在GPU实例上部署DeepSeek-R1蒸馏模型
在GPU实例上部署DeepSeek-V3/R1模型,需要提前在该实例上安装GPU驱动且驱动版本应为550及以上版本,建议您通过ECS控制台购买GPU实例时,同步选中安装GPU驱动。当下载任务完成后,会停止输出新的日志,您可以随时按下Ctrl+C退出,这不会影响容器的运行,即使退出终端也不会中断下载。Open WebUI:基于Web的交互界面,提供类似ChatGPT的用户体验,支持对话记录管理、多模
DeepSeek-V3/R1是拥有600B以上参数量的专家混合(MoE)模型,并已经开源了模型权重。本文为您介绍在GPU实例上部署DeepSeek-R1蒸馏模型推理服务。
核心工具介绍
NVIDIA GPU驱动:用来驱动NVIDIA GPU的程序,本文以Driver版本 550.127.08为例。
vLLM:是一个有助于更高效地完成大语言模型推理的开源库,本文以其v0.6.4.post1版本为例。
Open WebUI:基于Web的交互界面,提供类似ChatGPT的用户体验,支持对话记录管理、多模型切换及插件扩展,适合非技术用户直接操作。
操作步骤
步骤一:准备环境
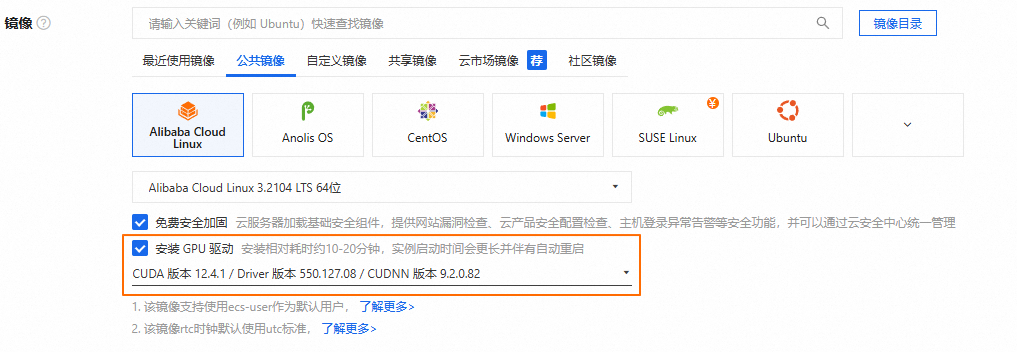
创建GPU实例并正确安装驱动。具体操作,请参见创建GPU实例。关键参数说明如下。
实例规格:参考估算模型所需配置,选择满足对应模型版本的实例规格。
镜像:选择公共镜像,本文以Alibaba Cloud Linux 3.2104 LTS 64位版本的镜像为例。
在GPU实例上部署DeepSeek-V3/R1模型,需要提前在该实例上安装GPU驱动且驱动版本应为550及以上版本,建议您通过ECS控制台购买GPU实例时,同步选中安装GPU驱动。实例创建完成后,会自动安装Tesla驱动、CUDA、cuDNN库等,相比手动安装方式更快捷。
系统盘:参考估算模型所需配置,设置满足对应模型版本的系统盘大小规格,建议系统盘大小设置1 TiB以上。
公网IP:选中分配公网IPv4地址,带宽计费方式选择按使用流量,建议带宽峰值选择100 Mbps,以加快模型下载速度。
安全组:开放22和8080端口。
安装Docker。具体操作,请参见安装Docker。
安装NVIDIA容器工具包。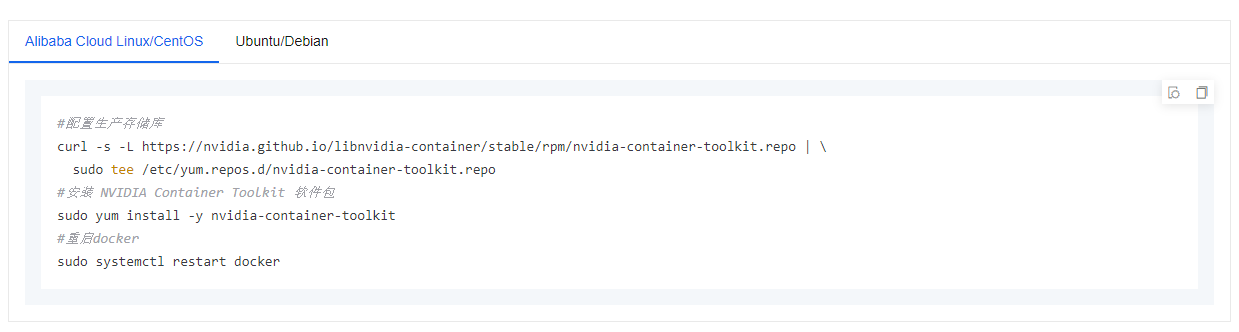
(可选)购买数据盘并完成挂载。
由于模型较大,如果您的系统盘容量不足,建议您单独购买数据盘用于存储下载的模型。建议挂载点以/mnt为例。具体操作,请参见挂载数据盘。
步骤二:部署和运行DeepSeek模型
1、执行以下命令,拉取推理镜像。
sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.6.4.post1-pytorch2.5.1-cuda12.4-ubuntu22.04
2、下载模型文件,您可以访问阿里云魔搭社区Modelscope选择模型,在模型详情页获取名称。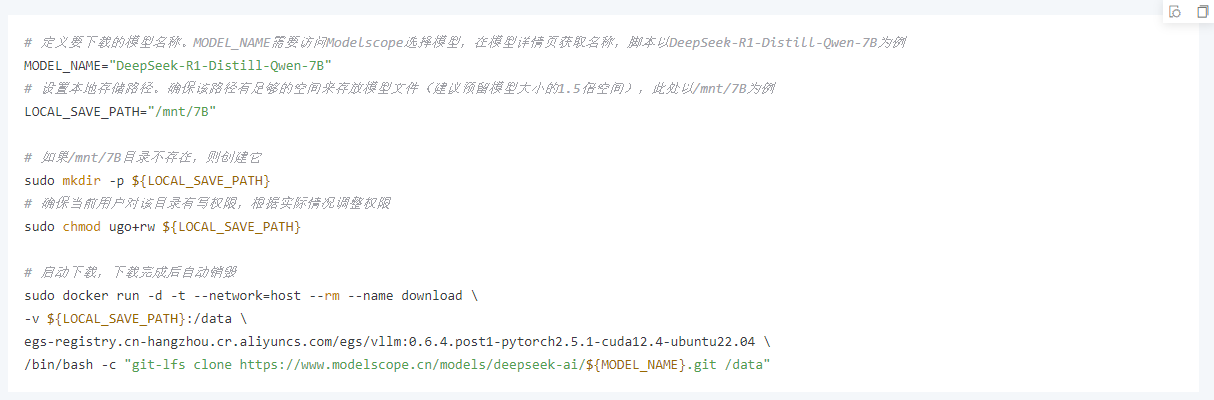
3、执行以下命令,实时监控下载进度,等待下载结束。
sudo docker logs -f download
下载模型耗时较长,请您耐心等待。当下载任务完成后,会停止输出新的日志,您可以随时按下Ctrl+C退出,这不会影响容器的运行,即使退出终端也不会中断下载。
4、启动模型推理服务。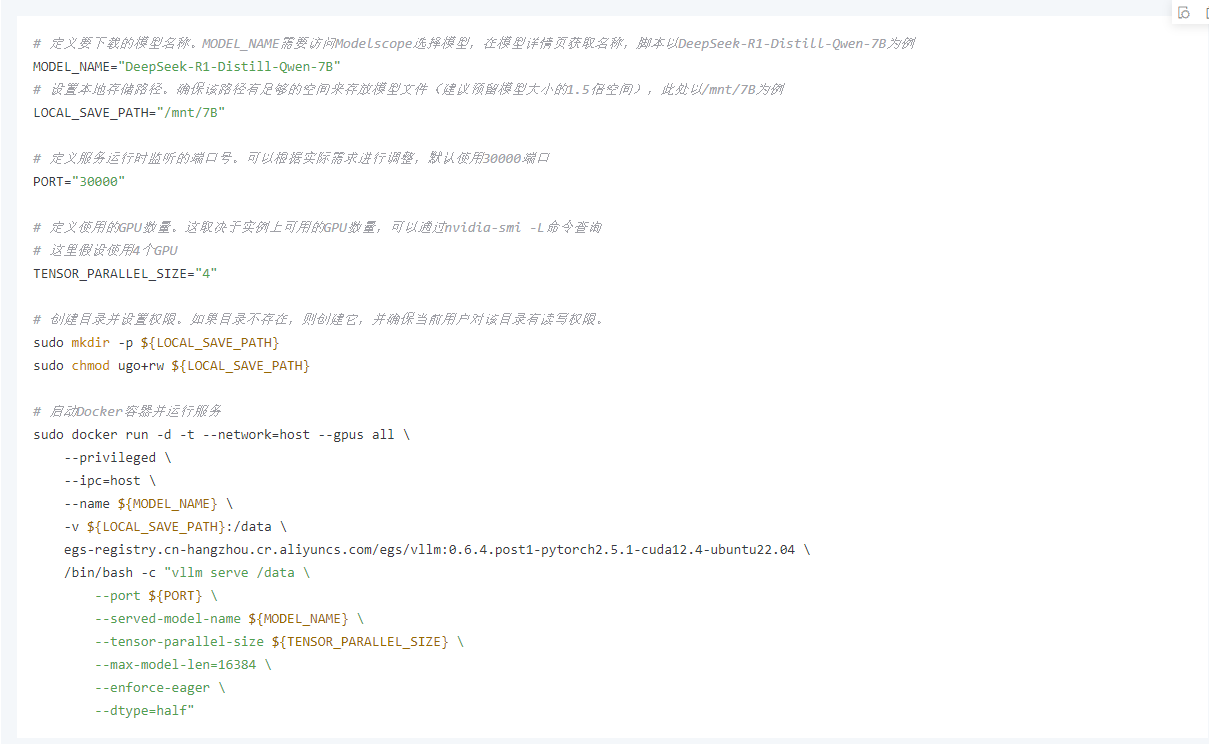
5、运行以下命令,检查服务是否正常启动。
sudo docker logs ${MODEL_NAME}
在日志输出中寻找类似以下的消息:
INFO: Uvicorn running on http://0.0.0.0:30000 (Press CTRL+C to quit)
这表示服务已经成功启动并在端口30000上监听。
步骤三:启动Open WebUI
1、执行以下命令,拉取基础环境镜像。
sudo docker pull alibaba-cloud-linux-3-registry.cn-hangzhou.cr.aliyuncs.com/alinux3/python:3.11.1
2、执行以下命令,启动Open WebUI服务。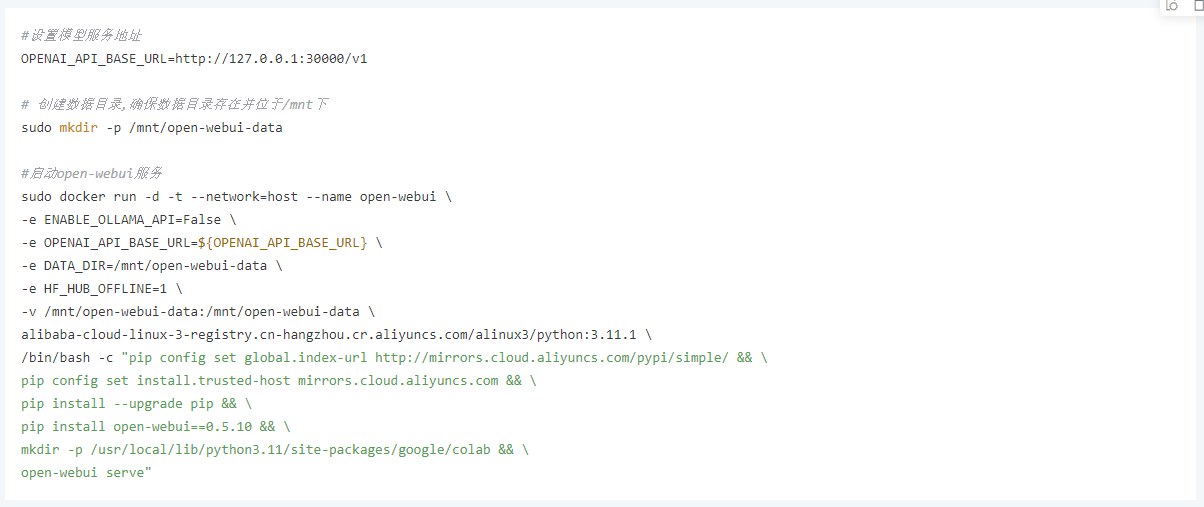
3、执行以下命令,实时监控下载进度,等待下载结束。
sudo docker logs -f open-webui
在日志输出中寻找类似以下的消息:
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
这表示服务已经成功启动并在端口8080上监听。
4、在本地物理机上使用浏览器访问http://<ECS公网IP地址>:8080,首次登录时,请根据提示创建管理员账号。
5、在Open WebUI界面中进行问答测试。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)