
分享 | 基于RK3588开发板部署测试DeepSeek模型
最近,AI界新星DeepSeek(中文名:深度求索)迅速崛起,凭借低成本、高性能的AI模型火爆全网。其核心是一个强大的语言模型,能够理解自然语言并生成高质量文本,此外DeepSeek免费向全球开发者开放,加速了AI技术普及。RK3588作为一款高性能AI芯片,采用了8nm LP 制程,搭载八核处理器,四核GPU以及6TOPS算力的NPU,依靠强大的性能和低功耗特性,非常适合边缘计算场景。

DeepSeek来袭!
最近,AI界新星DeepSeek(中文名:深度求索)迅速崛起,凭借低成本、高性能的AI模型火爆全网。其核心是一个强大的语言模型,能够理解自然语言并生成高质量文本,此外DeepSeek免费向全球开发者开放,加速了AI技术普及。

RK3588性能优势
RK3588作为一款高性能AI芯片,采用了8nm LP 制程,搭载八核处理器,四核GPU以及6TOPS算力的NPU,依靠强大的性能和低功耗特性,非常适合边缘计算场景。

能否在RK3588部署Deepseek呢
在RK3588上部署Deepseek有两种方法,分别是使用Ollama工具部署和使用瑞芯微官方的 RKLLM量化部署。下面分别对这两种部署方式进行介绍。
01-使用Ollama工具部署
Ollama 是一个开源的大模型服务工具,可以支持最新的deepseek模型,以及Llama 3,Phi 3,Mistral,Gemma 和其他多种模型,在安装Ollama工具之后,使用以下命令即可一键部署15亿参数的deepseek-r1模型,运行之后如下图所示:
ollama run deepseek-r1:1.5b
接下来就可以向该模型进行提问了,如下图所示:
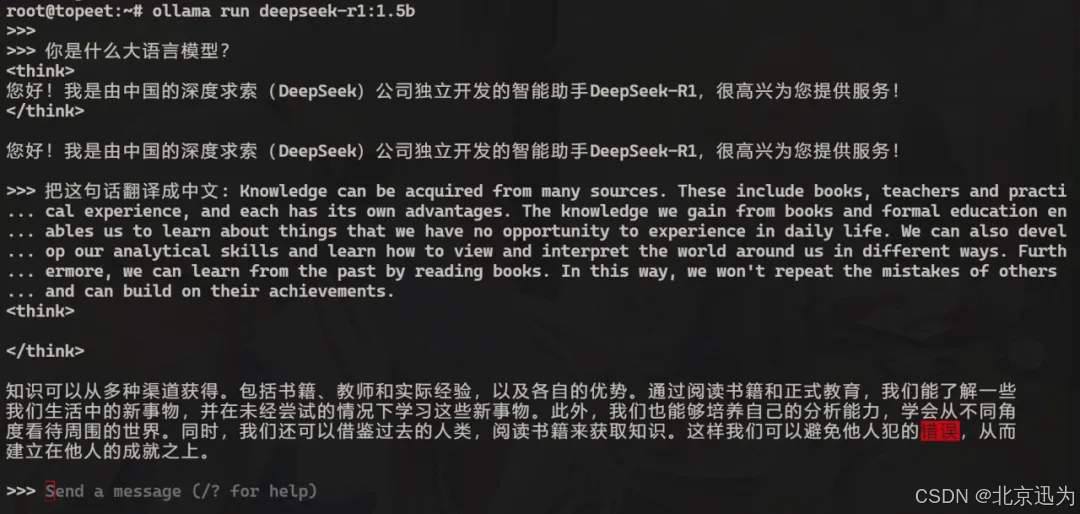 这里只是运行的15亿参数大小的模型,所以回复的可能并不是很准确,如果想要更高的准确率可以切换为参数更大的模型,但参数变大之后相应的回复速度也会变慢,并且使用Ollama工具部署的推理模型调用的是CPU进行的运算,如下图所示:
这里只是运行的15亿参数大小的模型,所以回复的可能并不是很准确,如果想要更高的准确率可以切换为参数更大的模型,但参数变大之后相应的回复速度也会变慢,并且使用Ollama工具部署的推理模型调用的是CPU进行的运算,如下图所示:
 可以看到在回复的过程中CPU的负载达到了百分之百,并没有调用NPU进行加速,那要如何将RK3588强悍的NPU调用起来呢,这就要看第二种方法使用瑞芯微官方的RKLLM进行量化部署了。
可以看到在回复的过程中CPU的负载达到了百分之百,并没有调用NPU进行加速,那要如何将RK3588强悍的NPU调用起来呢,这就要看第二种方法使用瑞芯微官方的RKLLM进行量化部署了。
02-使用RKLLM量化部署
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件。通过该工具提供的Python接口可以便捷地完成以下功能:
1.模型转换:支持部分格式的大语言模型转换为RKLLM 模型转换后的 RKLLM 模型能够在 Rockchip NPU 平台上加载使用
2.量化功能:支持将浮点模型量化为定点模型
DeepSeek转换完成的RKLLM模型如下图所示:
 然后将其传输到开发板上,使用对应的可执行文件运行即可,运行之后如下图所示:
然后将其传输到开发板上,使用对应的可执行文件运行即可,运行之后如下图所示:
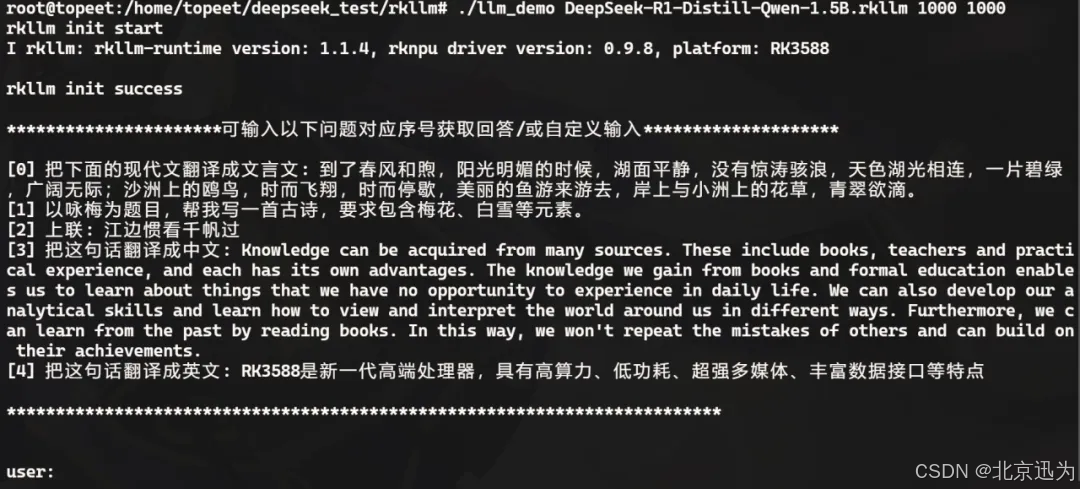
接下来向该模型提出问题即可,回复内容如下所示:
 在回复的过程中查看CPU和NPU的利用率,可以看到CPU的占用率已经降了下来,并且调用了NPU的3个核心进行加速推理:
在回复的过程中查看CPU和NPU的利用率,可以看到CPU的占用率已经降了下来,并且调用了NPU的3个核心进行加速推理:

至此,关于DeepSeek在RK3588上的部署推理就测试完成了。
部署视频展示
分享 | 基于RK3588开发板部署测试DeepSeek模型

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)