
大模型真的是下一个Token的预测器吗?
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~很久以前,牛顿发现了一个引力方程。这个方程非常简单(最多是高中代数水平),但它不仅能解释苹果为什么下落,还能预测行星及其卫星的椭圆运动。但它还是有一些小问题。最著名的是水星轨道与预测不符
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
很久以前,牛顿发现了一个引力方程。这个方程非常简单(最多是高中代数水平),但它不仅能解释苹果为什么下落,还能预测行星及其卫星的椭圆运动。
但它还是有一些小问题。最著名的是水星轨道与预测不符。爱因斯坦在提出广义相对论时解决了这些问题,这一理论还预测了黑洞和引力波的存在。
你可能听过类似这样的说法:"LLM(大语言模型)只是预测下一个词的统计模型。"就像牛顿的引力理论一样,这是对真相的逼近。
在这篇文章里,我将讨论指令微调和人类反馈强化学习(RLHF)。
目标不是深入探讨这些概念,而是用它们来解释 LLM 在多大程度上真正超越了下一个 token 的预测器的统计模型,它某种程度上可以认为是按照自己的"意愿"采取"行动"。
我们现在都知道 LLM 训练的三步:
- 预训练
- 指令微调 (SFT)
- 人类反馈强化学习(RLHF)
简单讨论大语言模型预测下一个词的概念。比如训练数据中有一个句子"我不喜欢蛋挞",可以构建的训练样本可能是这样的:(我, 不), (我不, 喜), (我不喜, 欢), (我不喜欢, 蛋), (我不喜欢蛋, 挞)…
也就是说,模型接收到该词之前的所有内容,然后必须预测下一个词。
从数学角度看,模型的输出根据交叉熵损失进行评判,衡量模型输出概率与实际下一个词之间的差异。
在预训练过程中,模型接收大量这样的文本并预测接下来的内容。但仅靠这种方法还不足以制造一个聊天机器人。
例如,如果你要求 GPT-3"写一篇关于足球的文章",它可能不会写文章,而是通过预测最可能的下一个词来续写这个句子。
它可能输出"写一篇关于足球的文章,首先要要对这项运动有深入的了解。。。"。
这就是接下来指令微调的作用。这么做使得模型在零样本学习上表现更好,即你只需告诉模型执行任务,无需提供任务示例,它就能完成。
这一步和预训练的差异主要是训练数据,指令数据集可以简单认为是,user assistant 的对话数据,模型通常只在 completion 部分上进行训练,而不是整个提示。
但除此之外,指令调整本质上与预训练相同,因为损失函数相同,模型仍然被训练来预测下一个 token。
但是,RLHF 很不一样。关于 RLHF 否真的是强化学习还有争议,Andrej Karpathy 说勉强算是,Yann LeCun 说不是,但关键是它与下一个 token 预测是非常不同的目标函数。
RLHF 步骤有两个:
- 给模型不同的提示词,让它生成多种不同的输出。对于每个提示,我们要求人类对输出进行排名。这就是 RLHF 中的人类反馈。用于训练一个奖励模型,预测人类会更喜欢哪个输出。
- 然后使用这个奖励模型来训练大语言模型生成人类会喜欢的输出。
奖励模型的损失函数是:
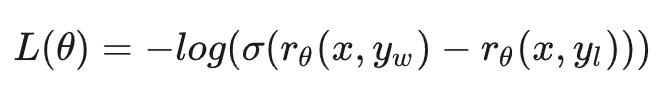
在这个公式中,我们的输入是一个提示 x 和一对输出 y_w 和 y_l,其中 y_w 是人类标注者更喜欢的输出,y_l 是他们不太喜欢的输出。
函数 r_θ 是奖励模型,它接收输出并返回一个分数。σ 是 sigmoid 函数。
我们得到一条看起来像这样的曲线:
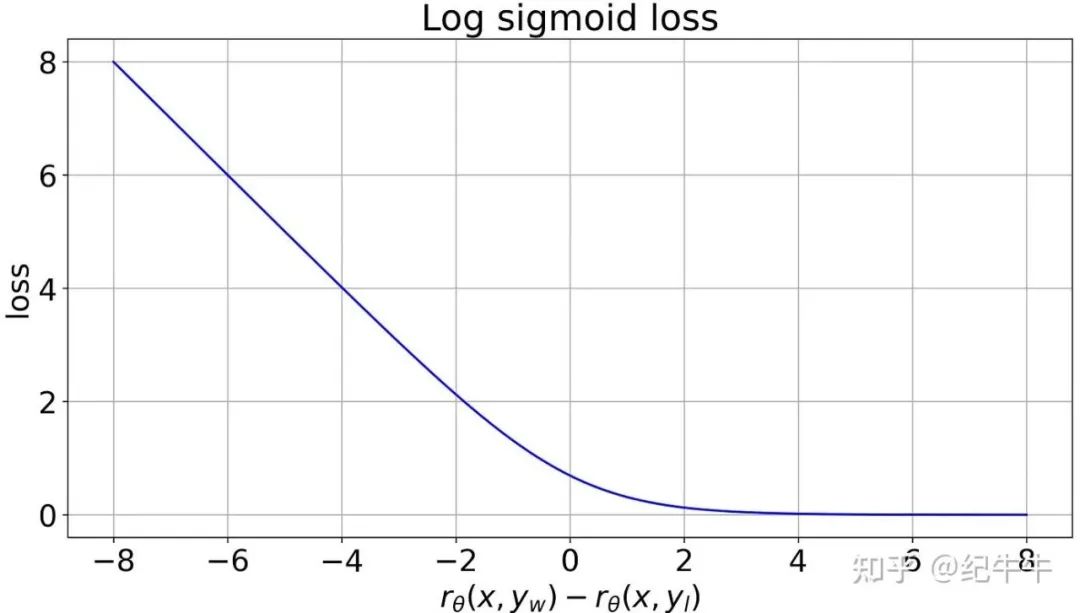
我们可以看到,当我们给人类认为更好的输出打更高的分数时,损失下降。另一方面,如果我们给人类实际认为更好的输出低分时,损失会上升。
通过以这种方式在人类提供的标签上训练奖励模型,我们最终得到一个可以预测人类对输出的喜好程度的模型。
有了这个函数 r_θ,在训练大语言模型的损失函数中使用奖励模型。因为大语言模型通过指令微调已经相当不错,所以是微调。这就是 PPO(proximal policy optimization)的思想。
训练的新目标函数如下:

先看第一项:
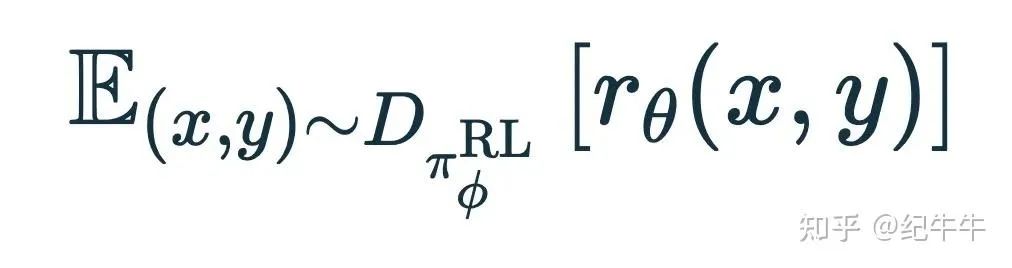
这里,(x,y)∼D 是我们用于 RLHF 训练的数据集,输入 (x),y 是模型对应的输出。
目标函数是奖励模型 r_θ(x,y) 在训练数据上的期望值。所以这里是试图最大化之前训练的奖励模型预测的奖励。
接下来是第二项:
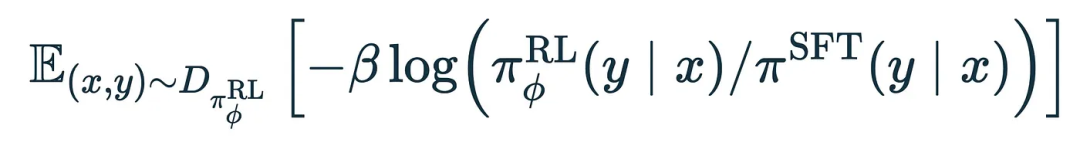
同样,x 是提示,y 是模型输出。现在 π_RL(y|x) 是我们正在训练的当前模型的预测概率,而 π_SFT(y|x) 是我们开始时的基础模型的预测概率,该基础模型已经完成预训练和指令微调。
令 p=π_RL(y|x) 和 q=π_SFT(y|x),这也是:
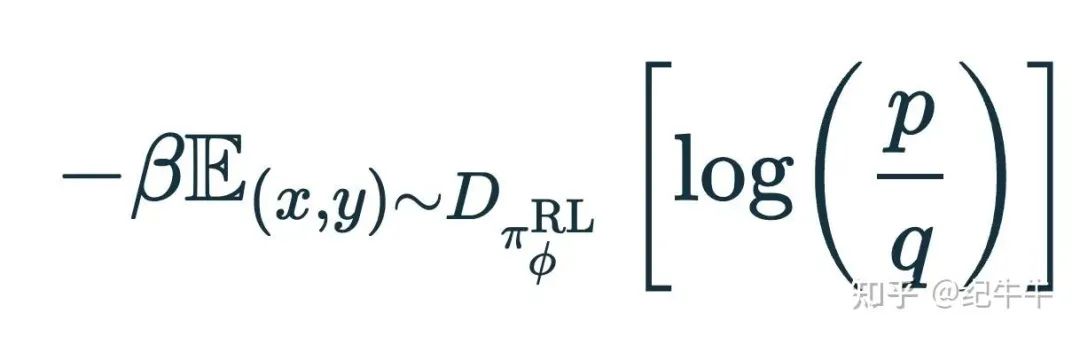
这个期望值是两个分布 p 和 q 之间的 Kullback-Leibler 散度(KL 散度),它表示两个分布的差异程度。
通过对差异施加惩罚,确保在训练模型时,其输出概率与基础模型中的输出概率(预训练+指令微调后的模型)保持相近。
最后是最后一项:
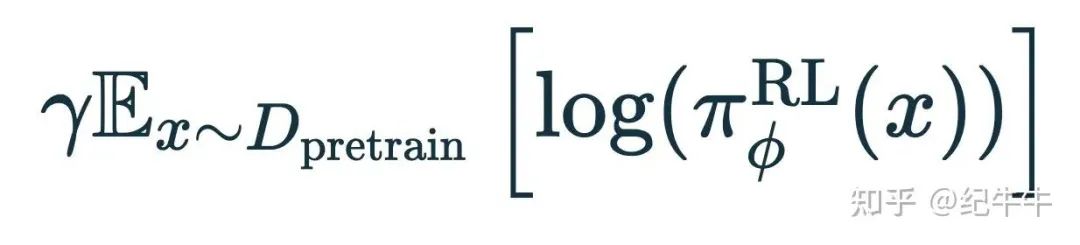
这里不是 RLHF 提示和输出数据集,而是回到预训练数据集 D_pretrain。这一项形式上和之前下一个 token 的预测采用的损失函数是一样的,只是乘以一个常数 γ。
添加这一项的目的是进行 RLHF 时,保持在预训练数据上预测下一个 token 的良好性能。
总结这三项的含义:
- 试图最大化之前训练的奖励模型给出的奖励。预期生成人类会偏好的输出。
- 对偏离基础模型太远的输出分布添加惩罚。
- 在预训练数据上混合一些普通的下一个 token 预测。
这个就是 PPO,"proximal"是因为我们保持接近基础模型,"policy optimization"是因为在强化学习中,模型的输出概率被称为模型的策略。
可以看到只有第三项直接训练模型预测下一个 token。第二项某种程度上是下一个 token 预测的近似。但第一项,与下一个词元预测有根本不同。
简单介绍下典型的强化学习是什么样的,以一个 AlphaGo 的下棋模型为例。如果不讨论树搜索的细节,该模型观测棋盘当前的子力位置状态最为输入,输出可能下一步棋的位置的分布(其策略)。
模型基于它所下的结果,即最终是赢了还是输了构建奖励函数来进行训练。也就是说我们有一个 agent(下棋模型)观察环境(棋盘当前的棋子位置信息)并采取行动(棋盘上的移动),下完之后反过来影响环境。
它在每一步的选择,都是能够最大化其预期奖励的动作。其动作表现为策略,即可能的下一步棋的概率分布。
无论 RLHF 是否真正属于强化学习,我们都可以在这里得出一个重要的类比。
LLM 不仅仅是下一个 token 预测器,它们是 agent,观察其环境(提示和目前为止的输出)并采取行动(下一个 token),这些行动影响环境。
它们试图选择能够最大化其预期奖励的行动(奖励模型,帮助它们产生人类喜欢的输出)。
无论我们如何训练 LLM,不变的部分是其输入空间(提示词的字符串)和输出空间(所有 token 组成的词表)。
换一种方式来解释:LLM 是一个以输出的内容能讨好人类评判者为目标的 agent。在有了 RLHF 这一步之后,它就不仅仅是统计模型。
那么问题来了,如果 LLM 已经是 agent,那么大家说的 agent 是什么呢。但其动作空间仅限于生成 token 或者说字符串。
通过将字符串映射到真实世界的行动,我们可以得到字符串以外的东西。RLHF 中的奖励函数是人类对 LLM 输出的喜好构建的奖励模型的 agent。
可以想象我们可以定义其他类型的奖励模型,使得 LLM 可以采取的各种行动。代码是一个明显的例子,agent 可以通过强化学习被训练来正确编码,因为代码是否正确是一个有清晰明确反馈的场景。
从根本上说,大语言模型不是下一个 token 预测器。实际上更加底层:一个输出 token 的机器。
我们可以选择是训练该机器来预测下一个 token,取悦人类评估者,编写代码,还是做完全不同的事情。
我们可以选择是简单地向用户显示这些 token,还是使用它们来调用函数并影响现实世界。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 30
30 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)