基于LangChain+DeepSeek Api+Vue实现私有知识库项目
该项目基于FastAPI构建后端,集成LangChain实现多格式文档(TXT/PDF/Word)处理,通过文本分块、向量化(Ollama的bge-m3模型)和FAISS索引实现语义检索。结合DeepSeek API进行检索增强生成(RAG),流式返回问答结果。支持知识库元数据管理(MySQL)、文件上传(UUID重命名存储)和跨域访问。核心流程:用户上传文档→向量化存储→提问时检索相关片段→构造
·
1.使用语言
Python、Vue
2.技术要点
SSE、LangChain、Rag、FAISS、OllamaEmbeddings...
3.项目流程图
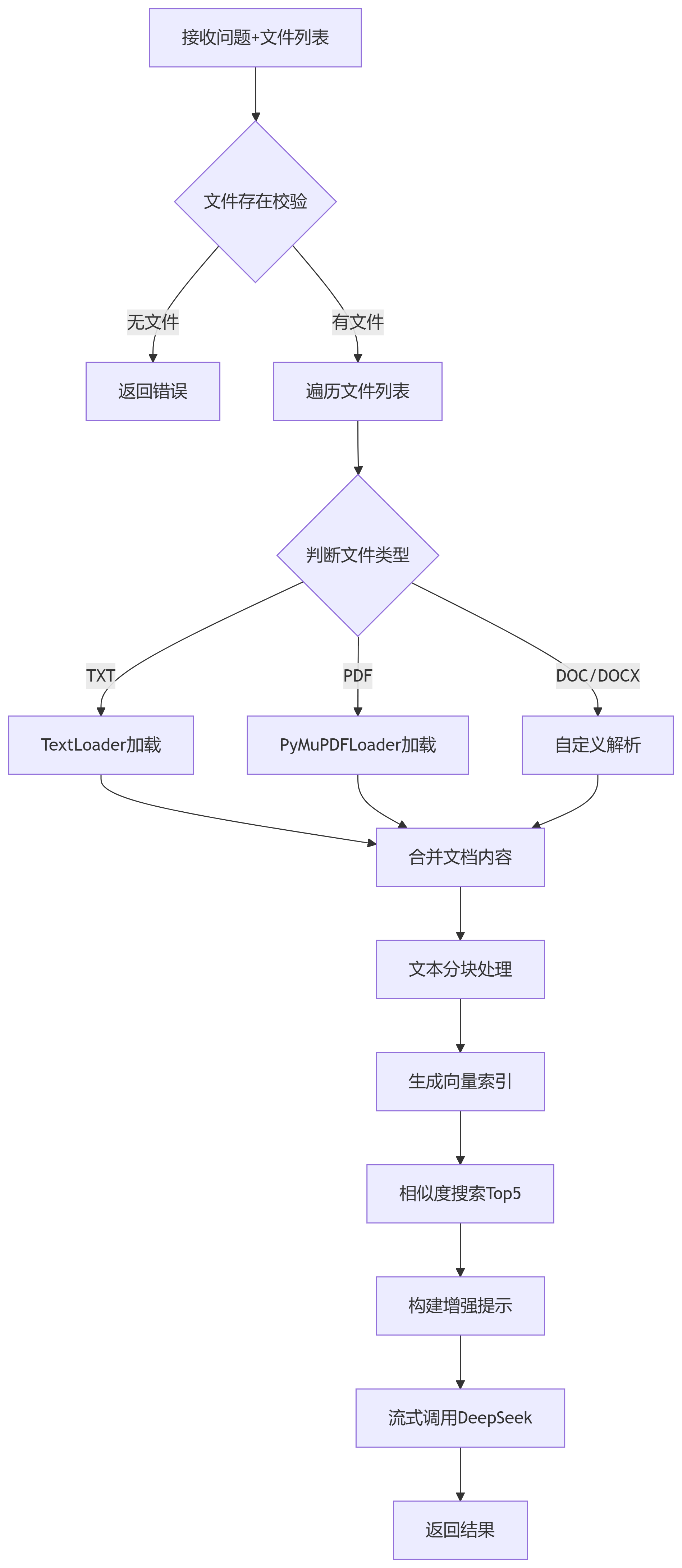
4.处理逻辑
-
多格式文档处理
-
TXT:使用
TextLoader方法解析(需注意编码格式) -
PDF:使用
PyMuPDFLoader解析文本(禁用图片/OCR提取) -
Word:使用
langchain_core.documents方法解析
-
-
文本优化处理
-
分块策略:500字符/块,50字符重叠
-
分隔符:段落分隔符 + 中文标点
-
元数据保留:记录原始文件路径
-
-
检索增强生成(RAG)
-
使用
bge-m3模型生成文本嵌入 -
FAISS实现高效相似度检索
-
动态构建含来源标识的上下文
-
-
流式响应设计
-
结合DeepSeekApi通过
StreamingResponse实现逐字输出快速响应 -
异步处理避免阻塞
-
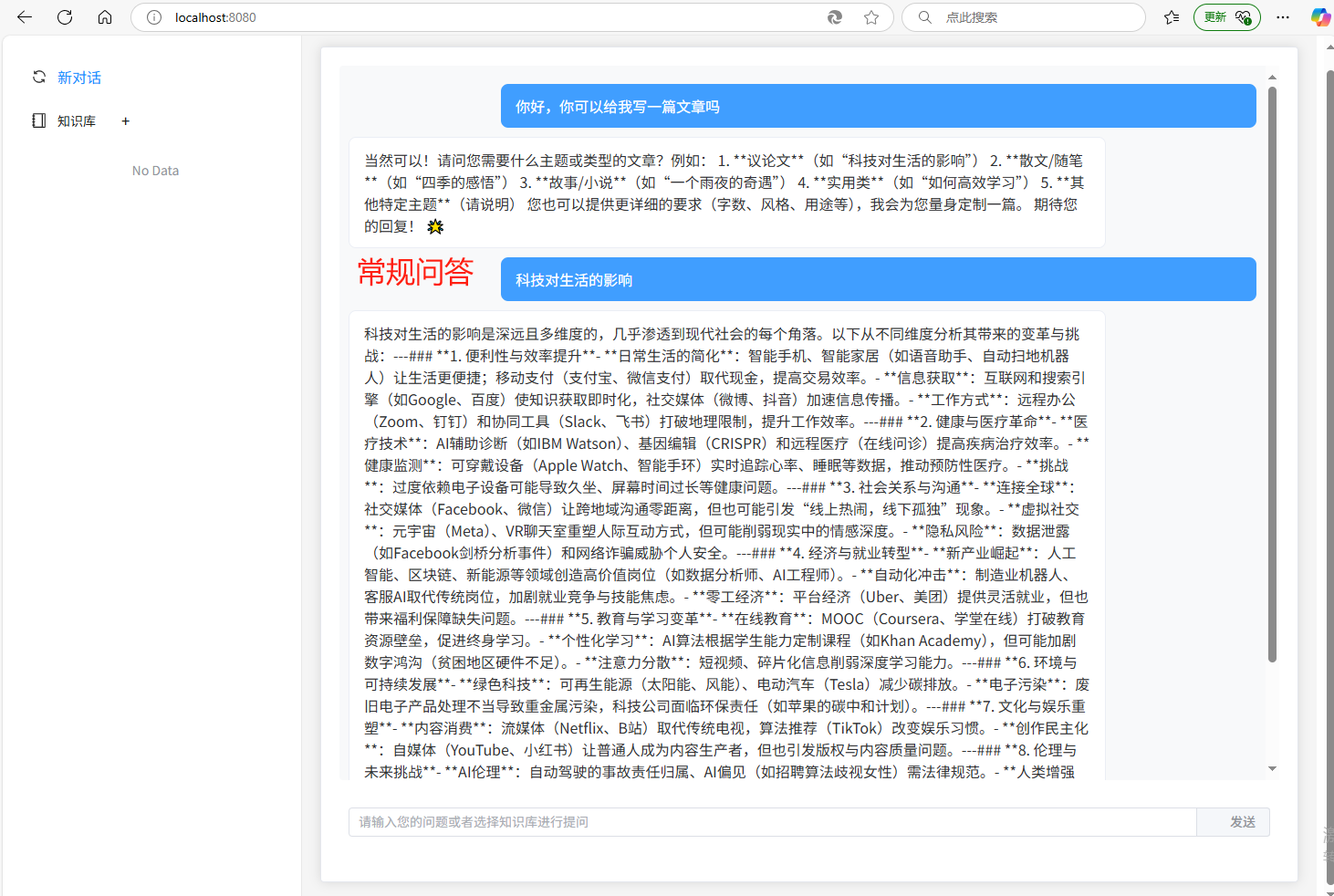
5.运行效果图
(1) 调用DeepSeekApi实现通用的常规问答(流式输出)
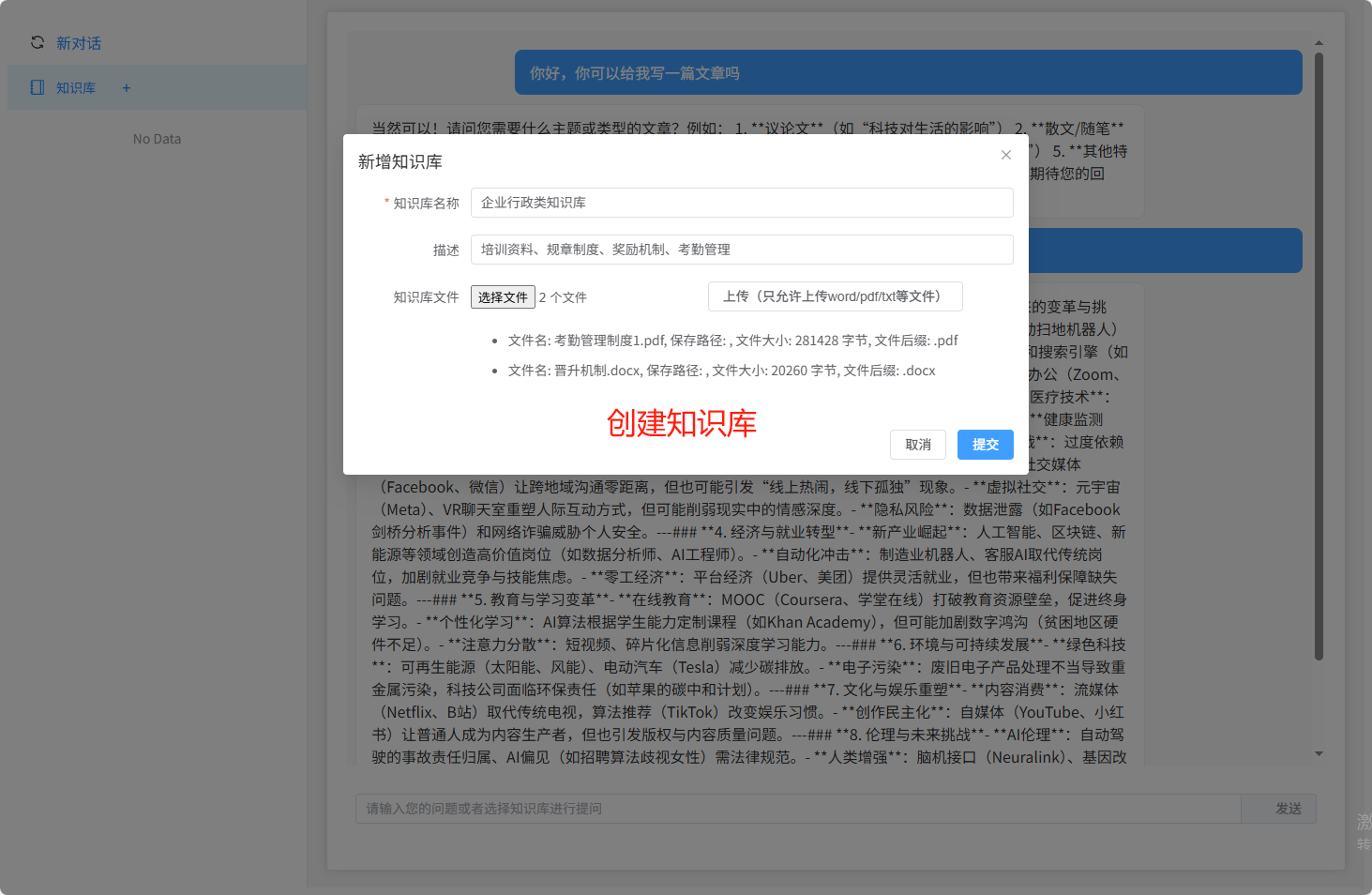
(2) 创建/维护私有知识库
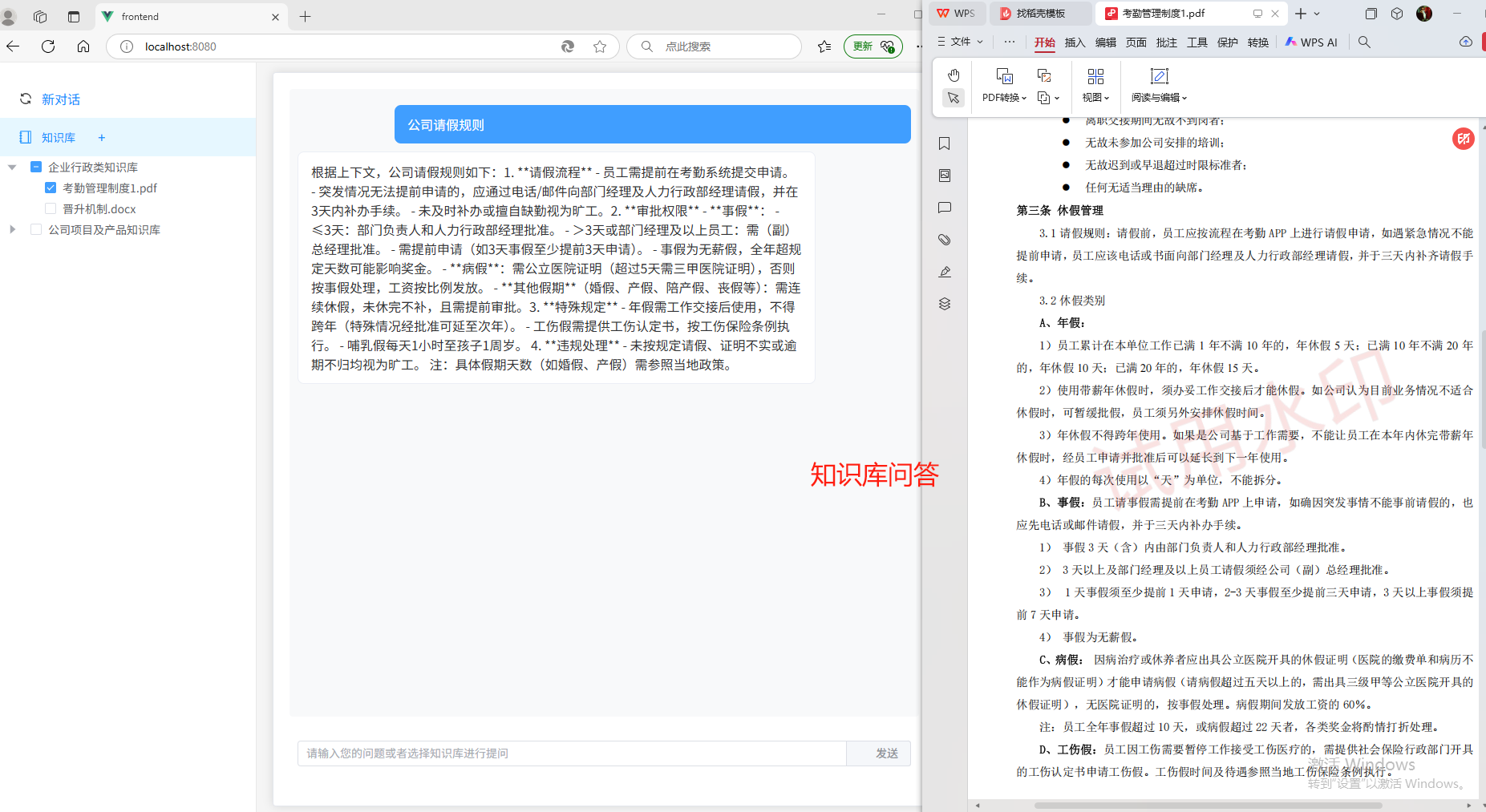
(1) 实现对多个知识库/或指定文档进行提问,AI检索相应答案并流式输出
项目总结
调用线上DeepSeekApi价格亲民,有条件者也可以本地部署大模型,亲测代码照样通用。未来可能会继续完善输出结果样式、支持更多文件类型、向量存储快速超找等板块。也希望支持更多业务场景,比如公司合同比对并标注、企业内部私有AI客服等。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)