【2025版】最新DeepSeek大模型微调实战(超详细实战篇)零基础入门到精通,收藏这篇就够了
DeepSeek是由 深度求索 团队开发的大语言模型,本实验将基于deepseek-llm-7b-chat模型,在EmoLLM数据集进行微调,实现大模型能够以心理医生的口吻来回答我们的问题。本实验基于transformers和openMind均已实现本次微调,代码均可在github链接上查看。通过本次实验,你不仅能够完成 多轮对话数据的微调,还能掌握这些方法,并 将其迁移到其他微调实验中,独立进行
DeepSeek是由 深度求索 团队开发的大语言模型,本实验将基于deepseek-llm-7b-chat模型,在EmoLLM数据集进行微调,实现大模型能够以心理医生的口吻来回答我们的问题。
本实验基于transformers和openMind均已实现本次微调,代码均可在github链接上查看。
通过本次实验,你不仅能够完成 多轮对话数据的微调,还能掌握这些方法,并 将其迁移到其他微调实验中,独立进行高效的模型调优。
实际项目代码+结果演示
本次实验同时适配transformers和openMind,由于openMind缺少数据处理的函数,下面实验手动添加即可,其他部分和基于transformers的代码一致。
2.1 基本概念
1、openMind Library—>Huggingface Transformers
openMind Library类似于transformers的大模型封装工具,其中就有AutoModelForSequenceClassification、AutoModelForCausalLM等等模型加载工具以及像TrainingArguments参数配置工具等等,原理基本一样,不过对NPU适配更友好些。

2、魔乐社区—>HuggingFace
魔乐社区类似于huggingface这种模型托管社区,里面除了torch的模型还有使用MindSpore实现的模型。transformers可以直接从huggingface获取模型或者数据集,openMind也是一样的,可以从魔乐社区获取模型和数据集。
2.2 实验环境搭建及实验代码、结果
2.2.1 环境设置
在运行代码前,需要先配置环境,由于本次实验对比各个参数结果比较多,所以对显存要求稍微高点,具体环境配置如下:
GPU:40GB左右
Python:>=3.8

2.2.2 数据预处理
本次微调目的是使得大模型能够以医生的口吻来回答我们的问题,因此需要与心理健康有关的数据集资料。
⭐下载数据
本项目使用一个EmoLLM-心理健康大模型中使用的数据集(该数据集已经进行数据清洗,在保证质量的同时,通过调整阈值减少因错误匹配而丢失重要数据的风险。):EmoLLM-datasets
(https://github.com/SmartFlowAI/EmoLLM/tree/main/datasets)
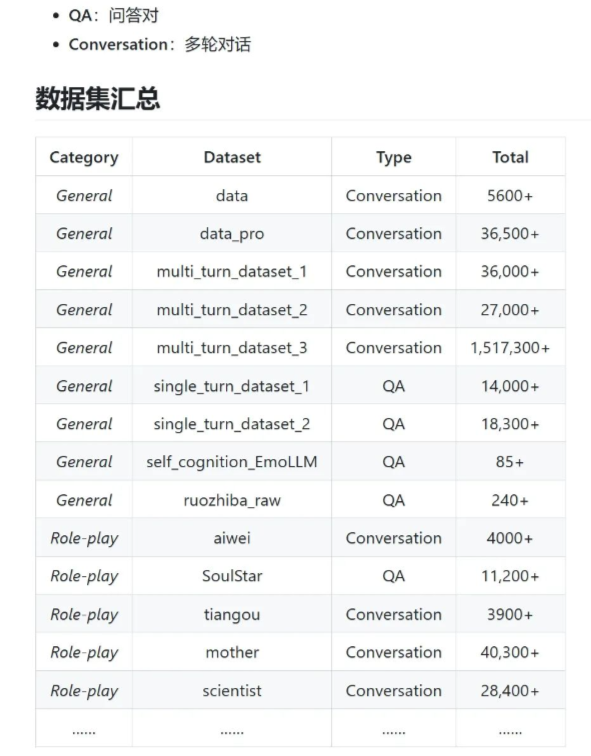
数据集内容如下:

在训练前,我们需要将数据进行预处理,将数据集的内容进行数据映射,得到input_ids、attention_mask、labels三个映射目标,同时对数据填充到最大长度,并且转换成张量格式。
数据映射

这里可能会根据每个模型的不同做修改,如果不按照每个模型对应的格式训练,而是按照自己编写的格式进行训练,结果可能会出现由于max_length比较大使得回答停不下来,一直生成句子。
那么该如何确定训练文本格式❓其实在每一个模型的tokenizer_config文件中已经给出模板。
比如deepseek的模板如下:

如果模板看的有点抽象的话,可以直接参考Llama-Factory中deepseek模型对应的模板:
https://github.com/hiyouga/LLaMA-Factory/blob/main/src/llamafactory/data/template.py

数据封装
⚠️注意:
由于openMind缺少数据封装的函数,因此这部分代码需要我们手动添加,transformers直接调用即可。
transformers:
 openMind:
openMind:

2.2.3 设置lora参数
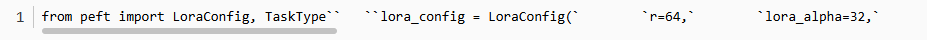
2.2.4 设置训练参数
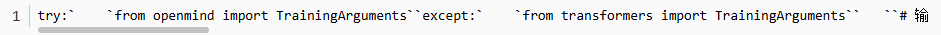
2.2.5 设置可视化工具SwanLab
SwanLab是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:
●基于一个名为swanlab的python库
●可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果
●能够自动记录logging、系统硬件、环境配置(如用了什么型号的显卡、Python版本是多少等等)
●同时可以完全离线运行,在完全内网环境下也可使用
代码如下:
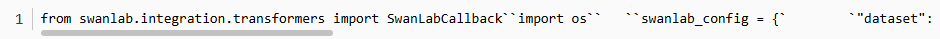
2.2.6 设置训练器参数+训练
在微调Transformer模型时,使用Trainer类来封装数据和训练参数是至关重要的。Trainer不仅简化了训练流程,还允许我们自定义训练参数,包括但不限于学习率、批次大小、训练轮次等。通过Trainer,我们可以轻松地将这些参数和其他训练参数一起配置,以实现高效且定制化的模型微调。
这里我们需要以下这些参数,包括模型、训练参数、训练数据、处理数据批次的工具、还有可视化工具
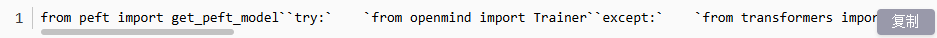
2.2.7 保存模型
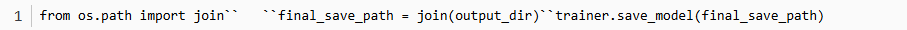
这里保存了模型的权重、配置文件和词汇表,确保你可以在之后重新加载并使用该模型进行推理或继续训练。模型的优化器状态、学习率调度器等其他信息如果需要保存,则需要显式调用其他相关方法,如 trainer.save_state()。

2.2.8 合并模型权重
保存下来的仅仅是模型的权重信息以及配置文件等,是不能直接使用的,需要与原模型进行合并操作,代码如下:

下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 4
4 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)