3.RK3588本地部署deepseek模型及调用API的方法
参考传送门:OpenAI调用报错问题分析。
参考传送门:
OpenAI调用报错问题分析
https://www.jianshu.com/p/f25c9753bca8
RK3588部署Deepseek R1模型(CPU+NPU)
https://blog.csdn.net/weixin_43999691/article/details/145557662
一、前言
deepseek非常火,被称为国运级研究成果,如果仅仅满足于网页对话框或APP的使用方式,未免浪费了这么好的开源模型的功能。从实用角度deepseek的服务器接口的爆满,也很难满足用户需求。
本文采用下面两种其他的方式,使用deepseek模型
- 使用python调用其API,和通过网页获取文本没有本质区别
- 通过部署到本地,使用本地主机的CPU或NPU算得答案
二、API的调用方法
1.环境准备
-
准备python3.8
# apt-get install python python3.8 # ln -sf /usr/bin/python3 /usr/bin/python # ln -sf /usr/bin/python3.8 /usr/bin/python3 # python --version Python 3.8.0 -
准备pip 25.0
# apt-get install python3-pip # pip3 install --upgrade pip # pip --version pip 25.0 from /usr/local/lib/python3.8/dist-packages/pip (python 3.8)
2.安装openai包
# pip3 install openai
网络延迟高的话,换国内源
# pip3 install openai -i https://pypi.tuna.tsinghua.edu.cn/simple/
3.按照deepseek官网的API文档写脚本
写脚本前需要获取自己的秘钥,走传送门
https://platform.deepseek.com/api_keys
# api_key要换成自己的
# cat joke.py
from openai import OpenAI
client = OpenAI(api_key="***************", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "Hello! My name is wxd."}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
print("wxd :",messages[0]["content"])
print("deepseek:",response.choices[0].message.content)
print("")
messages.append(response.choices[0].message)
# Round 2
messages.append({"role": "user", "content": "Can you tell me a cold joke in Chinese?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
print("wxd :","Can you tell me a cold joke in Chinese?")
print("deepseek:",response.choices[0].message.content)
print("")
messages.append(response.choices[0].message)
效果如图所示:

出于我不及格的python水平,勉强拼了些代码来演示现象。我测试的是deepseek官网关于多轮对话的推理,由于测试时忘记了关tz,导致测试一些文本经常python报错,还以为是API不好用。后续如果还有兴趣的话,或许会用Qt写个界面
三、RK3588本地部署
既然使用RK3588肯定是想使用其NPU,而不是靠CPU硬算,故跳过使用ollama跑模型的方法,使用瑞芯微的工具rkllm来跑。
1.获取模型
RKLLM-Toolkit 是为用户提供在计算机上进行大语言模型的量化、转换的开发套件。用人话讲RKLLM-Toolkit是在x86上将其他模型转换为RK NPU能运行的模型,转换的本质和流程没研究过,可以直接下载官方转换好的DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm,密码:rkllm
模型地址:deepseek-r1的rknn模型
2.环境配置
我的RK33588系统是Ubuntu20
-
python环境和上面一样,略
-
安装git以及编译环境
# apt-get install git build-essential cmake -
安装中文以及输入法
# apt install language-pack-zh-hans fcitx fcitx-googlepinyin fcitx-config-gtk
3.rkllm获取与编译
# git clone https://gitcode.com/gh_mirrors/rk/rknn-llm.git
root@firefly:~/deepseek/rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy# chmod a+x build-linux.sh
#修改编译脚本
# cat build-linux.sh
#!/bin/bash
# Debug / Release / RelWithDebInfo
...
C_COMPILER=gcc
CXX_COMPILER=g++
...
#将编译好的安装包改名
root@firefly:~/deepseek/rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install# mv demo_Linux_aarch64 ~/deepseek/rkllm
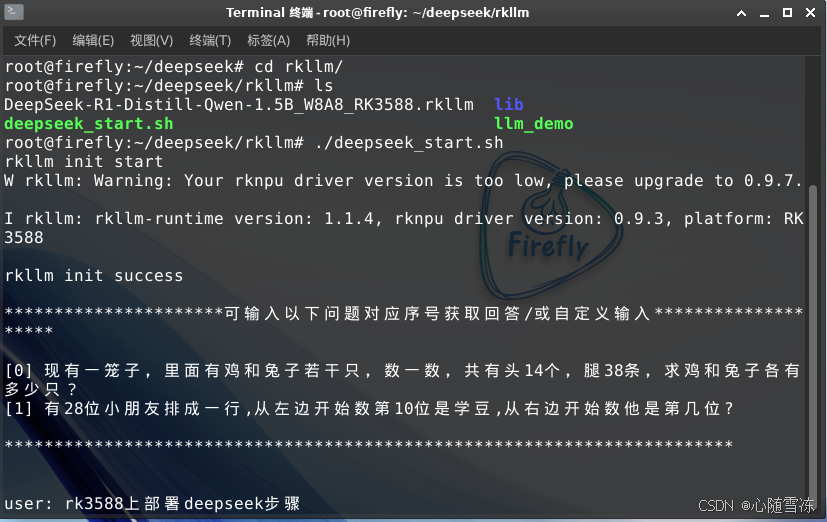
4.创建运行脚本
root@firefly:~/deepseek/rkllm# touch deepseek_start.sh
root@firefly:~/deepseek/rkllm# chmod 777 deepseek_start.sh
# cat ./deepseek_start.sh
#!/bin/sh
export LD_LIBRARY_PATH=/root/deepseek/rkllm/lib
taskset f0 ./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm 2048 4096
运行效果如图

查看NPU的是用情况:# cat /sys/kernel/debug/rknpu/load

观察现象可以看出来跑1.5B的模型都要花费三个NPU的一半性能了,1.5B的模型的回答也很蠢,当然让AI理解嵌入式的很多东西确实为难AI了,所以底层开发者没有必要有应用开发者的焦虑,如果AI发展到能分析自身所处的机器,那就是人类要面对的问题了,而不是仅仅是程序员要面临的失业问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)