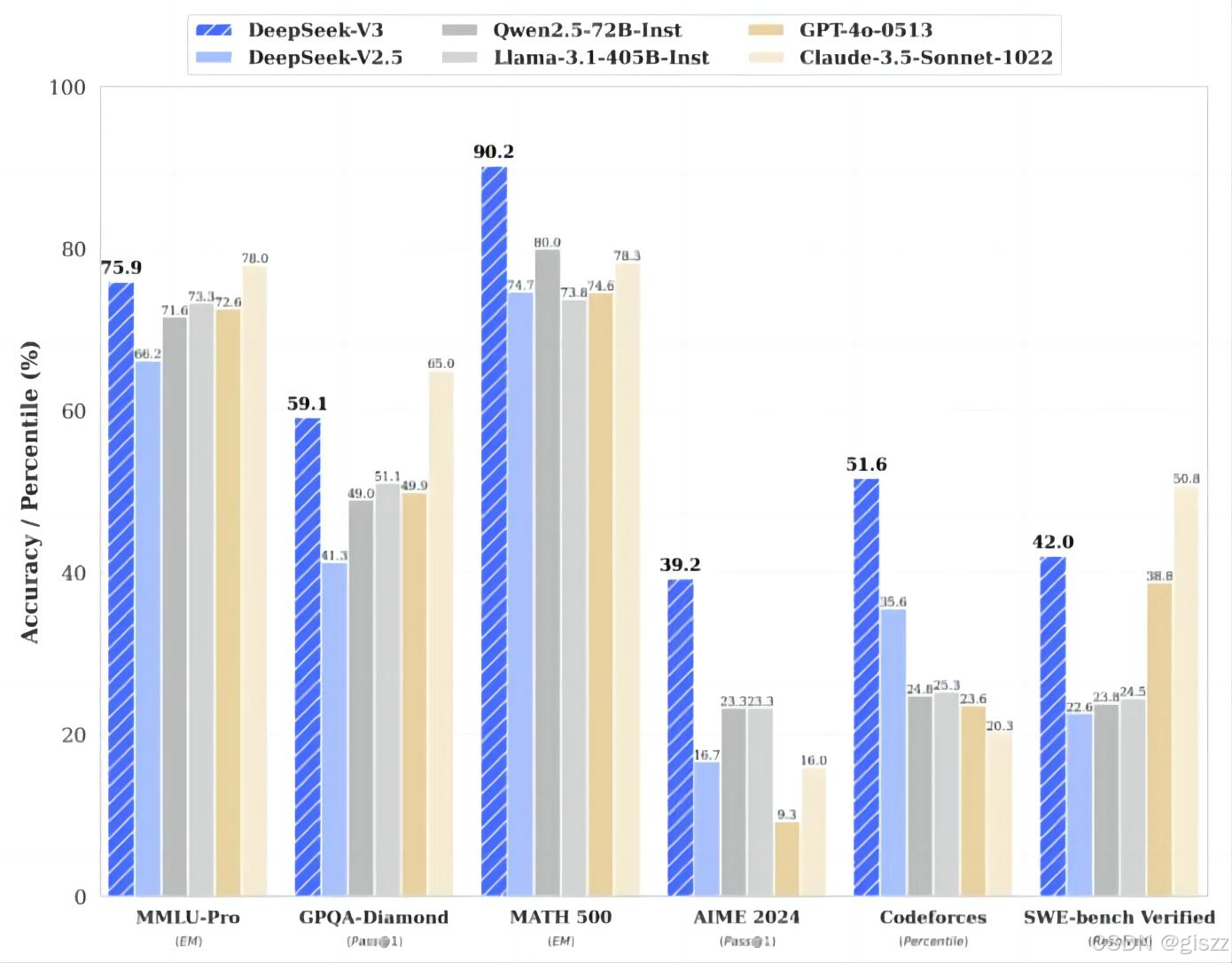
【AI】DeepSeek对比柱状图都看过,你看懂了吗?
通过以上分析,读者可清晰理解DeepSeek在技术路径、应用场景与商业策略上的定位,以及其与头部模型的竞合关系,为模型选型或技术投资提供参考依据。
·

以下是对DeepSeek与其他大模型对比图的逐项分析说明,旨在帮助读者理解图表传递的关键信息:
文章目录
一、对比维度分析
图表可能从以下核心维度展开对比(需结合实际图表内容调整):
1. 模型规模
- 参数数量:对比模型参数量级(如DeepSeek v2的16B稀疏化参数 vs GPT-4的1.8T稠密参数),反映模型复杂度与理论能力上限。
- 稀疏化技术:若DeepSeek采用动态稀疏激活(如MoE架构),则能以更少活跃参数实现接近稠密模型的性能,降低计算成本。
2. 训练数据
- 数据量级:对比训练语料规模(如DeepSeek使用4.5T tokens vs LLaMA-2的2T tokens),数据多样性影响模型泛化能力。
- 数据质量:是否引入多模态数据、专业领域数据(如代码、学术论文)或经过严格清洗过滤。
3. 计算效率
- 训练成本:单位参数的训练能耗(如DeepSeek每B参数消耗XX GPU小时 vs PaLM-2的XX小时),反映算法优化程度。
- 推理速度:生成token的延迟与吞吐量(如DeepSeek在同等硬件下比Claude快30%),决定实际部署可行性。
4. 性能表现
- 通用基准:MMLU(多任务语言理解)、GSM8K(数学推理)、HumanEval(代码生成)等标准化测试得分。
- 垂直领域:在法律、医疗、金融等专业场景的微调后表现,体现行业适配性。
5. 应用场景
- 商业化支持:是否提供API、定制化微调工具、企业级隐私保护(如DeepSeek针对B端客户优化)。
- 多模态能力:支持文本、图像、语音输入/输出的范围(如GPT-4V vs DeepSeek的纯文本专注)。
6. 开源与生态
- 开源程度:模型权重、训练代码、数据集的开放程度(如DeepSeek部分开源 vs LLaMA-2社区可商用)。
- 开发者工具:配套的SDK、文档、社区支持,影响技术采纳速度。
二、对比对象分析
图表可能涵盖以下主流大模型(需根据实际列出的模型调整):
| 模型名称 | 开发方 | 核心特点 | 对比点 |
|---|---|---|---|
| DeepSeek | 深度求索 | 稀疏化架构、高效推理、垂直领域优化 | 成本效益、行业解决方案、中文能力 |
| GPT-4 | OpenAI | 多模态、强泛化能力、最大规模商业化模型 | 综合性能、生态成熟度、API稳定性 |
| Claude 3 | Anthropic | 长上下文(200k tokens)、安全性强化 | 合规性、复杂指令理解、道德对齐 |
| PaLM-2 | 多语言支持、医学/科学领域预训练 | 跨语言迁移能力、学术场景表现 | |
| LLaMA-2 | Meta | 开源可商用、轻量级(7B-70B参数) | 开发者友好性、定制化潜力、社区贡献 |
| Ernie 4.0 | 百度 | 中文知识增强、搜索整合 | 本土化数据优势、搜索引擎联动 |
三、关键对比结论
-
DeepSeek的差异化优势
- 成本效率:通过稀疏化设计,在参数量减少的情况下保持性能,降低企业部署门槛。
- 垂直深耕:针对金融、法律等场景优化,提供行业专属微调方案,与GPT-4的通用性形成互补。
- 中文能力:依托本土数据积累,在成语理解、古文翻译等任务上表现优于国际模型。
-
竞争格局洞察
- 通用霸主:GPT-4仍领跑综合能力,但面临高昂使用成本与合规风险。
- 开源生态:LLaMA-2推动长尾创新,但企业需自行解决后续维护与合规问题。
- 场景化趋势:模型间竞争从“参数竞赛”转向“场景渗透”,DeepSeek等聚焦细分市场的模型更具落地价值。
-
用户选型建议
- 初创企业:优先考虑DeepSeek或LLaMA-2,平衡成本与定制需求。
- 全球化业务:GPT-4/Claude的多语言支持更可靠。
- 高合规要求:Claude的宪法AI设计更适合医疗、教育等敏感领域。
通过以上分析,读者可清晰理解DeepSeek在技术路径、应用场景与商业策略上的定位,以及其与头部模型的竞合关系,为模型选型或技术投资提供参考依据。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)