DeepSeek微调操作指南:使用Python创建自定义AI模型
了解如何针对各类用例微调DeepSeek R1模型。
近期DeepSeek掀起的热度持续升温。除了尝试在其上构建常规应用外,越来越多的开发者们也开始探索如何对DeepSeek R1进行微调,将其打造为特定领域的专业AI助手。
在本文中,我们将一同了解如何将通用DeepSeek R1转化为针对特定领域的专用大模型。

简介
随着AI技术的快速发展,开发者和创业者们不再满足于直接使用预训练模型,而是希望将其深度集成到自己的产品中。通过模型微调,我们可以使DeepSeek R1在特定领域表现出更强的专业性和针对性。凭借其强大的推理能力,DeepSeek已成为处理各类思考和问题解答任务的理想选择。
在本文中,我们将深入研究如何使用Python配合自定义数据集对DeepSeek R1进行微调,并将成果合并保存至Hugging Face Hub。考虑到微调的计算资源需求,我们将使用Google Colab Notebook来降低实现门槛。
微调准备与设置
在开始微调之前,需要完成以下准备工作。
Python库和框架
微调所需核心Python库包括:
· unsloth:可显著提升Llama 3、Mistral、Phi 4及Gemma等大模型的微调速度,内存占用量减少70%的同时保持准确性。参考文档:https://docs.unsloth.ai/。
· torch:PyTorch的核心库,提供强大的张量计算能力和GPU加速支持。
· transformers:功能强大的自然语言处理(NLP)开源库,支持各类预训练模型。
· trl:基于transformers的强化学习库,可简化transformer模型的微调过程。
计算要求
模型微调虽然不需要重新训练所有参数,但仍对计算资源有较高要求。所有可训练参数和模型都需要存储在GPU的显存中。
本指南将以DeepSeek R1 Distill(4.74B参数)为例,此模型至少需要8到12 GB vRAM,建议使用Google Colab的免费T4 GPU(16 GB vRAM)。
数据准备策略
要对大模型进行微调,我们需要针对特定任务的结构化数据。数据来源可以包括:
• 社交媒体平台
• 网站内容
• 专业书籍
• 研究论文
本指南将使用Hugging Face Hub中的yahma/alpaca-cleaned数据集数据集。更多详情请参考:https://huggingface.co/datasets/yahma/alpaca-cleaned。
Python实现
包安装
在Google Colab中,多数依赖包已预装,我们只需安装unsloth:
安装过程如下:
!pip install unsloth
模型与tokenizer初始化
使用unsloth加载预训练模型:
from unsloth import FastLanguageModel model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit", max_seq_length = 2048, dtype = None, load_in_4bit = True, # token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf )
· 这里我们将模型名称指定为'unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit',用以接入预训练的DeepSeek R1 Distill模型。
· 我们将max_seq_length设置为2048,代表模型所能处理的输入序列的最大长度。通过合理设置,我们可以优化内存使用率及处理速度。
· 将dtype设为None以反映模型所获取的数据类型,并确保与可用硬件相兼容。使用之后,我们将不必检查并声明数据类型,相关问题由unsloth处理。
· load_in_4bit能够增强推理能力并减少内存使用量。其实质是将模型精度量化为4bit。
添加LoRA适配器
下面,我们向预训练的大模型中添加LoRA矩阵,用以微调模型的响应结果。使用unsloth,只需几行代码即可完成:
model = FastLanguageModel.get_peft_model( model, r = 64, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 32, lora_dropout = 0.05, # Can be setto any, but = 0is optimized bias = "none", # Can be setto any, but = "none"is optimized use_gradient_checkpointing = "unsloth", # Trueor"unsloth"for very long context random_state = 3977, use_rslora = False, # unsloth also supports rank stabilized LoRA loftq_config = None, # And LoftQ )
代码说明:
· 我们使用get_peft_model,借助PEFT技术对FastLanguageModel提供的model进行重新初始化。
· 这里还需要传递在上一步中获取的预训练model。
· 此处,r=64参数定义的是LoRA适配中低秩矩阵中的秩。此秩通常会在8–128范围内产生最佳结果。
· lora_dropout=0.05参数在此LoRA适配器模型的训练期间将droput引入低秩矩阵,使用此参数可防止模型过度拟合。
· target_modules负责指定我们在模型之内,应用于LoRA适配的特定类或模块的名称列表。
数据准备
现在,我们已经在预训练大模型上设置了LoRA适配器。下一步开始构建模型训练数据。
为此,我们需要编写出包含输入、指令及响应的提示词。
· Instructions表示对大模型的主查询,即我们提出的问题。
· Input表示除指令或查询之外,我们所传递的其他分析数据。
· Response表示来自大模型的输出,用于解释如何根据特定instruction(查询)对大模型响应进行定制,且不受是否传递input(数据)的影响。
提示词结构如下:
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
这里我们创建一条函数,用以正确构建alpaca_prompt中的所有数据:
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
defformatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output inzip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
现在我们需要加载模型微调所使用的数据集,在本示例中为“yahma/alpaca-cleaned”。关于数据集详情请参考:https://huggingface.co/datasets/yahma/alpaca-cleaned。
from datasets import load_dataset
dataset = load_dataset("yahma/alpaca-cleaned", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
训练模型
有了附带LoRA适配器(矩阵)的结构化数据和模型,下一步开始训练模型。
为此,我们需要对部分超参数进行初始化。这有助于推动训练过程,但也会在一定程度上影响模型的准确性。
这里我们使用SFTTrainer和超参数对trainer进行初始化。
from trl import SFTTrainer from transformers import TrainingArguments from unsloth import is_bfloat16_supported trainer = SFTTrainer( model = model, # The model with LoRA adapters tokenizer = tokenizer, # The tokenizer of the model train_dataset = dataset, # The dataset to use for training dataset_text_field = "text", # The field in the dataset that contains the structured data max_seq_length = max_seq_length, # Max length of input sequence that the model can process dataset_num_proc = 2, # Noe of processes to use for loading and processing the data packing = False, # Can make training 5x faster for short sequences. args = TrainingArguments( per_device_train_batch_size = 2, # Batch size per GPU gradient_accumulation_steps = 4, # Step size of gradient accumulation warmup_steps = 5, # num_train_epochs = 1, # Set this for 1 full training run. max_steps = 120, # Maximum steps of training learning_rate = 2e-4, # Initial learning rate fp16 = not is_bfloat16_supported(), bf16 = is_bfloat16_supported(), logging_steps = 1, optim = "adamw_8bit", # The optimizer that will be used for updating the weights weight_decay = 0.01, lr_scheduler_type = "linear", seed = 3407, output_dir = "outputs", report_to = "none", # Use this for WandB etc ), )
使用此trainer训练模型:
trainer_stats = trainer.train()
模型训练开始,所有步骤及相应Training Loss 训练损失将记录在内核上。
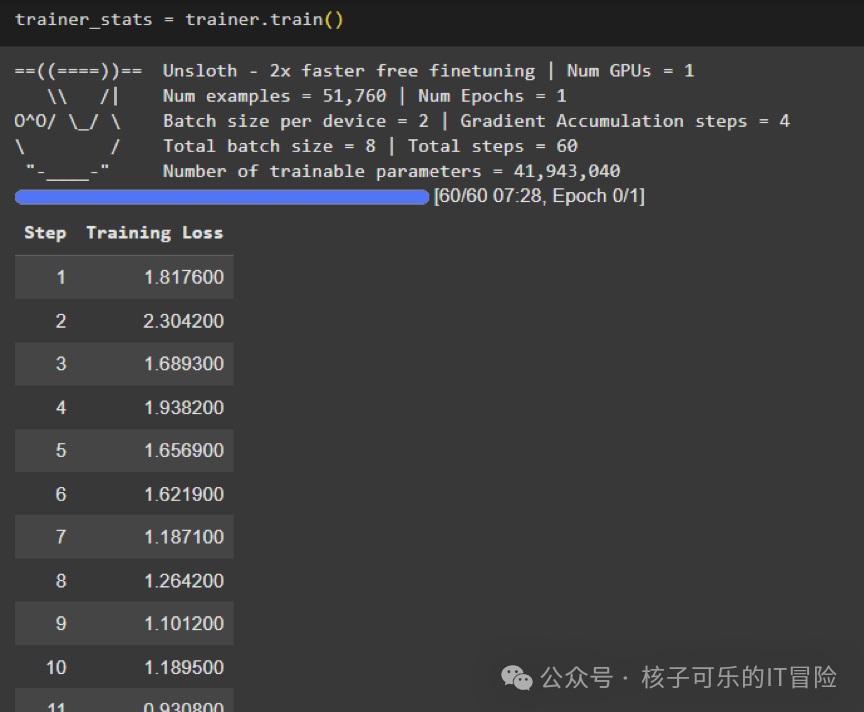
Google Colab上的训练过程截屏。
使用微调后的模型进行推理
模型训练已经完成,现在我们使用微调模型进行推理以评估响应质量。
推理代码为:
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # instruction
"1, 1, 2, 3, 5, 8", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
代码说明:
· 使用unsloth中的FastLanguageModel加载微调后的模型以进行推理。这种方法可更快产生结果。
· 为执行模型推理,首先需要将查询转换为结构化提示词,而后令牌化该提示词。
· 这里还设置了return_tensors="pt"以要求tokenizer返回PyTorch张量,而后使用.to("cuda")将该张量加载至GPU以提高处理速度。
· 然后调用model.generate()以生成查询响应。
· 在生成期间,设置max_new_tokens=64以限制模型所能生成的最大token数量。
· use_cache=True同样有助于加快生成速度,且在长序列条件下效果拔群。
· 最后,将微调模型的输出由张量解码为文本。

微调模型的推理结果。
保存微调模型
到此模型微调的全过程均已完成,我们可以保存结果以供后续推理使用。
这里需要将tokenzier与模型一同保存。以下是将微调模型保存在Hugging Face Hub上的方法:
# Pushing with 4bit precision
model.push_to_hub_merged("<YOUR_HF_ID>/<MODEL_NAME>", tokenizer, save_method = "merged_4bit", token = "<YOUR_HF_TOKEN>")
# Pushing with 16 bit precision
model.push_to_hub_merged("<YOUR_HF_ID>/<MODEL_NAME>", tokenizer, save_method = "merged_16bit", token = "<YOUR_HF_TOKEN>")
· 需要为模型设定名称,此名称将决定模型在Hub上的id。
· 可以上传具有4bit或16bit精度的完整合并模型。合并模型代表将预训练模型与LoRA矩阵一同上传至Hub,其中部分选项仅推送LoRA矩阵、不涉及模型本体。
· 关于如何获取Hugging Face token,请参阅此处:https://huggingface.co/settings/tokens。
关于本文微调的16bit精度模型成果,可访问此处(https://huggingface.co/krishanwalia30/DeepSeek-R1-Distill-Alpaca-FineTuned)查看。
总结
下面回顾本文讨论的各项要点:
· 常规大语言模型属于深度学习架构(例如Transformer)的精巧实现,由大量语言文本数据投喂训练而成。
· DeepSeek R1 Zero是一款以大规模强化学习(RL)方法训练而成的模型,无需借助有监督微调(SFT),且在推理方面表现出色。
· 所谓大模型微调,是指提供任务特定数据以结合目标用途进行响应结果定制的过程,旨在提高大模型准确性并增强响应结果与特定领域的结合度。
· 本指南中使用的主要Python库和框架为unsloth, torch, transformers以及 trl。此外,我们还讨论了大模型微调的算力需求。
· 我们为模型微调构建了相应数据集,并使用SFTTrainer进行训练。
· 我们还将LoRA适配器(矩阵)与预训练模型合并,并将成果推送至Hugging Face Hub。
最后,期待您关注并留下评论,这个年轻的个人栏目将持续为您带来IT领域的更多干货、资讯与趣闻。明天见!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)