Intel 优化版 Ollama 正式上线!Intel GPU 本地快速部署 DeepSeek + 知识库/联网搜索实战
Intel 优化版 Ollama 正式上线!Intel GPU 本地快速部署 DeepSeek + 知识库/联网搜索实战
最近很多小伙伴问怎么本地部署 DeepSeek,或者部署完成之后如何设置本地知识库和联网搜索功能。正好我今天看到 Intel 优化版 Ollama 已上线了魔搭社区,使用起来非常方便快捷,接下来就拿这个版本的 Ollama 来给大家做一下介绍。
ipex-llm 是英特尔团队开发的一个本地大语言模型推理加速框架,主要用于 Intel GPU(集成显卡)和 I 卡运行大语言模型,目前已经支持大多数主流 AI 大模型。Ollama 是目前比较主流的大模型本地化部署工具,主要通过命令行交互对模型进行下载、管理和使用。
最近,ipex-llm 专门针对 Ollama 优化出了一个免安装版本,省去了繁琐的环境配置和安装步骤,为英特尔GPU(集成显卡)和I 卡”进行了性能和体验优化。我在自己电脑上已经实测可用了,接下来分享给大家~
第一步:根据需要更新显卡驱动
按照 Intel 官方推荐,如果用的是 Intel Core Ultra processors (Series 2) 或者 Intel Arc B-Series GPU,最好升级到最新版本的驱动;如果是其他核显,推荐使用 32.0.101.6078 版本驱动。
第二步:下载 Ollama 英特尔优化版并解压
来到魔搭社区的项目地址:
Ollama 英特尔优化版www.modelscope.cn/models/ipexllm/ollama-ipex-llm编辑
下载 zip 文件,然后解压到任意位置即可。
第三步:启动 Ollama Server
在完成解压后的文件夹内,找到 start-ollama.bat,双击后会自动启动 Ollama Server 服务(如果这一步出错了,就需要去检查一下自己的集显驱动是否正常):
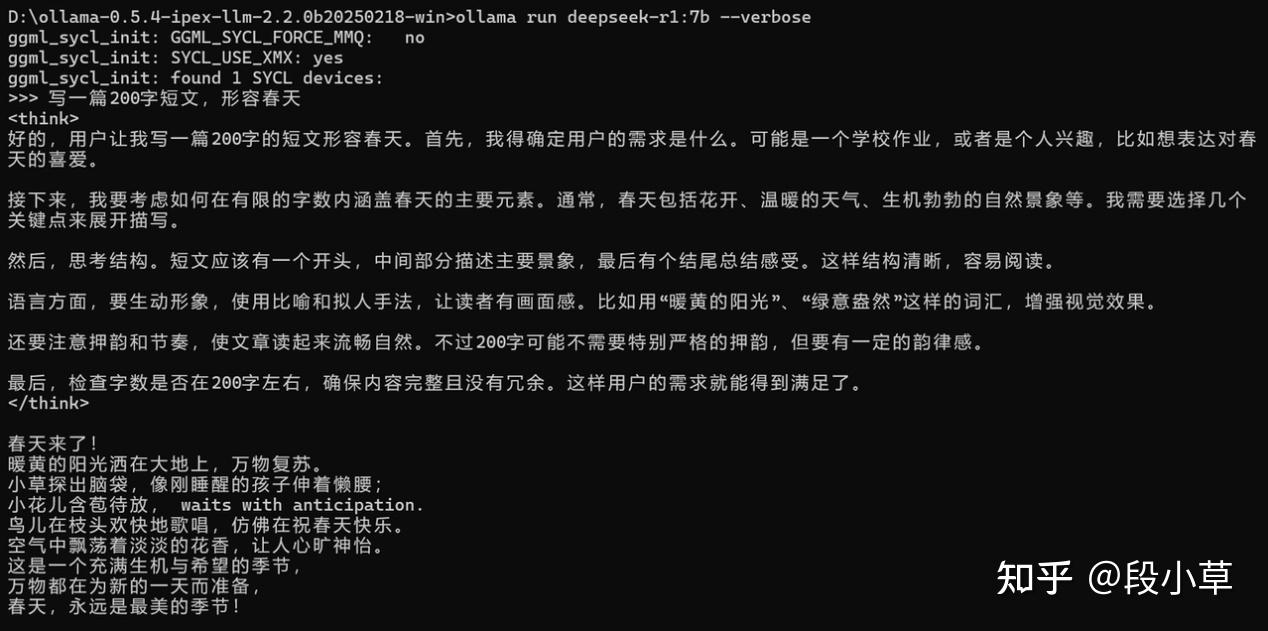
第四步:运行 Ollama 并拉取模型
打开 CMD,通过 cd \d 解压路径 来到 Ollama 安装路径后,运行 ollama run deepseek-r1:7b 命令,就会自动下载 DeepSeek R1 7B 蒸馏模型到电脑本地并运行,然后我们可以在 CMD 中进行一些对话,测试模型是否正常安装成功。
如果大家用的是 Intel ARL-H + 32G RAM 的机器,推荐跑 14B 量级及以下的本地模型。
运行时如果在命令后面加上 --verbose 参数,则会在对话生成结束后显示统计信息。
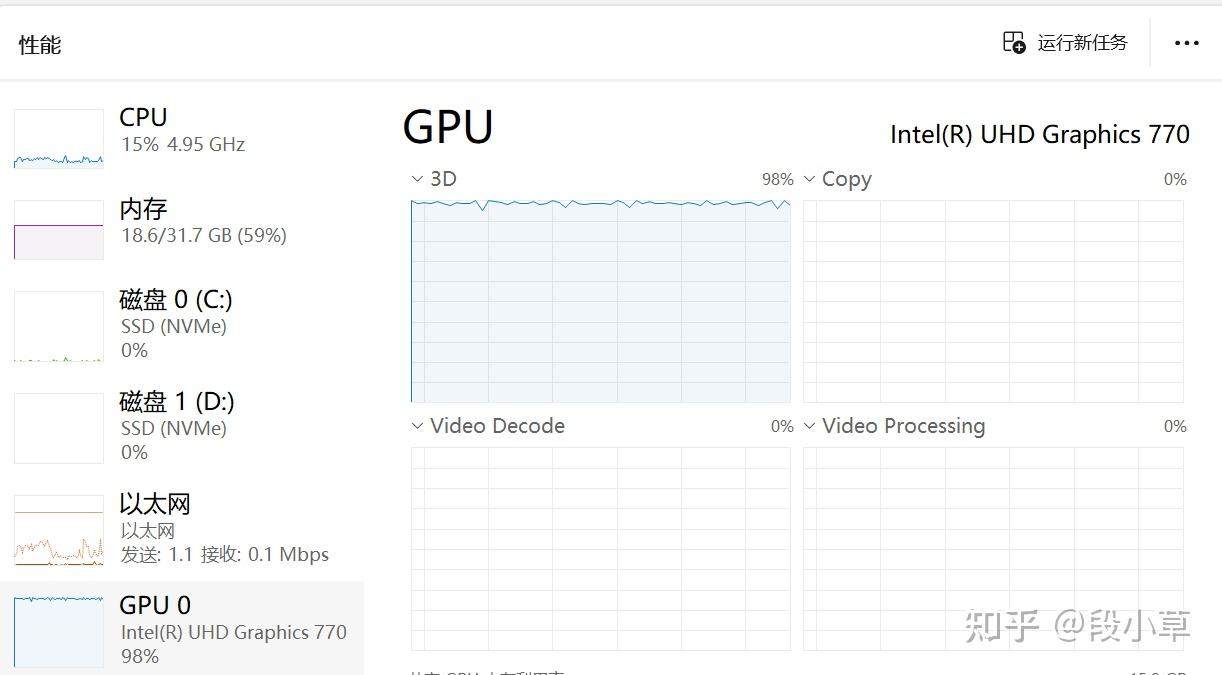
在任务管理器中可以看到资源的占用情况,我这里的电脑是通过集显运行的:
其实到这一步就已经完成了 Ollama 的安装和运行。不过大家安装本地模型最主要的原因不是为了对话,而是为了使用本地的知识库,Ollama 本身是一个极简的模型工具,并不提供图形化的对话界面,所以就需要搭配一些其他应用来实现。
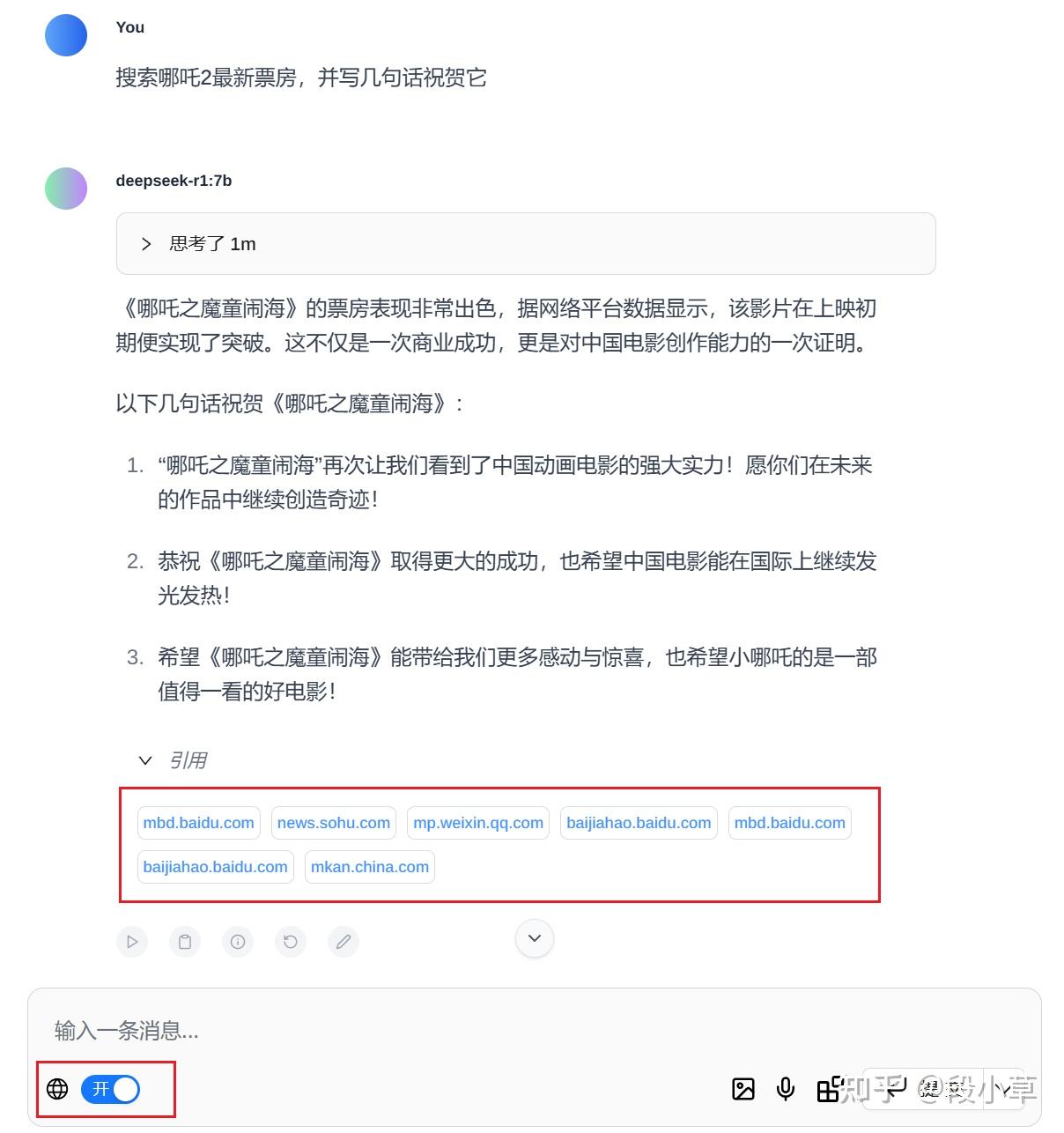
这边再给大家介绍一下如何在本地使用联网搜索以及知识库功能。目前我体验过的各类工具中,最简单易用的就是 Page Assist 浏览器插件,可以直接在浏览器插件商店中下载:
下载完成后,我们需要先进行几项设置。来到 Page Assist 的设置页面,在「管理网络搜索」中选择适合的搜索引擎并设定模型可以访问多少条搜索结果:
比如我们打开网络搜索功能,要求模型搜索哪吒 2 的最新票房,并写几句祝贺的话。可以看到模型能够正常访问到 7 条搜索引擎提供的结果:
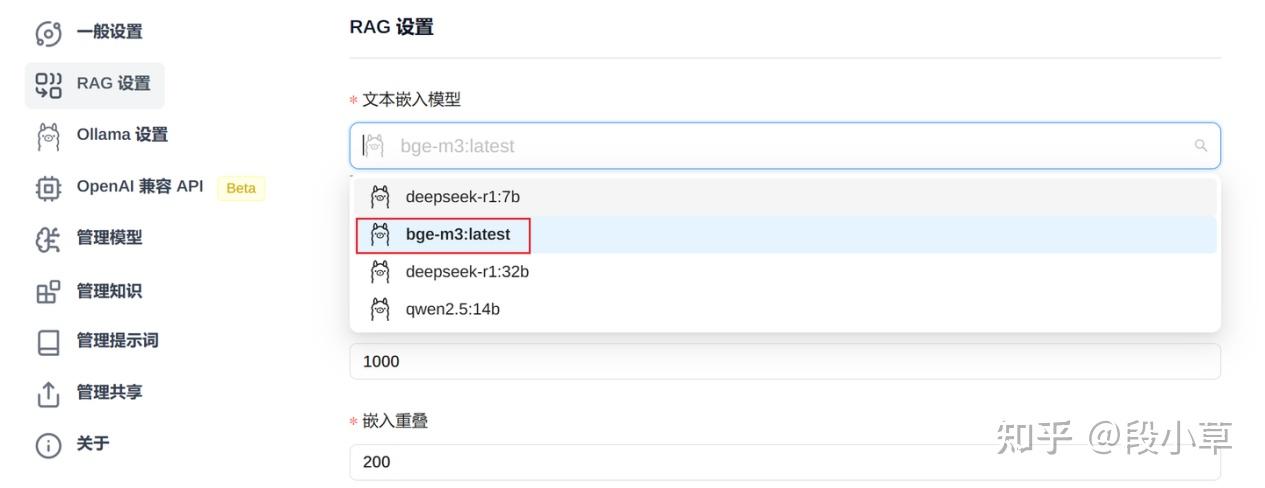
想要使用知识库功能,我们需要首先通过 ollama pull bge-m3 命令,拉取一个用于文本嵌入的 embedding 模型。之后在插件的「RAG 设置」中,选择 bge-m3 模型作为文本嵌入模型:
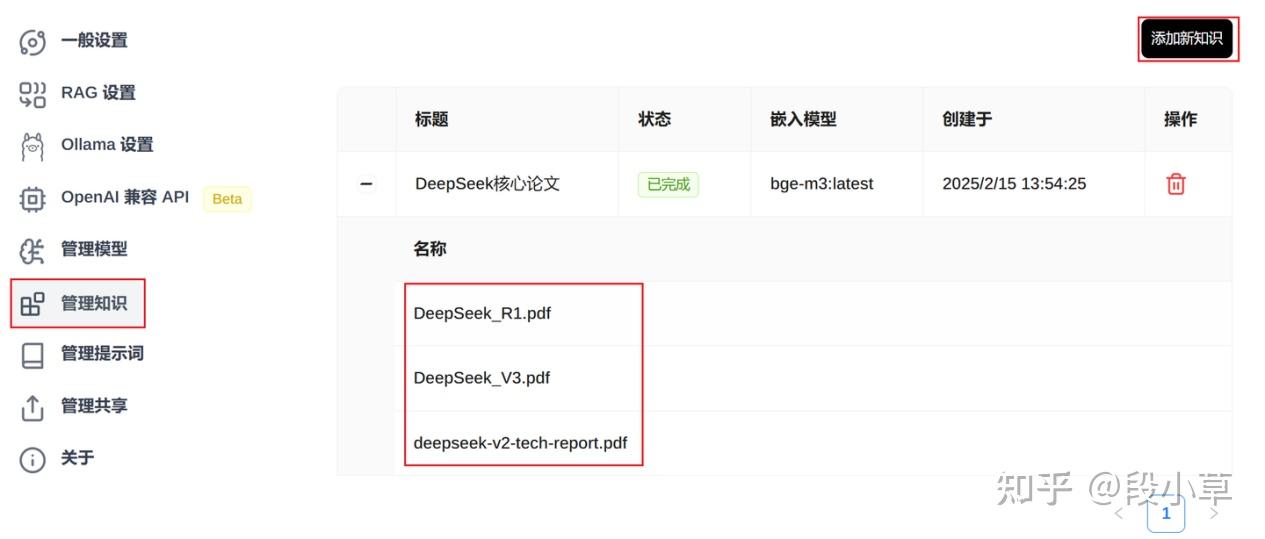
然后在「管理知识」设置中,添加新知识,可以上传一些 pdf 文档,上传后会运行 embedding 模型,等待状态显示已完成就可以对话了。
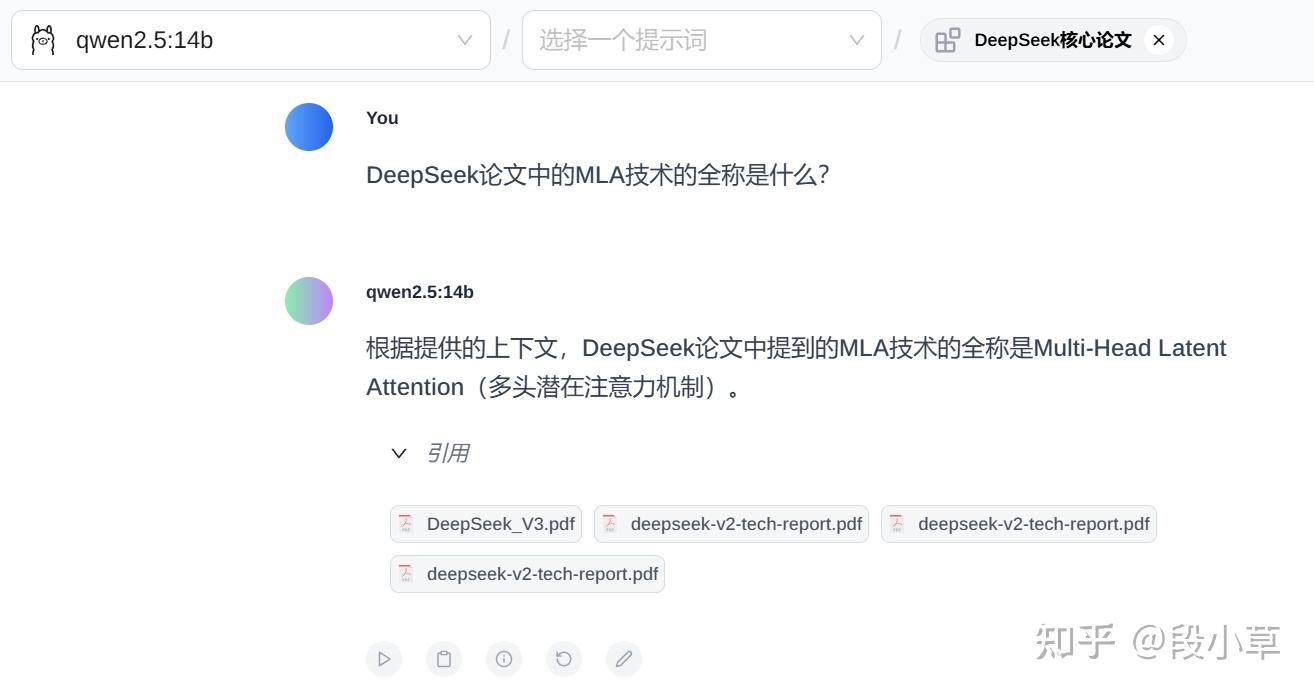
比如我这里上传了几篇 DeepSeek 的论文,选择知识库后进行提问,模型可以正确从论文中摘取到有效信息并进行回答:
当然,搭配本地模型使用的应用还有许多,比如 ChatBot、Flowy AI PC 等,大家可以根据自己的需求进行选择。
通过本地部署模型,搭配联网搜索和知识库检索使用,可以帮助我们的本地电脑变身 AI PC,通过大模型为各类学习和办公场景提供 AI 支持。有需求的小伙伴可以自行折腾一下~



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)