技术前沿对话:DeepSeek-R1与Kimi 1.5如何重塑AI开发的新思路
技术前沿对话:DeepSeek-R1与Kimi 1.5如何重塑AI开发的新思路
1.《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》
https://arxiv.org/pdf/2501.12948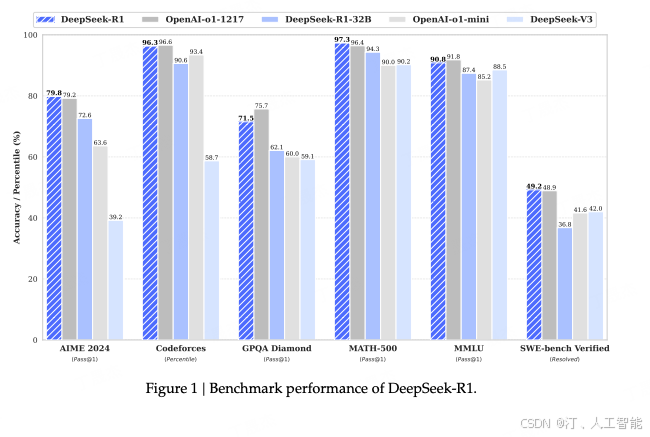

1.1 DeepSeek-R1-Zero 的训练
-
基础模型:使用 DeepSeek-V3作为基础模型。
-
强化学习:直接在基础模型上应用大规模强化学习 GRPO(RL),不依赖于监督微调(SFT)。
-
奖励建模:奖励模型可以说是 [RLHF] 的灵魂了,DeepSeek-R1-Zero 是基于纯规则的奖励系统,主要包括准确率奖励和格式奖励。
-
准确率奖励:评估响应是否正确,例如数学问题的确定性结果。
-
格式奖励:确保模型将思考过程放在
<think>和</think>标签之间。
可以看到 DeepSeek-R1-Zero 的强化学习奖励都是规则奖励,不用 ORM 或 PRM 这些 reward model,是因为 reward model 容易在大规模强化学习中出现 “rawrd hacking 奖励破解” 问题,而且训练 reward model 需要额外的训练资源。
- 训练模板:设计了一个简单的 prompt 模板,要求模型先产生推理过程,然后给出最终答案。

- 实验结果:通过 RL 训练,DeepSeek-R1-Zero 在推理任务上表现出显著的性能提升,例如在 AIME 2024基准测试中,pass@1 分数从 15.6% 提升到 71.0%。而且从论文的图来看,效果起来还能继续提升。
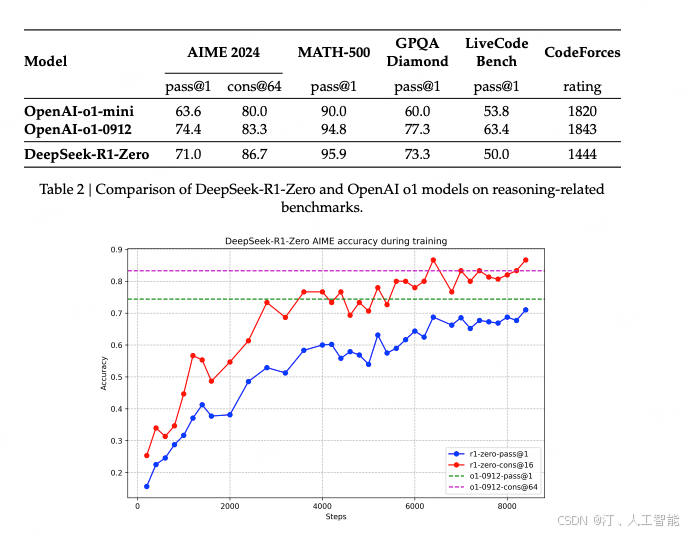
- 缺陷:虽然 DeepSeek-R1-Zero 在推理能力方面表现出色,但它仍然存在一些明显的问题。具体来说,该模型在可读性方面表现欠佳,并且存在语言混杂的问题。(这和我们偶尔在 Claude 3.7 或 Kimi 1.5 中看到的情况类似——问中文问题却返回英文回复,有时候返回格式有时混乱)。
1.2 DeepSeek-R1
-
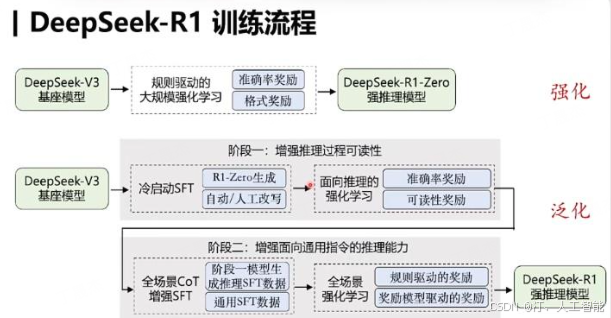
动机:1)通过引入少量高质量数据作为冷启动,能否进一步提高推理性能或加速收敛?2) 如何训练一个不仅能够处理数学、代码问题,还能处理其它偏 general 的推理问题的强大推理模型?为了解决这些问题,团队开发了 DeepSeek-R1,采用了四阶段训练策略
-
训练过程:
-
阶段一 SFT 做冷启动(Cold Start):
- 首先收集了数千个高质量的长推理链 (CoT) 数据,通过让 DeepSeek-R1-Zero 生成解题步骤,经人工筛选后用于微调 DeepSeek-V3-Base。这一步的目的是提高模型可读性和基础推理能力,为后续强化学习打好基础。
-
阶段二推理导向的强化学习 RLHF(Reasoning-oriented Reinforcement Learning):
- 在微调后的模型上应用大规模强化学习,重点提升模型在编码、数学、科学和逻辑推理等任务上的表现。除了准确率奖励外,还引入了语言一致性奖励,解决了语言混合的问题。
-
训练阶段三面向通用场景的 SFT(Rejection Sampling and Supervised Fine-Tuning):
-
当阶段二的模型收敛后,使用该模型生成 SFT 数据。这一阶段的 SFT 不止要包括推理数据,还要包括在写作、角色扮演和其他通用任务方面的能力,它们的这样得到的
-
600k 条推理数据:部分带有问题和简单真实答案的推理数据,这种数据例如利用模型采样多个回复,假如里面有 6 条是正确的,在这 6 条正确的,通过人工过滤,筛选出一条质量最好的那一条作为训练数据。对于部分推理问题,要做到模型预测和答案一模一样是很难的,这时候把真实答案和模型预测答案输入到 DeepSeek-V3 中进行判断,进行打分,对同一个问题,让模型采样多次,采用 deepseek-v3 打分最高的那个回复,作为 SFT 的训练数据。说白了,就是 reject sampling 的思想。
-
200k 条非推理数据:对于非推理数据,如写作、事实问答、自我认知和翻译,采用 DeepSeek-V3 流程,并复用 DeepSeek-V3 的有监督微调(SFT)数据集中的部分数据。对于部分非推理任务,调用 DeepSeek-V3 在通过提示回答问题之前生成一个潜在的思维链。不过,对于较简单的查询,如 “你好”,不会在回复中提供思维链。最后,总共收集了约 20 万个与推理无关的训练样本。
-
使用这 800k 条数据对模型模型进行两个 epoch 微调。
-
-
全场景强化学习的 RLHF(Reinforcement Learning for all Scenarios):
-
进一步的强化学习阶段,目标是训练出在推理方面出色且优先考虑有用性和无害性的模型,还是分成推理数据和非推理数据
-
推理数据:采用一样的准确率硬规则奖励
-
非推理数据:采用一个偏好对训练的 reward model(这里没有细写这个 reward model 是怎么训练的,但我觉得这是很核心的),而且这里的奖励分成两个,一个是有用性奖励,有用性奖励只输入 pormpt 和模型最终的回复,得到一个 reward 分数,还有一个奖励是无害性奖励,输入的是 prompt 和包含思维链的模型完整输出,得到一个分数。这里猜测,有用性和无害性,应该是两个独立训练的 reward model。
-
最终融合推理数据和非推理数据一起训练,目的是继续泛化,让模型把推理能力进一步通过 RLHF 增强,其次范化到非推理场景。但论文这里没跟阶段三一样说明推理数据和非推理数据的占比。
-
-
实验结果
结果十分的好,这里不细说了。实际用过 DeepSeek-R1 的朋友应该都对效果有了解,真的不输 GPT-o1。
1.3 DeepSeek-Distilled
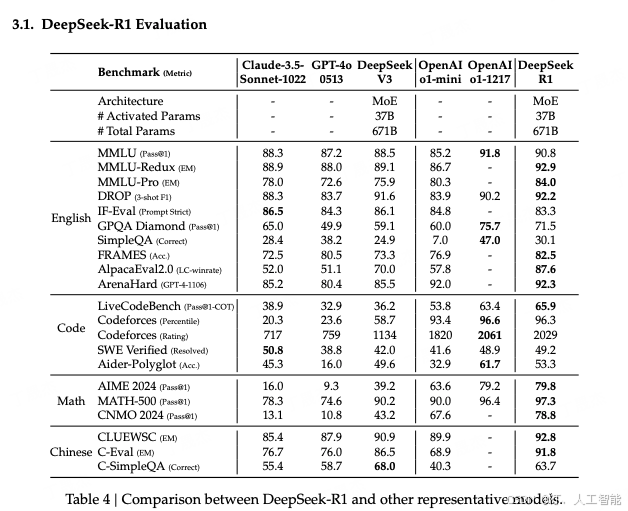
- 蒸馏模型选择:选择 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B和 Llama-3.3-70B-Instruct作为基础模型。
- 蒸馏数据和蒸馏训练:使用 DeepSeek-R1 训练阶段三的 800k 个训练样本进行 SFT 训练,不进行 RL 训练。
- 性能提升:蒸馏后的模型在推理任务上表现出显著的性能提升,例如 DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上的 pass@1 分数达到 55.5%。
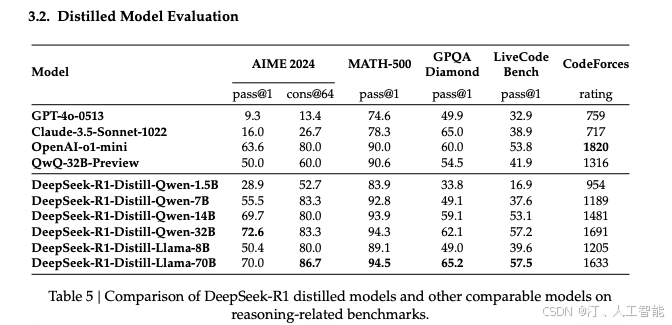
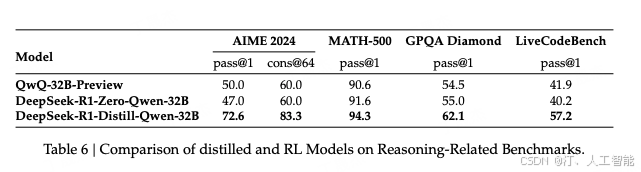
论文进一步探讨这些小 size 的模型能否在不进行蒸馏的情况下,通过 DeepSeek-R1-Zero 一样的的大规模强化学习训练达到相当的性能?因此论文做了如下实验。但实验结果这些小 size 的模型直接搞大规模强化学习不如从大 size 的模型蒸馏出的思维链数据 SFT 的效果要好。
2《KIMI K1.5: SCALING REINFORCEMENT LEARNING WITH LLMS》
https://arxiv.org/pdf/2501.12599
其实这篇论文也很有诚意,基本上把 kimi1.5 的训练方式很详细地亮出来了。

2.1 RL 数据集
构建高质量的 RL prompt 集是 RLHF 的核心,这部分 deepseek-R1 没怎么讨论,kimi1.5 倒是讨论的挺详细的,具体来说,高质量的 RL 数据集需要满足
-
覆盖度的多样性:使用自动过滤器筛选出需要推理的问题,这些问题跨越 STEM、编程、通用推理等多个领域。建立 tagging system,把问题按领域和学科对提示进行分类,以确保不同学科领域都分布均匀,但这里有个问题,这里好像没包括一些 general 的数据。
-
难度的均衡性:让 SFT 模型以较高采样温度生成 10 次答案,用通过率作为难度的代理指标,通过率越低,说明问题越难,通过这种方式给每一个 prompt 打上难度标签。有了这个难度标签后,可以后面可以干的事情就很多了,例如让模型先对难度低的进行训练,再慢慢加多些难度高的数据之类的。
-
评估的准确性:为了避免 reward hacking,Kimi 采用同 deepSeek-R1-Zero 一样的准确率硬规则奖励,直接评估模型答案与真实答案的差异。但这样可能导致模型学习错误推理得到正确答案,所以他们:
-
排除容易通过猜测得到答案的问题类型(如多选题,true/false 题等)。
-
对于一般的问题任务,开发了一个简单但有效的方法来识别 “易于破解” 的 prompt,做法是让模型不使用 CoT 直接猜答案,如果在 8 次内猜对,就认为这个 prompt 太容易被破解,将这样的 prompt 移除。
Long-CoT Supervised Fine-Tuning
这部分与 DeepSeek-R1 的 “冷启动” 阶段相似,通过 prompt 工程和 rejection sampling 获取高质量的长思维链数据。这批数据虽然不需要太大量,但必须高质量,为后续 RLHF 打下基础。
Reinforcement Learning
Problem Setting
Kimi 团队放弃了常见的 MTCs、PRMs 和 value model 方法,转而采用更直接的策略。
强化学习的目标

这部分也挺有趣的,用了 DPO类似的推导逻辑。
值得一提的是论文中阐述了抛弃了 value function 的原因。假设模型已生成部分推理链 ( z 1 , z 2 , . . . , z t ) (z_1,z_2, ..., z_t) (z1,z2,...,zt),面临两个可能的下一步推理: z t + 1 z_{t+1} zt+1 直接通向正确答案,而 z t + 1 ′ z^{'}_{t+1} zt+1′ 包含一些错误。若使用传统价值函数,它会显示 z t + 1 z_{t+1} zt+1 比 z t + 1 ′ z^{'}_{t+1} zt+1′ 具有更高价值,会惩罚选择 z t + 1 ′ z^{'}_{t+1} zt+1′,因为它相对于当前策略具有负面优势。 然而,探索 z t + 1 ′ z^{'}_{t+1} zt+1′ 对训练长链推理能力实际上非常有价值。通过使用最终答案的正确性作为奖励信号,模型可以从选择 z t + 1 ′ z^{'}_{t+1} zt+1′ 的 “试错” 中学习,只要它最终能够恢复并最终达到正确答案。这种探索多样化推理路径的方法能够积累丰富的解题经验,有助于培养模型的规划能力,最终提高其在测试问题上的表现。
Length Penalty
长度奖励机制(len_reward)旨在解决模型在强化学习训练中产生过长回答(论文称为 overthinking)的问题。如下图所示,对所有回答按长度归一化计算λ值(λ = 0.5 - 归一化长度),并根据回答正确性分配不同的奖励:对于正确回答,奖励偏短的正确答案,惩罚冗长的;对于错误回答,给予 min(0, λ) 作为奖励,即对长度适中或较短的错误回答不予惩罚 (0 分),而对冗长的错误回答施加惩罚。
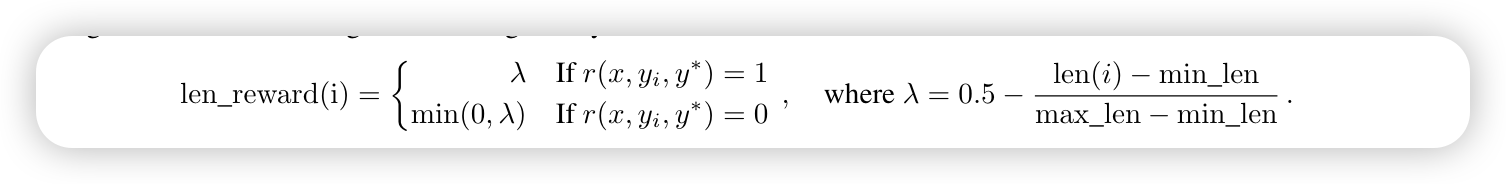
这样引导模型生成简洁有效的回答,缓解 “overthinking” 问题,虽然可能引入一些 “align tax”。
Sampling Strategies
如何提高 RL 的模型的训练效率,由于在上文中,对 RL 的每一条 prompt 都打上了难度的标签,Kimi 团队提出两种基于先验知识的采样方法:
- Curriculum Sampling 课程采样:这种方法的基本思路是从简单任务开始训练,逐步过渡到更具挑战性的任务。这样做的原因是:初始阶段的 RL 模型能力有限,如果直接用于解决非常困难的问题,往往会产生很少的正确样本,降低训练效率。
- Prioritized Sampling 优先级采样:追踪模型在每个问题上的成功率,并根据成功率的反比来分配采样概率。例如某个 prompt 被模型训练过 4 次,我们知道过去这个问题有多少次成功解决,如果当前某个问题 i 的成功率是 si,那么该问题被重新采样的概率就与 (1-si) 成正比。这让模型更关注自己的薄弱环节。
More Details on Training Recipe
描述了在 coding 验证,数学题奖励信号设置,多模态训练的细节
-
Test Case Generation for Coding 编程题验证:许多网上的编程题缺乏测试用例,但有那些正确的输入和输出的例子。kimi 的方法是:首先,使用 base 的 Kimi k1.5 基于题目描述生成 50 个测试用例,然后让 10 个正确的输入和输出的例子运行这些测试用例。如果一个测试用例能让至少 7 个例子得出相同的输出,这个测试用例就被认为是有效的。如果一个编程问题在所有筛选后的测试用例能让至少 9 个输入输出全部通过,这个问题就会被加入训练集。通过这种方法,他们从 1000 个在线竞赛题中筛选出了 614 个不需要特殊评判的问题,开发了 463 个能产生至少 40 个有效测试用例的生成器,最终有 323 个问题被纳入了他们的训练集。
-
Reward Modeling for Math 数学题评估:在评判数学答案时,一个难点是同一个答案可以有不同的写法(比如 a 2 − 4 a^2-4 a2−4 和 ( a + 2 ) ( a − 2 ) (a+2)(a-2) (a+2)(a−2) 其实是一样的)。为了解决这个问题,研究人员训练了两种评分模型:
-
传统评分模型:这种模型输入模型预测答案和真实答案,直接判断答案对错,准确率约 84.4%。
-
思维链评分模型:这种改进模型不仅给出判断,还会展示详细的推理 CoT 步骤。它的准确率高达 98.5%。
最终采用思维链模型评估答案,提供更准确的反馈。
-
Vision Data 多模态训练,使用了三种类型的图像数据来训练 AI:
-
真实世界的图片:包括带图表的科学题、地点猜测任务和各种图表分析等。这些帮助 AI 理解现实生活中的图像。
-
人工合成的图片:专门设计的图像,用来训练 AI 理解空间关系、几何图形和物体之间的交互等特定能力。这种方法可以无限制地创造训练样本。
-
文字转图片数据:把文本内容变成图片形式,确保 AI 无论是处理纯文本还是文本截图(比如屏幕截图),都能给出一致的回答。
long2short: Context Compression for Short-CoT Models
研究人员发现,虽然 long-CoT” 长思维 " 模型表现很好,但它们回答问题时太长啦,效率低。于是他们想把 long-CoT 模型的智慧转移到更简洁的 short-CoT 模型中,主要对比了四种方法:
- Model Merging:直接把一个 long-CoT 模型和一个 short-CoT 模型的权重取平均值,不需要重新训练。
- Shortest Rejection Sampling:让 long-CoT 模型对同一个 prompt 回答多次,然后选出最短的正确答案最为训练数据来 SFT 训练。
- DPO:将最短的正确答案作为 positive sample,把那些又长又啰嗦的答案作为 negative sample,教模型偏向简洁的回答风格。
- Long2short RL:在标准的强化学习训练阶段之后,选择一个在性能和 token 效率之间实现最佳平衡的模型作为基础模型,并开展一个单独的长转短强化学习训练阶段(Long2short RL)。在这个第二阶段,应用上面提到的 length penalty 惩罚机制以惩罚那些虽然可能正确但超出预期长度的回复。
后面的实验效果表示 long2short RL 效果最好。
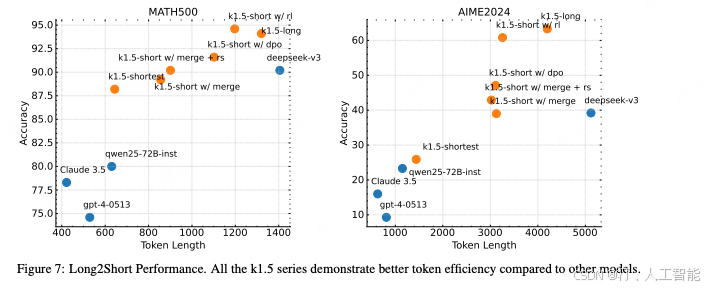
Pretraining and SFT
- Pretraining 分三个训练阶段:
- 先教模型理解语言,再理解图像。
- 然后进行 “冷却” 阶段,用精选的数据帮助模型巩固所学, 这一阶段 focus 在推理知识。
- 最后训练模型处理超长文本的能力,可以一次处理 13 万多个词。
- SFT 数据: 对于一般的问答、写作等任务,他们先人工标注一些样本来训练初始模型。然后收集各种提示词,让模型生成多个回答,再请人类评判并改进最好的答案。对于数学和编程这类有明确对错的任务,他们用自动化的方式来筛选好的训练样本。最终的训练数据包含了 100 万个文本样本,其中,50 万个是通用问答,20 万个是编程相关,20 万个是数学和科学题,5 千个是创意写作,2 万个是长文本任务 (如摘要、文档问答等)。另外还有 100 万个图文互动的样本,用来训练模型理解图表、识别文字、看图编程等能力
RL Infrastructure
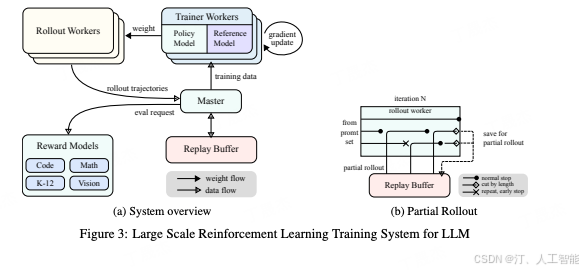
Kimi 团队开发了创新的训练系统,通过 “Partial Rollouts 部分展开” 技术处理超长思维过程,巧妙地在同一硬件上交替进行训练和推理,并建立高效代码沙盒 Code Sandbox 评估编程能力。
实验结果
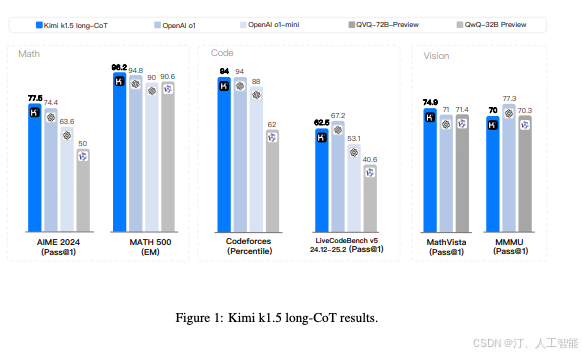
long-CoT 的结果,对比的都是推理模型
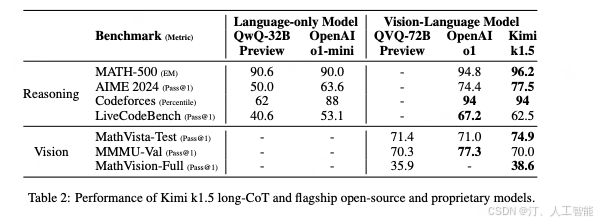
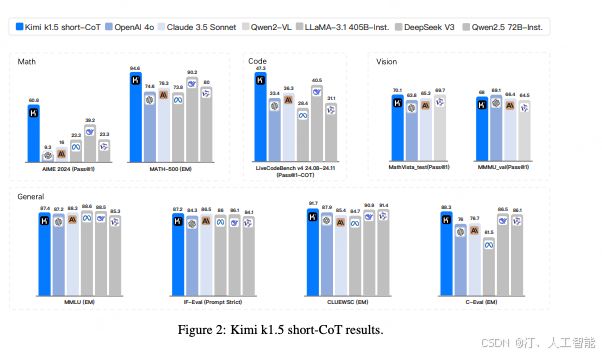
short-CoT 的结果,对比的都是语言模型
随着训练的过程,模型回复越来越长,准确率也越来越高
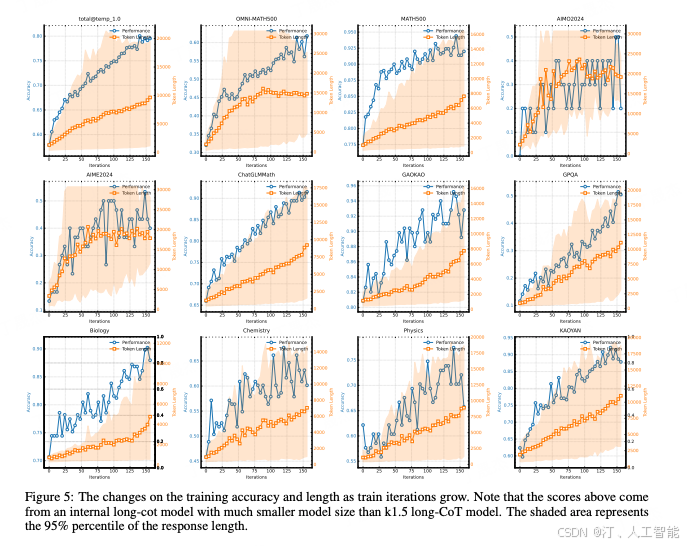
- Scaling of model size and context length
探讨了 RL 提升 CoT 生成能力与简单增加模型规模的比较。研究发现,虽然较大模型初始表现更好,但通过 RL 优化的较小模型使用更长的 CoT 后,可以达到与大模型相当的性能。不过大模型在令牌效率方面仍然占优。这表明:如果追求最佳性能,增加大模型的上下文长度会有更高上限且更高效;而如果测试时计算资源有限,训练小模型并增加上下文长度是可行方案。但论文里没有提到这个 small size 究竟有多 small,因为按 DeepSeek-R1 论文里提到,直接在 32B 的 qwen 上用大规模的 RL,效果其实是不好的。
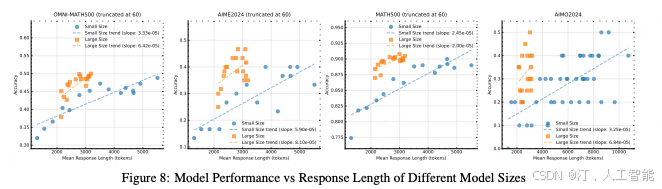
- Effects of using negative gradients
比较了使用负梯度的 RL 方法与不使用负梯度的 ReST 算法在生成长思维链 (CoT) 任务中的效果。研究发现,在此场景下,使用负梯度来惩罚错误回答的方法比仅拟合最佳回答的 ReST 表现出更好的样本复杂度,即需要更少的训练样本就能达到更好的性能。这表明在生成长 CoT 过程中,负梯度起着关键作用,能显著提高训练效率和推理质量。
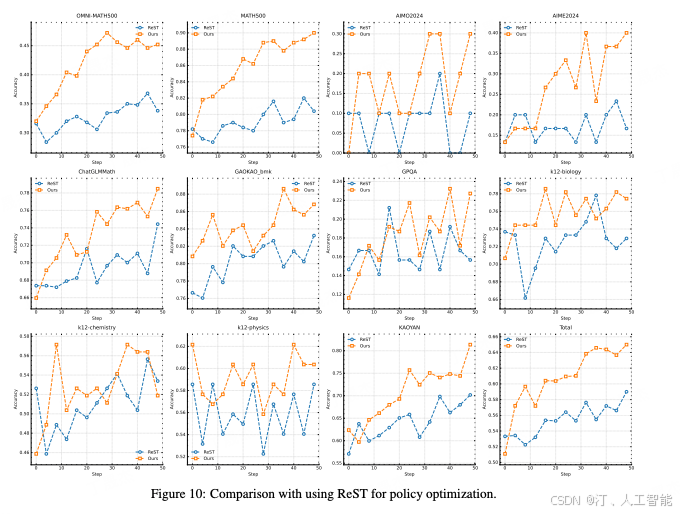
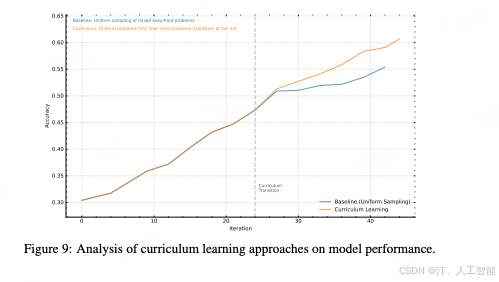
- Sampling strategies
课程采样策略的有效性,该策略包括两个阶段:先用包含各难度问题的数据集进行热身,然后专注于难题训练。研究表明,相比于无课程调整的均匀采样的 baseline,这种逐步增加挑战性的方法显著提升了模型性能,让模型对复杂问题有更稳健的理解和解决能力。
kimi 为啥不如 deepseek-R1 出圈
尽管 Kimi 1.5 论文含金量高,包含很多 DeepSeek-R1 未提及的技术,但朋友们应该也感觉 kimi1.5 体验是不如 DeepSeek-R1 的。对比了下两篇论文的做法,可能原因是
- Kimi 1.5 只做了一轮 SFT+RL 训练,而 DeepSeek-R1 做了精细化的两轮(第一轮 focus 在推理,第二轮是为了泛化)
- Kimi 的训练数据可能过于集中在推理任务
- Kimi 回复存在语言混杂问题,没用 DeepSeek-R1 的语言惩罚
听说 Kimi1.6 快出了,估计上述的问题很快会优化。
- 总结
最后分享点个人的一点关于复现推理模型的见解,欢迎大家多多交流
-
SFT+RLHF 的迭代训练组合才是王道。SFT+RLHF DeepSeek-R1 和 [Kimi1.5]都跑通了,猜测不用纯 RL 的原因很简单,强化学习训练难,通常为了避免训崩,通常会用 KL 散度限制模型不要偏离初始分布太远。但这种限制也可能束缚了模型的潜力发挥。因此先通过 SFT 来让模型拟合到一个最优点附近的分布,再用强化学习这种方式。SFT 保证稳定性,RLHF 则提供突破性能上限的能力。
-
强化学习是突破性能上限的关键突破点,还有好多可以提升的方向
-
**推理数据还没挖掘尽。**现在的推理数据大部分是 STEM 题、数学和代码题。让人不禁思考,还有没有请它类型的高质量推理数据呢?即使是代码,有没有其它的展示形式呢?最近看了 deepseek 的一篇论文《CODEI/O: Condensing Reasoning Patterns via Code Input-Output Prediction》,论文提出一种新颖的创建推理数据的方法:假如有一个代码函数,以及正确的输入参数和输出。让模型根据代码和输入,用自然语言的形式预测输出,假如输出跟实际输出一致,就可作为一条高质量的推理数据。这种基于代码构建推理数据的方法非常创新。
-
**RL 训练方式。**在强化学习算法上,各家大模型采用的方法各不相同:DeepSeek 用他们家的 GRPO,Kimi1.5 用的是在线策略镜像下降的变体,而 Llama 则组合了 PPO+DPO。未来肯定会有更强大的强化学习算法出现。
-
PRM 和 MCTS 可能不如想象中重要,因为它们难以实现规模化。正如 DeepSeek-R1 所指出,PRM 的主要缺点在于难以指定标注标准、难以快速大量人工标注,这使得 PRM 难以扩展。相比之下,规则奖励或 ORM 更为实用——只要模型预测正确就给予正反馈,不论中间过程如何。随着大规模 RL 和 base model 做大,过程错误但结果正确的数据所带来的噪声影响似乎并不显著。
-
奖励模型仍然必不可少。DeepSeek-R1 训练的第四阶段表明,对于没有明确答案无法应用规则奖励的数据,依然需要依赖训练好的奖励模型。特别是针对垂类微调的 RLHF,特定领域的奖励模型尤为重要。
-
未来垂类推理模型的发展方向
预测针对垂直领域的 RLHF 训练需采用混合策略:对存在明确测试用例的领域(如代码、数学),优先采用规则奖励模型(ORM)验证结果正确性;对主观性强的垂类(如法律咨询、医疗诊断),则需构建领域专属的奖励模型。数据层面需融合通用推理数据(如逻辑推导、代码问题)与垂类特定数据(如医学诊疗路径),同时探索领域知识的结构化表达(如知识图谱辅助的奖励设计)。训练过程中需注意平衡领域专精与通用推理能力的保留。 -
小 size 模型的可行性探索
当前 RLHF 成功案例多基于大模型(如 DeepSeek-R1),但小模型的潜力值得关注。核心挑战在于小模型能否通过 DeepSeek-R1 这套迭代训练的流程达到可用效果,还是必须依赖大模型蒸馏(如传闻中的 o3-mini 可能采用的技术路径),期待相关的论文出现。
总之,大模型训练正在从简单的 SFT 向更复杂的迭代训练方式发展,而强化学习将成为未来突破性能上限的关键所在。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 66
66 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)