爆料!DeepSeek R2即将发布:1.2万亿参数,成本暴跌97%,真王炸,还是空欢喜?
爆料!DeepSeek R2即将发布:1.2万亿参数,成本暴跌97%,真王炸,还是空欢喜?
DeepSeek 这是要搞一波大的了?
一条关于 DeepSeek 新模型的消息在 AI 圈里炸开了锅。
什么?DeepSeek-R2,混合专家模型,5.2 PB 训练数据,1.2 万亿总参数,780 亿动态激活参数,最最炸裂的是,R2 的训练和推理成本比 GPT-4 还要低 97.3%?!
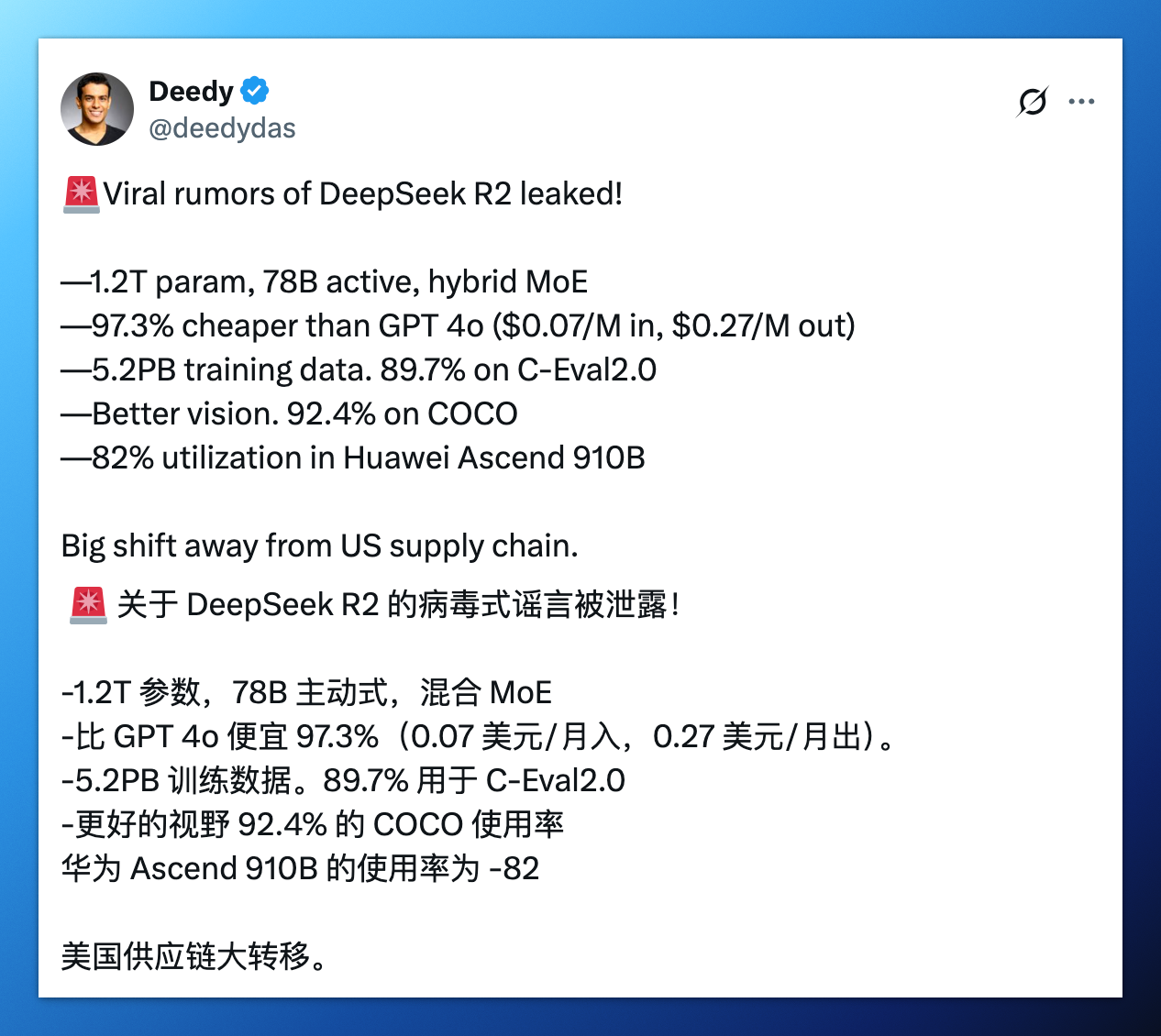
上面这条在 X 平台疯传的帖子,经我调查,源头来自一个叫“韭研公社”的投资平台。

根据“韭研公社”的爆料,DeepSeek-R2 模型采用混合专家 3.0(Hybrid MoE 3.0)架构,总参数规模达到惊人的 1.2 万亿,其中动态激活 780 亿;单位 token 推理成本比起 GPT-4 Turbo 下降 97.3%,硬件适配上实现了昇腾 910B 芯片集群 82% 的高利用率,算力接近 A100 集群。
然而,先别急着开香槟,爆料的真实性仍待 DeepSeek 官方确认。
“热心”的外国网友甚至根据这则爆料制作出了下面这份 DeepSeek-R2 概念股(DeepSeek R2 Concept Stocks)的盘点图。
一个字,绝!

中文翻译版在这里。

此外,无独有偶,Hugging Face(抱抱脸)CEO Clément Delangue 也在几小时前发布了一条耐人寻味的“谜语”帖。
帖子内容仅有三个 👀 小表情,以及 DeepSeek 在 Hugging Face 的仓库链接(按照惯例,DeepSeek 的开源模型会第一时间发布在 Hugging Face 仓库)。
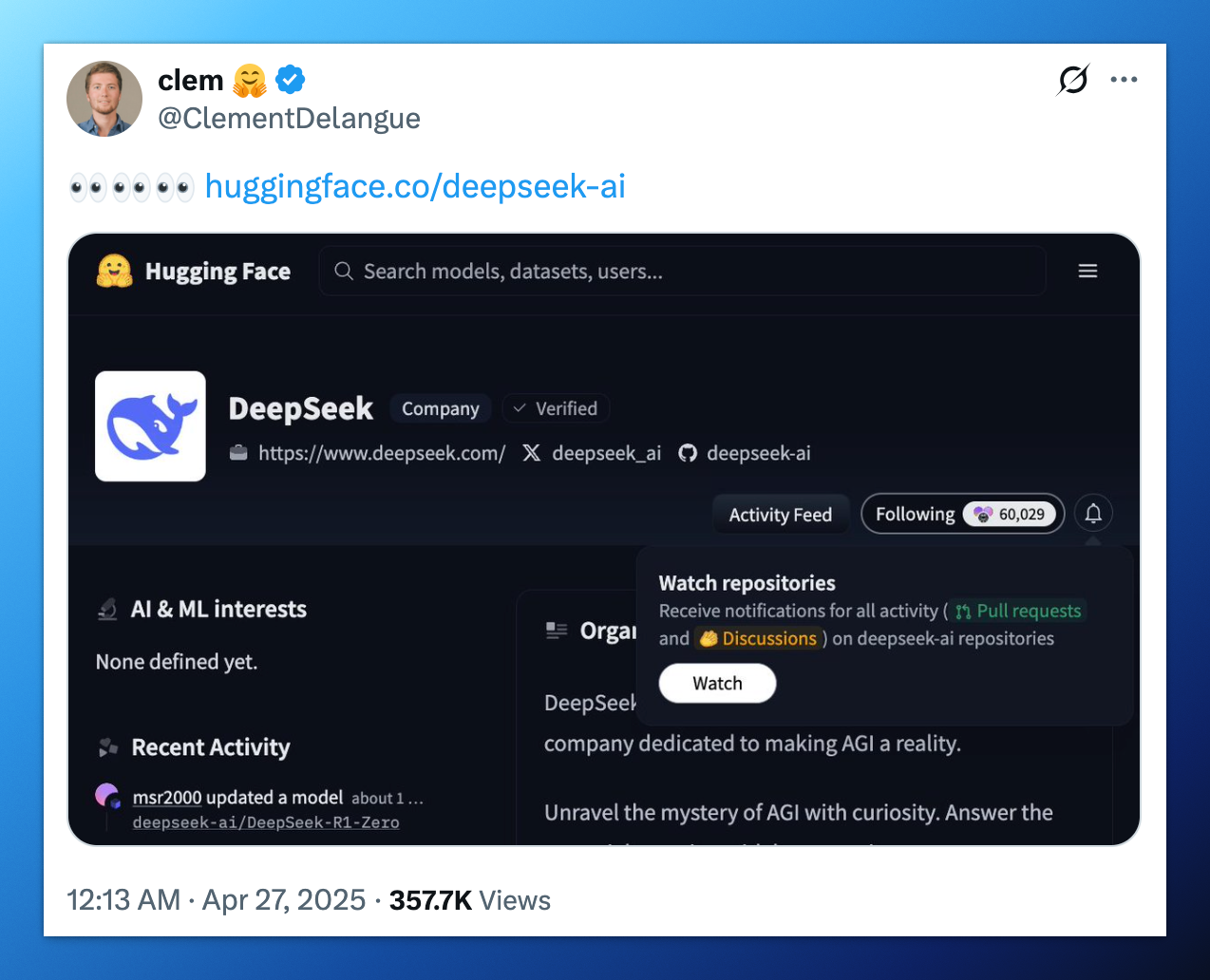
该说不说,留给 DeepSeek 的时间不多了。
距离轰动全球的 DeepSeek-R1 模型发布已经过去了 3 个月。
在这期间,有太多比 R1 强的新模型涌现:北美“御三家”有近期刚发布的 o3 + o4-mini、曾一度霸榜且免费的 Gemini 2.5 Pro、代码之王 Claude 3.7 Sonnet,以及背靠大金主马斯克的 Grok 3。
大模型排行榜的前几位已经看不到 DeepSeek 的身影。
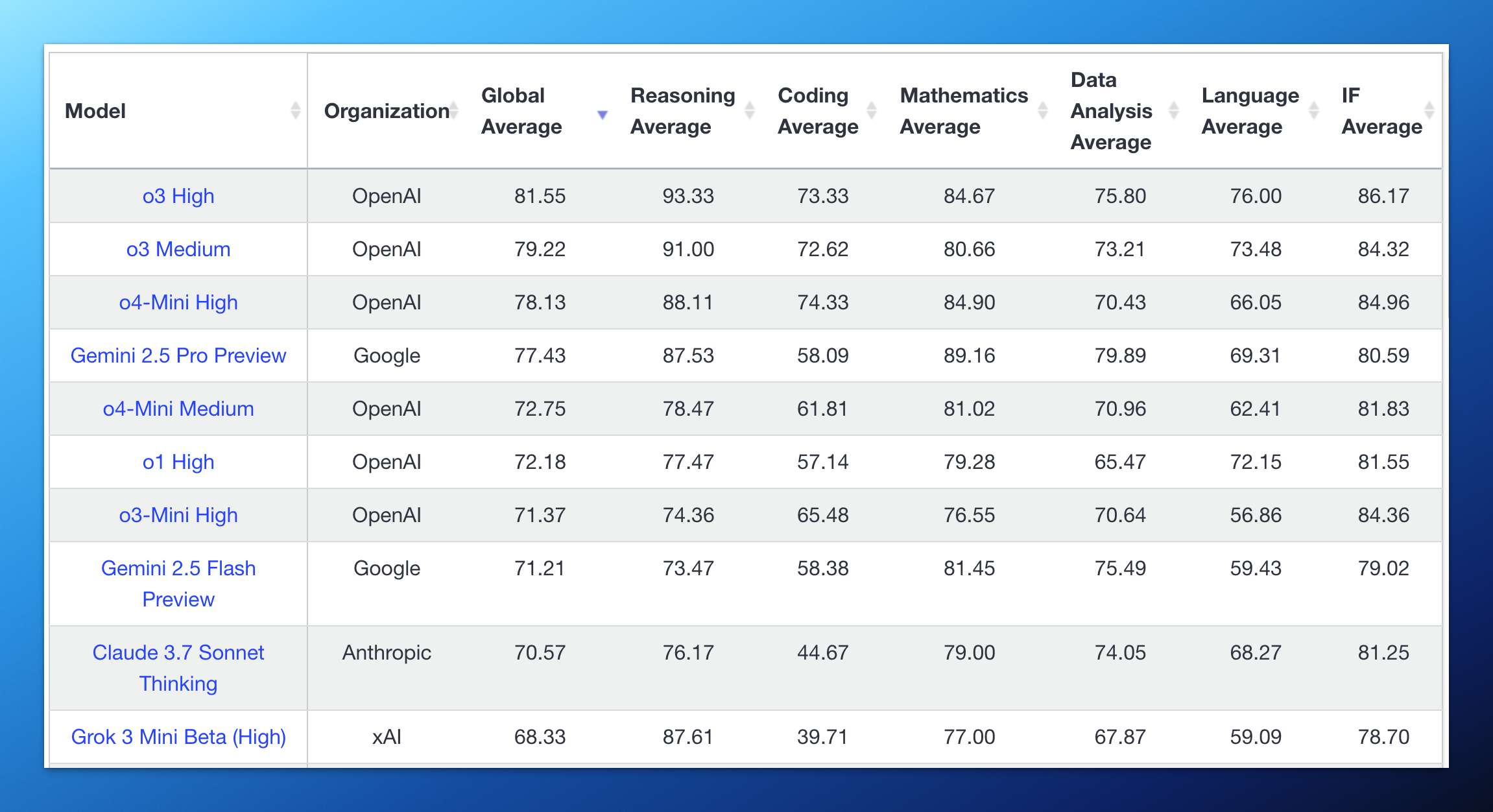
结语
坦白说,这条坊间的传言有几分真几分假,没人知道。
但即使只有一半的数据是真的,也足以引起轰动了。
这个五一假期,AI 圈注定不平静。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
精选推荐

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)