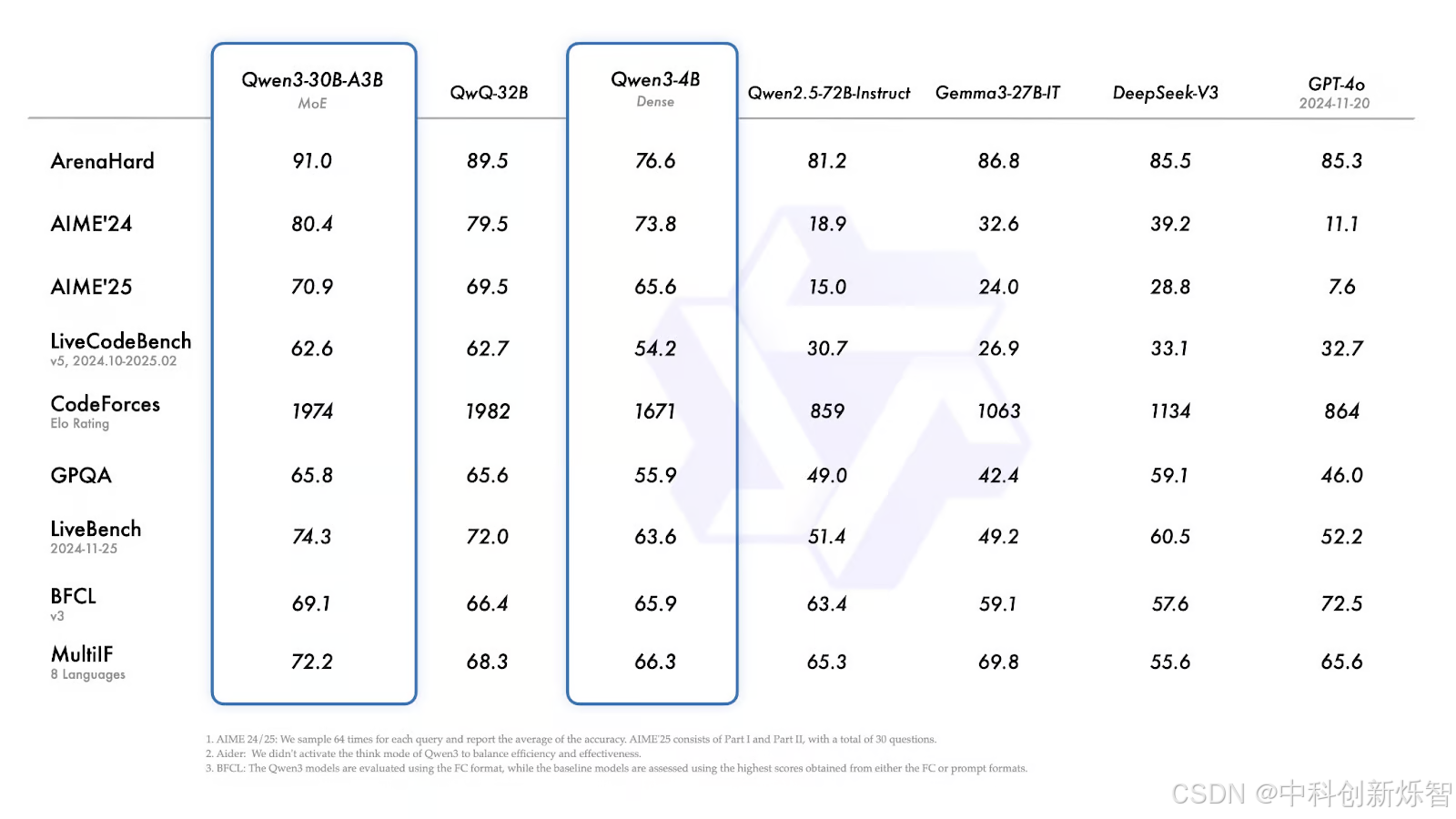
Qwen3-4B 的性能就其尺寸而言非常稳定:
-
竞技场难度:76.6
-
AIME'24 / AIME'25:73.8 和 65.6——明显比早期且更大的 Qwen2.5 模型和 Gemma-27B-IT 等模型更强。
-
CodeForces Elo:1671——与较大的模型相比没有竞争力,但与其重量级相当。
-
MultiIF:66.3——对于 4B 密集模型来说相当不错,并且明显领先于许多类似大小的基线。
结论
Qwen3是目前为止发布的最完整的开放重量模型套件之一。
旗舰级 235B MoE 模型在推理、数学和编码任务中表现出色,而 30B 和 4B 版本则为小规模或预算有限的部署提供了实用的替代方案。调整模型思维预算的功能为普通用户带来了额外的灵活性。
目前,Qwen3 是一个全面的版本,涵盖了广泛的用例,可以在研究和生产环境中使用。
探索智能边界,发现无限可能!(AIOAGI.TECH)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)