个人笔记本安装deepseek-r1:7b-qwen-distill-q4_K_M模型
win11机器本地部署deepseek-r1-7b模型
系统:win11
CPU:i7-12800HX 16核
内存:8GB SK Hynix 4800MHz 双通道
显卡:RTX3070Ti Laptop 8GB显存
下载ollama
ollama官网地址
ollama github地址
当前系统是windows11
-
Ollama 是一个开源的本地大语言模型运行框架,可以在本地机器上便捷部署和运行大型语言模型(LLM)。
-
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
-
Ollama 提供对模型量化的支持,可以降低显存要求。
进入ollama官网,下载ollam。
将ollama安装在指定目录
将ollama安装包放入执行文件夹
点击路径框,ctrl+c复制当前路径
输入cmd后回车
进入命令行窗口后,输入oll然后按tab建会补全ollama安装包命令,然后输入 /DIR=${要安装的路径}。
这是我的路径
OllamaSetup.exe /DIR=E:\MyTools\OllamaDir
回车,点击 install 安装ollma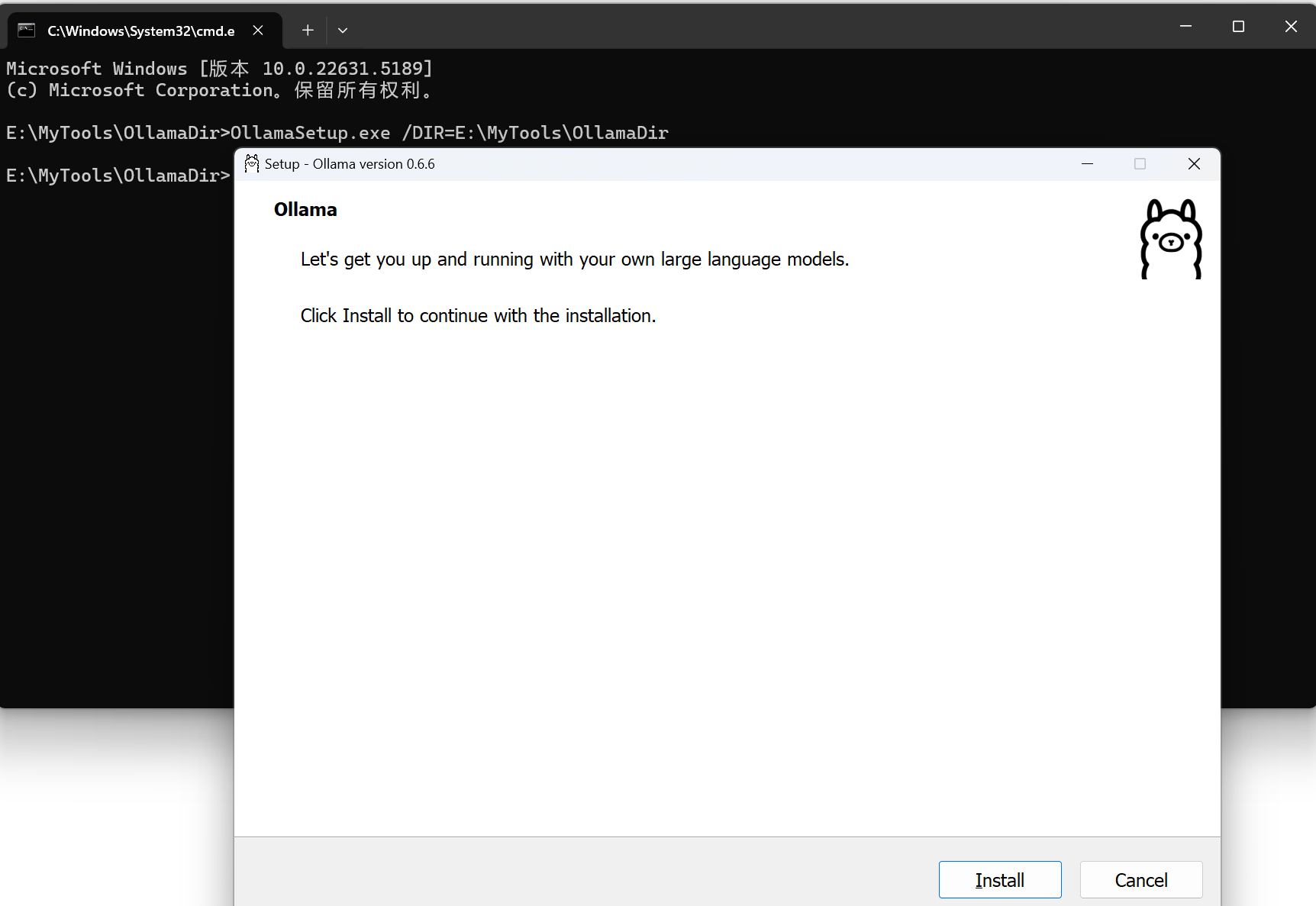
安装完成后,后台会出现ollama图标
查看ollma是否安装成功
输入下列代码,查看当前ollama安装版本。
ollama -v
由下列图片显示,ollama可以不需要安装在c盘,也不需要手动配置ollama执行命令的环境变量。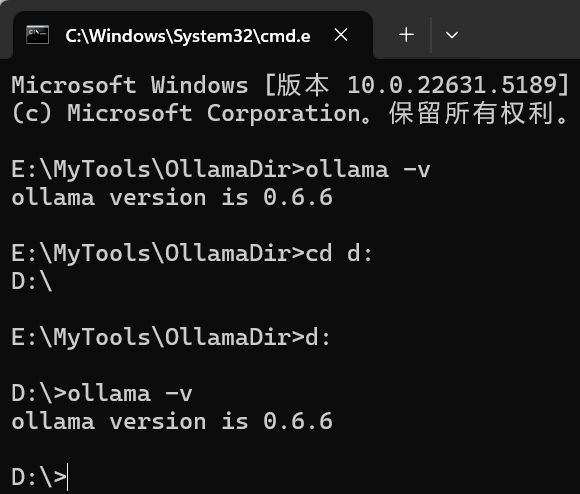
修改下载模型的安装位置
模型安装位置默认是在 C:\Users\xxx 下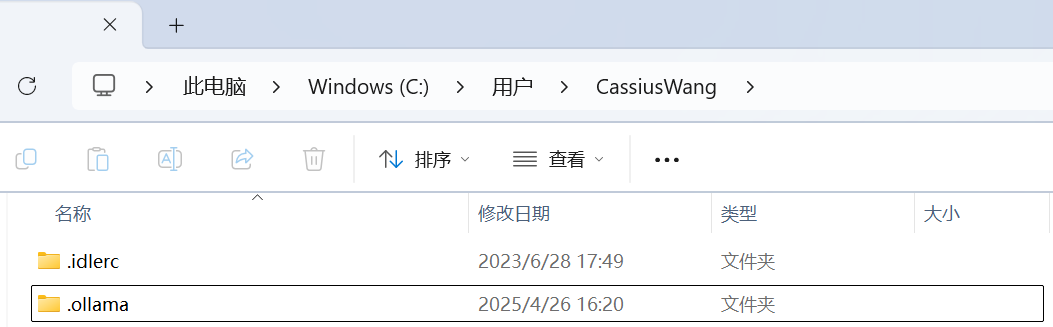
将.ollma文件夹复制到想要安装模型的目录
在刚刚安装ollama的目录下新建models文件夹,将c盘下的.ollama文件夹复制过来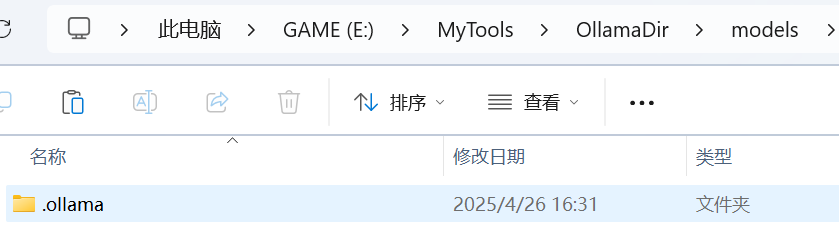
配置下载模型安装目录的环境变量
按下win键进入设置
选择 系统 -> 系统信息
选择高级系统设置
本机显卡是3070Ti,显存是8GB,
内存是16GB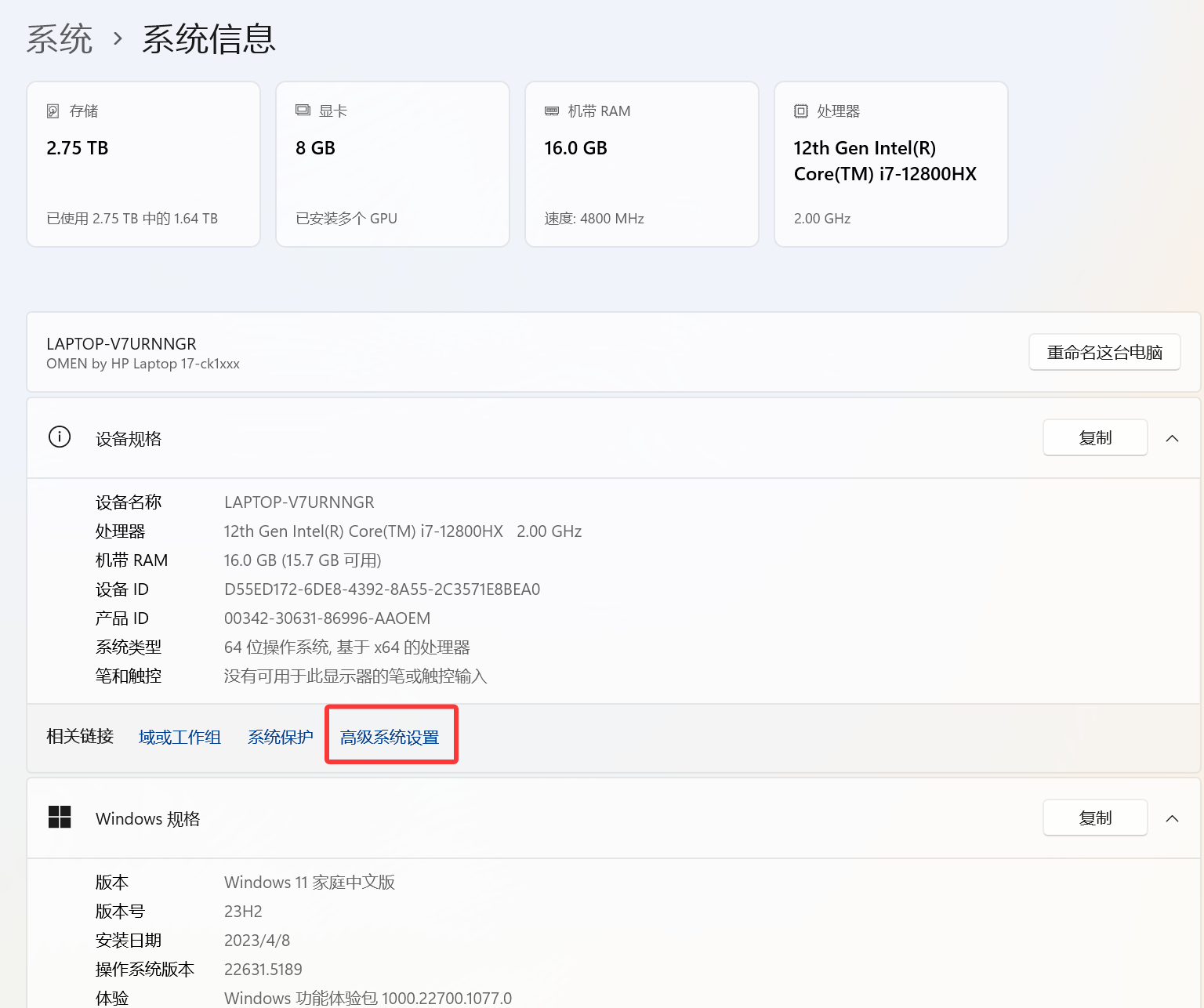
选择环境变量
在系统变量中新建环境变量
变量名:OLLAMA_MODELS
变量值:E:\MyTools\OllamaDir\models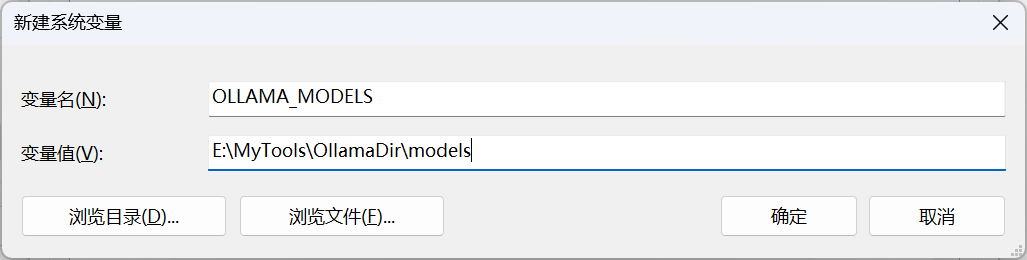
quit 退出ollama
重启ollama服务
在cmd窗口输入ollama会显示ollama相关命令用法
输入 ollama serve 后,ollama不是后台启动服务的,若将该窗口关闭,则ollama停止服务。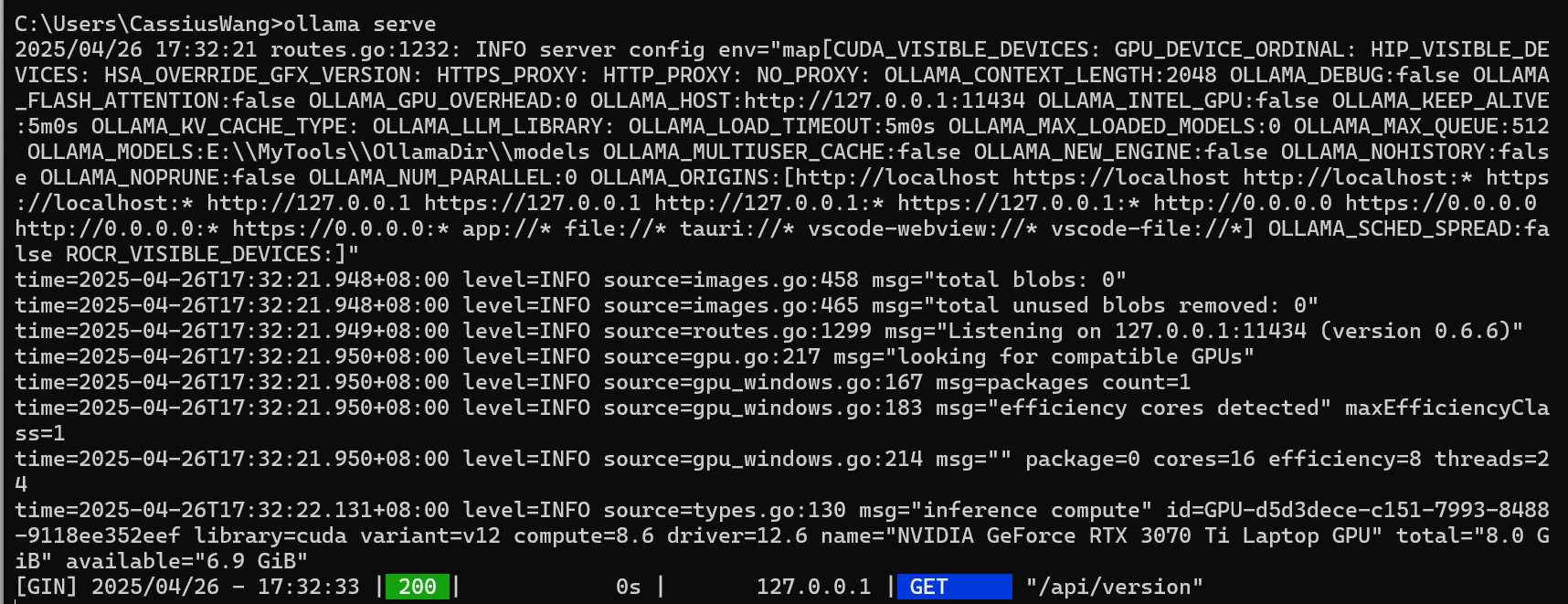
另外启动一个cmd窗口输入 ollama -v 则正常显示ollama服务;若是将启动服务的cmd窗口关闭,则会显示无法连接到一个运行的ollama实例上。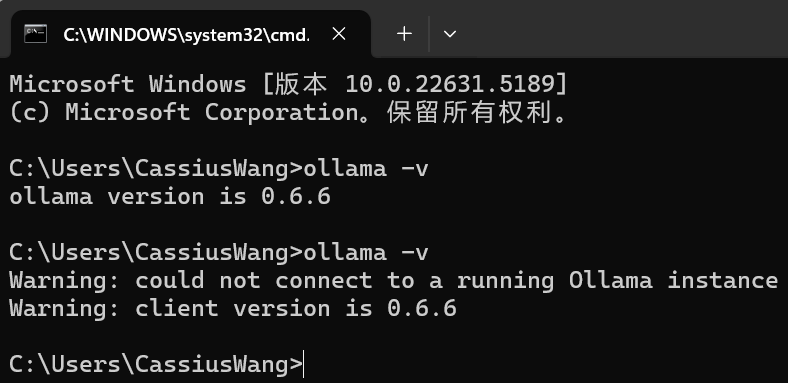
重启电脑后,ollama自动后台启动了。
选择deepseek模型
在命令行窗口输入 ollama list 查看已经安装的大语言模型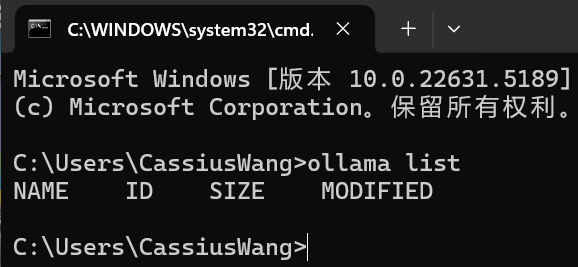
官网点击models查看可以安装的模型
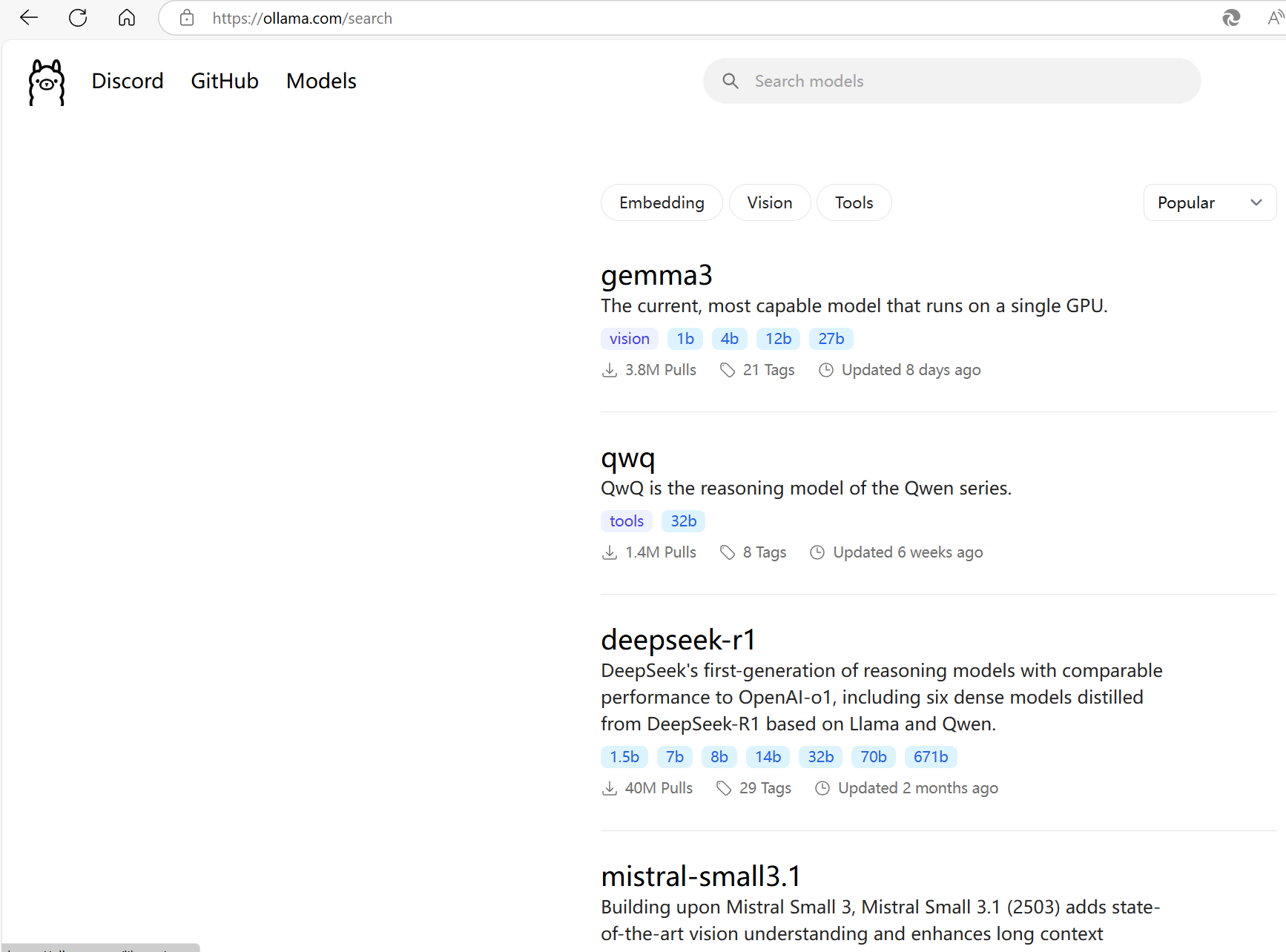
点击deepseek-r1查看各个版本的deepseek-r1模型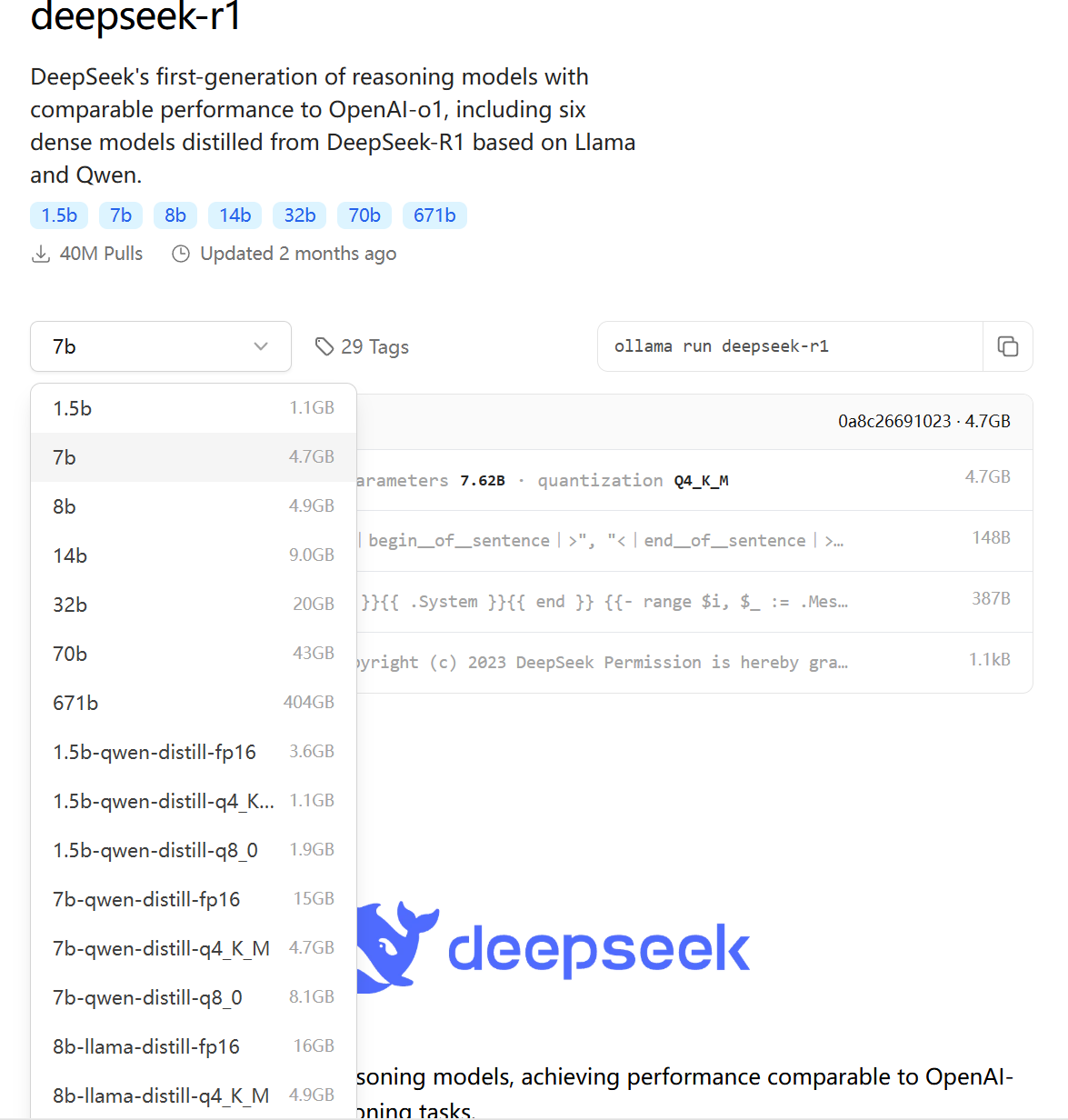
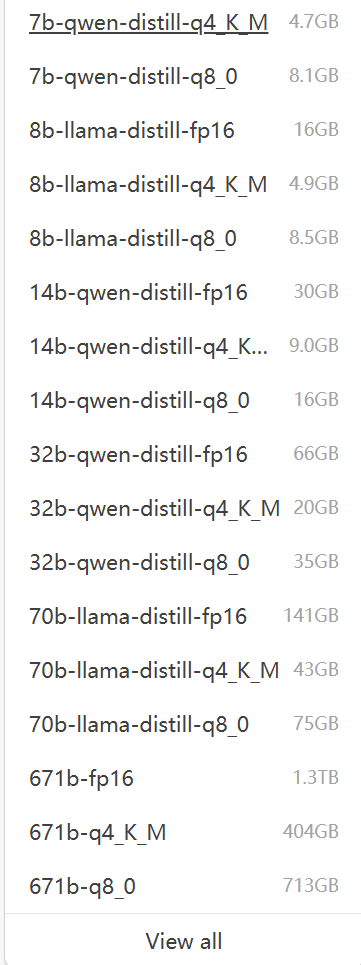
点击deepseek官网,进入deepseek的git hub地址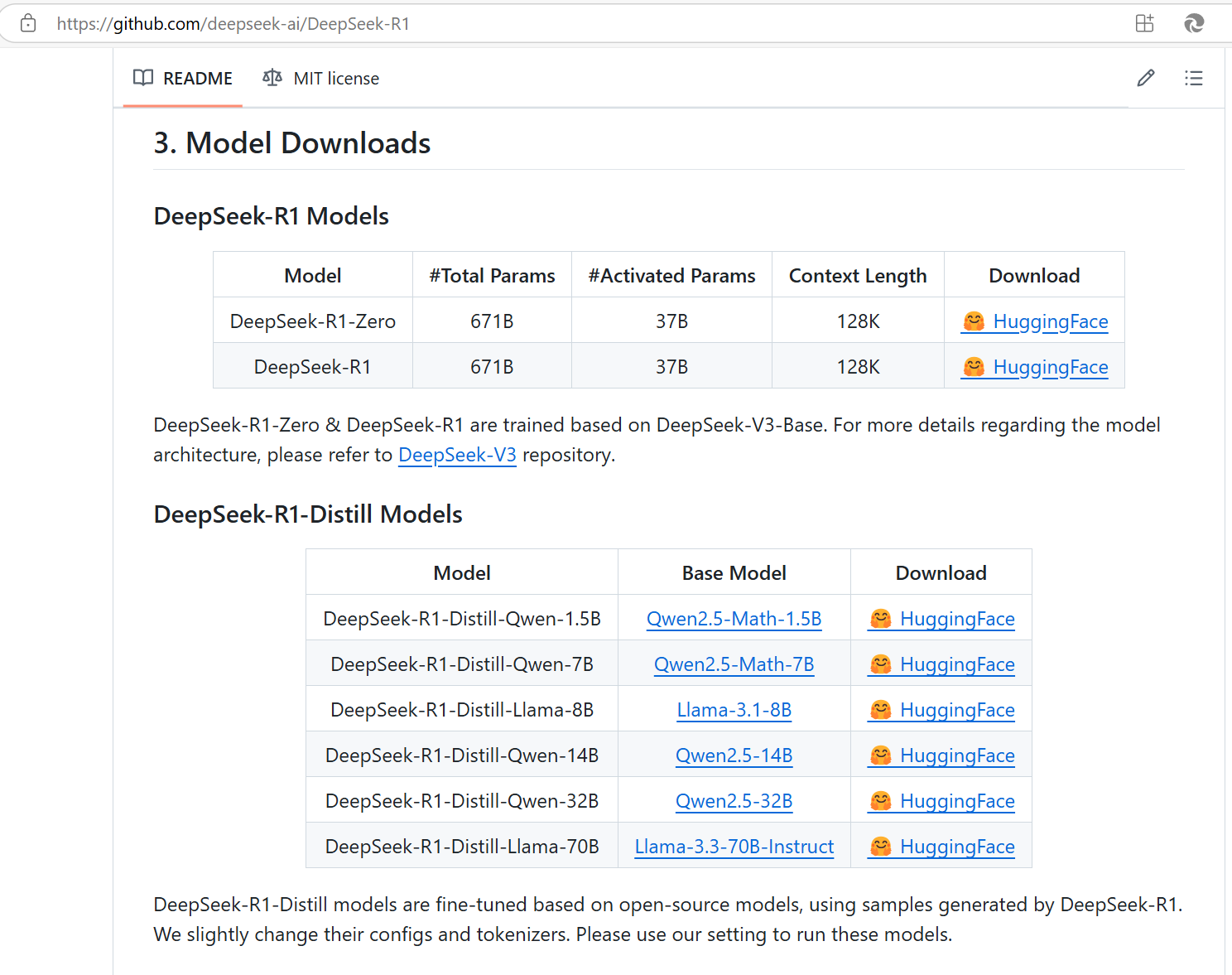
这里的B代表Billion——十亿,参数单位,参数越大模型越聪明。
deepseek官方发布了 DeepSeek-R1-Zero 与 DeepSeek-R1两种R1模型。其余的都是 基于Qwen 与 Llama 蒸馏得来的。
蒸馏,教师-学生范式,教师(DeepSeek-R1)-学生(Qwen2.5、Llama3.3等),将更大、更先进的知识传授给更小、更轻量级的模型。
用DeepSeek-R1的数据去训练Qwen、Llama,这两模型经过微调后得到的更轻量级的模型。
Qwen github地址:QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud.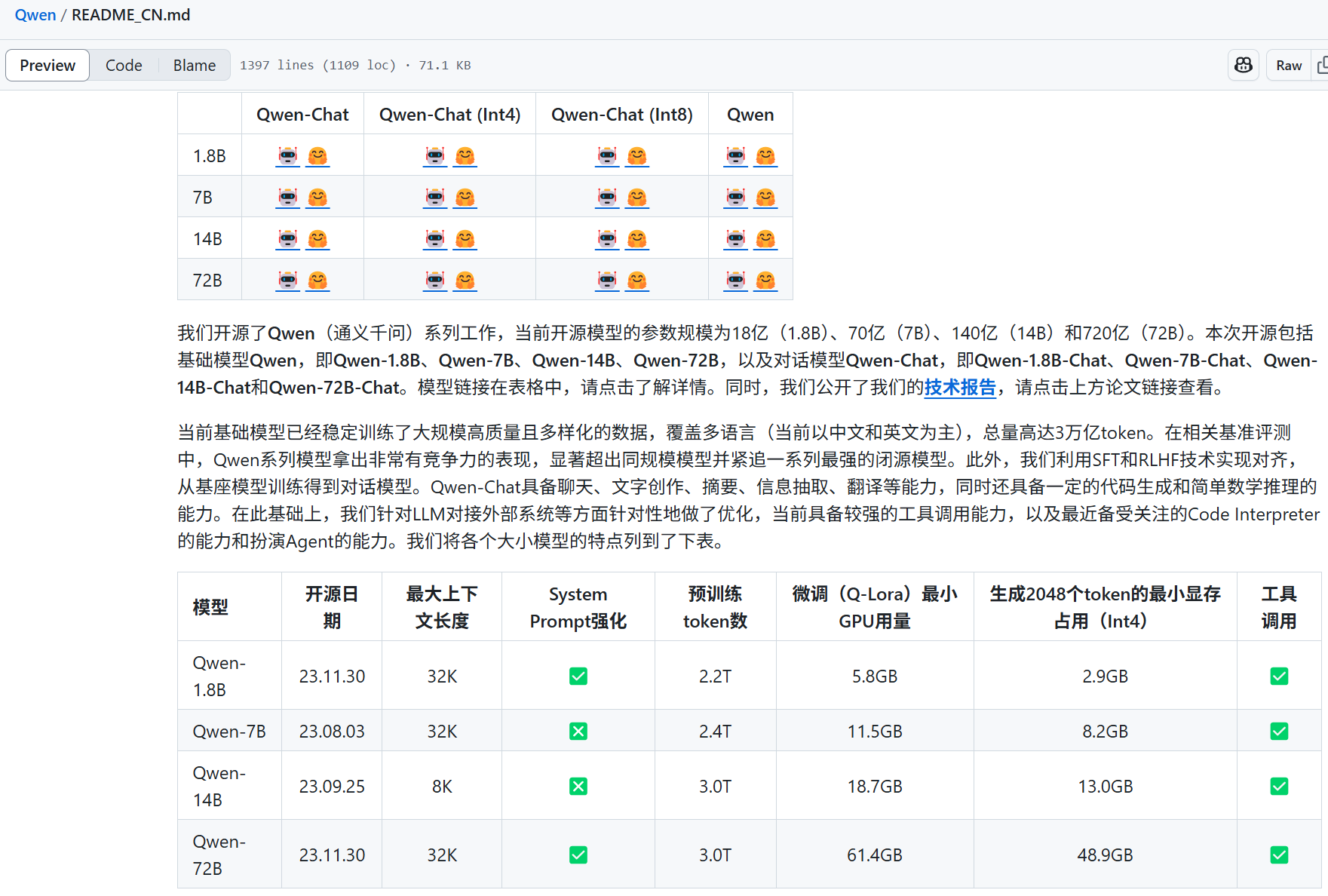
Llama中文官方地址:Llama-3品牌馆 · 魔搭社区
-
Qwen:通义千问,阿里巴巴的大语言模型,内部语言以中文与英文为主。
-
Llama:扎克伯格的Meta公司推出的大预言模型,内部语言以英文为主。
ollma官方github地址,文档上建议,用7B的模型至少要有8GB的内存可用空间,16GB运行13B模型,32GB运行33B模型。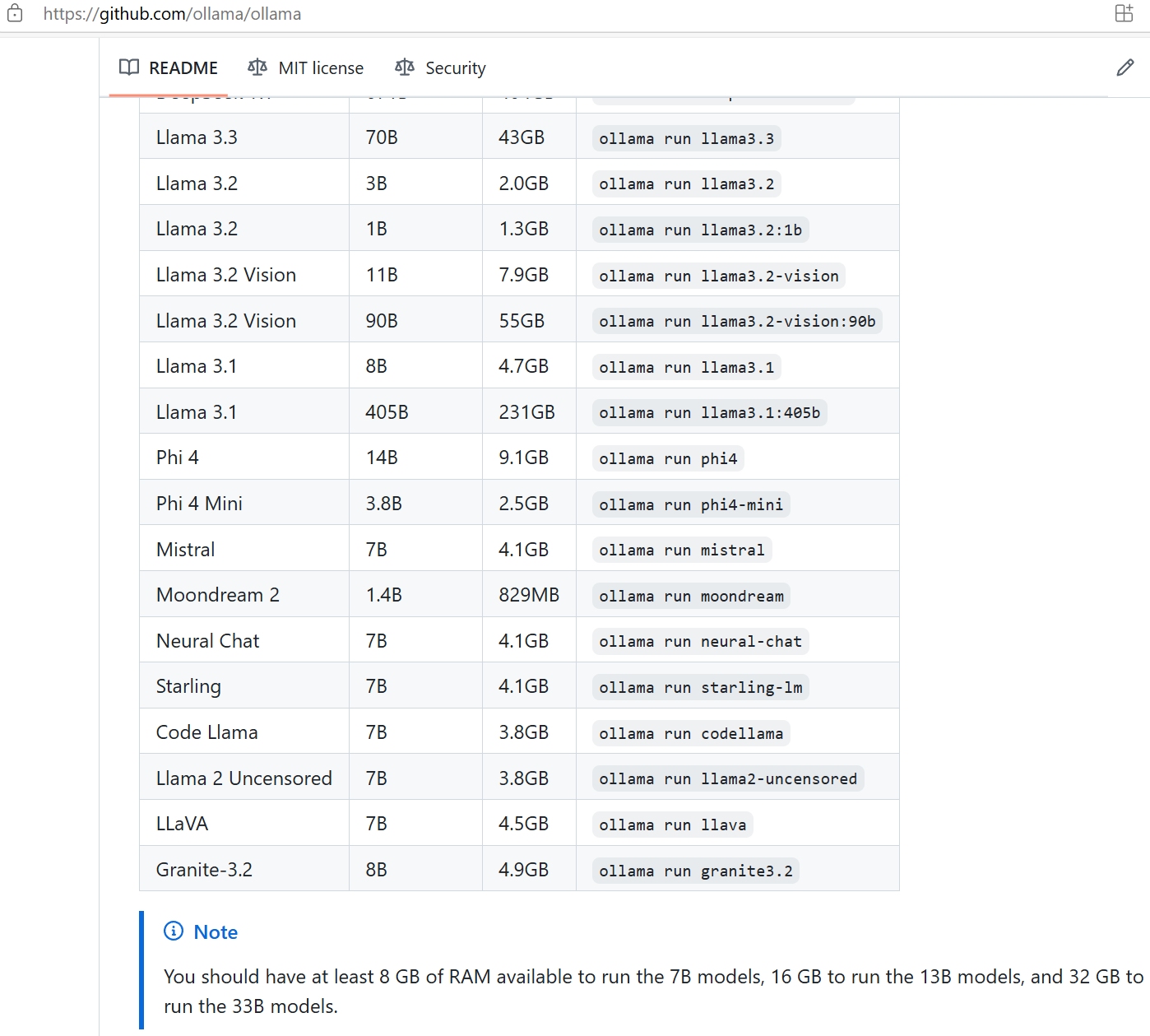
本机内存16GB,显卡RTX3070Ti,显存8GB,以中文提问为主,所以选择千问的7B蒸馏模型,Q4_K_M量化,占用4.7GB硬盘空间。
这里的quantization量化,是将模型参数量化,量化是为了减少资源占用。同一参数模型下,精度越高运行速度越慢,但是推理精度更高。
ollama官网提供了q4、q8、fp16。
-
q4:比特整数4位 4-bit
-
q8:比特整数8位 8-bit
-
fp16:半精度浮点数16位 float 16 Half-precision floating-point
比如7B模型参数,q4量化,来计算所需显存空间。
-
q4量化是4个比特位,1字节是8个比特位,所以是半个字节。
-
7B是70亿个模型参数,70亿 ✖ 0.5字节 = 35亿字节,差不多需要4GB显存空间。
-
1KB = 1024 byte,1MB = 1024KB,1GB = 1024MB;8GB = 8 ✖ 1024 ✖ 1024 ✖ 1024 = 8,073,741,824;将近80亿字节。
-
内存空间达到显存空间的1.5~2倍就可以运行推理模型了。
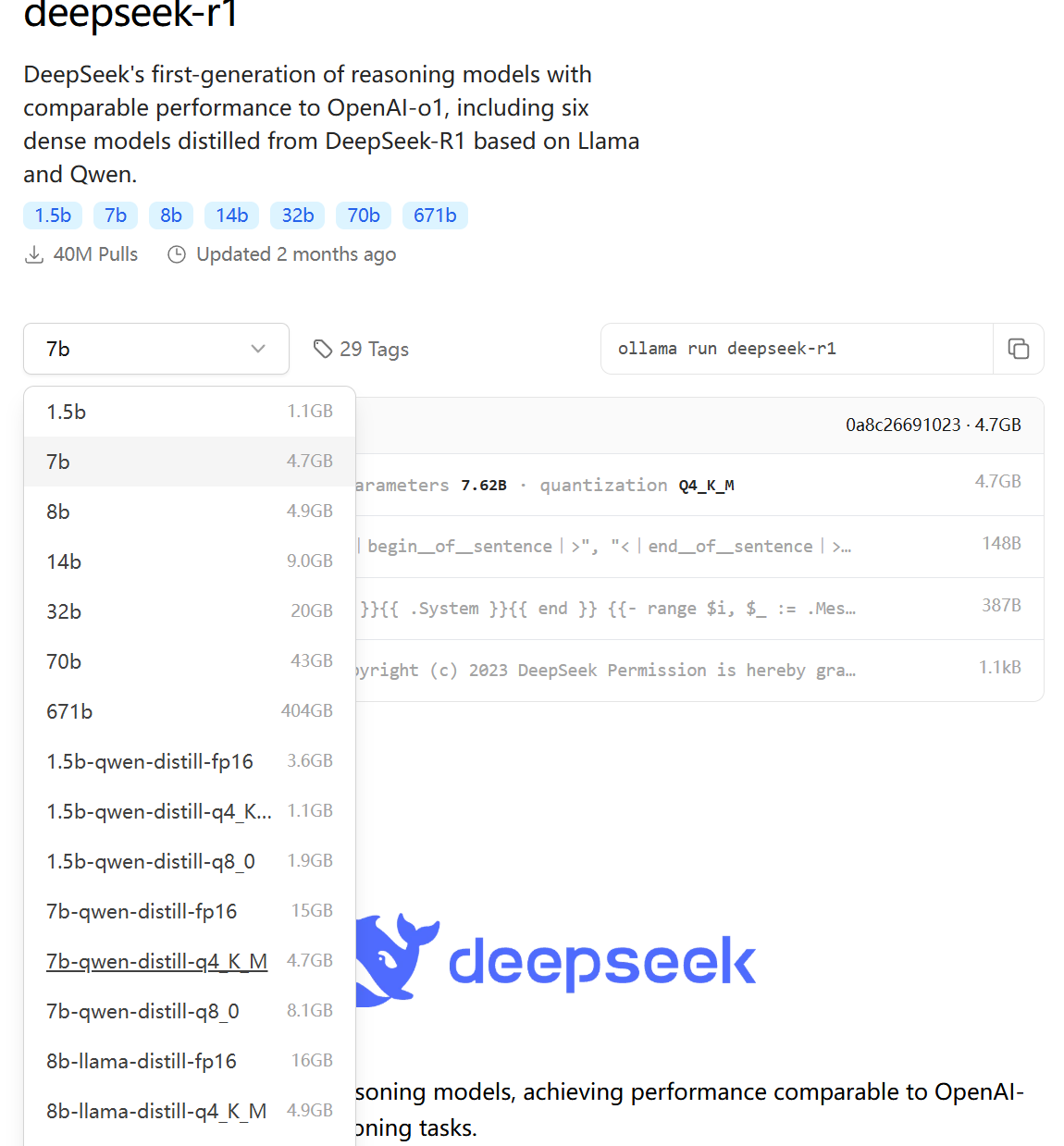
安装deepseek模型
点击图标 复制运行模型命令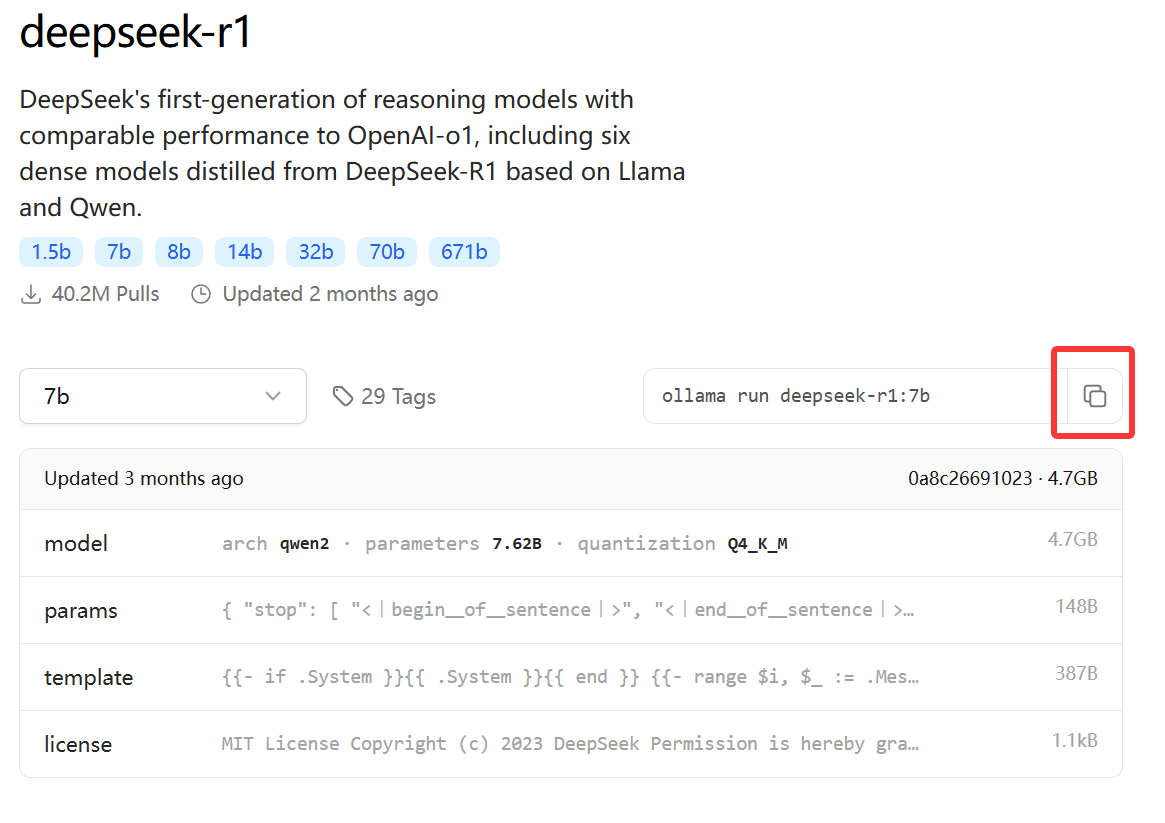
在命令行窗口粘贴命令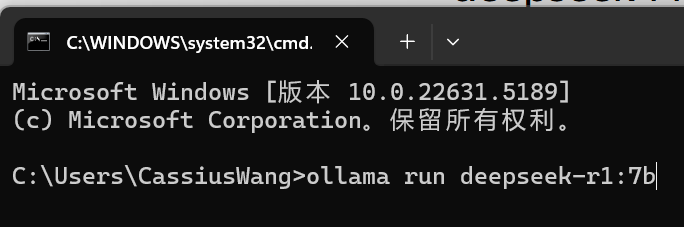
回车运行
当下载速度变慢
按ctrl+c停止下载,再按方向键 上,回车;重新连接下载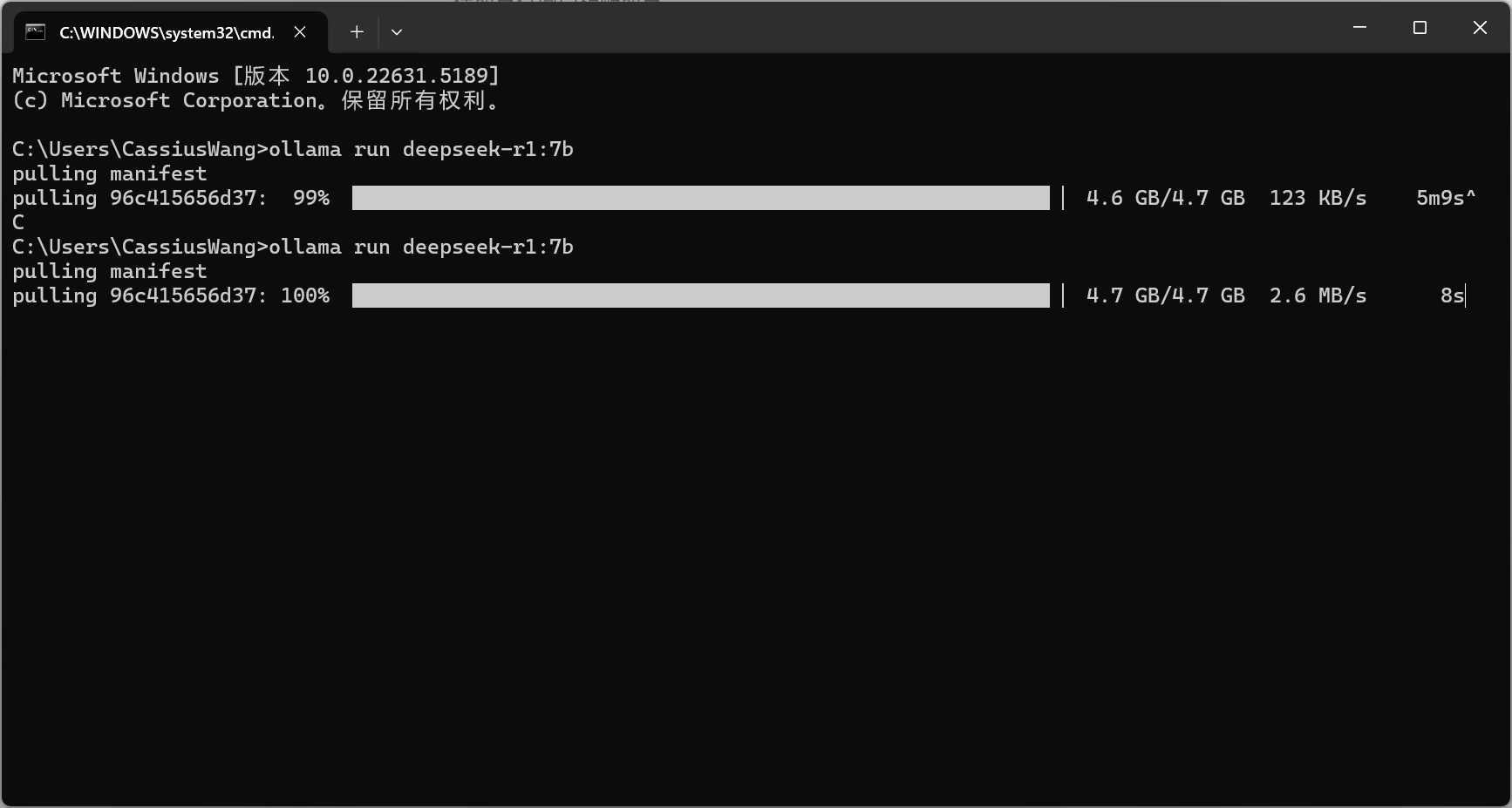
下载成功
输入 你是谁 ,模型回答成功。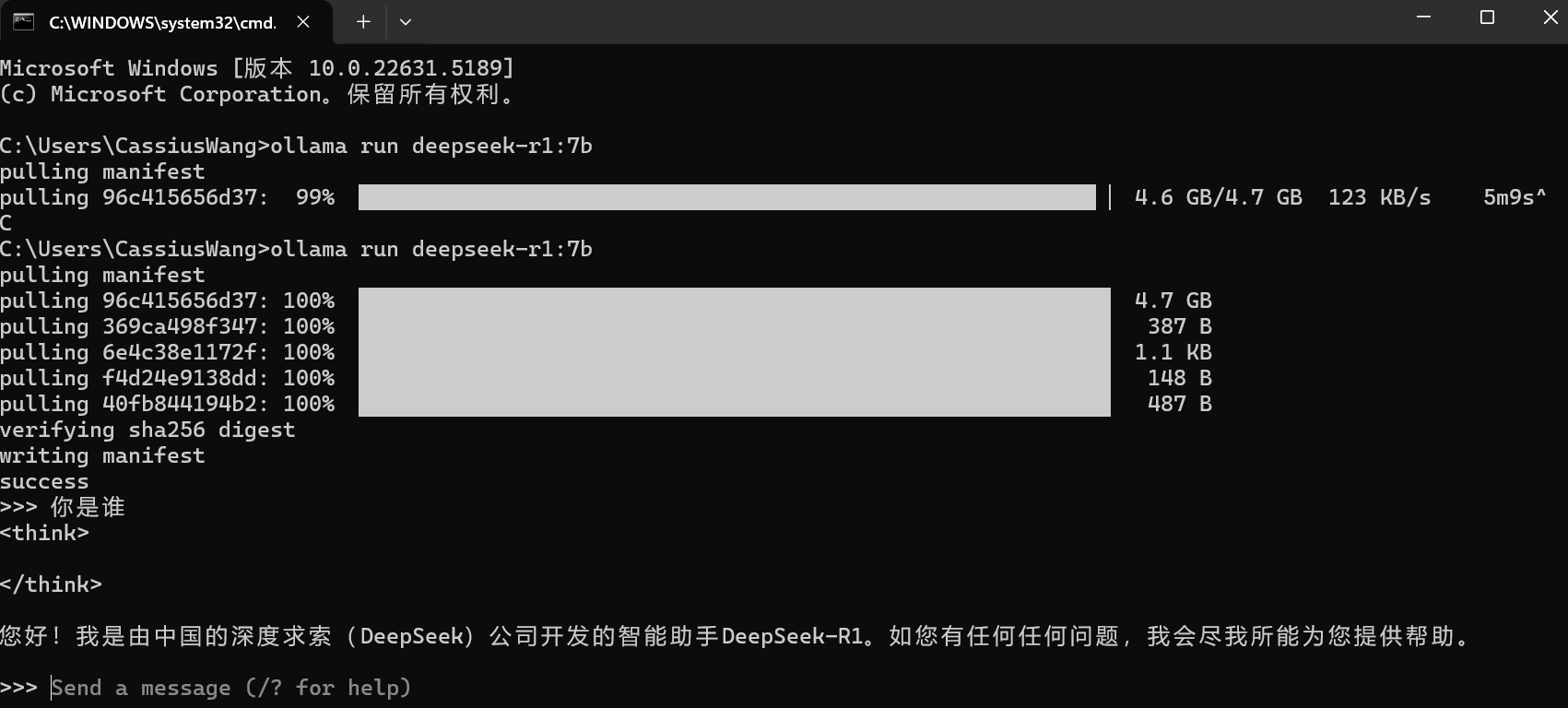
查看设置环境变量,模型存放空间的路径,显示4.36G,说明指定模型安装目录的环境变量设置成功。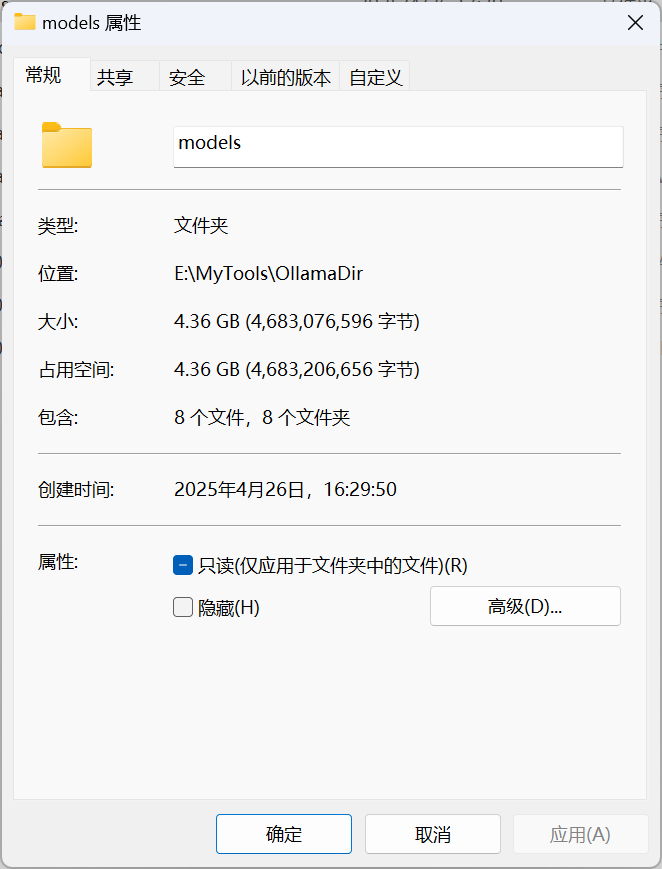
卸载ollama
点击 unins000.exe 卸载ollam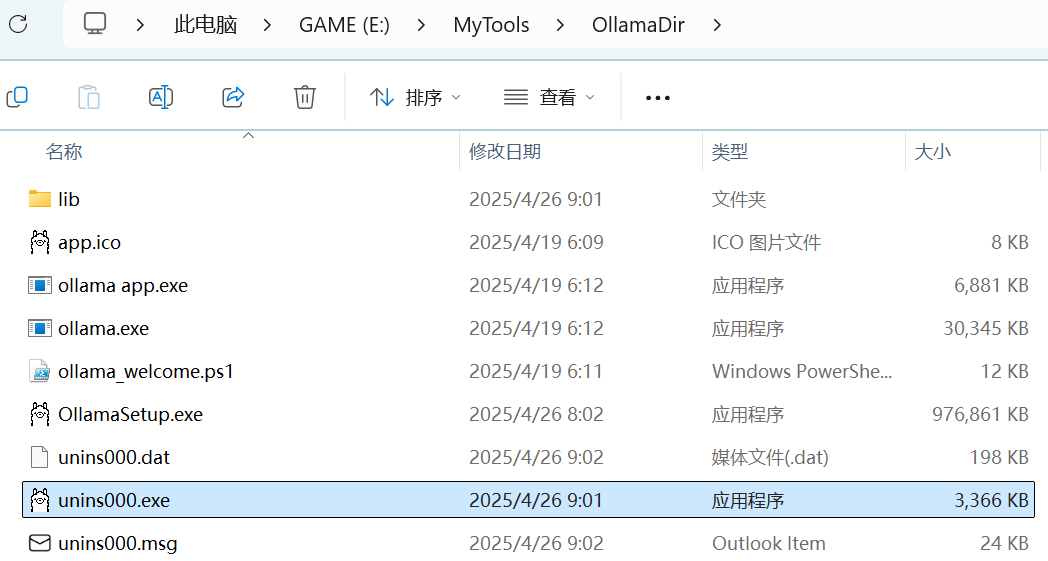
点击 y 确定卸载
卸载完成
输入 ollama-v 没有该命令,卸载成功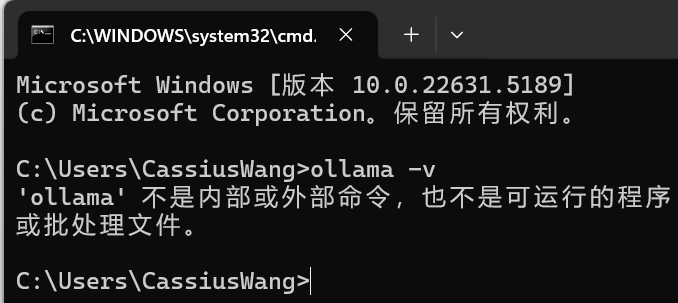

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)