江大白 | DeepSeek的风吹到了多模态,Visual-RFT发布,视觉任务性能飙升20%!(附论文及源码)
上交大提出 Visual-RFT,将 RFT 扩展至视觉任务,借可验证奖励函数(如 IoU、分类准确率奖励)与策略优化,提升 LVLMs 性能。实验显示,少样本场景下视觉任务性能飙升 20%+,相关成果开源。
本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:DeepSeek的风吹到了多模态,Visual-RFT发布,视觉任务性能飙升20%!(附论文及源码)
导读
上交大提出 Visual-RFT,将 RFT 扩展至视觉任务,借可验证奖励函数(如 IoU、分类准确率奖励)与策略优化,提升 LVLMs 性能。实验显示,少样本场景下视觉任务性能飙升 20%+,相关成果开源。
尽管DeepSeek-R1风格的模型在语言模型中已经取得了成功,但其在多模态领域的应用仍然有待深入探索。
上交大等提出并开源 Visual-RFT,将 RFT 扩展到视觉任务,通过设计针对不同视觉任务的可验证奖励函数,提升 LVLMs 在视觉感知和推理任务中的性能。
视觉强化微调(Visual-RFT)的概述。
与(a)数据驱动的视觉指令微调相比,(b)视觉强化微调(Visual-RFT)在有限数据下更具数据效率。(c)成功地将RFT应用于一系列多模态任务,并在底部展示了模型的推理过程示例。
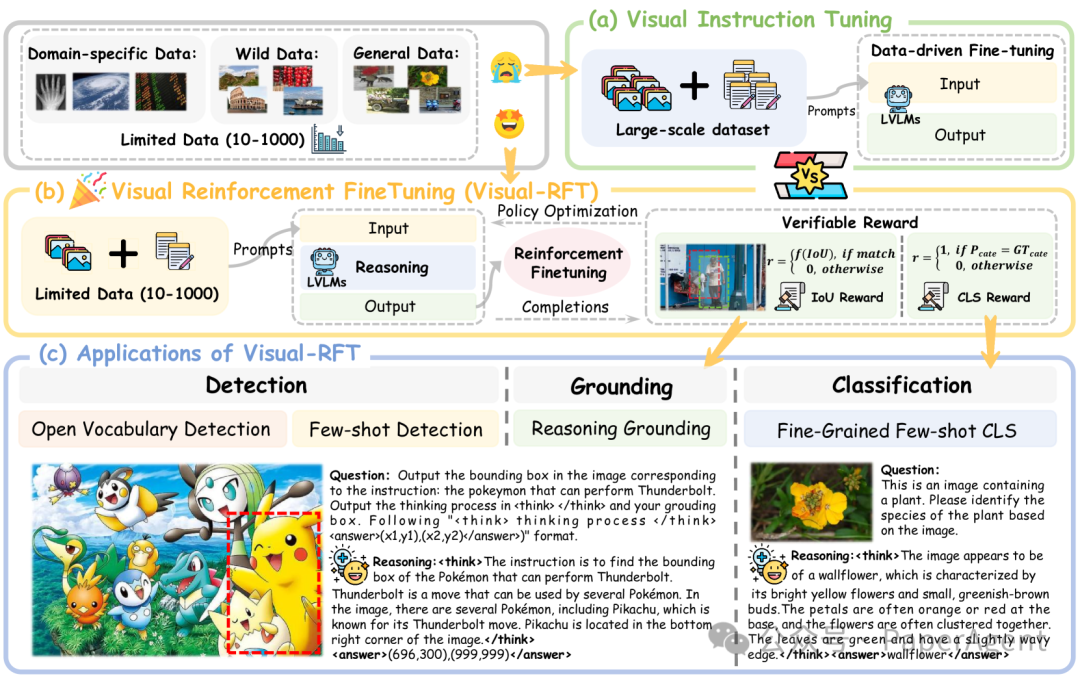
Visual-RFT 的核心在于利用 LVLMs 生成多个包含推理过程和最终答案的响应,并通过可验证奖励函数对模型进行策略优化。具体步骤如下:
-
任务输入:模型接收图像和问题作为输入。
-
响应生成:LVLMs 生成多个可能的响应,每个响应包含推理过程和最终答案。
-
奖励计算:针对不同任务(如目标检测、分类等),设计特定的可验证奖励函数,如 IoU 奖励(用于目标检测)和分类准确率奖励。
-
策略优化:使用 GRPO 等策略优化算法,根据奖励函数更新模型参数。
可验证奖励函数
-
IoU 奖励(目标检测):通过计算预测边界框与真实边界框的交并比(IoU)来评估检测任务的奖励。
-
分类准确率奖励(分类任务):通过比较模型输出类别与真实类别来评估奖励。
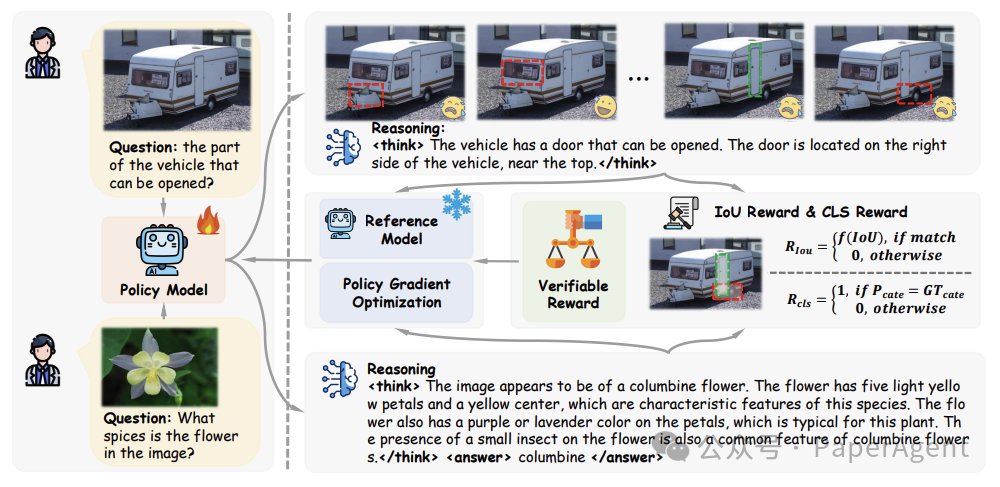
视觉强化微调(Visual-RFT)的框架。给定问题和视觉图像输入后,策略模型会生成多个包含推理步骤的响应。然后,使用可验证奖励(如IoU奖励和分类奖励)与策略梯度优化算法来更新策略模型。
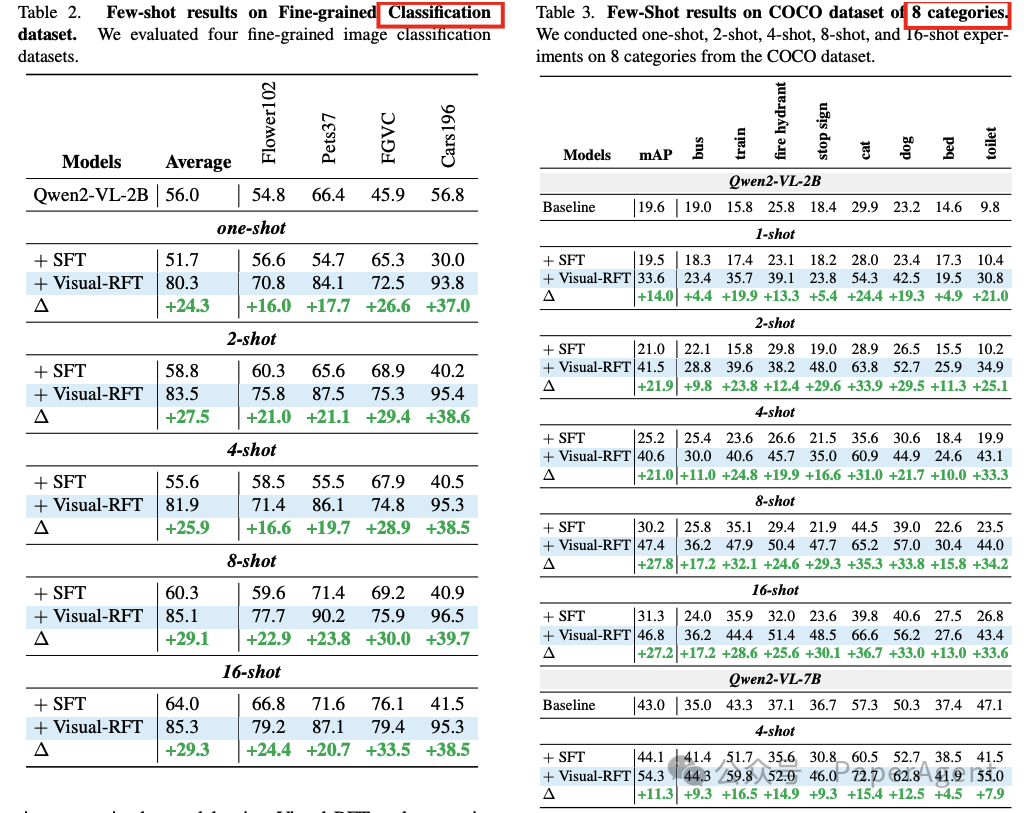
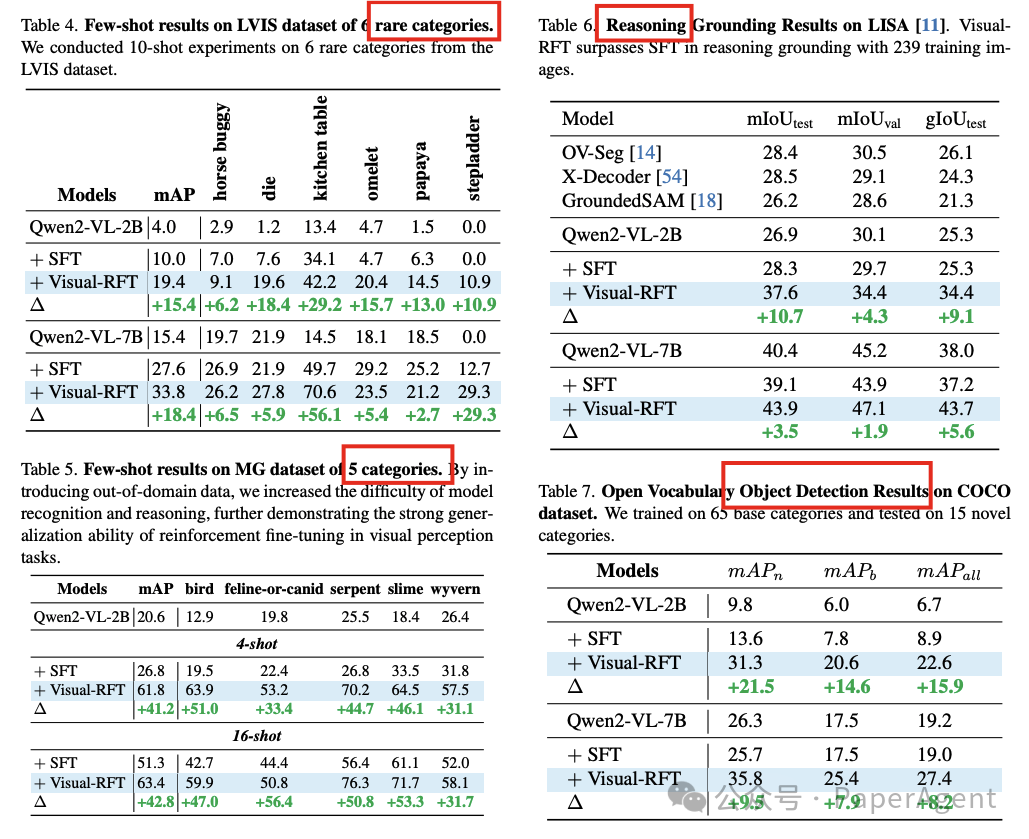
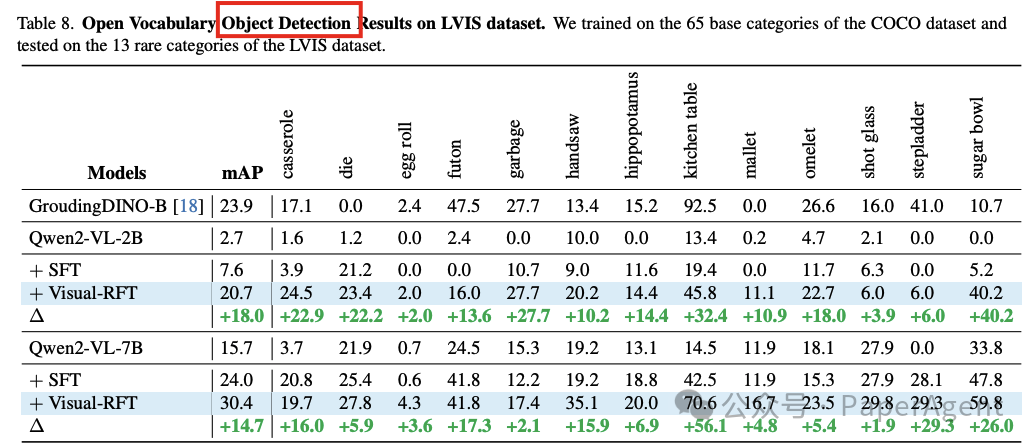
在细粒度图像分类、少样本目标检测、推理定位以及开放词汇目标检测基准测试中的实验结果表明,与监督微调(SFT)相比,Visual-RFT具有竞争力的性能和先进的泛化能力:
-
在大约100个样本的单样本细粒度图像分类中,Visual-RFT的准确率比基线提高了24.3%。
-
在少样本目标检测中,Visual-RFT在COCO的两样本设置中超过了基线21.9,在LVIS上超过了15.4。
Visual-RFT代表了对LVLMs微调范式的一种转变,提供了一种数据高效、由奖励驱动的方法,增强了对特定领域任务的推理能力和适应性。
细粒度图像分类的定性结果。推理过程显著提升了大型视觉语言模型(LVLMs)的推理能力,从而提高了图像分类的性能。
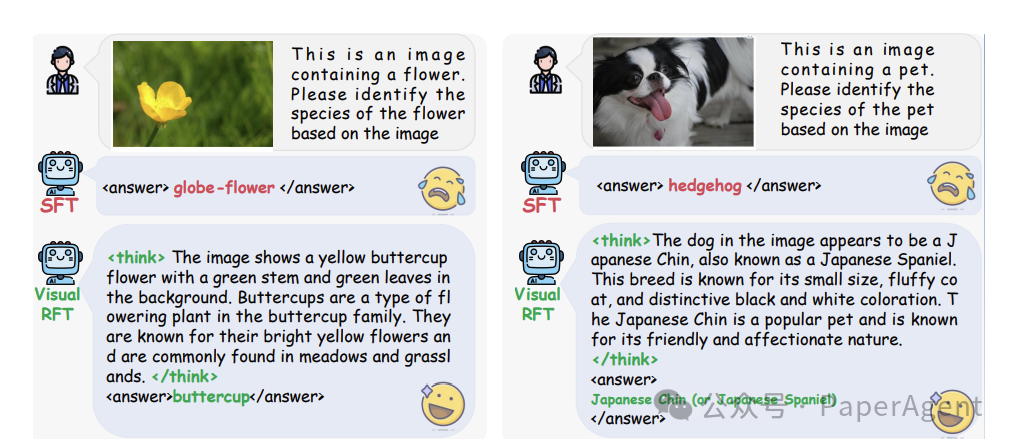
在LISA [11] 数据集上的推理定位任务的定性结果。通过Visual-RFT,推理过程显著提升了模型的推理定位能力。

https://arxiv.org/pdf/2503.01785Visual-RFT: Visual Reinforcement Fine-Tuninghttps://github.com/Liuziyu77/Visual-RFT
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 2
2 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)