数字人完全离线本地Windows Web端 (生成的不是视频!!)
写在前面
本人是程序员,对于建模和骨骼动画的没有什么时间去学习,所以这个项目采用的前端采用的是vue+Live2D,没时间去弄UE和U3D,模型也是免费模型,如果你懂这一块的内容,那你完全可以自定义。
由于我做的是企业项目,所以我可以搞到一些资源过来,但是我在做这块的时候发现有相当一部分人,并不是从事相关行业的,我一开始做这个的时候也很烧脑,所以这篇文章主要是为了让更多的人能搞出来这个数字人来玩,同时大家也可以交流一下各种各样的问题,所以一切从简,那如果你有足够的时间或人力物力,那就是万物起源。
这个项目做完的版本是一个可以将你的问题(可以是语音,可以是文字)通过DeepSeek的回答转换成语音的实时响应的数字人(生成的不是视频!!)完全离线,当然你也可以租服务器做到随时随地访问。
我的电脑配置
CPU 12th Gen Intel(R) Core(TM) i5-12490F 3.00 GHz
内存 32.0 GB (31.9 GB 可用)
操作系统 Windows11
显卡 4060(8G)
这里的话 无非就是内存大了一些,一般大家用的都是16G的内存,因为这个项目中间,有一块TTS的模块,也就是文字转语音这里,它占用的内存很大,当然16G也可以满足,不过需要一些骚操作,但是32更好。再就是显卡最好8G以上,因为你没有显卡或者显存比较小的话,跑的更慢。
项目介绍
整体模块结构图,很简单,接下来我们会一步一步实现这里面的每一块,先介绍一下,这个结构里面的一切内容都可以替换成你喜欢的模块。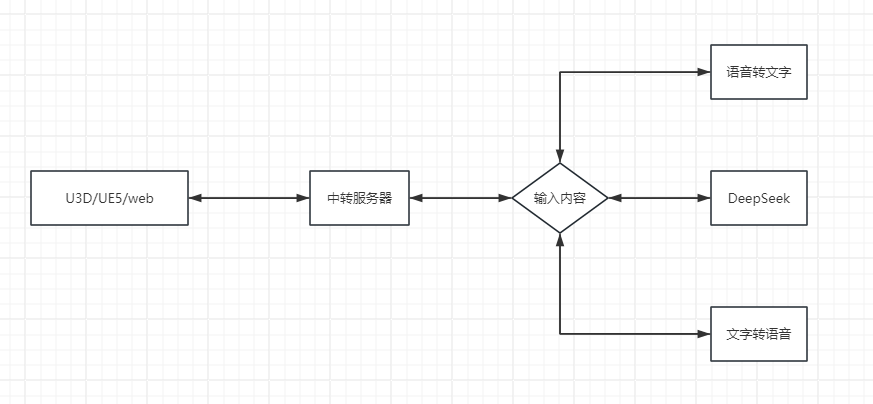
U3D/UE5/web(前端)
这块是主要是数字人表现这里,你想把这个数字人通过什么渠道展现出来
U3D/UE5 的话主要是通过下载的方式,也就是说做了一个应用或者游戏或者嵌入到你已有的项目中作为一个NPC或者小助手的存在。 因为我们做的是实时的,所以U3D这里的实时渲染并没有UE5这块好,可以拿来直接用的插件也比较少,所以U3D这里我不好推荐,但是如果你熟悉UE5的话,这块的内容就很多,教程也不少,可以从MetaHuman这里入手,但是学习成本也有。
Web 的话就是通过网页展示,这里相对于上面的U3D/UE5就简单很多,并且看效果也很快,学习成本也没有那么高,我这个选择的是Vue3+Live2D, 也是这篇文章做的展示方式。
中转服务器(门户)
中专服务器,主要是因为安全性和便捷性设计的,可以通过中专的服务器,把你的输入做一个判断,然后把这个输入发给后面的模块,如果你需要一个可以统筹规划各种数据以及接口的话,有一个中转的服务器就很舒服,同时也可以避免你的各种模型模块不被直接暴露给前端,毕竟多数的模块都需要算力,这东西挺贵的,如果你自己玩我建议也有一个,这也是大多数后端的一中设计, 我这里用的是Python + fastapi。
文字转语音(TTS)
这个主要是把你的输出的文字进行语音合成,这里的模型主要选择方向一个是合成的效果,另外是合成的速度,目前大多数的模型都支持几秒的急速复刻,主要区别也是速度和效果,我这里选择的是CosyVoice2,其他的我也试过,但是效果不是很好,但是用CosyVoice2有个问题就是慢,效果我个人觉得还不错。
DeepSeek
这个DeepSeek大家应该有所了解,当然也有其他的模型,选择这个主要是为了回答的准确率和响应速度,这里我使用的是deepseek:r1-1.5b, 因为是实验版本,你可以根据的你需求进行修改,接Api或者自己部署更高版本的DeepSeek,或者其他产品。
文字转语音
这个主要是把你的语音输入识别出来文字,就像是微信的语音转文字一样, 模型很多,效果也都很好,这里我用的SenceVoice。
那整体的每一个模块的内容就是上面简单的介绍了,接下来就一步一步实现,包括实现过程中我们可以通过哪些应用、插件、AI来实现我们这个过程,整体的耗时不会很久,更多的时间是消耗在下载模型文件的时间,有的人可能不会科学上网,有的人可能不会看不懂代码,但是没关系,都有解决方案。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)