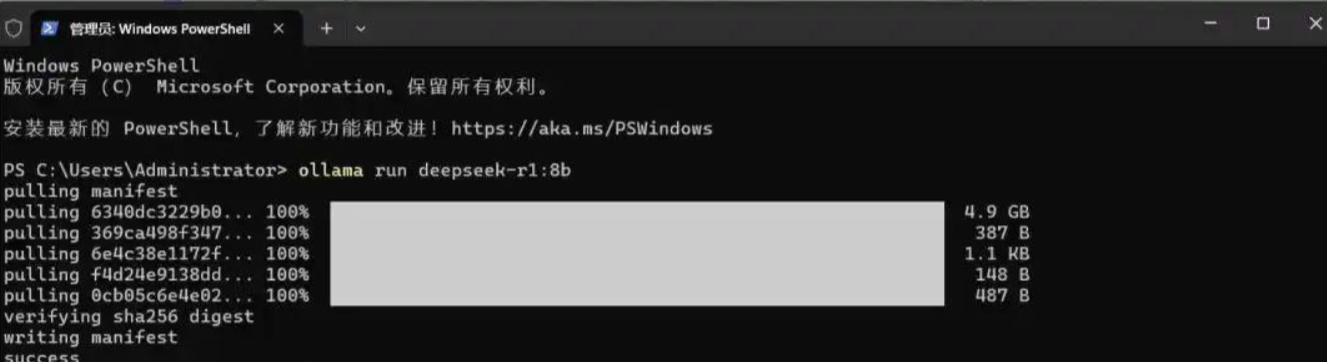
手把手deepseek本地部署教程(满血联网版deepseek部署本地详细步骤)
GPU显存溢出|执行`nvidia-smi-l 1`监控显存波动|启用8bit量化或使用`--max-batch 16`限制批次||模型输出乱码|检查`tokenizer_config.json`版本|重新下载模型并校验SHA256|•GPU(可选):NVIDIA RTX 3060(8GB显存)及以上,支持CUDA 12.0。|API响应延迟>5s|使用`py-spy`进行性能剖析|优化预处理流水
DeepSeek作为国产领先的自然语言处理框架,凭借其高效的推理能力和对中文语境的深度优化,已成为企业级AI应用的首选。本地部署不仅能规避云端服务的网络延迟和隐私风险,还可通过私有知识库定制实现精准业务适配。本教程整合2025年最新部署方案,涵盖基础环境搭建、多场景部署策略、性能调优及故障排查,适用于开发者、企业技术团队及AI爱好者。
deepseek本地部署工具包:s.cusscode.top
一、部署前准备

1.硬件配置要求
•基础配置
•CPU:Intel i5-12代/AMD Ryzen 5 5600X(4核8线程)及以上
•内存:16GB DDR4(7B模型)或32GB(32B模型)
•存储:NVMe SSD≥500GB(建议预留模型文件2倍空间)
•GPU(可选):NVIDIA RTX 3060(8GB显存)及以上,支持CUDA 12.0
•企业级推荐配置
•多GPU并行:NVIDIA A100 80GB*2(通过NVLink互联)
•存储阵列:RAID 0配置的SSD组,带宽≥2GB/s
2.软件环境搭建
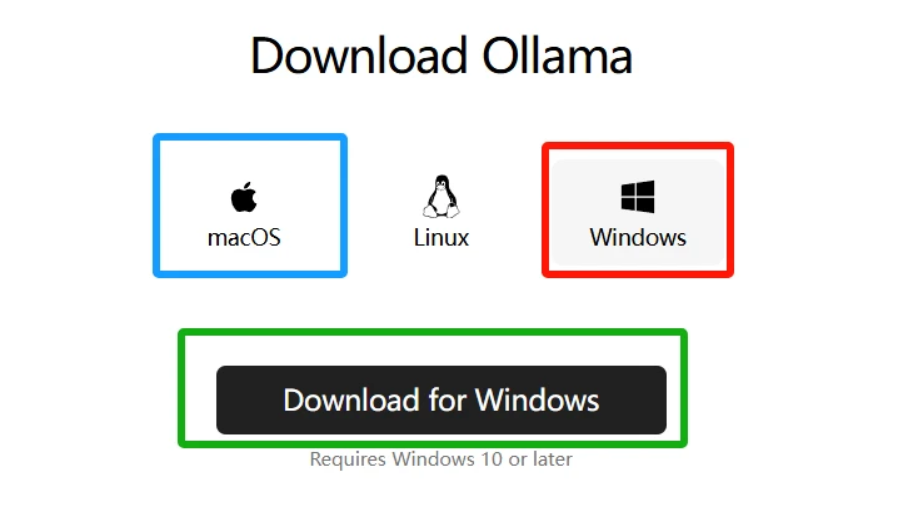
•操作系统
•首选Linux:Ubuntu 22.04 LTS(内核≥5.15)或CentOS Stream 9
•次选Windows:需安装WSL2并启用GPU-PV支持
•核心依赖
```bash
#Ubuntu环境示例
sudo apt install-y python3.10-venv nvidia-cuda-toolkit git
pip install torch==2.3.0+cu121--extra-index-url https://download.pytorch.org/whl/cu121
```•工具链验证
```bash
nvidia-smi#确认GPU识别状态
python-c"import torch;print(torch.cuda.is_available())"#输出应为True
```
二、核心部署方案
方案1:基础手动部署(适合开发者)
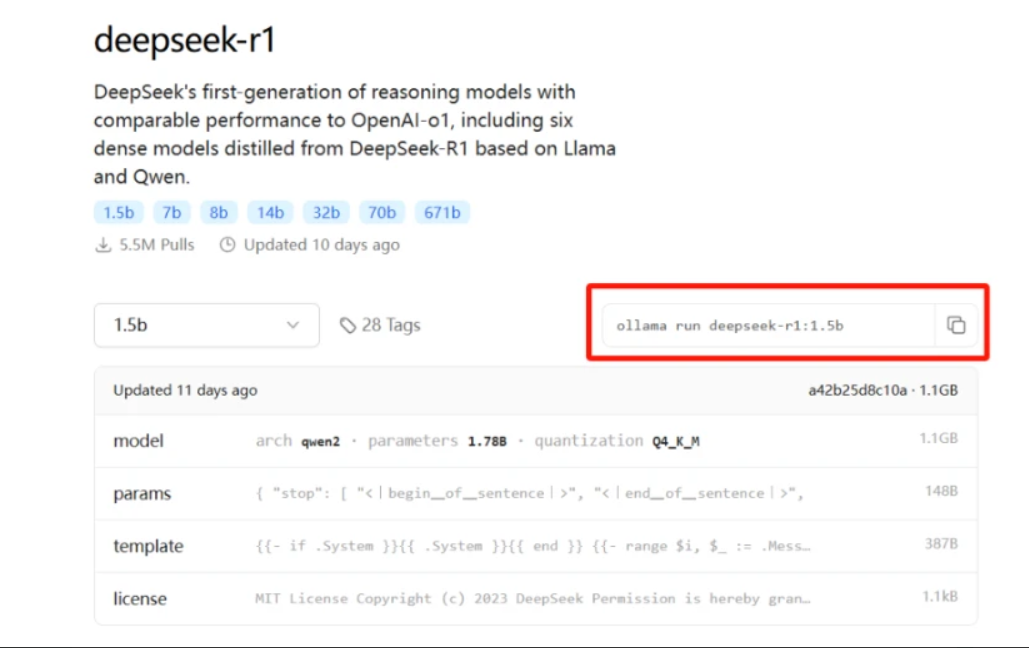
1.代码获取与模型下载
```bash
git clone--depth 1 https://github.com/deepseek-ai/core.git
wget https://models.deepseek.com/deepseek-r1-7b-2025v2.bin-P./models
```2.虚拟环境配置
```bash
python-m venv.venv&&source.venv/bin/activate
pip install-r requirements.txt--no-cache-dir
```
3.启动参数优化
```yaml
#configs/server.yaml
compute:
device:cuda#启用GPU加速
quantization:bnb_8bit#降低显存占用30%
network:
api_key:"your_secure_key"#建议使用密钥轮换策略
``` 
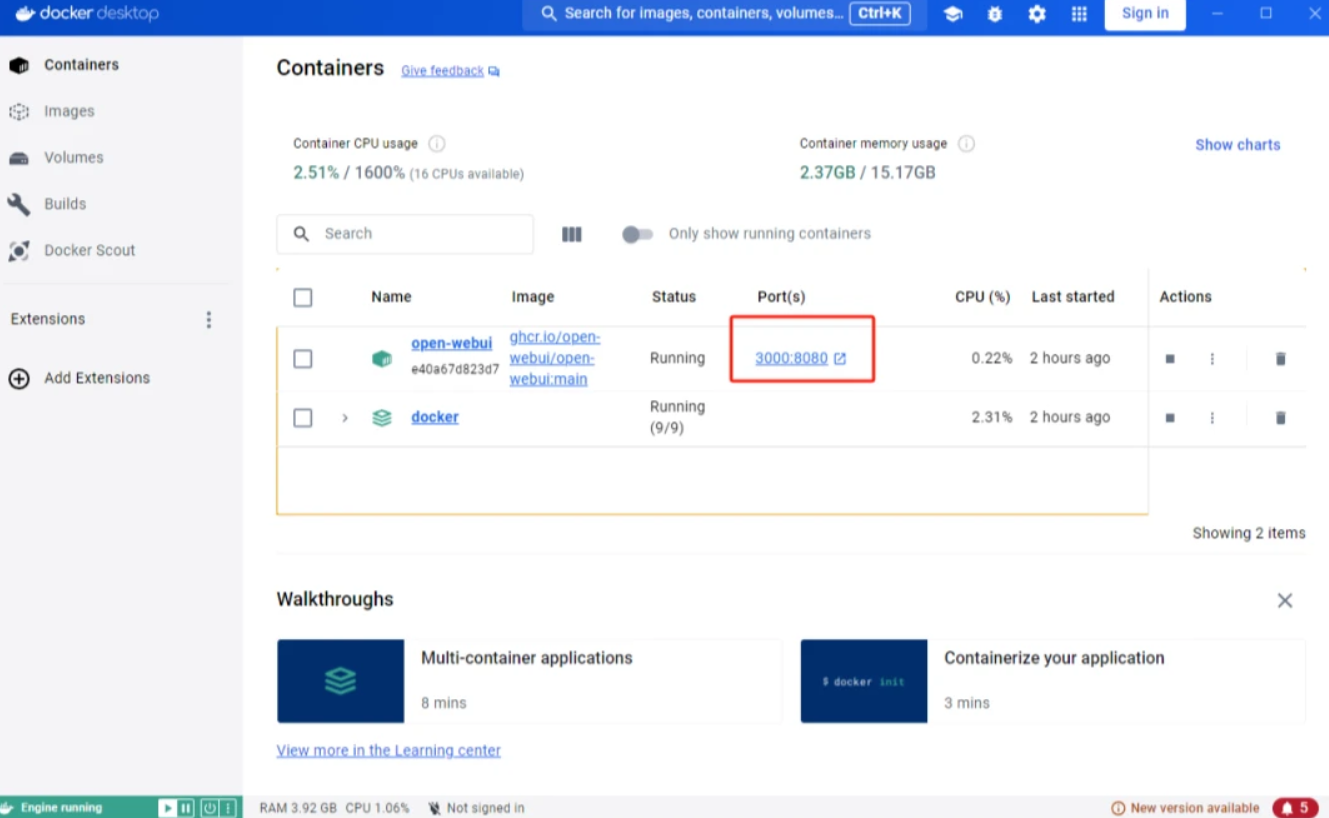
4.服务启动与验证
```bash
python serve.py--port 8080--model-path./models/deepseek-r1-7b-2025v2.bin
curl-X POST http://localhost:8080/v1/completions-H"Content-Type:application/json"-d'{"prompt":"你好,DeepSeek"}'
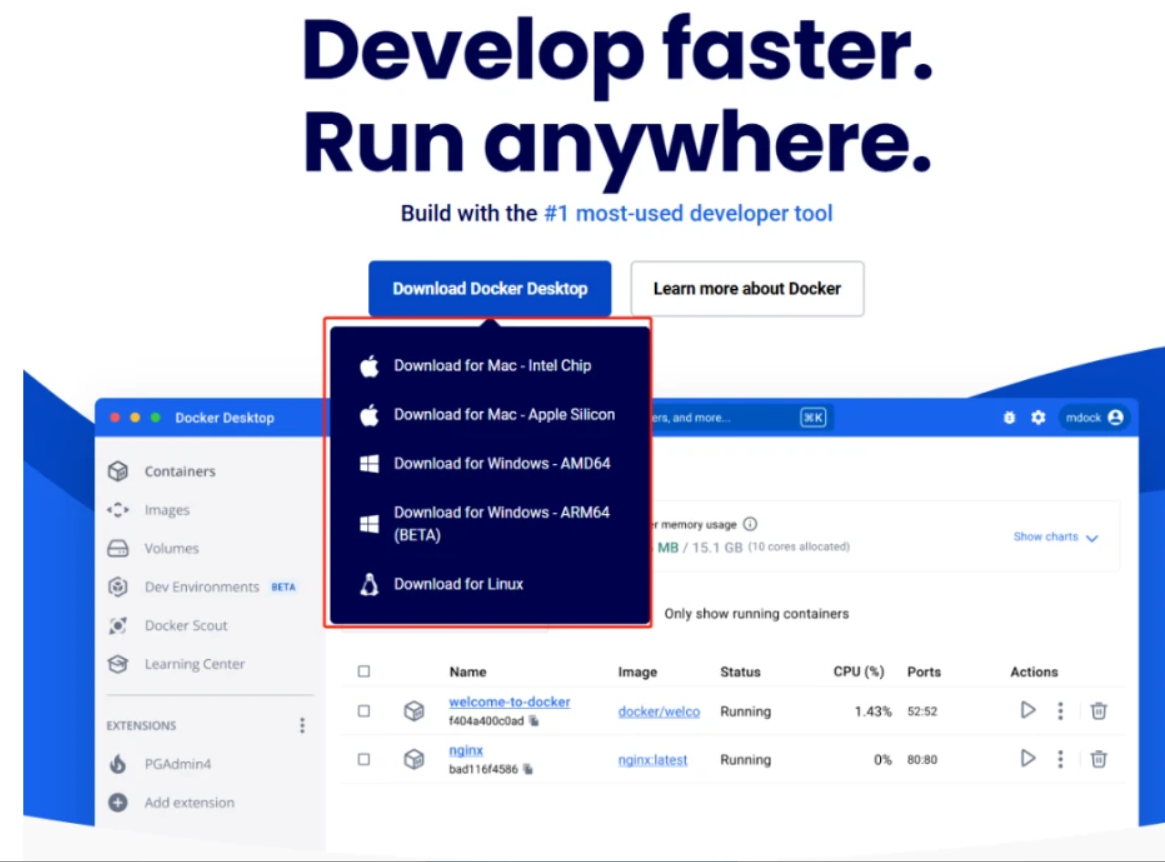
```方案2:容器化部署(推荐生产环境)
1.Docker Compose编排
```dockerfile
#docker-compose.yml
version:'3.8'
services:
deepseek:
image:deepseek/official:r1-7b-2025q2
deploy:
resources:
reservations:
devices:
-driver:nvidia
count:1
capabilities:[gpu]
volumes:
-./models:/app/models
ports:
-"8080:8080"
``` 
2.集群扩展配置
```bash
docker swarm init#初始化Swarm集群
docker stack deploy-c docker-compose.yml deepseek-prod
```方案3:Cherry Studio混合部署(适合快速验证)
1.硅基流动API集成
•注册获取API密钥(每月2000万免费Token)
•在Cherry Studio中配置终端节点:
```json
{
"endpoint":"api.siliconflow.cn/v1",
"key":"sk-xxxxxxxx"
}
``` 
2.本地知识库增强
•上传行业术语表(CSV/TXT)至`/data/knowledge`目录
•启用向量检索:
```python
from cherry import KnowledgeBase
kb=KnowledgeBase(embed_model="text-embedding-3-large")
kb.index_documents("金融行业术语表.csv")
```三、高级配置与优化
1.GPU加速策略
•混合精度训练
在`train.py`中启用`amp`模式,降低显存消耗40%:
```python
torch.cuda.amp.autocast(enabled=True)
```•模型切片技术
使用`accelerate`库实现多卡并行:
```bash
accelerate launch--num_processes 2 train.py--model_name deepseek-r1-32b
```2.安全加固措施
•TLS加密传输
```bash
openssl req-x509-newkey rsa:4096-nodes-out cert.pem-keyout key.pem-days 365
python serve.py--ssl-certfile cert.pem--ssl-keyfile key.pem
``` 
•访问控制列表(ACL)
```yaml
#security/acl.yaml
allowed_ips:
-192.168.1.0/24
rate_limit:
requests:100
per:60s
```四、故障排查手册
|问题现象|诊断方法|解决方案|
|---------|---------|---------|
|GPU显存溢出|执行`nvidia-smi-l 1`监控显存波动|启用8bit量化或使用`--max-batch 16`限制批次|
|API响应延迟>5s|使用`py-spy`进行性能剖析|优化预处理流水线,启用缓存机制|
|模型输出乱码|检查`tokenizer_config.json`版本|重新下载模型并校验SHA256|
五、部署方案对比
|维度|基础部署|容器化部署|Cherry Studio|
|-------------|---------------|----------------|------------------|
|启动时间|5-10分钟|2分钟(镜像预载)|1分钟(云端配置)|
|扩展性|手动扩容|Kubernetes集成|按需购买Token|
|安全等级|★★☆|★★★★|★★★☆|
|适用场景|开发调试|生产环境|快速原型验证|
六、注意事项
1.版本兼容性
•模型文件与框架版本需严格匹配(如2025Q2模型需DeepSeek SDK≥2.3.1)
2.数据合规
•本地化部署需遵守《生成式AI数据安全管理办》第三章条款
3.长期维护
•建议配置Prometheus+Grafana监控栈,设置以下告警阈值:
◦GPU利用率>90%持续5分钟
◦API错误率>1%
本教程综合了2025年主流部署方案,开发者可根据实际需求选择适配路径。如需更深入的性能调优指南,可参考DeepSeek官方文档或加入硅基流动开发者社区。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)