
DeepSeek R1 大模型信息汇总!本地部署与使用技巧大全
想掌握 DeepSeek R1 大模型的使用技巧吗?这篇文章帮你搞定。文中会为你提供超详细的本地部署教程,哪怕是技术小白也能轻松上手。此外,还分享了丰富的新手和高级使用技巧,无论是日常使用还是深度挖掘模型潜力,都能让你收获满满,快速成为 DeepSeek R1 使用高手。
在人工智能飞速发展的当下,DeepSeek R1 作为大模型领域的佼佼者,备受瞩目。它不仅在技术创新上独树一帜,还在实际应用中展现出强大的实力。
但对于众多 AI 爱好者和从业者来说,如何深入了解并高效运用 DeepSeek R1,仍存在诸多疑问。
本文将全方位剖析 DeepSeek R1,从其技术演进、核心优势、性能表现,到人人都能学会的本地部署实战,再到新手和高手都能受益的使用技巧,带你一站式解锁 DeepSeek R1 的无限可能,助力你在 AI 浪潮中抢占先机。
目录
一、核心突破:强化学习驱动的推理革命
1.1 技术演进路线


1.2 核心技术优势
| 技术特性 | 说明 |
|---|---|
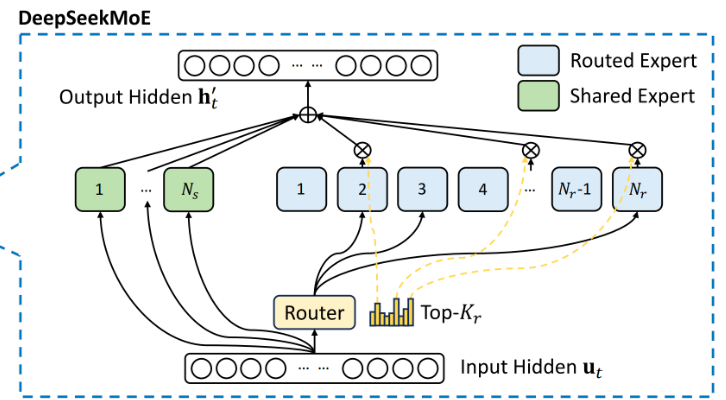
| MoE 架构 | 混合专家系统,动态分配计算资源 |
| FP8 量化训练 | 8位浮点精度训练,显存占用减少50% |
| 长链推理(CoT) | 支持多步逻辑推理,问题分解能力提升3倍 |
| 模型蒸馏 | 可将660B参数推理能力迁移到7B小模型 |
注:MoE(Mixture of Experts) 是一种通过动态路由机制将输入分配给不同专家模块的神经网络架构
二、性能表现:全面对标国际顶尖水平
2.1 基准测试对比
| 模型 | AIME 2024 | MATH-500 | MMLU | 推理延迟 |
|---|---|---|---|---|
| DeepSeek-R1-32B | 79.8% | 97.3% | 90.8% | 350ms |
| OpenAI-o1-mini | 78.5% | 96.8% | 91.2% | 420ms |
| DeepSeek-V3 | 68.7% | 89.4% | 85.6% | 280ms |

R1系列模型及其蒸馏版本的性能表现
DeepSeek此次发布了R1-Zero、R1以及多个蒸馏后的小模型,以下是它们的性能对比:
| 模型 | AIME 2024 (%) | MATH-500 (%) | LiveCodeBench (%) |
|---|---|---|---|
| DeepSeek R1-Zero | 71.0 | 89.7 | 55.2 |
| DeepSeek R1 | 79.8 | 97.3 | 57.2 |
| R1-Distill-Qwen-1.5B | 65.4 | 85.2 | 52.8 |
| R1-Distill-Qwen-7B | 68.9 | 88.6 | 54.3 |
| R1-Distill-Qwen-8B | 70.2 | 89.1 | 55.0 |
| R1-Distill-Qwen-14B | 72.6 | 90.5 | 56.1 |
| R1-Distill-Qwen-32B | 72.6 | 94.3 | 57.2 |
| R1-Distill-Llama-70B | 70.8 | 93.5 | 56.8 |
| Qwen2.5-32B (原始) | 55.5 | 72.6 | 45.0 |
| Llama3-70B (原始) | 58.3 | 75.1 | 47.5 |

2.2 开源模型矩阵
graph TD
A[DeepSeek-R1] --> B[Llama架构]
A --> C[Qwen架构]
B --> D[32B]
B --> E[70B]
C --> F[1.5B]
C --> G[7B]
C --> H[14B]
C --> I[32B]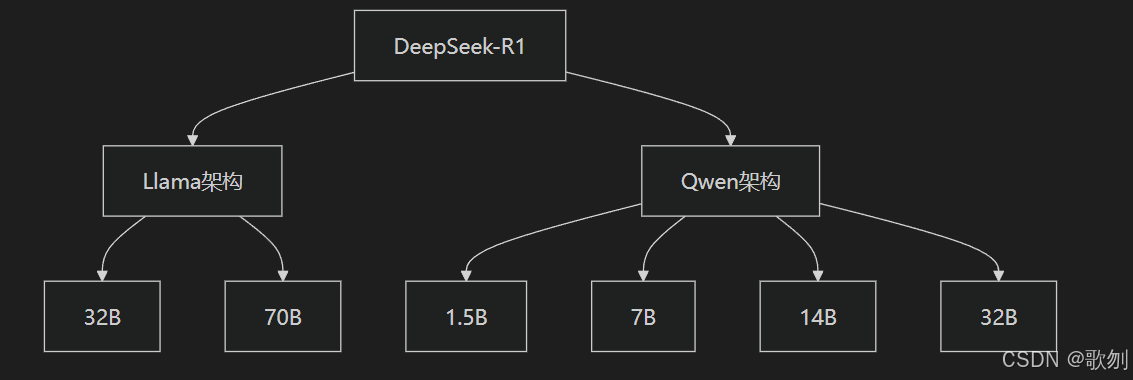
三、本地部署实战指南
3.1 硬件要求
| 模型版本 | CPU | 内存 | 硬盘 | 显卡 | 适用场景 | 预计费用 |
|---|---|---|---|---|---|---|
| DeepSeek-R1-1.5B | 最低4核 | 8GB+ | 256GB+(模型文件约1.5 - 2GB) | 非必需(纯CPU推理) | 本地测试,自己电脑上可以配合Ollama轻松跑起来 | 2000~5000 |
| DeepSeek-R1-7B | 8核+ | 16GB+ | 256GB+(模型文件约4 - 5GB) | 推荐8GB+显存(如RTX 3070/4060) | 本地开发和测试,可以处理一些中等复杂度的自然语言处理任务,比如文本摘要、翻译、轻量级多轮对话系统等 | 5000~10000 |
| DeepSeek-R1-8B | 8核+ | 16GB+ | 256GB+(模型文件约4 - 5GB) | 推荐8GB+显存(如RTX 3070/4060) | 适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等 | 5000~10000 |
| DeepSeek-R1-14B | 12核+ | 32GB+ | 256GB+ | 16GB+显存(如RTX 4090或V100) | 适合企业级复杂任务,比如长文本理解与生成 | 20000~30000 |
| DeepSeek-R1-32B | 16核+ | 64GB+ | 256GB+ | 24GB+显存(如A100 40GB或双卡RTX 3090) | 适合高精度专业领域任务,比如多模态任务预处理 | 40000~100000 |
| DeepSeek-R1-70B | 32核+ | 128GB+ | 256GB+ | 多卡并行(如2x A100 80GB或4x RTX 4090) | 适合科研机构或大型企业进行高复杂度生成任务 | 400000+ |
| DeepSeek-R1-671B | 64核+ | 512GB+ | 512GB+ | 多节点分布式训练(如8x A100/H100) | 适合超大规模AI研究或通用人工智能(AGI)探索 | 20000000+ |
- 模型权重资源需求
| Model Version | VRAM (GPU) | RAM (CPU) | Storage |
|---|---|---|---|
| 1.5B | 4GB+ | 8GB+ | 5GB |
| 7B | 12GB+ | 16GB+ | 10GB |
| 8B | 16GB+ | 32GB+ | 15GB |
| 14B | 24GB+ | 64GB+ | 30GB |
| 32B | 48GB+ | 128GB+ | 60GB |
| 70B | 80GB+ | 256GB+ | 120GB |
| 671B (MoE) | 4x A100 GPUs (320GB VRAM) | 512GB+ | 500GB+ |
生产部署时,实际显存占用 = 权重占用 + kv cache占用
3.2 gpt4all (适合入门用户)
网址:GPT4All
特征:无需命令行,支持多种轻量级模型,适合基础推理任务
gpt4all 部署步骤
第一步:安装 gpt4all
(这里以Windows系统为例)
- 进入gpt4all官网:https://gpt4all.io
- 选择适合的系统版本:Windows/macOS/Linux

- 按常规软件安装步骤完成安装即可

第二步:下载 DeepSeek 模型
- 在gpt4all里点击查找模型

- 浏览可用的DeepSeek模型,选择并下载

第三步:开始对话
- 模型下载完成后,在左侧进入对话界面
- 点击选择模型,从下拉列表选择已有的模型

- 和AI进行对话,确认能够成功就结束了

3.3 LMStudio 部署
Step 1:下载LMStudio
大家可以在LMStudio的官网下载对应的安装包,支持 Windows,Linux,MacOS。
📌Github Link: https://github.com/lmstudio-ai/lmstudio.js
LMStudio 官网: https://lmstudio.ai/
注:请下载0.3.9版本,本教程仅适用于该版本。
Step 2:更换模型下载源及模型下载路径
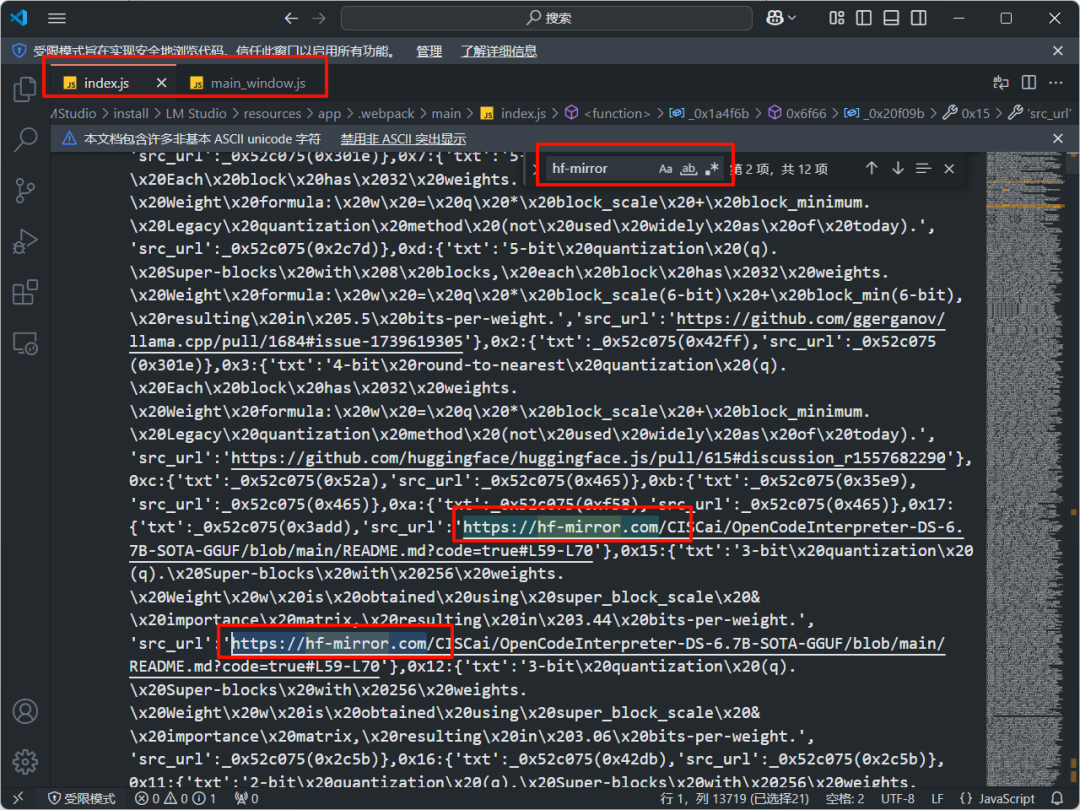
LMStudio 的默认模型下载地址为 Hugging Face 平台,但由于众所周知的原因,我们需要设置一下国内可访问的 HF 镜像源。一共需要修改两个文件。
Step 2.1 :修改模型下载源
- 首先打开 LMStudio 的下载安装位置,如果你忘记刚刚下载到哪里了,可以右键点击桌面上的 LMStudio 的图标,点击属性。点击“打开文件所在位置”即可。

- 一共需要修改两个文件,如下所示:
📌* LMStudio文件位置\resources\app.webpack\renderer\main_window.js
- LMStudio文件位置\resources\app.webpack\main\index.js
main_window.js 文件有点大,使用 windows 自带的文本编辑器打开可能会有点慢,建议使用 vscode 打开,全部替换。
https://huggingface.co/
https://hf-mirror.com/
将https://huggingface.co/全部替换为https://hf-mirror.com/,然后重新打开LMStudio即可。
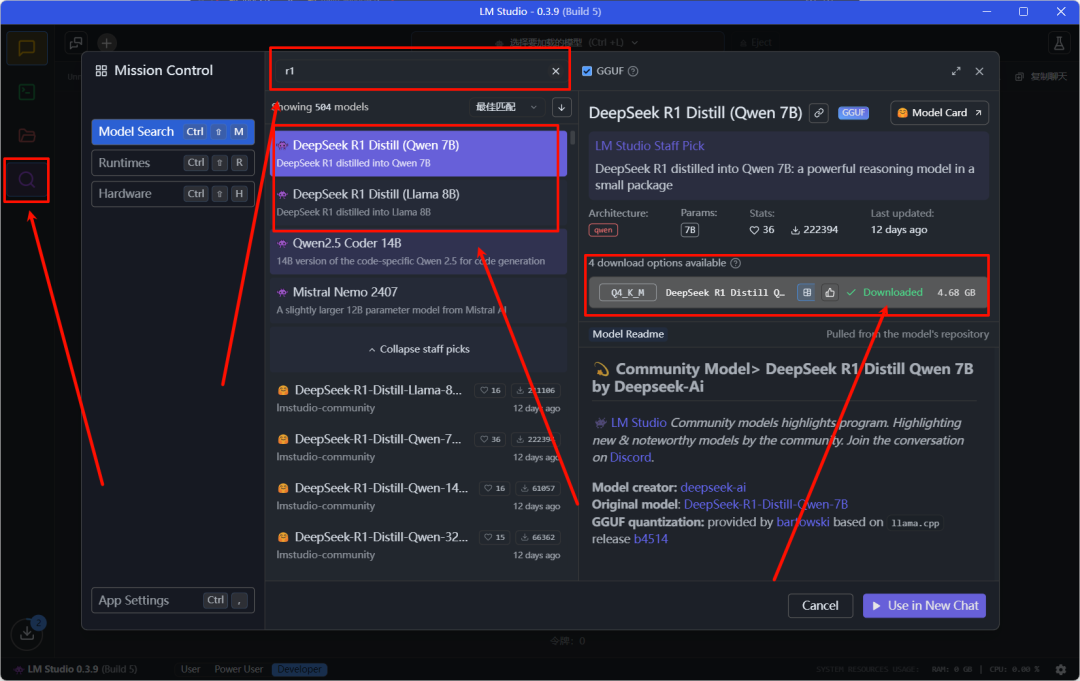
Step 2.2 :下载模型并进行对话
- 修改完成之后重新打开 LMStudio,首先点击左侧的放大镜按钮,在搜索框搜索r1,然后点击下面的搜索结果,进行下载即可。
注:如果此处没有搜索结果的话,请返回上一步检查是否替换完全,或是检查电脑网络问题。
- 然后就可以在 LMStudio 的主界面进行对话啦,这里我使用了 deepseek-r1-distill-qwen-7b 进行提问" Strawberries 有几个 r ?"经典问题哈,也是回答正确!
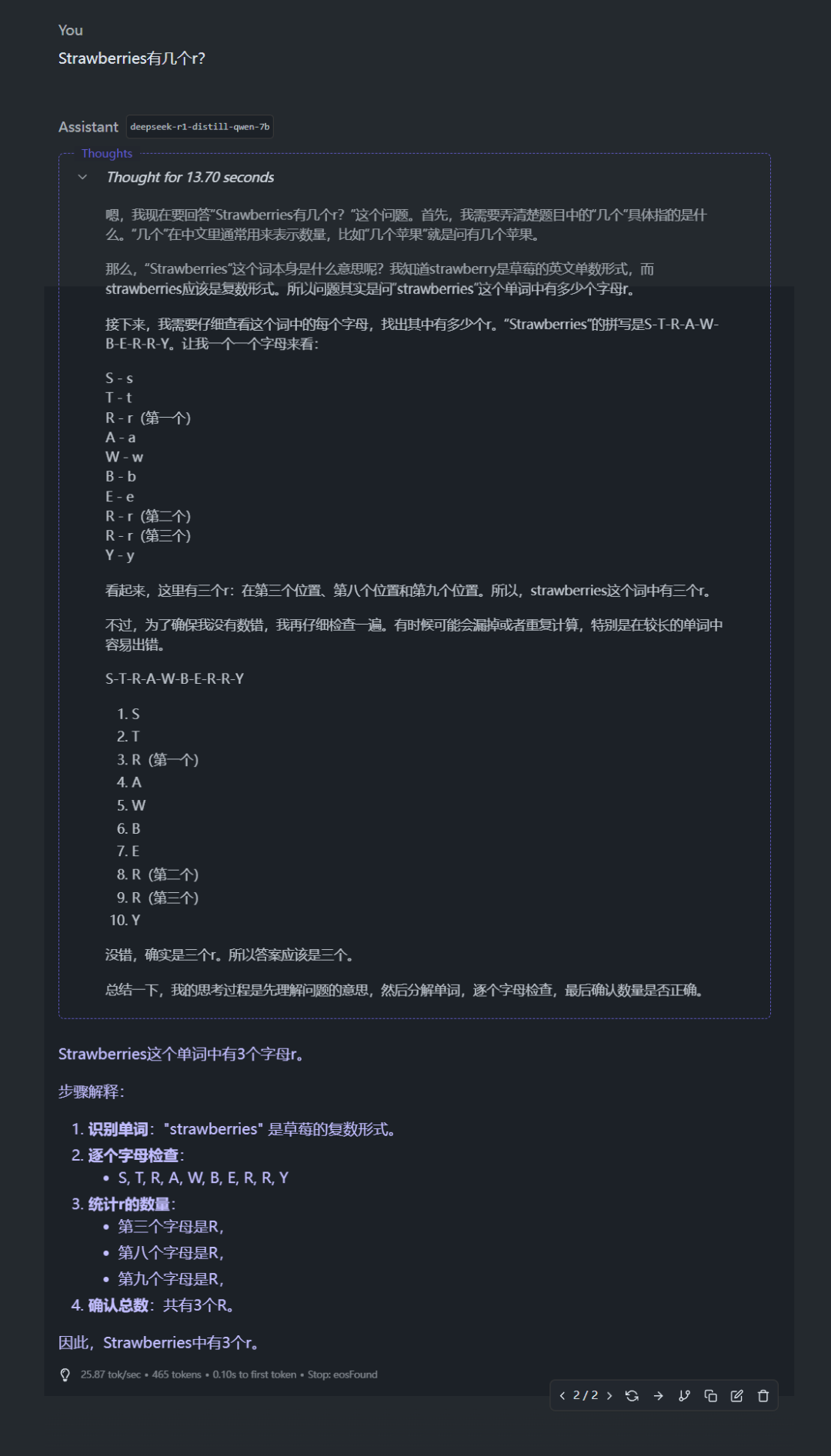
我的设备是笔记本的 4060,显存 8G。LMStudio 加载模型,当你的显存不够用时,会使用内存加载一部分参数,所以显存小也是可以本地部署一下的。

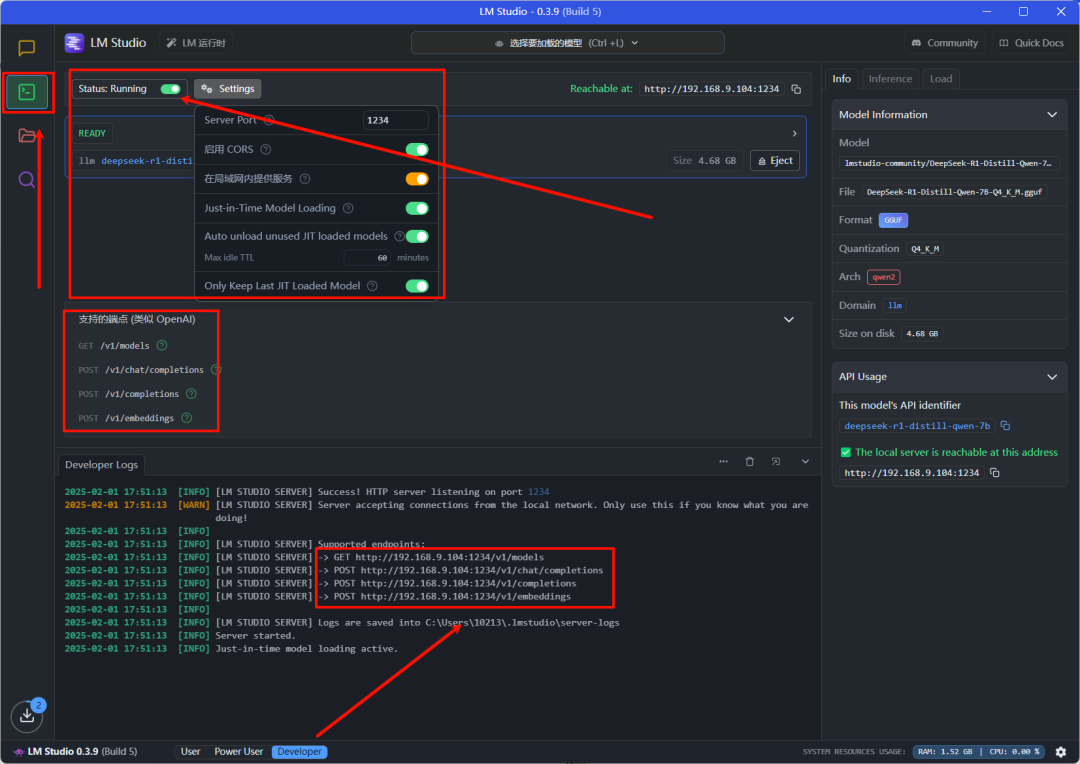
Step 2.3 :部署 r1 api
- 点击 LMStudio 主界面的第二个按钮,可以进入开发者界面,打开此处的 api 部署服务,并在 Setting 中选择全部打开,这样就算 windows 部署 LMStudio 之后也可以在wsl 中访问到服务。
3.4 Ollama 部署示例
-
Ollama:你可以使用 Ollama 在本地提供模型服务:Ollama 是一个用于在你的机器上本地运行开源 AI 模型的工具。你可以在 Ollama 下载页面 下载它。
接下来,你需要本地下载并运行 DeepSeek R1 模型。
Ollama 提供了不同大小的模型——基本上,模型越大,AI 越聪明,但需要更好的 GPU。以下是模型系列:
为了开始实验 DeepSeek-R1,建议从较小的模型开始,以熟悉设置并确保与你的硬件兼容。你可以通过打开终端并执行以下命令来启动这个过程:
ollama run deepseek-r1:8b -
-
1.5B 版本(最小):
ollama run deepseek-r1:1.5b
-
8B 版本:
ollama run deepseek-r1:8b
-
14B 版本:
ollama run deepseek-r1:14b
-
32B 版本:
ollama run deepseek-r1:32b
-
70B 版本(最大/最智能):
ollama run deepseek-r1:70b
-
3.5 vLLM 高性能部署
from vllm import LLM, SamplingParams
llm = LLM(model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B")
params = SamplingParams(temperature=0.8, max_tokens=500)
outputs = llm.generate(["如何提高客户满意度?"], params)
print(outputs[0].outputs[0].text)
3.6 ms-Swift 部署
CUDA_VISIBLE_DEVICES=0 swift infer \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--stream true \
--infer_backend pt \
--max_new_tokens 2048
四、线上使用途径
| 平台 | 地址 | 版本 | 收费 | 响应速度 | 多轮对话 | 国内直连 | 联网 | 特性 |
|---|---|---|---|---|---|---|---|---|
| 钉钉 | 钉钉,让进步发生!AI时代,实现团队协同方式和企业经营管理的持续进步 | V3,满血R1 | 免费 | 快 | 有 | 直连 | 有 | 需要在APP里创建一个DeepSeek AI助手 |
| Openrouter | R1 (free) - API, Providers, Stats | OpenRouter | V3,满血R1 | 部分免费 | 中 | 有 | 直连 | 有 | 离线模式免费,但每分钟最多20次对话,每天最多200次。联网模式有额度限制。 |
| 扣子 | 扣子 | V3,满血R1 | 部分免费 | 中 | 有 | 直连 | 无 | 免费用户每天50次对话,不展示思维连。需要在网页中自行创建智能体 |
| 天工AI | 天工AI - 聊天写作对话的全能AI助手,搜索更深度,阅读更多彩 | 满血R1 | 免费 | 慢 | 有 | 直连 | 有 | |
| Monica AI | https://monica.im/home/chat/Monica/monica | V3,满血R1 | 部分免费 | 快 | 有 | 需要魔法 | 有 | 每天免费对话40次 |
| deepinfra | deepseek-ai/DeepSeek-R1 - Demo - DeepInfra | 满血R1 | 免费 | 中 | 有 | 直连 | 无 | 审核较严 |
| Flowith | https://flowith.io | V3,满血R1 | 免费 | 中 | 有 | 需要魔法 | 有 | 界面与传统聊天框不一样,可能会不太习惯 |
| Hugging Face | https://huggingface.co/deepseek-ai/DeepSeek-R1 | V3,满血R1 | 免费 | 快 | 有 | 需要魔法 | 无 | 审核较严,V3 和 R1 并不是在同一个页面的,需要重新搜索模型 |
| Perplexity | https://www.perplexity.ai/ | 满血R1 | 部分免费 | 快 | 有 | 需要魔法 | 有 | AI搜索工具,每天5次 R1 的对话机会,主要是搜索 |
| Cursor | Cursor - The AI Code Editor | 满血R1 | 收费 | 中 | 有 | 需要魔法 | 无 | |
| Merlin | Merlin AI | 让人工智能一键完成研究、写作和总结 | 满血R1 | 部分免费 | 快 | 有 | 直连 | 有 | 非联网每天5次对话机会,联网模式每天2次 |
| 秘塔搜索 | 秘塔AI搜索 | 满血R1 | 免费 | 中 | 无 | 直连 | 有 | |
| 硅基流动&华为云 | SiliconFlow, Accelerate AGI to Benefit Humanity | 满血R1 | 免费 | 慢 | 无 | 直连 | 无 | 认证,卡死了,不回答了 |
| 国家超算互联网平台 | 超算互联网 | 蒸馏R1 | 免费 | 中 | 无 | 直连 | 无 | |
| 无问芯穹 | https://cloud.infini-ai.com/genstudio | V3,满血R1 | 免费 | 中 | 有 | 直连 | 无 | 正常情况下响应速度快,偶尔会卡死不动 |
| Groq | Groq is Fast AI Inference | 蒸馏R1 | 免费 | 快 | 有 | 需要魔法 | 无 | |
| Cerebras | https://cerebras.ai | 蒸馏R1 | 免费 | 快 | 有 | 需要魔法 | 无 | 响应非常快 |
| 百度智能云,千帆 | 百度智能云千帆大模型平台 | 满血R1 | 免费 | 慢 | 有 | 直连 | 无 | 身份认证、路径复杂 |
| 腾讯云-大模型知识引擎 | 大模型知识引擎 | 满血R1 | 免费 | 快 | 有 | 直连 | 有 | 审核严,有时只会输出思维链,不进行实际总结回答 |
| 天翼云 | 一站式智算服务平台 | 满血R1 | 免费 | 慢 | 有 | 直连 | 无 | 需要身份认证,使用路径复杂 |
| 火山方舟 | 火山方舟-火山引擎 | 满血R1 | 部分免费 | 快 | 有 | 直连 | 无 | 身份认证,免费50万token |
| 华为云 | https://console.huaweicloud.com/modelarts/ | V3,满血R1 | 部分免费 | 中 | 有 | 直连 | 无 | 身份认证,免费200万token,回答不用<think> 和 <\think>包起来 |
| 商汤大装置 | https://console.sensecore.cn/aistudio/experience/conversation?model=DeepSeek-R1 | V3,满血R1 | 免费 | 快 | 有 | 直连 | 无 | |
| Chatbox | Chatbox | V3,满血R1 | 收费 | 快 | 有 | 直连 | 有 | 3.99刀每月,可以使用联网的满血R1 |
| POE | https://poe.com | V3,满血R1 | 收费 | 快 | 有 | 需要魔法 | 无 | |
| AskManyAI | AskManyAI | V3,满血R1 | 免费 | 快 | 有 | 直连 | 有 |
4.1、完整版 R1
官方渠道
DeepSeek
网址:DeepSeek.com及移动应用(iOS/Android)
特征:完整版 R1 模型,支持深度搜索,但目前因流量大常遇到服务器繁忙问题
第三方平台
硅基流动&华为云
网址:SiliconFlow, Accelerate AGI to Benefit Humanity
特征:满血版 R1 模型,支持 API 调用和直接对话,但聊天记录不保存
Monica AI
网址:https://monica.im/home/chat/Monica/monica
特征:满血版 R1,可以联网搜索,免费使用
秘塔搜索
网址:秘塔AI搜索
特征:满血版 R1 模型,免费使用,自带搜索功能,但不支持多轮对话
Openroutor
特征:满血版 R1,可以联网搜索,免费使用,响应速度偏慢
Cursor
网址:Cursor - The AI Code Editor
特征:满血版 R1 模型,可用于聊天,但需要会员资格
Hugging Face
网址:https://huggingface.co/deepseek-ai/DeepSeek-R1
特征:满血版 R1,免费使用,但是不能联网,在模型页面的右侧,有一个对话框
Perplexity
特征:AI搜索引擎,将资料检索与R1思考能力完美融合。免费版每天限5次R1使用
Merlin
网址:Merlin AI | 让人工智能一键完成研究、写作和总结
特征:满血版 R1,可以联网搜索。但是离线模式每天只有 5 次对话机会,联网模式每天 2 次对话,想要继续聊天需要会员
4.2、蒸馏版 R1
国家超算互联网平台
网址:超算互联网
特征:免费使用,蒸馏版非完整版 R1
无问芯穹
网址:https://cloud.infini-ai.com/genstudio
特征:支持文本和视觉生成的企业级大模型服务平台,目前提供蒸馏版R1
Groq
特征:基于 Llama 70B 蒸馏版,免费快速,但中文能力较弱
Cerebras
特征:免费,响应速度很快,但是是 70B 的蒸馏模型
4.3、API调⽤
官方:首次调用 API | DeepSeek API Docs
英伟达(赠送算⼒): Try NVIDIA NIM APIs
Azure(需visa绑定): Azure AI Foundry
AWS (需visa绑定): https://aws.amazon.com/cn/blogs/aws/DeepSeek-r1-models-now-available-on-aws
⼀键云服务部署:
阿⾥云: 阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
华为云: Models
腾讯云:
百度云: https://console.bce.baidu.com/qianfan/overview
| 平台名称 | 地址 | 版本 | 输入(1M tokens) | 输出(1M tokens) | 直连 | 优惠情况 |
|---|---|---|---|---|---|---|
| OpenRouter | DeepSeek: R1 (free) – Run with an API | OpenRouter | 满血R1 | ¥0 | ¥0 | 直连 | 免费API |
| 天翼云 | 一站式智算服务平台 | 满血R1 | 计费说明:计费说明-一站式智算服务平台 - 天翼云 | 直连 | 两周 2500万Tokens免费使用 | |
| 百度智能云,千帆 | 百度智能云千帆大模型平台 | 满血R1 | ¥2 | ¥8 | 直连 | 2月18日结束前免费 |
| 英伟达 | deepseek-r1 Model by Deepseek-ai | NVIDIA NIM | 满血R1 | 免费1000次 | 免费1000次 | 直连 | 免费1000次调用,偶尔会不调用思考部分 |
| 火山方舟 | 火山方舟-火山引擎 | 满血R1 | ¥4 | ¥16 | 直连 | 免费50万token,2月18日结束前半价优惠 |
| 华为云 | https://console.huaweicloud.com/modelarts/ | 满血R1 | 计费说明:ModelArts计费模式概述_AI开发平台ModelArts_华为云 | 直连 | 免费送200万tokens,包年/包月 的计费方式 | |
| 阿里云百炼 | 阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台 | 满血R1 | ¥4 | ¥16 | 直连 | 送 100 万 tokens |
| 腾讯云 | 登录 - 腾讯云 | 满血R1 | ¥4 | ¥16 | 直连 | 2月25日结束前免费 |
| 微软 Azure | Azure AI Foundry | 满血R1 | 暂时免费 | 暂时免费 | 直连 | 需要VISA信用卡 |
| Together ai | https://api.together.xyz/ | 满血R1 | $7 | $7 | 直连 | 免费1刀 需要vis 信用卡 |
| 硅基流动 | Models | 满血R1 | ¥4 | ¥16 | 直连 | 送14块,但是很卡 |
五、新手使用技巧

官网提示库
代码改写
对代码进行修改,来实现纠错、注释、调优等。
USER
下面这段的代码的效率很低,且没有处理边界情况。请先解释这段代码的问题与解决方法,然后进行优化:
def fib(n):
if n <= 2:
return n
return fib(n-1) + fib(n-2)
代码解释
对代码进行解释,来帮助理解代码内容。
USER
请解释下面这段代码的逻辑,并说明完成了什么功能:
// weight数组的大小 就是物品个数
for(int i = 1; i < weight.size(); i++) { // 遍历物品
for(int j = 0; j <= bagweight; j++) { // 遍历背包容量
if (j < weight[i]) dp[i][j] = dp[i - 1][j];
else dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
代码生成
让模型生成一段完成特定功能的代码。
USER
请帮我用 HTML 生成一个五子棋游戏,所有代码都保存在一个 HTML 中。
内容分类
对文本内容进行分析,并对齐进行自动归类
SYSTEM
#### 定位
- 智能助手名称 :新闻分类专家
- 主要任务 :对输入的新闻文本进行自动分类,识别其所属的新闻种类。
#### 能力
- 文本分析 :能够准确分析新闻文本的内容和结构。
- 分类识别 :根据分析结果,将新闻文本分类到预定义的种类中。
#### 知识储备
- 新闻种类 :
- 政治
- 经济
- 科技
- 娱乐
- 体育
- 教育
- 健康
- 国际
- 国内
- 社会
#### 使用说明
- 输入 :一段新闻文本。
- 输出 :只输出新闻文本所属的种类,不需要额外解释。
USER
美国太空探索技术公司(SpaceX)的猎鹰9号运载火箭(Falcon 9)在经历美国联邦航空管理局(Federal Aviation Administration,FAA)短暂叫停发射后,于当地时间8月31日凌晨重启了发射任务。
结构化输出
将内容转化为 Json,来方便后续程序处理
SYSTEM
用户将提供给你一段新闻内容,请你分析新闻内容,并提取其中的关键信息,以 JSON 的形式输出,输出的 JSON 需遵守以下的格式:
{
"entiry": <新闻实体>,
"time": <新闻时间,格式为 YYYY-mm-dd HH:MM:SS,没有请填 null>,
"summary": <新闻内容总结>
}
USER
8月31日,一枚猎鹰9号运载火箭于美国东部时间凌晨3时43分从美国佛罗里达州卡纳维拉尔角发射升空,将21颗星链卫星(Starlink)送入轨道。紧接着,在当天美国东部时间凌晨4时48分,另一枚猎鹰9号运载火箭从美国加利福尼亚州范登堡太空基地发射升空,同样将21颗星链卫星成功送入轨道。两次发射间隔65分钟创猎鹰9号运载火箭最短发射间隔纪录。
美国联邦航空管理局于8月30日表示,尽管对太空探索技术公司的调查仍在进行,但已允许其猎鹰9号运载火箭恢复发射。目前,双方并未透露8月28日助推器着陆失败事故的详细信息。尽管发射已恢复,但原计划进行五天太空活动的“北极星黎明”(Polaris Dawn)任务却被推迟。美国太空探索技术公司为该任务正在积极筹备,等待美国联邦航空管理局的最终批准后尽快进行发射。
角色扮演(自定义人设)
自定义人设,来与用户进行角色扮演。
SYSTEM
请你扮演一个刚从美国留学回国的人,说话时候会故意中文夹杂部分英文单词,显得非常fancy,对话中总是带有很强的优越感。
USER
美国的饮食还习惯么。
角色扮演(情景续写)
提供一个场景,让模型模拟该场景下的任务对话
USER
假设诸葛亮死后在地府遇到了刘备,请模拟两个人展开一段对话。
使用技巧
讲清楚目标
核心思想:不需要给模型详细的步骤,只需定义清晰的目标。
🔴 错误示例:
请按以下步骤操作,帮我写一个用于发布到社交媒体的帖子:
步骤一: 首先,在帖子的开头写一句吸引人的疑问句,例如"今天你喝咖啡了吗?"
步骤二: 接着,在第二句话中简单介绍一下咖啡。
步骤三: 第三句话,明确我们帖子的目的是宣传咖啡品鉴活动。
步骤四: 然后,用一句话介绍咖啡品鉴活动的 时间。
步骤五: 再用一句话介绍咖啡品鉴活动的地点。
步骤六: 在帖子结尾,号召大家来参加活动,可以使用 "快来参加吧!" 这样的语句。
步骤七: 最后,加上 #咖啡品鉴 #三里屯 两个话题标签。
请按照以上七个步骤,写一个社交媒体帖子。
步骤太多,限制 AI 自由发挥,结果僵硬
🟢 正确姿势:
请撰写一条微博帖子,目的是宣传我们本周六在三里屯举办的咖啡品鉴活动。
目标明确,AI 知道格式 (微博帖子)、主题、目的
提供背景信息
核心思想:避免让模型猜测,明确任务背景以获得更精准的解决方案。
🔴 错误示例:
总结下这篇文章
哪篇文章?关于什么的?有什么特殊要求吗?模型一头雾水
🟢 正确姿势:
请总结一下这篇关于气候变化对北极熊栖息地影响的科学研究文章,重点概括文章中提到的核心论点和数据支撑。(请注意,文章的目标读者是具有环境科学背景的本科生)
明确了文章主题、类型,以及总结的重点和目标读者,模型能更好地理解任务
找到元问题
核心思想:让模型反向提问,帮助深入思考和规划。
🔴 错误示例:
帮我解决客户满意度低的问题
问题太大太空泛,没有深入分析原因,可能找不对方向
🟢 正确姿势:
我的目标是提升公司客户满意度,但目前不太清楚具体从哪些方面入手。请你扮演一位资深的客户体验顾问,针对"如何有效提升客户满意度"这个问题,先向我提出 5 个关键性的问题,引导我深入思考, 最终找到提升客户满意度的核心方向。
引导模型反问,帮助自己找到问题根源,比直接让模型解决问题更有效
要求风格
核心思想:指定风格或对标人物,让输出更具个性。
🔴 错误示例:
写一首诗
模型自由发挥,可能写出的诗没有特色,不符合你的喜好
🟢 正确姿势:
请用李白的风格,创作一首关于秋天的五言绝句,要描写出秋天萧瑟但又充满生机的意境。
指定了诗人风格、诗歌体裁、主题和意境,模型能写出更具风格化的诗歌
规定知识状态
核心思想:让模型根据受众的知识水平调整表达方式。
🔴 错误示例:
解释下区块链技术
模型可能会用专业术语解释,如果听众是小白就听不懂
🟢 正确姿势:
请用最通俗易懂的语言,例如使用生活中的例子,向一位完全不懂技术的小学五年级学生,解释一下什么是区块链技术,字数控制在 200 字以内。
明确了受众是"小学五年级学生",模型会用更浅显易懂的语言和例子解释
转换视角
核心思想:借助名人思维或不同角色的视角解决问题。
🔴 错误示例:
如何解决城市交通拥堵问题?
问题很大,模型可能找不到创新性的解决方案
🟢 正确姿势:
假设你是埃隆·马斯克,请运用第一性原理思维,从彻底颠覆现有交通模式的角度出发,为解决北京目前的交通拥堵问题,提出 3 个前瞻性、且可规模化的创新解决方案,并简要分析每个方案的潜在风险和技术挑战。
让模型扮演埃隆·马斯克,并运用其标志性的"第一性原理思维",更容易获得突破性、颠覆性的解决方案
批判性思维
核心思想:利用模型挑毛病或辩证思考,评估方案和决策。
🔴 错误示例:
评估一下这个网站改版方案
评估过于宽泛,模型可能不知道从哪些方面评估
🟢 正确姿势:
请你扮演一位资深的毒舌网站设计师,指出这份网站改版方案的潜在风险和不足之处,并针对每个方面给出具体的改进建议,可以犀利一点
指定模型毒舌角色,批判的角度给出建议让你更全面
开放讨论
核心思想:提出开放性问题,探索深刻和本质的思考。
🔴 错误示例:
如何处理好亲子关系和夫妻关系
对于宽泛问题直接索取方案,模型只会给出教科书式的答案,缺乏深度
🟢 正确姿势:
我想跟你讨论一下亲子关系和夫妻关系的本质,你有什么想法吗
开放性问题,引导模型进行更深入、更发散的思考,探讨更深层次的问题
六、高级使用技巧

5.1 提示词设计原则
| 类型 | 劣质示例 | 优质示例 |
|---|---|---|
| 目标定义 | "写个产品介绍" | "撰写面向Z世代的智能手机小红书文案" |
| 背景限定 | "解释区块链" | "向小学生用比喻解释区块链" |
| 风格控制 | "写首诗" | "仿李白风格创作中秋主题五言绝句" |
| 输出格式 | "总结会议" | "用Markdown表格整理会议要点" |
5.2 进阶玩法
自动生成图文
功能:将新闻资讯转化为小红书风格图文。
帮我整理最近网上最火的十条关于AI的新闻,然后用HTML把这些新闻做成一个日报,用适合发小红书图文的版式来做。
PS自动处理图片
功能:通过脚本实现自动调色、加水印等操作。
帮我写一个PS2021的脚本,把图片调整成小清新色调,并且在中间加上一个"秋芝2046"的水印
专业图表生成
功能:支持LaTeX、Mermaid、Excel等多种图表格式。
用mermaid帮我写一个能全面梳理自动驾驶系统中AI决策机制的图表
AI创意辅助
功能:辅助生成镜头描述、视频分镜等创意内容。
假设你是一位经验丰富、极具想象力的AI视频创作者。现在我想用5帧法生成一些镜头,每个镜头长5秒。5帧法就是说,每个镜头的提示词里描述了5个关键画面,这样就能引导AI生成出变化丰富、具有动感的镜头,并且在开头先规定氛围,在结尾下充一些对镜头、画质的描述来提升画面质感。我想生成的镜头风格是科幻、悬疑、压迫感,请你根据这些元素给我生成10组各不相同的提示词
5.3 场景启发思路
AI 学术论文助手
选题
找研究方向
我是一名环境科学专业的本科生,请推荐5个适合毕业论文的城市公园绿地规划相关课题,要求:
有一定的新意,但不需要非常超前
主要用数据分析和模型来研究,不需要做实地建造
提供一些找相关资料的关键词
优化题目
优化以下论文标题:城市公园绿地对改善城市热岛效应的影响研究
文献速览
- 上传PDF文献并输入:
请用表格对比这些文献的研究方法,从 '亮点/不足/可以参考的地方' 三个方面总结
论文写作
方法描述
请把这段实验步骤用更学术化的语言改写:『我们先用ArcGIS软件处理了卫星图片,然后用统计软件算了绿地面积』
数据可视化
- 提供Excel数据后输入:
「请推荐三种适合展示 空气质量指数变化 的图表,并说说为什么这样选」
论文降重
- 对需要修改的段落使用指令:
「润色一下 这段话,意思不变,但是换一种更学术的说法」
格式调整
请帮我检查一下论文格式对不对,要求如下:
三级标题 用 1.1.1 这种格式
参考文献 里 [1] 这条要加上 DOI 号
所有图片都要有 居中的“图 1-” 编号
行距 设成 1.5 倍
文本辅助
论文查重和修改
- 查重预检指令:
分析下面这段文字:[粘贴文本]
预测一下查重率大概多少,哪些地方 可能查重率高 (用红色标出来)
看看有没有 可能漏掉引用 的地方(推荐 3 篇相关的文献)
给一些 修改建议 (比如换个词、改一下句子结构)
智能期刊匹配
- 匹配指令:
我的研究是关于:
领域:用人工智能搞环境监测
创新点:建立了一个 动态的城市绿地健康地图
数据量:用了 10万+ 城市公园的监测数据
推荐:
3 个可以试试的期刊 (影响因子 3-5 分左右)
2 个比较稳的期刊 (容易被接受,录用率 > 40%)
1 个新的开源期刊 (不用交版面费)
要求:
附上 最新的影响因子 和 审稿周期
告诉我 期刊对格式有什么特别要求 (参考文献、图表等等)
电脑配置指导
核心目标:
根据您的预算和需求,快速获取最佳电脑配置方案和市场价格信息。
AI 方案生成与优化
-
步骤 1:输入整合后的需求描述,让 AI 生成初步配置方案。
- 提示词示例:
你是一位装机专家,请根据以下需求推荐一套电脑配置清单,并给出市场最新价格:用途:3A 游戏、日常办公、轻度视频剪辑;预算:8000-10000 元人民币;偏好:英特尔 CPU, NVIDIA 显卡;硬盘:1TB SSD。
-
步骤 2:评估 AI 方案,如有不满意的地方,进一步优化提示词进行调整。例如,对价格不满意,可以要求降低预算;对某些硬件配置不满意,可以提出更具体的要求。
- 提示词示例:
这个配置方案价格偏高,能否在 9000 元以内提供一套配置方案?显卡方面,我更倾向于 RTX 4060 Ti,请调整配置清单。
-
步骤 3:可以要求 AI 提供不同价位或侧重点的多个方案,以便对比选择。
- 提示词示例:
请再提供一个 8000 元左右的配置方案,以及一个 12000 元左右配置更高性能的方案,方便我对比选择。
市场价格核实与购买建议
-
步骤 1:针对 AI 提供的配置清单,要求 AI 查询市场最新价格,并告知购买渠道建议 (例如:电商平台)。
- 提示词示例:
请查询以上配置清单中各硬件的市场最新价格,并推荐性价比较高的购买渠道。
-
步骤 2:可以进一步询问装机注意事项、售后服务等相关问题。
- 提示词示例:
装机时需要注意哪些问题?各个硬件的售后服务政策如何?
面试准备
在你把面试真题文档发给 AI 之后:
- 问题分类 + 考察重点分析
请分析这份文档中的面试真题,将它们按照问题类型(例如:行为问题、技术问题、情景题、开放性问题等)进行分类。并且,针对每一类问题,总结面试官通常想要考察的应聘者哪些方面的能力、素质或特点?
你也可以在做出回答之后和AI说:
分析这个示例回答的优点,以及可以进一步提升的地方。请从面试官的角度,给出让回答更具吸引力、更有效展现我的能力和优势的具体建议。
行业分析
为[行业/市场]进行全面的市场分析,重点关注关键趋势、增长驱动因素、竞争格局以及潜在机会或威胁。
合同编写
你是一位资深的法律专家,专精于中国法律和合同起草。请根据中国法律给我编写一份【】合作合同,包含合同标题、合作主体、合作目标、合作内容、权利义务、违约责任、争议解决等核心条款
直播话术
你是一位经验丰富的直播带货脚本策划师和金牌销售。请你帮我为 [直播平台名称,例如:抖音/淘宝直播/快手] 平台上的 [产品类型,例如:美妆产品/食品/服装] 直播带货活动,撰写一份具有吸引力、能够有效促进销售的直播话术脚本。我的目标受众是[XXX]。
六、生态发展与未来展望
6.1 开源模型矩阵
- 基础架构:Llama/Qwen 双架构支持
- 参数规模:1.5B/7B/14B/32B/70B 全系列
- 应用版本:对话版/代码版/数学特别版
6.2 云服务平台
| 平台 | 特性 | 计费方式 |
|---|---|---|
| 华为昇腾 | 国产硬件适配 | 按小时计费 |
| 硅基流动 | API生态完善 | 按token计费 |
| 无问芯穹 | 企业级服务支持 | 定制化套餐 |
6.3 发展趋势预测
- 多模态融合:预计2025年Q2推出视觉推理版本
- 端侧部署:1B以下超小规模模型研发中
- 行业解决方案:金融/医疗/制造垂直领域专用模型
6.4 模型资源下载
国内下载模型建议去魔搭社区上找,huggingFace 国内访问和下载不稳定
- 如果是本机(Win或者Mac),则找的是 deepseek gguf 格式的模型
下载方法:modelscope 魔搭社区模型下载
DeepSeek-R1 Models
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 314B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 314B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Distill Models
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
附录:扩展资源
- 官方技术白皮书
- Hugging Face模型库
- 华为昇腾部署指南
- ModelScope-魔搭社区
- deepseek-部署Docker镜像下载
- Linux 快速部署DeepSeek-R1 蒸馏系列模型
- DeepSeek R1 蒸馏系列模型测评
- 探秘 DeepSeek-R1:推理大语言模型的深度解析与启示
- DeepSeek R1 “顿悟时刻”(Aha Moment) 的重现与探索
- TinyZero 是 DeepSeek R1 Zero 在倒计时和乘法任务中的复制品
- Deepseek R1 Zero成功复现, 三阶段RL,Response长度稳定涨幅,涌现语言混杂
- DeepSeek R1 Zero中文复现教程
- 使用DeepSeek-R1蒸馏训练自己的本地小模型(Qwen2.5-0.5B)
本文部分数据引自深度求索公司官方技术文档及第三方评测报告,最新信息请以官方渠道为准。
官方公告
- 目前,DeepSeek 仅在以下社交媒体平台拥有唯一官方账号:
- 微信公众号:DeepSeek
- 小红书:@DeepSeek(deepseek_ai)
- X (Twitter) : DeepSeek (@deepseek_ai)


除以上官方账号外,其他任何以 DeepSeek 或相关负责人名义对外发布公司相关信息的,均为仿冒账号。
如未来 DeepSeek 在其他平台开设新的官方账号,将通过其他已有官方账号进行公告。
与 DeepSeek 有关的一切信息以官方账号发布为准,任何非官方账号、个人账号发布的信息均不代表 DeepSeek 观点,请大家注意甄别。
- 获取 DeepSeek 模型服务,请认准官方网站,通过正规渠道下载官方正版 App:
- 官方网站:www.deepseek.com
- 官方 App: DeepSeek(DeepSeek-AI 人工智能助手)开发者:杭州深度求索人工智能基础技术研究有限公司
PS:DeepSeek 官方网页端与官方正版 App 内不包含任何广告和付费项目。
- 目前除 DeepSeek 官方用户交流微信群外,我们从未在国内其他平台设立任何群组,一切声称与 DeepSeek 官方群组有关的收费行为均系假冒,请大家仔细辨别,避免财产损失。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 38
38 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)