Linux深入理解文件系统(19)
在Windows下,我们经常会有分盘的操作,比如说C盘和D盘这很有意思,其背后的原理是什么呢,当我们格式化的时候,背后都发生了什么呢?我们将在本篇有所感悟!设计的极其精妙,计算机先辈的智慧不由得不令人赞叹!!!大家可以问DeepSeek,找到 inode、Super block 等的源码来进一步掌握!!!
文章目录
–
前言
在Windows下,我们经常会有分盘的操作,比如说C盘和D盘
这很有意思,其背后的原理是什么呢,当我们格式化的时候,背后都发生了什么呢?
我们将在本篇有所感悟!
一、磁盘文件
在计算机中,没有被打开的文件都是静静的躺在外存(磁盘)中,当需要对文件进行操作时,会通过 inode 对文件进行访问
磁盘文件由两部分构成,分别是文件内容和文件属性。文件内容就是文件当中存储的数据,文件属性就是文件的一些基本信息,例如文件名、文件大小以及文件创建时间等信息都是文件属性
在Linux操作系统中,文件的文件信息和内容是分离存储的,其中保存文件信息的结构称之为inode,因为系统当中可能存在大量的文件,所以我们需要给每个文件的属性集起一个唯一的编号,即inode号。
也就是说,inode是一个文件的属性集合,Linux中几乎每个文件都有一个inode,为了区分系统当中大量的inode,我们为每个inode设置了inode编号。
通过以下指令查看当前目录中文件的详细信息及 inode 值
注意: 无论是文件内容还是文件属性,它们都是存储在磁盘当中的。
ls -lai
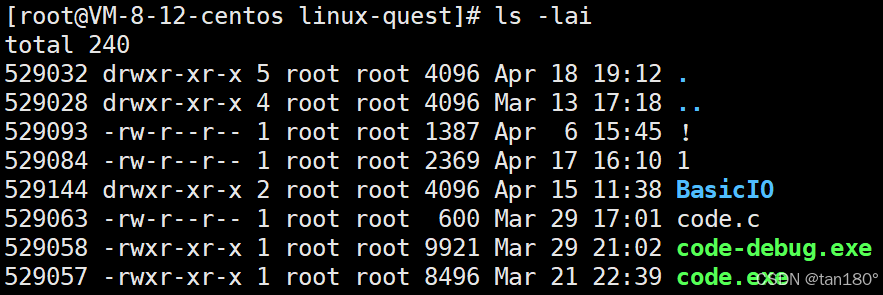
如同 pid 与进程的唯一对应性一样,inode 与文件也是唯一对应的(未被硬链接的情况下),可以通过 inode 访问文件在磁盘中的详细信息
磁盘文件是如何进行管理的?
- 磁盘文件的管理类似于菜鸟驿站,其中的包裹就像待访问的文件,而 inode 就是取件码
- 得益于这种规范化的存储模式,我们可以做到对文件的快速定位、快速读取和快速写入
可能有点过于抽象了,但是我们可以继续往下看
二、磁盘概念
现在市面上的磁盘主要分为 机械硬盘 和 固态硬盘,前者读取速度慢,但便宜、稳定;后者读取速度快,但价格高昂且数据易损,两者各有其应用场景,本文主要介绍的是 机械硬盘
基本结构
机械硬盘是我们电脑中的唯一一个机械设备,并且它还是一个外设,根据 冯诺依曼体系结构,机械硬盘 在速度上远远慢于 CPU 和 内存
假设 CPU 运行速度是纳秒级,那么内存就是微秒级,而机械硬盘只不是是毫秒级
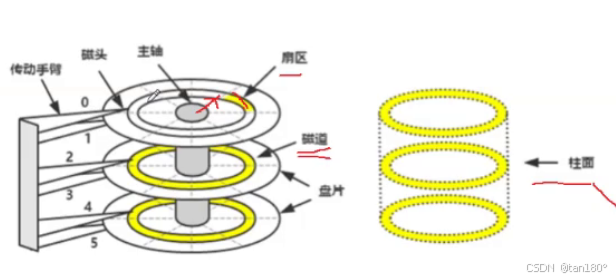
机械硬盘 的主要结构主要包括以下几种:
- 盘片:一片两面,每一面都可以存储数据,有一摞盘片
- 磁头:一面配备一个磁头,专门用于读取盘面中的数据
- 主轴:用于控制整块盘的转动
- 音圈马达:控制磁头的进退
- 磁头臂:链接磁头与音圈马达
- 伺服电路板:控制读取数据的流向及各种结构的运行
……
注意: 多个盘片、多个磁头都是共进退的
机械设备 控制是需要时间的,因此导致 机械硬盘 读写数据速度相对于 CPU 和 内存 来说比较慢
数据存储
总所周知,数据是以 0 和 1 的方式进行存储的,常见的存储介质有:强信号与弱信号、高电平与低电平、波峰与波谷、南极与北极 等,而盘面上比较适合的是 南极与北极
当磁头移动到指定位置时
- 向磁盘写入数据:N->S
- 删除磁盘中的数据:S->N
磁盘中读写的本质:更改基本元素的南北极、读取南北极
注意: 磁头并非与盘面进行直接接触,而是以 15 纳米的超低距离进行磁场更改,假如真是直接接触的话,就会与盘面发生摩擦(高速旋转)发热,从而导致磁场消失,该扇区失效,数据丢失
机械硬盘工作原理
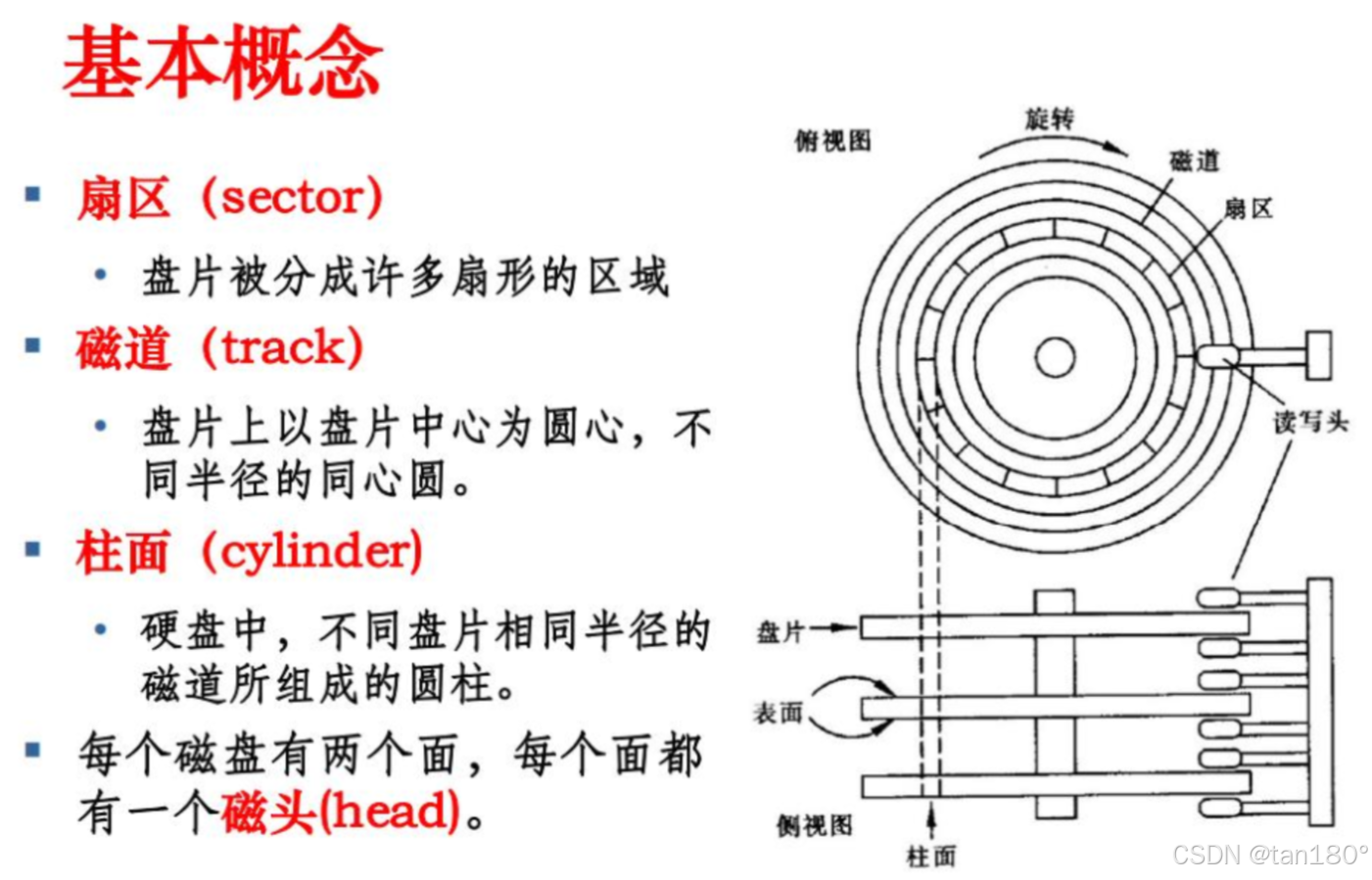
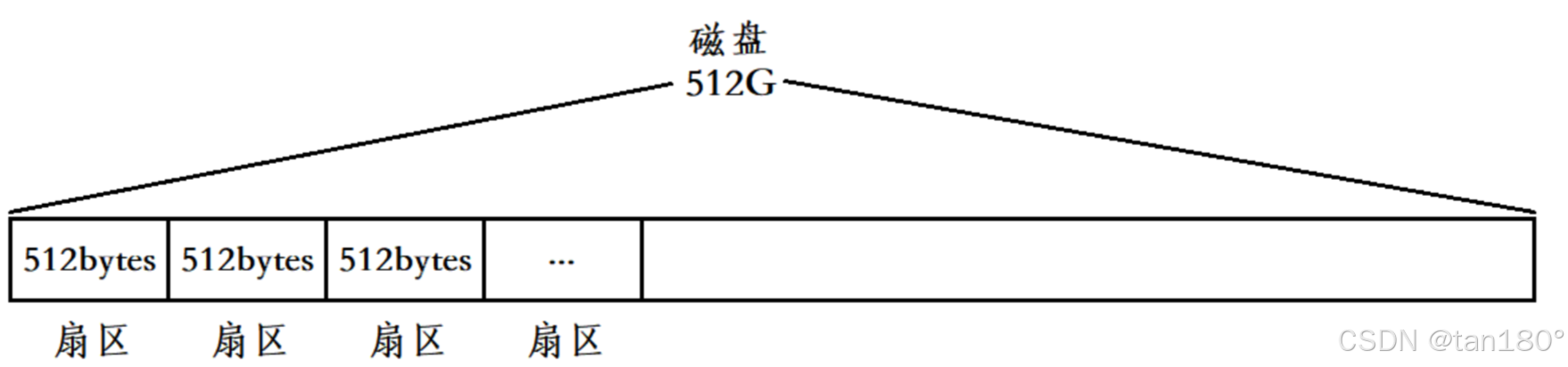
在盘面设计上,一个盘面被切割若干个扇区,单个扇区大小为 512 字节(或者 4 kb),这些扇区用来存储数据,同一半径中的所有扇区组成扇面;而半径相同的扇区组成磁道(柱面)
我们可以先根据磁头(head)确定盘面,再根据半径定位磁道(柱面 cylinder),最后根据块号确定扇区(sector)
这种寻址方法称为 CHS 定位法,是机械设备查找具体扇区时的方法
文件(数据+属性)在存储时,占用一个或多个扇区进行数据存储
虽然 CHS 定位法很妙,但它太依赖于具体硬件信息了,假设其中的硬件参数有所不同,那么 OS 就得使用另一套 CHS 定位法,于是为了做到 解耦,OS 使用的并非 CHS 定位法进行文件定位,而是采用 LBA 逻辑地址块进行寻址
将盘面分割为多个线性分区,通过下标 N 计算出 CHS 地址,然后进行文件访问
将磁道拉长,会得到一串线性空间(数组),其中的每个单位(扇区)为 512 字节(或者 4 kb)
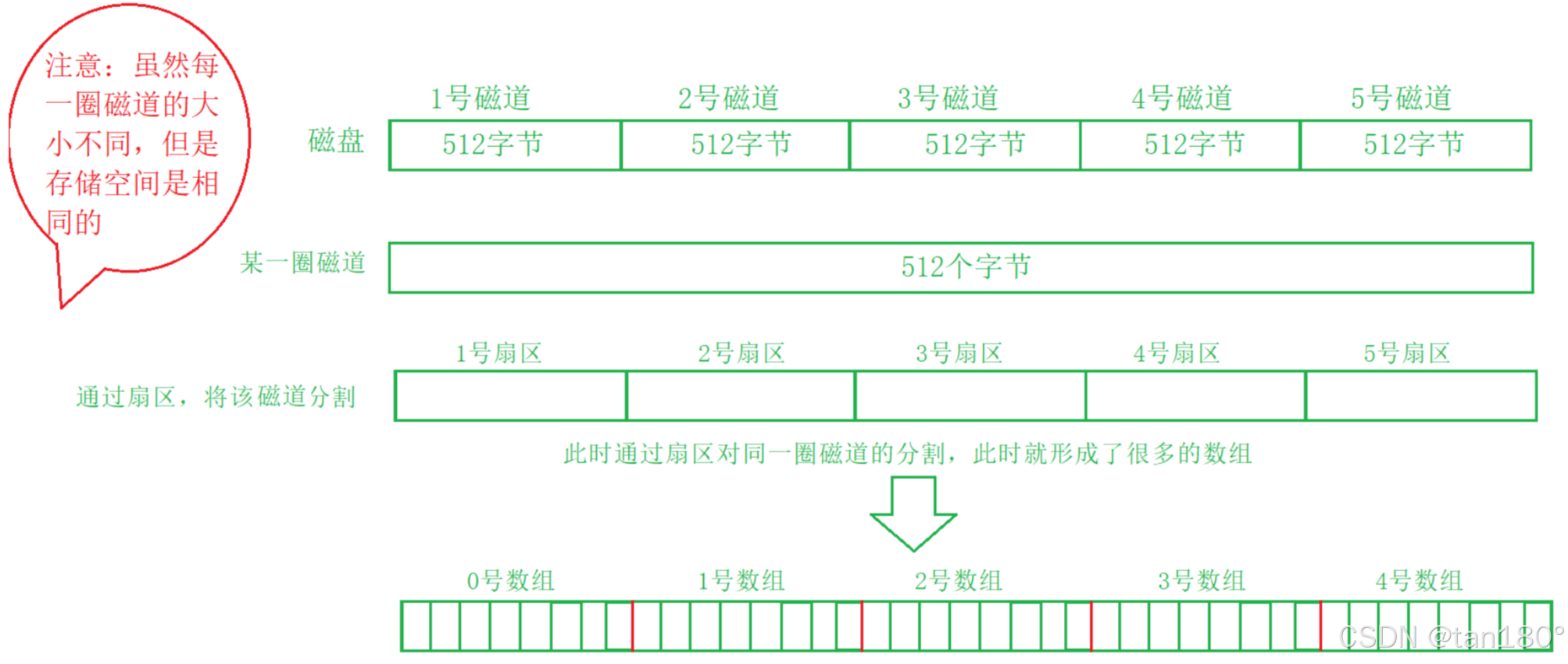
现在 OS 想访问具体的扇区时,只需通过 起始扇区的地址 + 偏移量 就可以获取 LBA 地址,然后通过特定手段转为 CHS 地址,交给外设进行访问即可 LBA 和 CHS转换
因此对于外设中文件的管理,经过 先描述,再组织 后,变成了对数组的管理,这个数据就是 task_struct 中的 struct block
最后我们就能理解为什么 IO 的基本单位是 4 kb 了,因为直接读取一个数据块(4 kb),这样可以提高 IO 效率(内存对齐)
CHS && LBA
某⼀盘⾯的某⼀个磁道展开,是一维数组
整个磁盘所有盘⾯的同⼀个磁道,即柱⾯展开,是二维数组
整个磁盘不就是多张⼆维的扇区数组表,是三维数组
所以,寻址⼀个扇区:先找到哪⼀个柱⾯(Cylinder) ,在确定柱⾯内哪⼀个磁道(其实就是磁头位置,Head),在确定扇区(Sector),所以就有了CHS
我们之前学过C/C++的数组,在我们看来,其实全部都是⼀维数组

所以,每⼀个扇区都有⼀个下标,我们叫做LBA(Logical Block Address)地址,其实就是线性地址。所以怎么计算得到这个LBA地址呢?
CHS转成LBA:
- 磁头数 * 每磁道扇区数 = 单个柱⾯的扇区总数
- LBA = 柱⾯号C * 单个柱⾯的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱⾯号C * (磁头数 * 每磁道扇区数) + 磁头号H * 每磁道扇区数 + 扇区号S - 1
- 扇区号通常是从1开始的,⽽在LBA中,地址是从0开始的
- 柱⾯和磁道都是从0开始编号的
- 总柱⾯,磁道个数,扇区总数等信息,在磁盘内部会⾃动维护,上层开机的时候,会获取到这些参
数。
LBA转成CHS:
- 柱⾯号C = LBA // (磁头数 * 每磁道扇区数)【就是单个柱⾯的扇区总数】
- 磁头号H = (LBA % (磁头数 * 每磁道扇区数)) // 每磁道扇区数
- 扇区号S = (LBA % 每磁道扇区数) + 1
- “//”: 表示除取整
所以:从此往后,在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部自己转换
从现在开始,磁盘就是⼀个 元素为扇区 的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤磁盘,就可以⽤⼀个数字访问磁盘扇区了
三、磁盘信息
分区意义
磁盘空间是巨大的,如果不加以划分,会导致 OS 的管理成本提高,对应到现实生活中,学校需要将不同专业的学生及老师分为不同学院,比如计算机学院、人文学院等,分院后的好处不言而喻,最重要的是上层管理者更好的调用管理资源,这种思想称为 分治思想
在文件系统中,OS 先将整个大文件系统分为不同的区,存入 struct disk 数组中进行管理
struct disk
{
struct part[2];
//……
};
可以通过 ll /dev/vda* -i 查看当前系统中的 分区数 及 详细信息

系统在分区后,需要对区块进行格式化
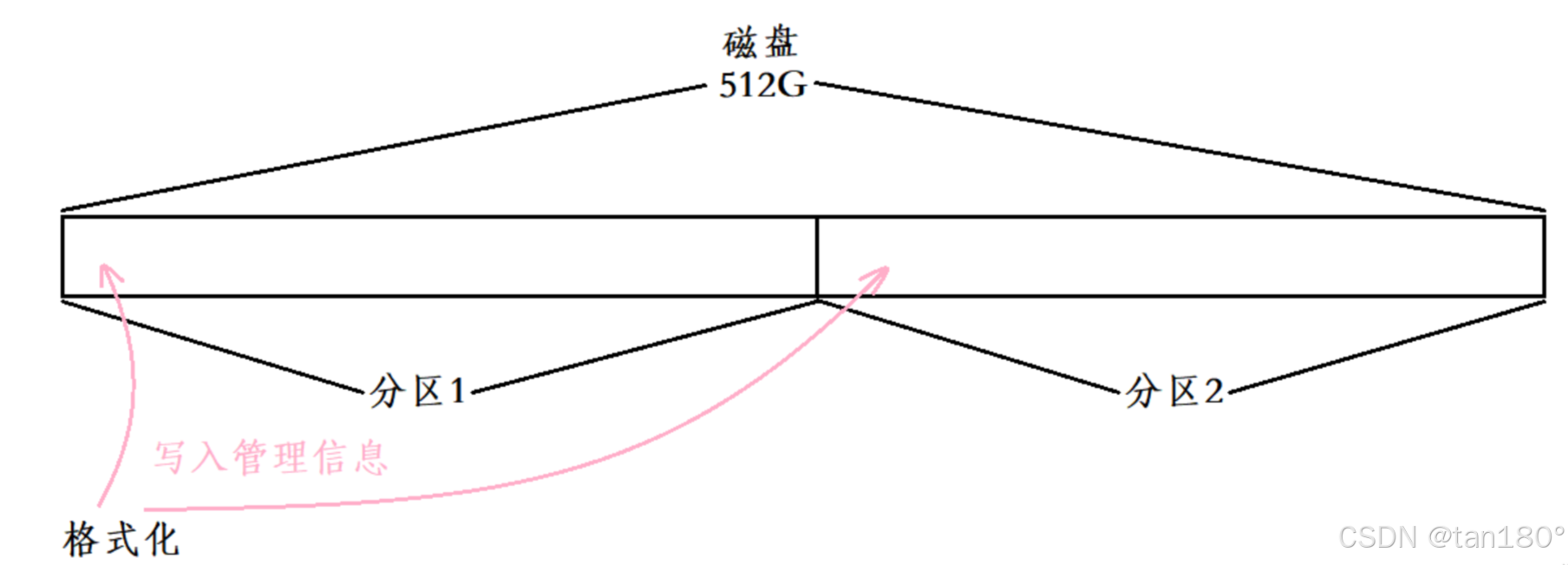
不同的文件系统在格式化时写入的数据是不同的,这里讨论的是 EXT 文件系统
- 磁盘分区后,分组、填写系统属性是 OS 做的事
- 为了使分区能被正常使用,需要对分区进行格式化
- 分区格式化:OS 向分区写入文件系统的管理属性信息
- 在具体分区内,还可以细分为 块组
由 块组 构成的线性空间亦可称为 组线 (代表一个 分区)
struct part
{
struct part group[100]; //分为100个块组
int lba_start; //起始与结束位置
int lba_end;
//……
}
将现有资源再分配后,可以 最大化利用资源,避免造成浪费及拖慢效率
块组(Block Group)是本文的重点内容
块组信息
块组 是由 分区 细分出的产物,它与分区的关系如图所示
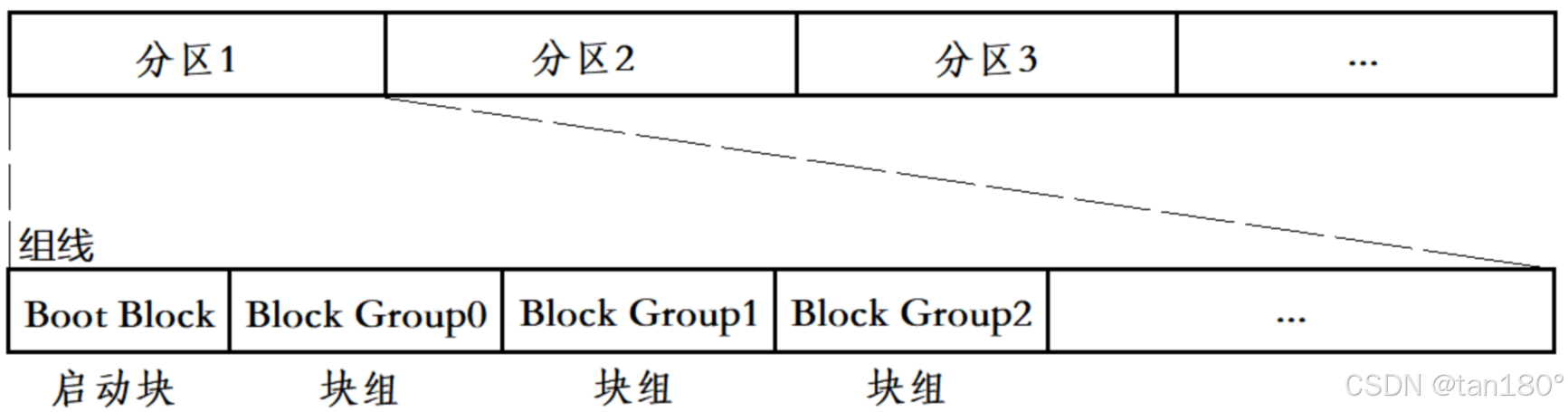
其中, Boot Block 是 启动块,大小固定为 1 kb,在每一条 组线 前都有此 块组,它用来 存储分区信息和系统启动,属于被保护的内容,不允许用户私自修改
至于其他 块组,它们有着统一的格式,具体内容如图所示
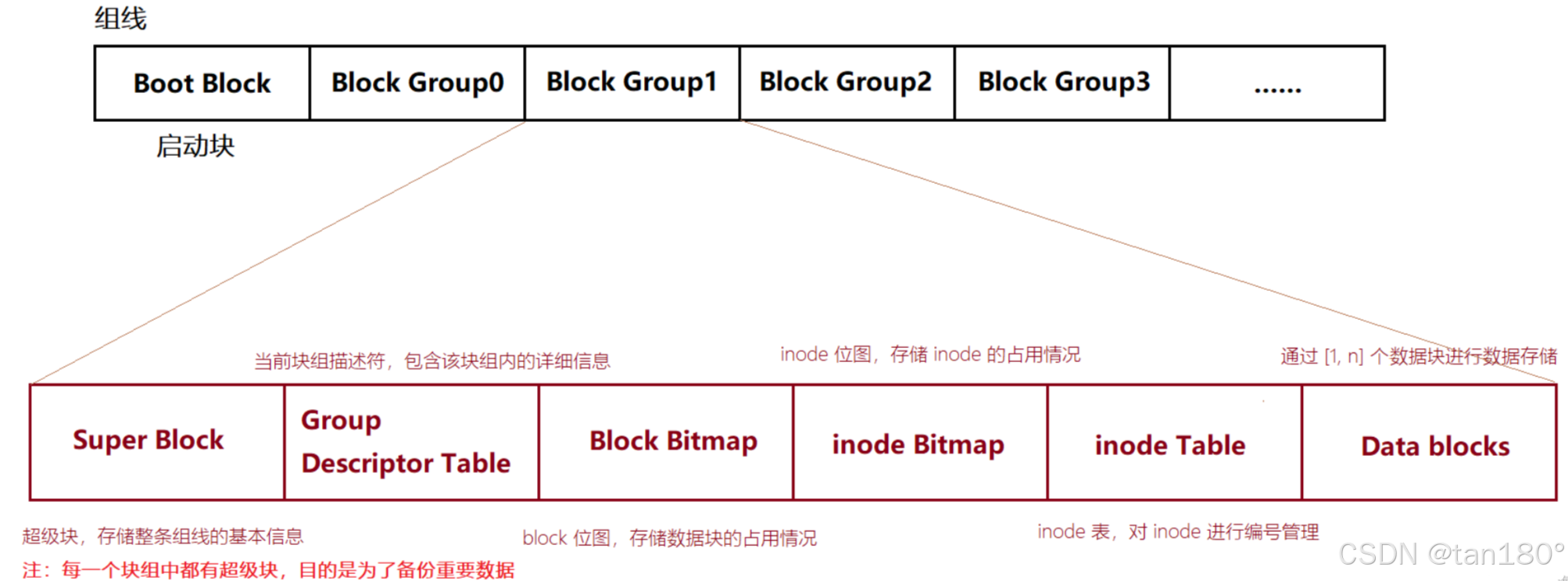
其中一个文件对应一个 inode,而 inode 中存储了该文件的所有属性,包括所使用的数组块信息,因为文件很多,所以需要 先描述,再组织,即通过 inode Table 对 inode 进行管理
- Super Block: 存放文件系统本身的结构信息。记录的信息主要有:Data Block和inode的总量、未使用的Data Block和inode的数量、一个Data Block和inode的大小、最近一次挂载的时间、最近一次写入数据的时间、最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
- Group Descriptor Table: 块组描述符表,描述该分区当中块组的属性信息。
- Block Bitmap: 块位图当中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。
- inode Bitmap: inode位图当中记录着每个inode是否空闲可用。
- inode Table: 存放文件属性,即每个文件的inode。
- Data Blocks: 存放文件内容。
注意:
- inode 属性中并不包含文件名,文件名只是给用户用的
- 目录文件也有 inode,目录中的数据块保存的是该目录下的 文件名 和 inode 编号对应的映射关系,而且在此目录内,文件名和 inode 互为 key 值
- inode 确定分组,inode 值只在一个分区内有效,不能跨分区
- 其他块组当中可能会存在冗余的Super Block,当某一Super Block被破坏后可以通过其他Super Block进行恢复
- 磁盘分区并格式化后,每个分区的inode个数就确定了
四、文件相关操作
接下来看看文件是如何创建在磁盘中的
文件创建
创建一个文件的步骤如下:
- 申请一个空闲的 inode,将文件信息记录至 inode 属性中(其实就是遍历找到一个空的inode)
- 寻找空闲的数据块(Data block),将数据块信息填入 inode 中的磁盘分布区
- 添加文件名至当前目录文件的 Data block 中,同时将文件名和 inode 之中的属性链接起来
注意: 每使用一个 inode 和一个 Data block,它们对应位图中的信息都会被改为已占用

文件访问
文件创建后,如何根据 inode 访问文件呢?
- 找到文件的 inode 编号,在目录分组中查找
- 通过 inode 和 Data block 的映射关系,找到文件的数据块,并加载至内存中
这也就解释了为什么在 file 对象中会存在 inode 信息,因为它与 fd 一样重要
对文件进行增删查改
文件创建后,如何删除?删除并不是真删除,而是将 inode Bitmap 和 Block Bitmap 中位图信息进行修改即可(只要访问不到,就是删除)
- 根据文件名找到 inode 编号
- 再根据 inode 属性中的映射关系,设置 Block Bitmap 对应的比特位,设置为 0 (删内容)
- 最后根据 inode 编号设置 inode Bitmap 中对应的比特位为 0 (删属性)
将位图信息置为 0 后,创建新文件时,系统可以直接使用
至于文件的查找与修改,通过 inode 修改其内部属性即可
注意: inode 和 Data blcok 可能存在失衡的情况
- 一直创建空文件,导致 inode 满载,而 Data block 空余很多
- 不断往同一个文件中写入数据,导致 Data block 被占用,后续创建文件时,inode 无法再分配到 Data block
文件误删后的解决方案
通过对上文文件进行增删改查的原理的掌握,你应该能猜到数据是可以恢复的,并且应该要能说个大概的原理
前面说过,删除并不是真删除,访问不到就行了,所以只要在删除后,根据 inode 找到 Data block,其中的内容没有被覆盖,数据就可以找回来
应急方案:
- 不要轻举妄动,避免 Data block 被覆盖
- 通过 inode 将 inode Bitmap 中的位图置 1,使文件复活,再根据属性进行数据恢复
- 如果自己不知道 inode,那就尽早断电,送给厂家恢复(专业)
大文件存储
单个数据块大小有限(4 kb),如何做到一个数据块存储大量数据?
答案是 套娃,Data block 中存储其他 Data block 信息,此时称为多级索引,可以做到一个数据块中存储大量数据
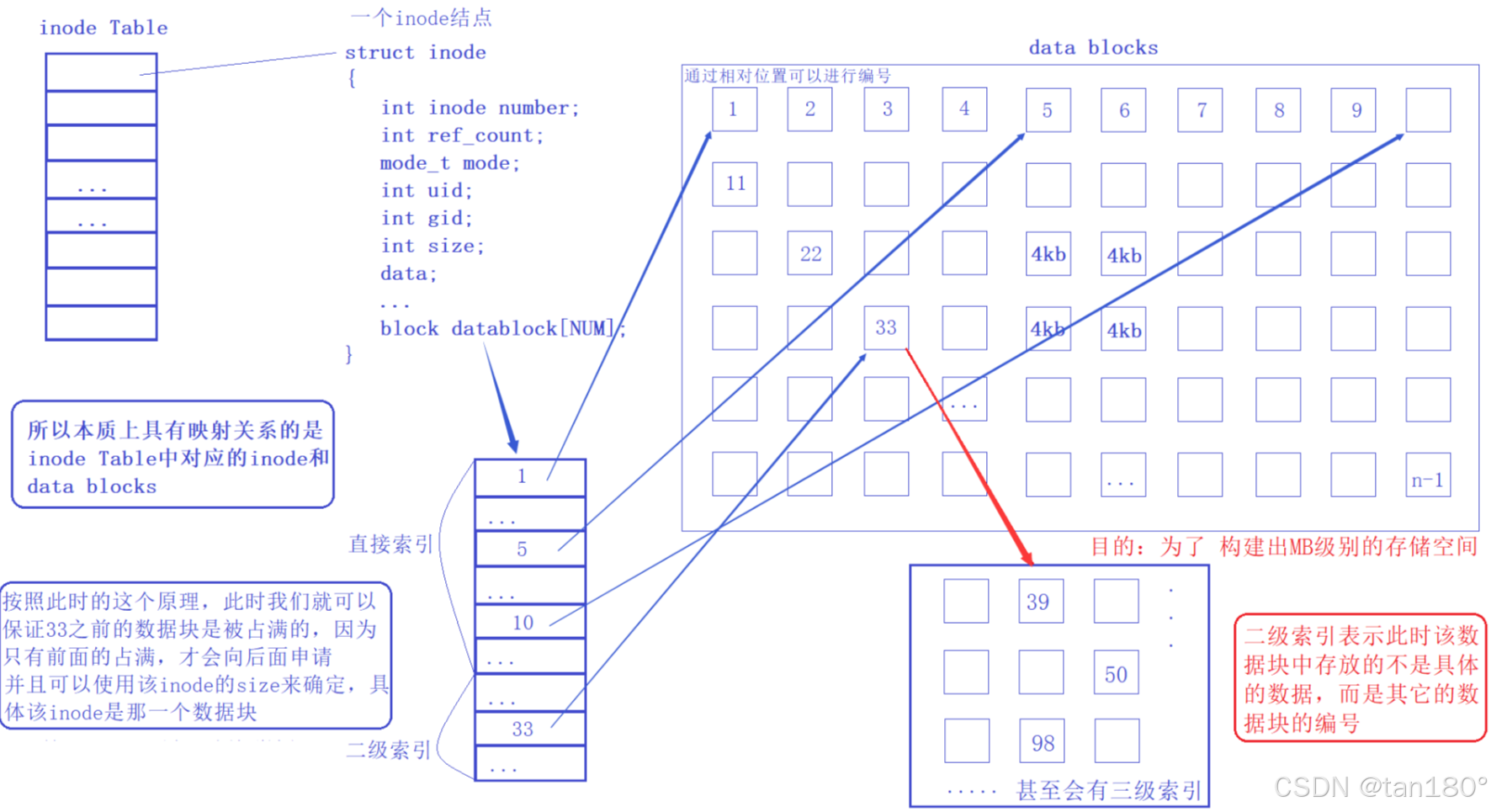
请注意:
一个文件使用的数据块和inode结构的对应关系,是通过一个数组进行维护的,该数组一般可以存储15个元素,其中前12个元素分别对应该文件使用的12个数据块,剩余的三个元素分别是一级索引、二级索引和三级索引,当该文件使用数据块的个数超过12个时,可以用这三个索引进行数据块扩充
如何理解目录?
- 都说在Linux下一切皆文件,目录当然也可以被看作为文件。
- 目录有自己的属性信息,目录的inode结构当中存储的就是目录的属性信息,比如目录的大小、目录的拥有者等。
- 目录也有自己的内容,目录的数据块当中存储的就是该目录下的文件名以及对应文件的inode指针。
注意: 每个文件的文件名并没有存储在自己的inode结构当中,而是存储在该文件所处目录文件的文件内容当中。因为计算机并不关注文件的文件名,计算机只关注文件的inode号,而文件名和文件的inode指针存储在其目录文件的文件内容当中后,目录通过文件名和文件的inode指针即可将文件名和文件内容及其属性连接起来。
所以我们现在就能解释, 为什么同一个目录下不能有同名文件?
ll 查看时,先找到目录的 inode, 目录内容中存储了文件的 inode,找到对应文件的 inode,就可以访问文件内容啦,例如说删除文件实际上是删除文件名与 inode 的关联,也就是从目录项中移除该文件名。
可是目录的 inode 怎么求,是不是就要一直递归往上了,一直到根目录 “/” 这个是我们所知道的
并且为了效率,Linux内核源码还有一个dentry缓存机制,你问我为什么不讲解,因为我看了源码和博客,我至今也没有搞明白。。。。。就交给大家自己去了解了!
总结
设计的极其精妙,计算机先辈的智慧不由得不令人赞叹!!!
大家可以问DeepSeek,找到 inode、Super block 等的源码来进一步掌握!!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)